注意力機制作用被高估了?新研究:把注意力矩陣替換成常數矩陣後,性能差異不大_風聞
量子位-量子位官方账号-2022-11-19 21:43
蕭簫 發自 凹非寺
量子位 | 公眾號 QbitAI
要説Transformer的核心亮點,當然是注意力機制了。
但現在,一篇新研究卻突然提出了帶點火藥味的觀點:
注意力機制對於預訓練Transformer有多重要,這事兒得打個問號。

研究人員來自希伯來大學、艾倫人工智能研究所、蘋果和華盛頓大學,他們提出了一種新的方法,用來衡量注意力機制在預訓練Transformer模型中的重要性。
結果表明,即使去掉注意力機制,一些Transformer的性能也沒太大變化,甚至與原來的模型差異不到十分之一!
這個結論讓不少人感到驚訝,有網友調侃:
你褻瀆了這個領域的神明!

所以,究竟如何判斷注意力機制對於Transformer模型的重要性?
把注意力換成常數矩陣
這種新測試方法名叫PAPA,全稱“針對預訓練語言模型注意力機制的探測分析”(Probing Analysis for PLMs’ Attention)。
PAPA採用的方法,是將預訓練語言模型(PLMs)中依賴於輸入的注意力矩陣替換成常數矩陣。
如下圖所示,我們熟悉的注意力機制是通過Q和K矩陣,計算得到注意力權重,再作用於V得到整體權重和輸出。
現在,Q和K的部分直接被替換成了一個常數矩陣C:
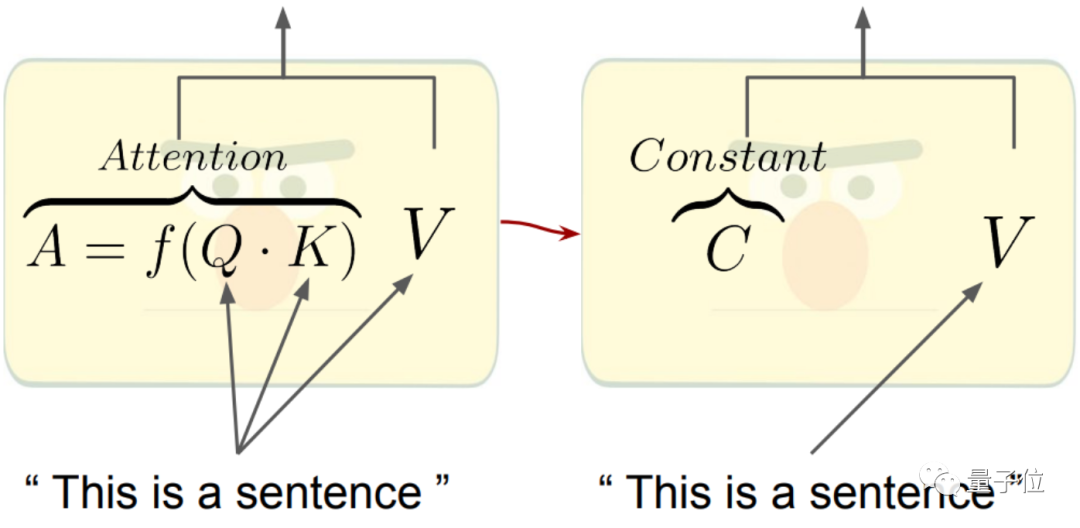
其中常數矩陣C的計算方式如下:
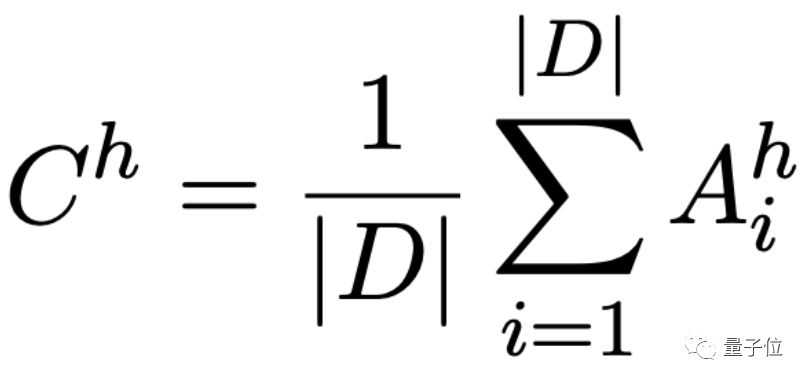
隨後,用6個下游任務測試這些模型(CoLA、MRPC、SST-2、MNLI、NER、POS),對比採用PAPA前後,模型的性能差距。
為了更好地檢驗注意力機制的重要性,模型的注意力矩陣並非一次性全換成常數矩陣,而是逐次減少注意力頭的數量。
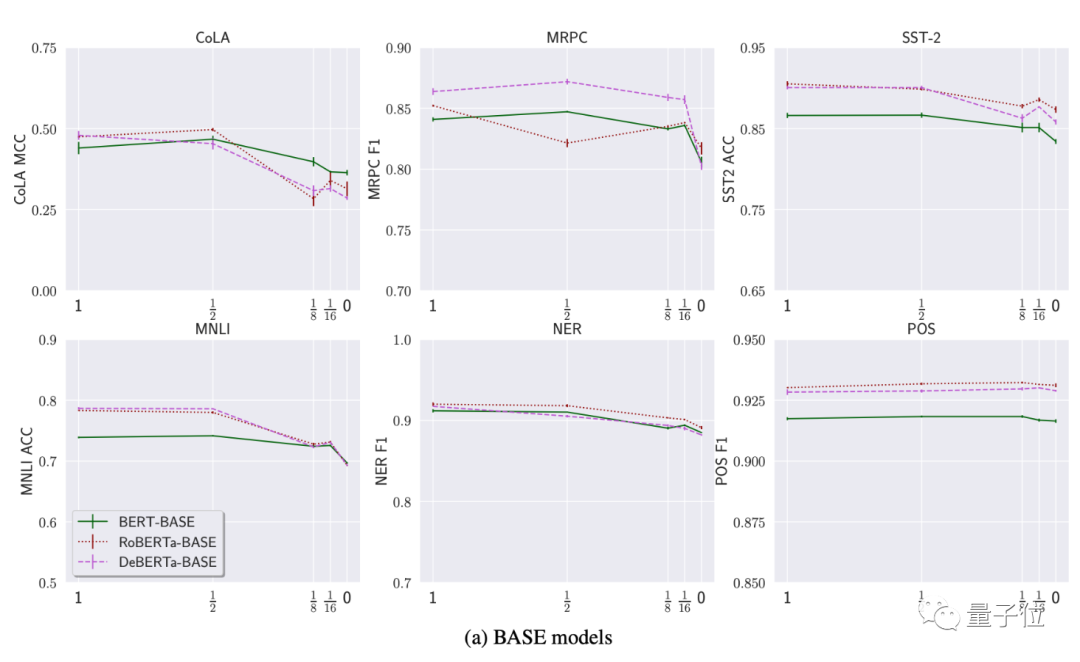
如下圖,研究先用了BERT-BASE、RoBERTa-BASE和DeBERTa-BASE做實驗,其中y軸表示性能,x軸是注意力頭相比原來減少的情況:
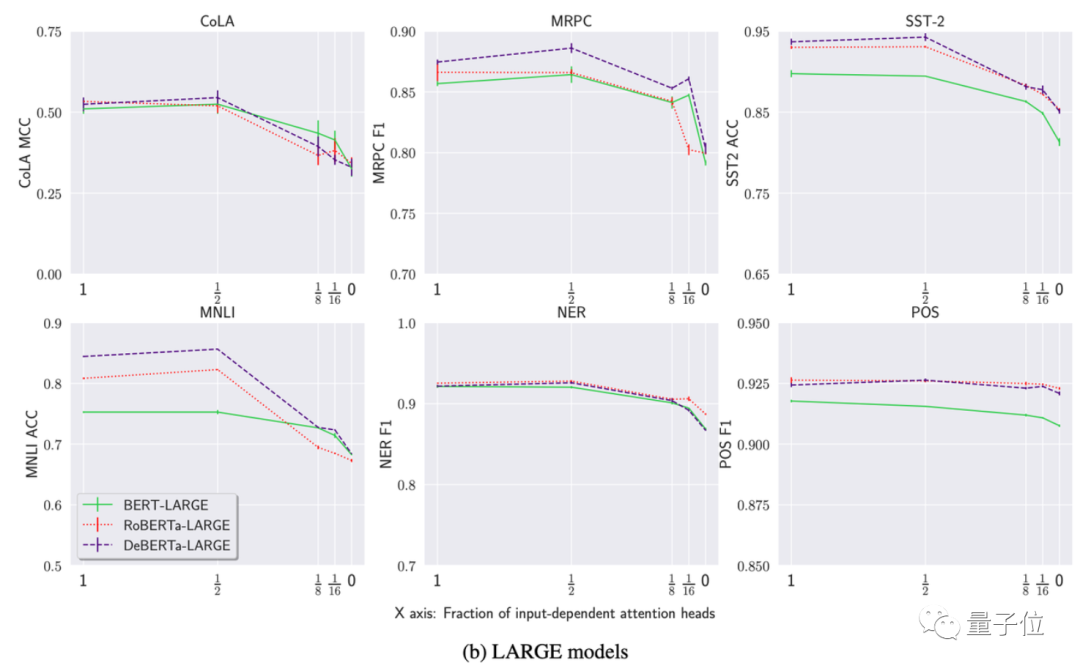
隨後,研究又用了BERT-LARGE、RoBERTa-LARGE和DeBERTa-LARGE做實驗:
通過比較結果,研究人員發現了一些有意思的現象:
首先,用常數矩陣替換一半的注意矩陣,對模型性能的影響極小,某些情況下甚至可能導致性能的提升(x值達到½時,圖中有些模型數值不減反增)。
其次,即使注意力頭數量降低為0,平均性能下降也就8%,與原始模型相比最多不超過20%。
研究認為,這種現象表明預訓練語言模型對注意力機制的依賴沒那麼大(moderate)。
模型性能越好,越依賴注意力機制
不過,即使是預訓練Transformer模型之間,性能表現也不完全一樣。
作者們將表現更好的Transformer模型和更差的Transformer模型進行了對比,發現原本性能更好的模型,在經過PAPA的“測試”後,性能反而變得更差了。
如下圖,其中y軸代表各模型原本的平均性能,x軸代表將所有注意力矩陣替換為常數矩陣時(經過PAPA測試)模型性能的相對降低分值:
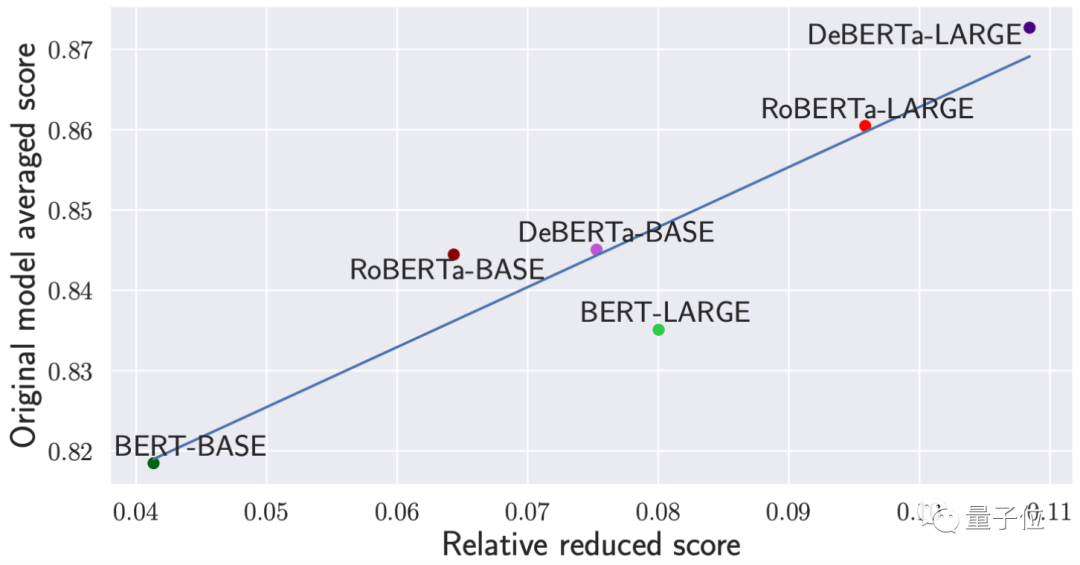
可以看出,之前性能越好的模型,將注意力矩陣替換成常數矩陣受到的損失也越高。
這説明如果模型本身性能越好,對注意力機制的利用能力就越好。
對於這項研究,有網友感覺很贊:
聽起來很酷,現在不少架構太重視各種計算和性能任務,卻忽略了究竟是什麼給模型帶來的改變。

但也有網友認為,不能單純從數據來判斷架構變化是否重要。
例如在某些情況下,注意力機制給隱空間(latent space)中數據點帶來的幅度變化僅有2-3%:
難道這種情況下它就不夠重要了嗎?不一定。
對於注意力機制在Transformer中的重要性,你怎麼看?
論文地址:
https://arxiv.org/abs/2211.03495
參考鏈接:
https://twitter.com/_akhaliq/status/1589808728538509312