國產小廠胖揍英偉達,中國芯片這就崛起了?_風聞
差评-差评官方账号-2022-09-29 08:17
本文原創於微信公眾號:差評 作者:差評君
 最近,差評君聽到了一個好消息。
最近,差評君聽到了一個好消息。
AI 算力領域的“ 圖靈獎 ”—— MLPerf 測試,發佈了一個關於當前主流 ai 芯片的基準性能的測試結果。
一家首次參加測試的芯片企業——墨芯人工智能,化身“ 草根英雄 ”,火速制裁了AI芯片的霸主英偉達。
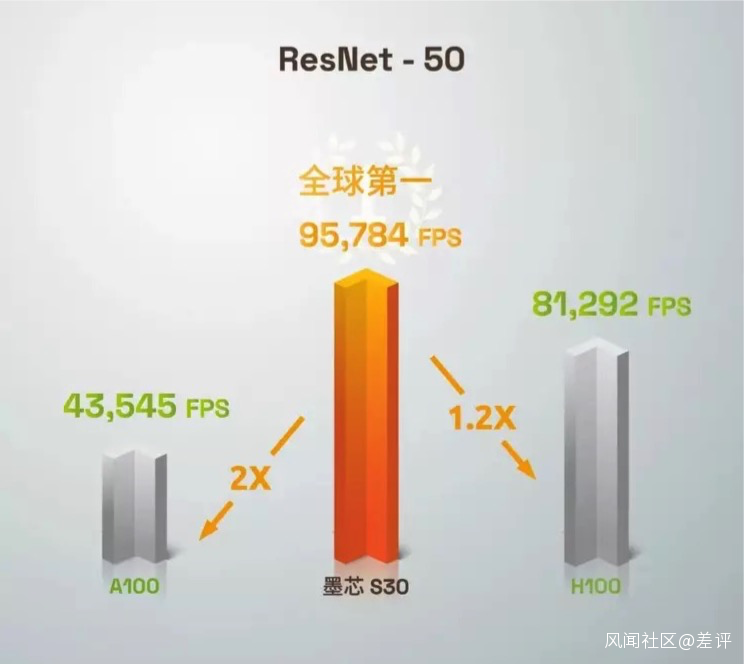
墨芯 S30 芯片在主流 AI 模型之一的圖像分類( ResNet50 )中,以 95784 FPS 的單卡算力奪得全球第一。
是英偉達現役最強 GPU——A100 的 2 倍,是即將上市的英偉達 H100 的 1.2 倍。

 對芯片不太瞭解的差友,可能不太瞭解這事的重要性。
對芯片不太瞭解的差友,可能不太瞭解這事的重要性。
市場研究公司 Omdia 調查顯示:英偉達佔據了全球人工智能( AI )處理器 80.6% 的市場份額。
而作為他的旗艦產品 A100、H100 幾乎代表了全球同類芯片的最高水平。
如果墨芯 s30 真能超越英偉達最新科技的話,説不定雙方的團隊已經在洽談收購的事情了。
不過,更逆天的是,墨芯 S30 竟然用 14nm 納米的製程就暴打了 4nm 工藝的英偉達最強 GPU——h100 系列。
 這是真的 6 翻了。
這是真的 6 翻了。
雖然,每一年都有一兩家企業叫囂着:拳打英偉達、腳踩英特爾。
但是能用 14nm 工藝超越 4nm 工藝的芯片公司,英特爾看了都要饞。

所以要是不出意外的話,憑藉這個技術,名不經傳的墨芯公司完全可以,名揚大中華,技術封鎖美利堅,然後帶着歐盟 27 個小弟稱霸世界了。
好了,説到這裏,想必各位差友都知道了
如果不出意外的話,那麼意外就來了。
很快有人扒出來:墨芯這瓜,它不保熟。
雖然,這個叫做 MLPerf 的性能測試,權威且保真。
但是,也有很多周旋的空間。
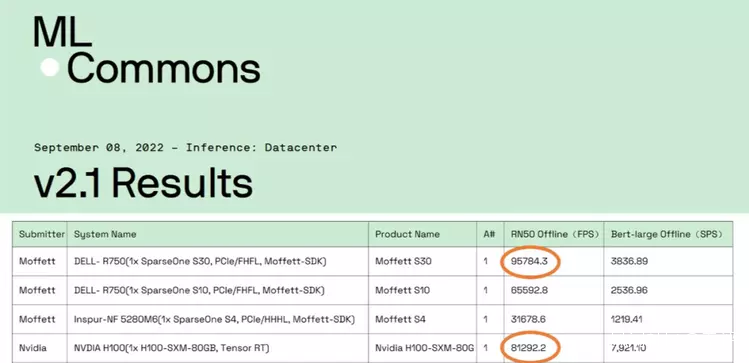
比如,雖然墨芯公司官方的宣傳裏,着重強調了“ 算力全球第一 ”。
但後續有人扒出了,這個“ 全球第一 ”的數據經過了“ 美化 ”的處理。

關鍵性的分組標籤,被人p掉了。
點擊查看大圖 ▼
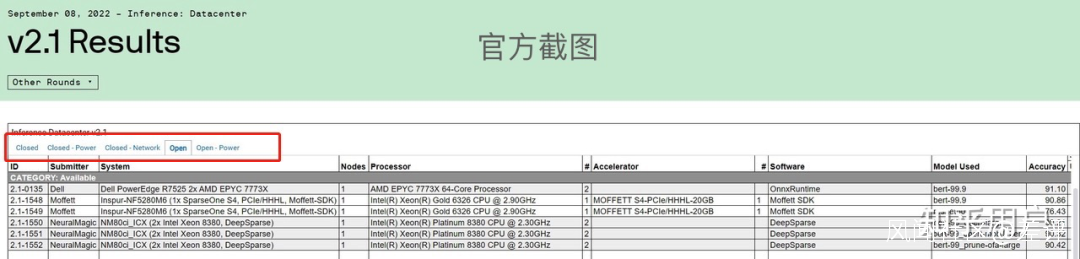
點擊查看大圖 ▼
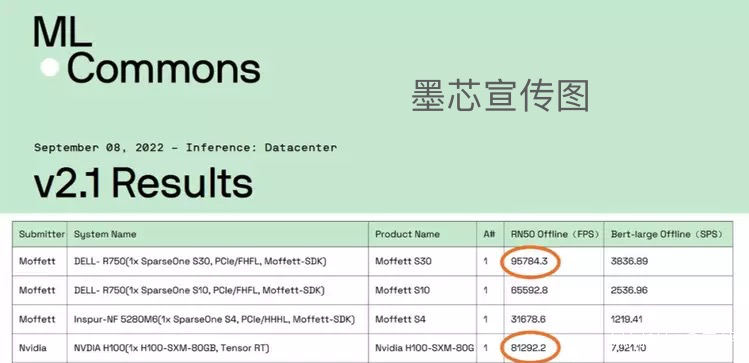
原來,這個 MLPerf 測試它是分為 Closed( 固定任務 )和 Open( 開放優化 )兩組。

Closed 代表的固定任務分組,進行的是正式比賽。
也就是説,廠商們,需要運行統一的算法,對同一個模型圖像分類( ResNet50 )進行計算,實現芯片之間的性能比較。
而這個 open 分組就是用來展示一些創新性的成果的,也就是所謂的表演賽。
在這個組別裏,只要不改變測試的內容,你想怎麼玩都行。
而墨芯參加的恰恰就是 open 分區的測試。
於是,墨芯 s30 憑藉着“ 稀疏化 ”的算法,用“ 無規則格鬥 ”的打法勝了英偉達的“ 空手道 ”。
然後,公司再一運作,刪刪減減,一個全球算力第一的營銷廣告就這麼華麗的出現。

 又一個營銷鬼才。
又一個營銷鬼才。
不過這豈不是證明了墨芯用的稀疏算法**,能大幅增加ai****芯片的算力?**
情況也確實是這樣的。
所謂的稀疏算法,又稱剪枝。
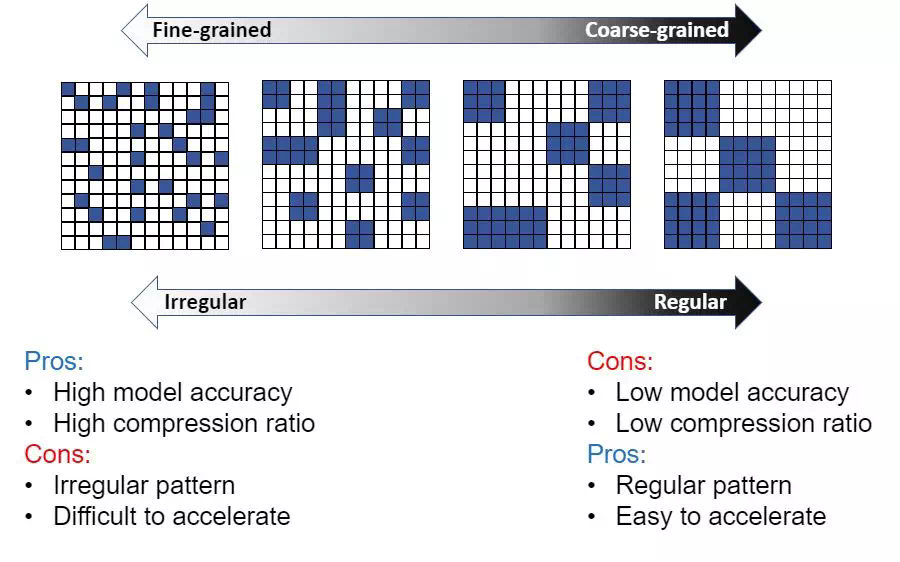
就是在 ai 模型的訓練過程中,把一些不重要的運算過程去掉,大大增加計算的效率。
這就像識別一個超清的圖像,如果我們降低到標清的水平,傳輸速度就會快上許多。
但是,這種成倍提升算力的“ 黑魔法 ”怎麼會沒有代價呢?
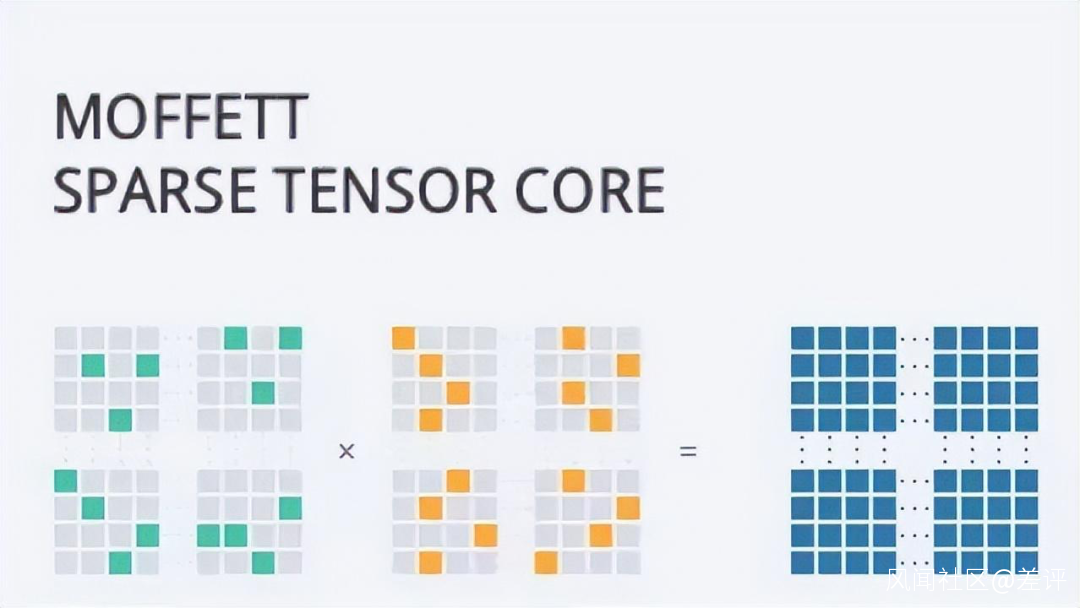
一來, 這種提升算力的方式應用場景比較小,不適合高精度的模型訓練。
二來,算力是通用的,ai 的模型並不是,這就需要根據不同的模型,研究不同的稀疏算法。
但問題的重點在於,稀疏算法並不是墨芯一家的專利,英偉達家的 h100 也能支持。
而且,英偉達依然是目前唯一一家在每輪 MLPerf 基準測試都參與所有主流算法測試,然後橫掃各項測試成績的全能選手。
 所以説,回到 ai 芯片的性能本身,我們還是很難否認英偉達在這方面的統治力。
所以説,回到 ai 芯片的性能本身,我們還是很難否認英偉達在這方面的統治力。
不過,拋開這次的“ 吊打英偉達 ”的烏龍事件不談,最近幾年國內還是湧現出一批優秀的國產 ai 芯片。
比如在今年 3 月,壁仞科技誕生了一枚名為 BR100 的芯片。
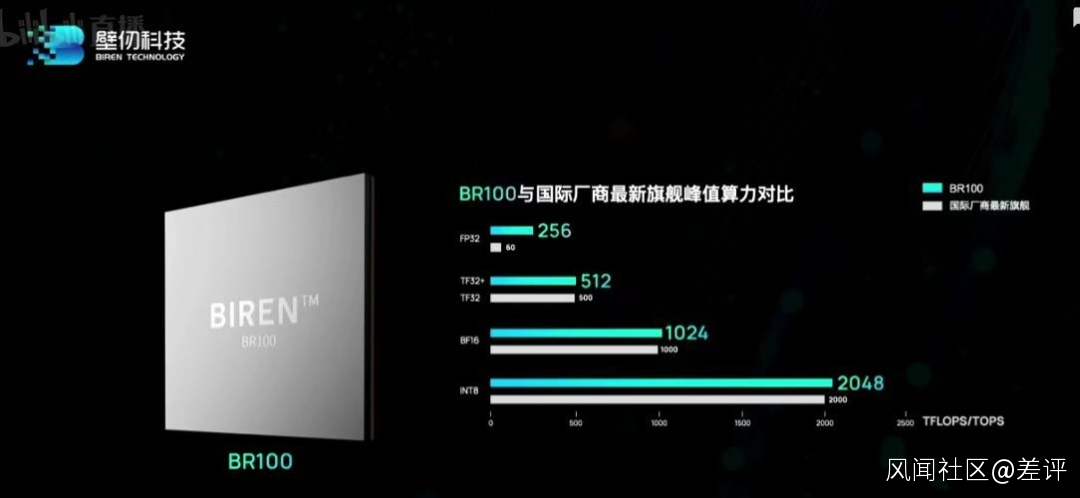
這顆芯片 16 位浮點算力在 1000T 以上,8 位定點算力達到了 2000T 以上,打破了此前一直由國際巨頭保持的通用 GPU 全球算力紀錄。
而 19 年,華為發佈的昇騰 910 芯片的算力也號稱是當時國際頂尖水平的兩倍。
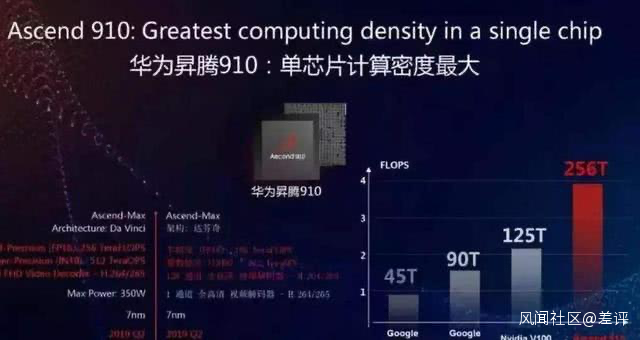
看來,真金白銀地砸進去還是有水花的。
不過,當國內芯片的性能開始觸碰到全球算力的天花板的時,我們才發現差距不止在算力上。
國內的一大批創業者們,早已經在追趕英偉達的過程中,撞上了第二堵南牆**:**生態。

2016 年前後,ai 的浪潮席捲中國,人人都想做“ 中國的英偉達 ”。
但後來,國內的廠商們慢慢發現AI芯片陷入了一個困境:ai 芯片無法成為一個單獨的產品。
探境科技的CEO概括了這種複雜的處境:
英偉達的GPU在AI應用中很難被替換,因為英偉達的GPU除了能處理AI的工作,還能進行圖形計算等。
即便AI專用芯片性能大幅提升,也不能滿足最終應用的所有需求,客户還要再購買GPU。
以至於,大家都以兼容英偉達的軟件開發系統目標,如果不兼容,代碼重新開發或者移植的成本太大了。
之所以會有這樣的問題,是因為英偉達依靠在 gpu 上的先發優勢建立了自己的生態--CUDA ,一套與英偉達芯片配套的軟硬件開發的工具包。

能為幾乎所有主流的 ai 模型服務,同時大量的開發者也在反哺和完善這個生態。
據 2021 年英偉達官方最新數據顯示,英偉達生態的開發者數量已接近 300 萬, CUDA 在過去 15 年總計下載量達 3000 萬次,過去一年下載量達到 700 萬。
這就好比同樣是一個野外求生俱樂部。
國內還停留在,拿着一本野外求生指南讓客户自己學的階段時。
而英偉達,已經提供了全套裝備。

 甚至送來了一個貝爺。
甚至送來了一個貝爺。

這就導致了,AI的軟件生態成了****英偉達生態。
而英偉達的軟件生態,尤其是 CUDA 相關的核心部分都是閉源、封閉的。

在這樣的封鎖下,想要將自家的軟件與英偉達的生態兼容的難度可想而知,建立一個新的 AI 生態更是痴人説夢。
一位國內AI芯片公司軟件的負責人直言:“ CEO 和 CTO 都聽不懂我的工作。一些國內 AI 公司創始人對軟件的認知,相比領先的國際大公司,我認為有十幾年的差距。”
英偉達 GPU 強大的產品力加上頂尖的 CUDA 軟件生態,使得它在 AI領域的勢力不可動搖。
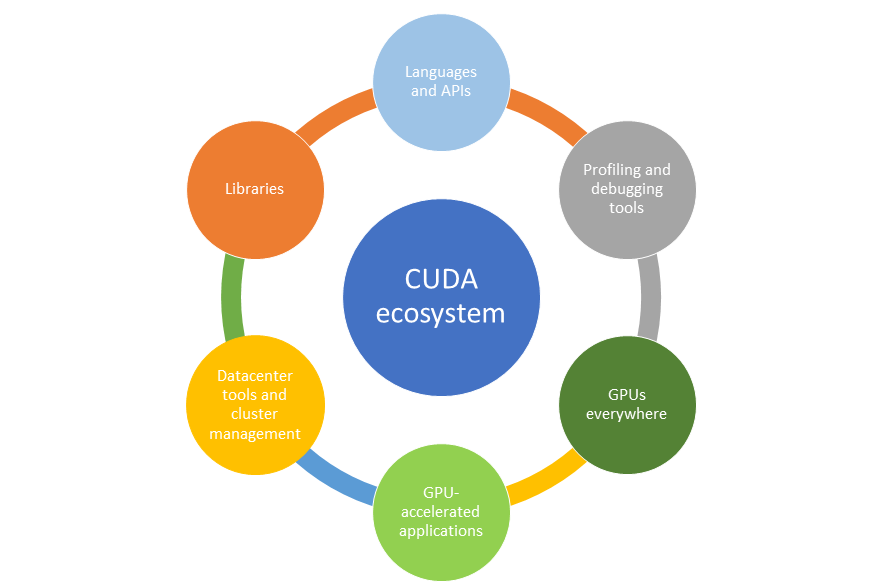
包括微軟、三星、 Snap 等在內的 25000 多家企業客户,都接入了英偉達的 ai 推理平台。
而且它比想象的要難以超越。
 因為他不僅比你更強,還比你更努力。
因為他不僅比你更強,還比你更努力。
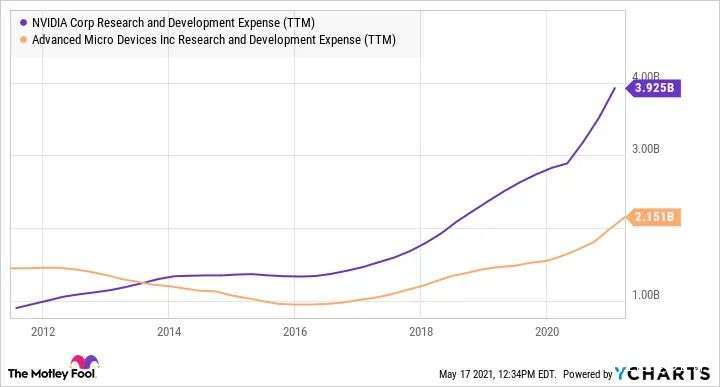
在過去的十年中,英偉達在研發方面的支出持續擴大,根據財報,2021 年英偉達研發投入達到 39.24 億美元。
所以,在這種全面的領先下,我們很難相信有什麼公司可以在ai芯片領域,一步跨越大山一樣的英偉達。
這一點,每年砸出去上百億的英特爾深有體會。
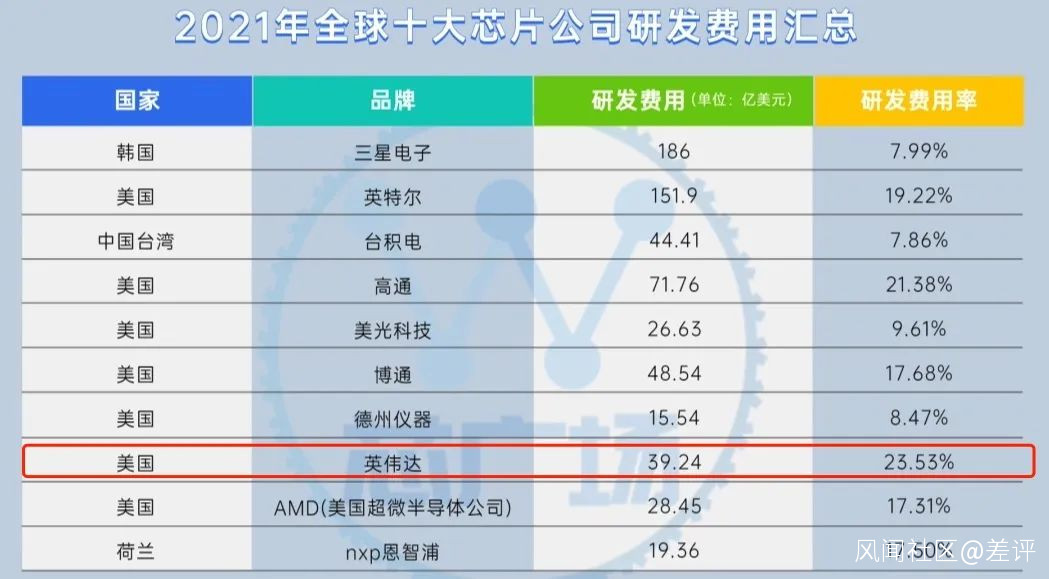
而相對於全球其他的競爭者們,我們還面臨着芯片製程的問題。
但即便如此,差評君覺得,差距越大,我們更應該腳踏實地地發展。
 不要幻想一日趕英超美,而是緊緊跟在對手的身後,就像一頭獵豹,等待敵人犯錯。
不要幻想一日趕英超美,而是緊緊跟在對手的身後,就像一頭獵豹,等待敵人犯錯。
參考文獻:
市值四倍於英特爾,英偉達踩上數據爆發的風口 商業數據派
聚焦丨英偉達CUDA在深度學習中扮演着什麼角色?ai芯天下
中國AI芯片提前進入肉搏期。財經十一人
如何看待墨芯S30計算卡超越英偉達H100,中國AI芯片突然這麼猛了嗎?知乎
算法引領AI芯片走入2.0時代 甲子光年
AI時代,英偉達如何成為最大贏家? 老石談芯
人工智能未來發展的底層邏輯 老石談芯
2021年全球十大芯片公司財報營收及研發支出一覽 芯廣場
NVIDIA and the battle for the future of AI chips
