雲原生數據庫百花齊放,騰訊雲TDSQL-C雲原生架構憑何凸顯?_風聞
智能相对论-智能和车,边评边测;未来和家,且品且鉴2022-11-25 15:56
文 | InfoQ
作者 | 萬佳
從傳統關係型數據庫到雲數據庫,數據庫在不斷演進。與此同時,它也發揮着越來越重要的作用。從雲計算、新媒體、音視頻、雲遊戲到移動 App,幾乎各行各業都離不開數據庫。一方面,數據庫作為 IT 基礎設施的關鍵一環,對企業業務的發展起着支撐作用;另一方面,數字化在經濟社會中不斷深入,數據成為核心要素,圍繞數據的生產、存儲和消費均依賴數據庫。
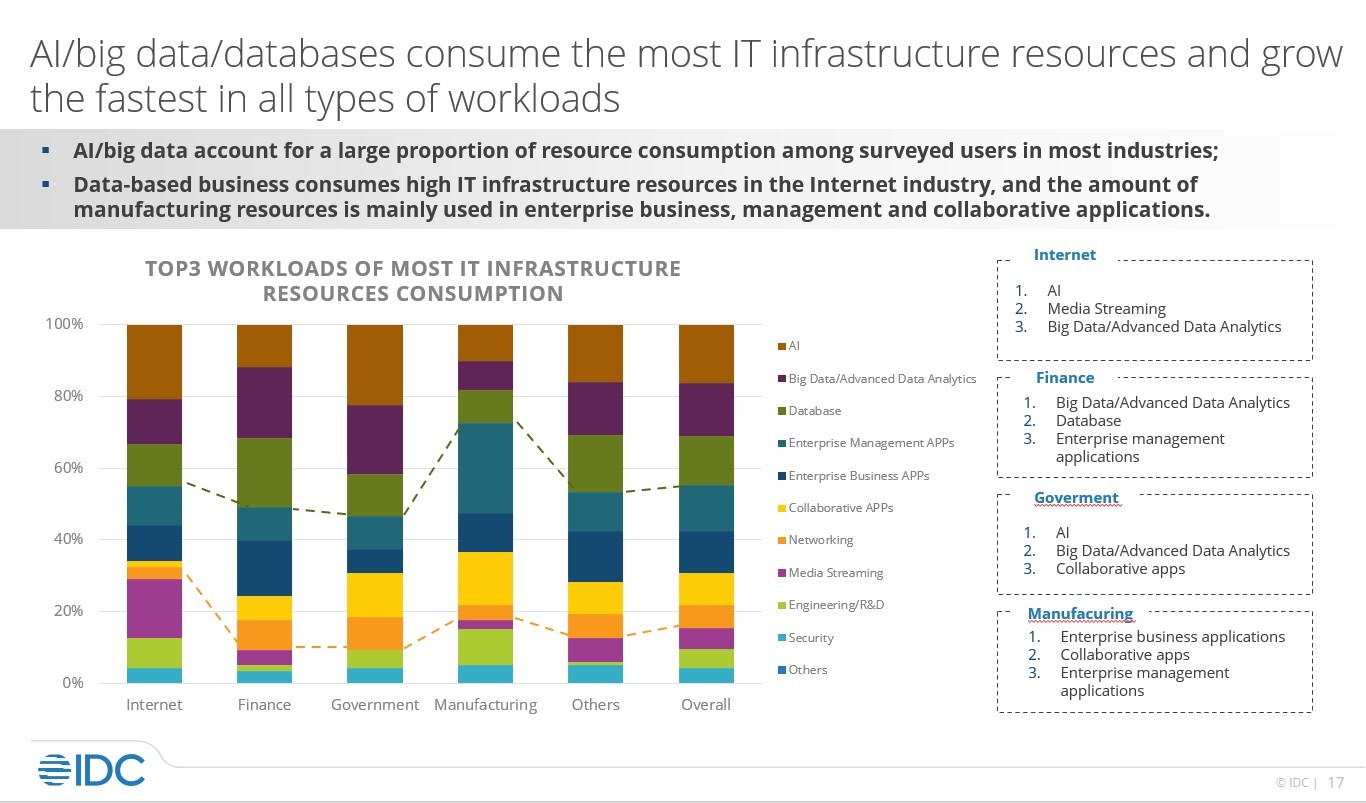
IDC 報告顯示,數據庫、AI、大數據三者消耗了最多的 IT 基礎設施資源,並且在所有類型的工作負載中增長最快。由此可見,數據庫已經成為雲中最重要的工作負載之一。
隨着企業數字化轉型的深入,業務與數據的關係越來越緊密,數據庫市場呈現蓬勃發展之勢。根據 IDC 預測,到 2024 年,中國關係型數據庫軟件市場規模將達到 38.2 億美元,未來 5 年整體市場年複合增長率為 23.3%。
除市場快速發展外,數據庫自身也在變化。雲計算的出現和發展,讓企業 IT 基礎設施雲化,應用轉向雲端。與此同時,從單體到微服務架構再到 Serverless 架構,系統架構不斷演進。這一方面為用户提供了更優秀的特性,另一方面也對雲計算的組件提出更高要求。作為雲計算關鍵技術和最基礎的組件之一,數據庫也需要適應這種架構變化。雲數據庫應運而生。
“數據庫+雲”還是“雲+數據庫”****?
雲計算自 2006 年出現後,隨着企業上雲進程的加速,傳統數據庫逐漸從私有部署轉化為雲上部署,但變化主要集中在部署模式的不同,並未充分利用雲計算理論為大數據技術本身賦能。而云原生概念的興起,讓數據庫迎來重大變革,雲原生數據庫開始成為行業“主角”。
經久不衰的關係型數據庫
眾所周知,數據庫起源於 20 世紀 60 年代。在 70 年代,關係型數據庫誕生,併成為沿用至今的數據庫存儲計算系統。即使隨着移動互聯網的發展,大數據技術的廣泛應用,湧現出越來越多新型數據庫,但關係型數據庫依舊佔據主導地位。
據 DB-Engines 統計,截至 2020 年 5 月,在收錄的 357 種數據庫中,關係型數據庫佔比高達 75.2%。它之所以能經久不衰,是因為其滿足數據庫的 ACID 特性,能幫助應用開發且簡化應用開發的複雜性。同時,它採用 SQL 標準,業務人員很容易看懂開發人員寫的代碼,代碼可讀性和可維護性非常強,降低了溝通成本。
在雲計算出現前,關係型數據庫通常採用本地部署方式(On-Premises),其中,商業數據庫代表有 Oracle、Microsoft SQL Server、IBM Db2,開源數據庫代表則是 MySQL、PostgreSQL。那時,大多數企業都是自行採購硬件和租用 IDC。除服務器外,機櫃、交換機、網絡配置和軟件安裝等底層很多事情都需要專業人士負責。數據庫方面,只有資金充裕的大企業(如電信、金融等)主要用 Oracle、IBM DB2 等商業關係型數據庫,它們的特點是性能強大、穩定性好,但價格貴、維護成本高。
傳統數據庫架構依賴於高端硬件,每套數據庫系統服務器少、架構相對簡單,且無法支持新業務的擴展需求。如果想提升性能,主要靠採用配置更高、更先進的硬件。當然,這樣的機器也更昂貴。
除了擴展性差,傳統關係型數據庫還面臨一些挑戰:一是部署成本高,維護難度大;二是由於私有化部署,數據庫內核迭代升級比較緩慢。並且,它無法應對高併發讀寫。像以 Web 2.0 為代表的網站,其數據庫負載非常高,本地部署的傳統關係型數據庫往往無法應對每秒上萬次的讀寫請求,硬盤 I/O 成為性能瓶頸。
雲計算興起,關係型數據庫演化到雲託管關係型數據庫
雲計算出現後,傳統關係型數據庫遇到的問題部分得到緩解。藉助 IaaS,企業開始將傳統數據庫“搬遷”到雲上,因此出現了雲託管關係型數據庫,雲廠商稱之為 RDS 服務,如 Amazon RDS、阿里雲 RDS 等。
與傳統關係型數據庫相比,雲託管關係型數據庫在外部交互層面上,保持了和傳統“原版”數據庫幾乎完全一致的編程接口和使用體驗。在搭建、運維和管理層面,雲託管關係型數據庫門檻更低,對用户更友好,且實現了相當程度的智能化和自動化。許多在傳統數據庫中需借額外工具或產品的功能,在雲託管關係型數據庫中默認內置,開箱即用。本質上,雲託管是將原本部署於 IDC 機房內物理服務器(也可能是虛擬出來的服務器)上的傳統數據庫軟件部署在雲主機上。
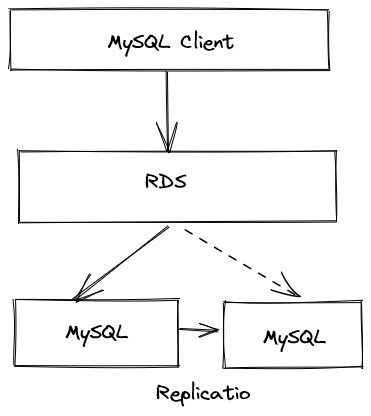
以 Amazon RDS 為例。其架構類似在底層的數據庫上構建了一箇中間層。這個中間層負責路由客户端的 SQL 請求發往實際的數據庫存儲節點。因為將業務端的請求通過中間層代理,所以可對底層的數據庫實例進行很多運維工作。這些工作由於隱藏在中間層後邊,業務層可以做到基本無感知。另外,這個中間路由層基本只是簡單的轉發請求,所以底層可以連接各種類型的數據庫。其缺點在於,它本質上還是一個單機主從架構,無法適用超過最大配置物理機容量、CPU 負載和 IO 的場景。尤其是移動互聯網時代,很多企業業務快速增長,數據庫併發量越來越高,也愈加重視可擴展性。
雲託管關係型數據庫雖然能部分實現“彈性”與“自愈”,但是這種方案存在資源利用率低、維護成本高、可用性低等問題。
以阿里云為例,阿里 PolarDB 之所以會誕生,原因之一是阿里雲數據庫團隊在業務中遇到很大挑戰:它們在雲上維護了龐大的 MySQL 雲服務(RDS)集羣,包含成千上萬個實例,面臨很多棘手問題:
雲服務一般使用雲硬盤,導致數據庫的性能沒物理機實例好,比如 I/O 延時過高;RDS 實例集羣很大,可能同時有很多實例在備份,從而佔用雲服務巨大的網絡和 I/O 帶寬,導致雲服務不穩定;大實例恢復需重建時,耗時太長,影響服務可用性;對需要讀寫分離,且要求部署多個只讀節點的用户,最明顯的感覺是每增加一個只讀實例,成本是線性增長。針對這些問題,可選解決方案是基於共享存儲,即數據庫共享存儲方案:RDS 實例(一般指一主一從的高可用實例)和只讀實例共享同一份數據。好處是實例故障或只讀擴展時,不用拷貝數據,只需新建只讀計算節點或把故障節點重新拉起來。並且,通過快照技術和寫時拷貝解決數據備份和誤操作恢復問題。不過,業內可用的共享存儲方案非常少,即使可用,性能也達不到要求。
因此,想解決雲託管關係型數據庫服務面臨的問題,必須改變思路,從架構入手。
架構“革命”,雲原生數據庫出現
要知道,過去三四十年,傳統關係型數據庫架構並未發生很大改變。
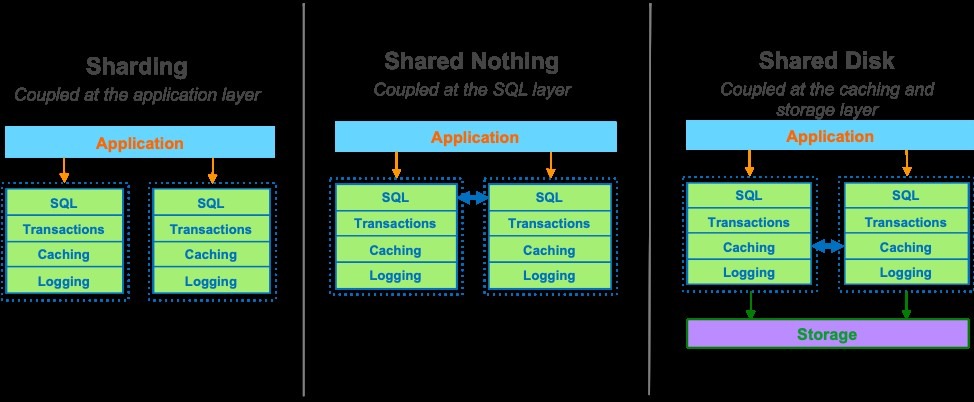
雖然在數據庫擴展方面存在不同的常規方法(如分區、無共享或共享磁盤等),但這些方法都基於同樣的基本數據庫架構。
正如亞馬遜雲科技在博客中寫道:“這些方法無法解決大規模性能、彈性和爆炸半徑問題,因為嚴密耦合型整體式堆棧的基本侷限性依然存在。”
為解決雲託管關係型數據庫面臨的問題,適應雲特性的雲原生數據庫就此誕生。雲原生數據庫完全為雲設計,能充分發揮雲的特點和優勢。
具體説來,雲原生數據庫有三大特點:第一,計算、存儲分離,由於對存儲與計算進行解耦合,實現了存儲與計算分離;第二,無狀態,計算節點無狀態或較少狀態;第三,存儲節點靈巧化,因採用小存儲塊方式組織副本,用以減少平均恢復時間,多副本共識算法,實現存儲的高可用與故障“自愈”能力。
目前,業內雲原生數據庫的代表有亞馬遜雲科技 Aurora、阿里 PolarDB、Azure CosmosDB、騰訊 TDSQL-C 等。
從上述各種雲原生數據庫的實踐和發展來看,我們總結出數據庫技術的幾個發展趨勢:第一,從scale up到 scale out。打個比方,這就像從傳統火車到動車一樣,scale out 不僅可以降低用户 TCO,而且該架構可以支撐系統擴展。尤其是如今的網絡已經從百兆邁向 100G、200G,協議從 socket 邁向 RDMA,因此 scale out 架構已經完全成為可能。其次,從物理機到雲原生。正如英特爾大數據首席工程師程從超所言,“我們原來的數據庫從物理機逐步走向雲平台,充分利用雲平台底層的分佈式存儲,以及計算資源池、存儲資源池的無限擴展能力,讓數據庫關注上層業務邏輯,與雲平台充分地結合,形成雲原生。”第三,從計算存儲分離到邏輯和執行引擎分離,走向Serverless架構。好處在於 CPU 可以動態擴展或縮容,為用户提供 on demand 服務。第四,數據計算將放在內存裏,數據存儲可能採用塊存儲、對象存儲。這樣,在計算過程中,避免和底層存儲“打交道”。最後是AIOps。通過 AI 技術自動的對前端業務系統進行調優。這可以在提高性能的同時,降低成本、預防 IT 事故,並提高業務的敏捷性。
發揮極致性能,雲原生數據庫的創新實踐
如今人工智能、低代碼、即時數據分析等技術的加速創新意味着雲上工作負載日趨多元化、動態化。如何應對這種變化,對雲原生數據庫是非常大的考驗。
在架構設計上,現有云原生數據庫最顯著的特點是將原本一體運行的數據庫拆解,讓計算、存儲資源完全解耦,使用分佈式雲存儲替代本地存儲,將計算層變成無狀態。雲原生數據庫將承載每層服務的資源池化,獨立、實時地伸縮資源池的大小,以匹配實時的工作負載,使得資源利用率最大化。
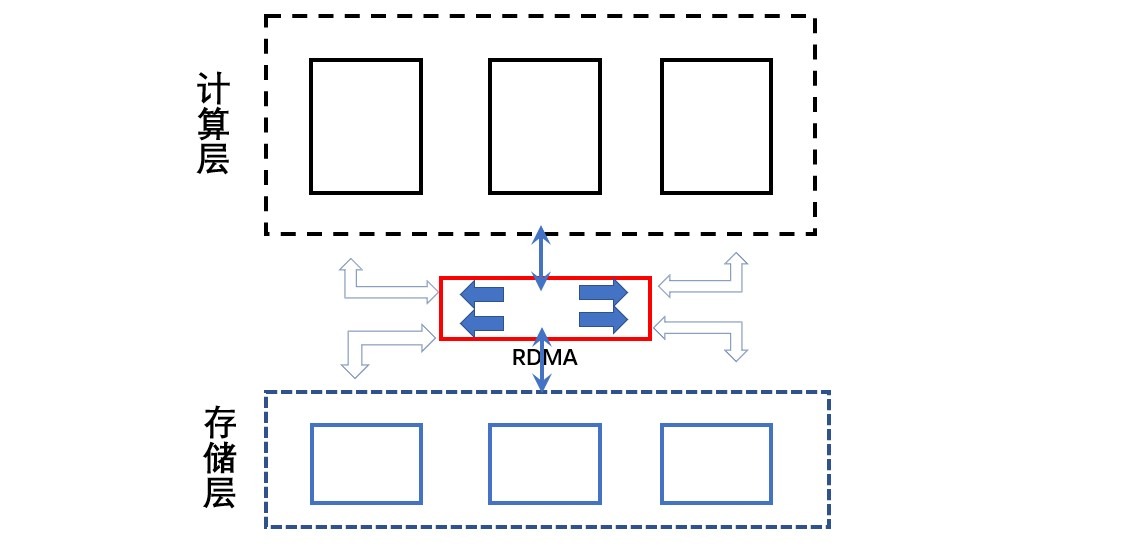
如上圖所示,大部分雲原生數據庫將 SQL 語句解析、物理計劃執行、事務處理等都放在一層,統稱為計算層。而將事務產生的日誌、數據的存儲放在共享存儲層,統稱為存儲層。在存儲層,數據採用多副本確保數據的可靠性,並通過 Raft 等協議保證數據的一致性。由此可見,高性能的分佈式存儲是雲原生數據庫實現的關鍵。
此外,計算節點與存儲節點之間採用高速網絡互聯,並通過 RDMA 協議傳輸數據,讓 I/O 性能不再成為瓶頸。值得注意的是,Amazon Aurora 並未使用 RDMA。
除架構外,雲原生數據庫還需要與硬件搭配,軟硬協同,才能發揮出最大潛力。新硬件的發展為數據庫技術注入了更多的可能性,充分發揮硬件性能成了所有數據庫系統提升效率的重要手段。雲原生數據庫拆解了計算、存儲,並利用網絡發揮分佈式的能力,在這三個層面都充分結合新硬件的特性進行設計。
通過騰訊雲 TDSQL-C 的實踐,我們可以深入瞭解雲原生數據庫的創新思路。
TDSQL-C 是騰訊雲自研的新一代雲原生關係型數據庫,採用計算和存儲分離的架構,所有計算節點共享一份數據,存儲容量高達 128TB,單庫最高可擴展至 16 節點,提供秒級的配置升降級、秒級的故障恢復和數據備份容災服務,兼具商用的性能和穩定性以及開源的靈活和低成本。
大體上,TDSQL-C 核心技術創新表現在兩方面:一方面是架構創新,另一方面是性能優化。
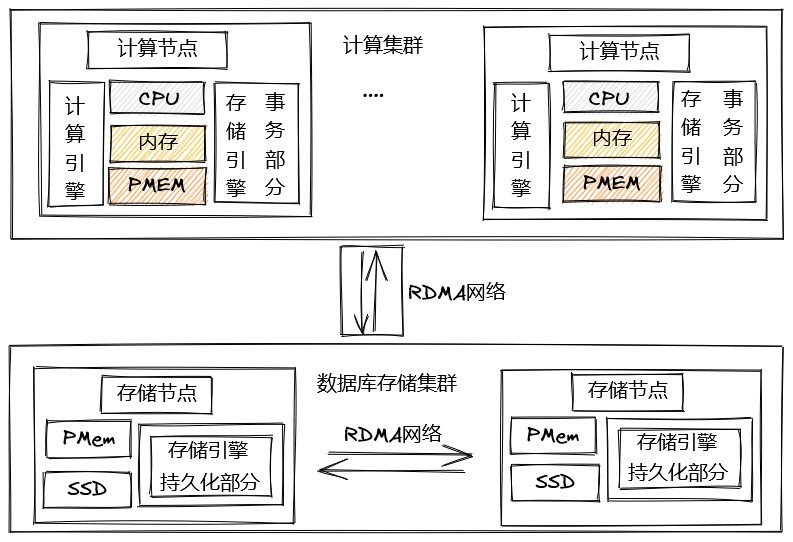
在架構上,TDSQL-C 存算分離,把計算層和存儲層進行解耦,做分層處理,分層過後通過池化讓計算、存儲的能力變得無限大。存算分離後,存儲可以使用集羣化的雲存儲,大大提升存儲上限,計算資源可以跨實例、跨物理機調度,按需使用,彈性大大增加。
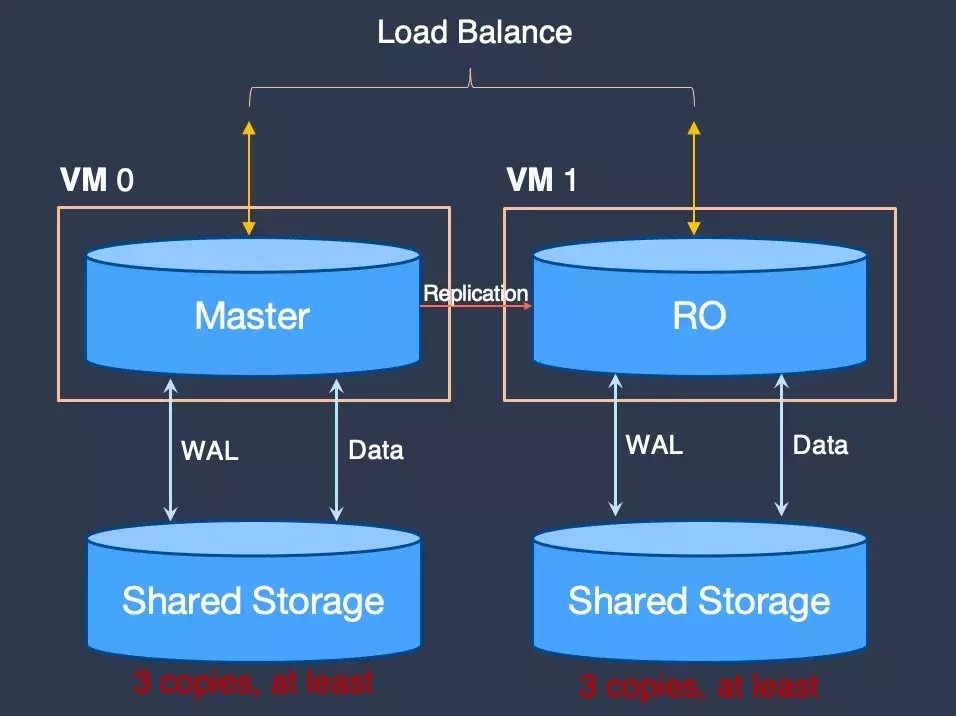
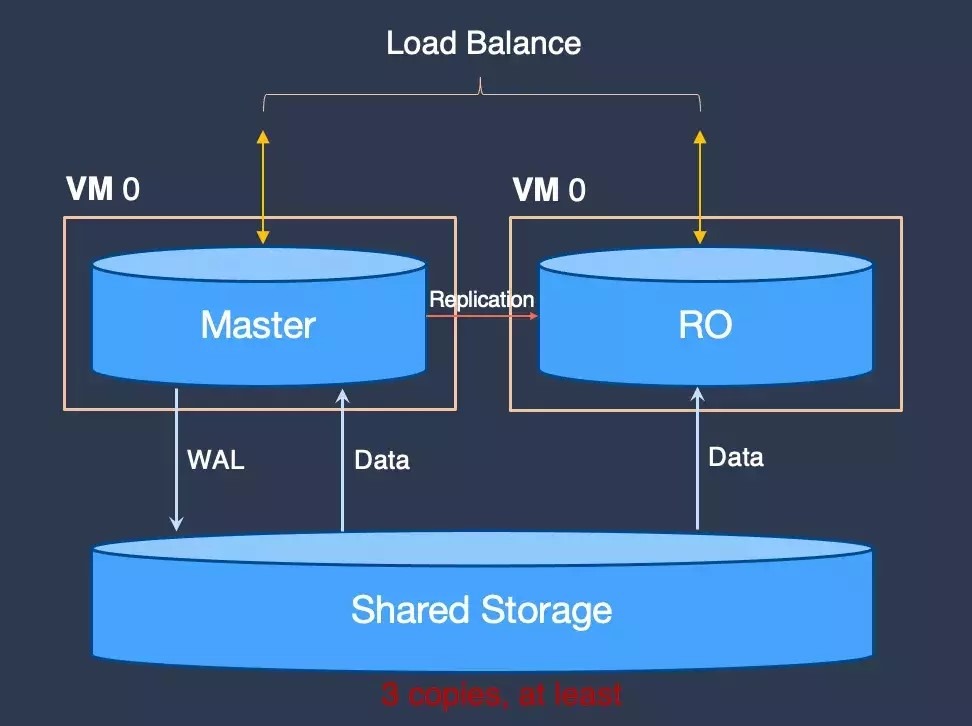
其次,TDSQL-C 共享存儲。如上圖所示,傳統上,Master 和 RO 雖然對應的是同一份數據,但實際存儲時有六份數據。而每增加一個 RO 節點,就會多出三份數據,這也讓整個集羣的存儲副本數近一步放大。並且,高吞吐的數量使網絡問題成為瓶頸,在共享存儲側也有大量網絡浪費。而 TDSQL-C 採用共享存儲方式,如下圖所示,Master 和 RO 是基於一份數據放在共享存儲中,RO 只從共享存儲中讀取所需的 page,不需要寫入存儲,並且 RO 可以從主庫接收 WAL 在緩存中重放,以此保持緩存中 Page 持續更新。如此,TDSQL-C 就解決了業務容量和計算節點的擴容問題。
第三,TDSQL-C 使用“log is database”方案,把一部分數據庫計算邏輯下沉到存儲層完成, 實現網絡數據傳輸減少 90%+,計算層資源更聚焦於 SQL 處理,提升系統性能,分佈式刷髒基本上規避 BP 刷髒的影響,加快了系統啓動速度。
除了架構創新,TDSQL-C 在性能優化方面,不僅很好地利用雲原生數據庫自身特點,而且充分結合英特爾產品和技術,實現極致性能。
具體而言,騰訊雲 TDSQL-C 團隊首次深入底層軟件的設計層面,利用英特爾 oneAPI 收集軟件運行過程中的函數開銷等,通過反饋優化技術進行再編譯。這樣,TDSQL-C 性能得到進一步提升,在大部分用户場景下都有更好的效果,甚至在某個方面,性能提升可以達到 85%。
在這個過程中,英特爾 oneAPI 發揮着重要作用。作為一種開放、統一的編程模型,oneAPI 用於 CPU 和加速器,並支持多個廠商的計算機架構。
其次,為優化讀取性能和寫入性能,騰訊雲 TDSQL-C 團隊基於英特爾傲騰持久化內存設計了一個二級緩存方案,因為由計算和存儲分離帶來的遠程 I/O 成為不小的挑戰。同時,根據數據温度,智能存儲分層:熱數據放在內存,冷數據放在磁盤。在使用傲騰持久化內存後,團隊重新定義温數據,實行低冗餘度存儲。在計算節點,通過對温數據進行緩存,團隊極大提高了數據庫在 IO 密集型場景下的訪問速度。
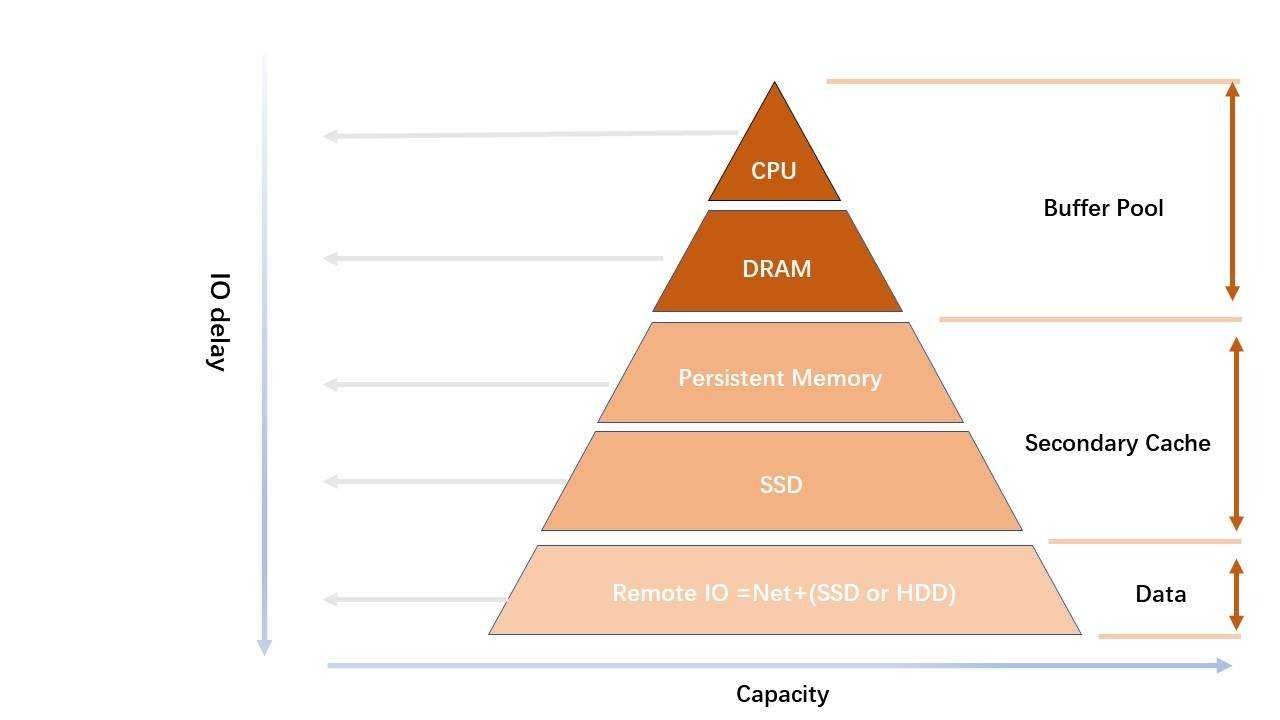
如上圖所示,TDSQL-C 團隊在遠程存儲和 buffer pool 之間實現了二級緩存層,它使用本地存儲介質。從 buffer pool 中淘汰的頁面緩存在該層——實際上並非淘汰,而是把從buffer pool 移出的數據緩存到本地的 SSD存儲或AEP存儲。下次訪問該數據時,滿足一定的條件下,可以直接從本地讀取,這樣就能最大限度地降低網絡 I/O 的消耗。
通過與 英特爾 技術團隊的聯合創新,結合最新一代英特爾® 至強® 可擴展處理器以及英特爾® 傲騰™ 持久內存(PMem)的硬件特性,TDSQL-C 團隊重構了二級緩存設計方案,在IO bound 場景中的讀寫性能提升2倍以上。
同時,TDSQL-C 團隊攜手英特爾多方位優化存儲方案設計,如加入輪詢、算法優化、消除鎖等機制,優化存儲引擎等,並引入由英特爾提供的 SPDK 開發套件,優化 NVMe 固態盤的 IOPS 和時延性能。並且,對網絡架構全面升級,TDSQL-C 新版本採用全鏈路 RDMA 網絡,依靠零拷貝、內核旁路、無 CPU 干預等特性,進一步優化了存儲層與計算層以及存儲層多副本間關鍵路徑的系統性能,降低請求延遲最高達 80%,使 I/O 性能不再成為瓶頸。
簡言之,TDSQL-C 新版本對雲原生數據庫場景進行了大量優化,極大提升了數據庫性能,能更好地滿足企業對數據庫性能的極致追求。
從騰訊雲與英特爾合作的創新實踐中,我們發現未來的數據庫將步入全棧優化時代,從硬件平台優化到架構層優化再到上面的應用層優化。所謂“軟件優化三年不如硬件更新一代”,比如算力上,一定是充分利用 CPU 最底層的指令集和最新的加速器。據悉,最新的英特爾® 至強® 可擴展處理器(Sapphire Rapids)一代,已經從單純的提高主頻和增加核數逐步走向更多的加速器,包括 QAT 和 SGX 以及 DSA 等。在英特爾大數據首席工程師程從超看來,這些新的加速器會對數據庫的整個優化設計帶來很大的影響,這也是未來需要充分重視的。
以硬件到基礎設施的優化為例,算力優化方面,需採用最新的處理器和最新的軟件版本,並選擇高主頻的核。同時,還要避免 NUMA,即非一致性內存訪問,因為它對數據庫的性能影響較大。並且,可以充分利用底層 CPU 最新的指令集,如 SIMD。在存儲優化方面,實行數據封層存放,把 redo log 和 binlog 等日誌存儲在低延時設備上,以及通過 PMEM 在物理存儲(HDD、SSD、NAND)和內存間增加一個 cache 層,作為應用的熱數據存儲,從而擴展內容容量,彌補存儲性能。為進一步優化存儲,企業還可以利用 LSM 的多版本管理機制增強系統的性能。網絡優化上,可以採用 ADQ,通過 SPDK/DPDK 等技術提高網絡性能,繞過 kernel space 的性能瓶頸。
寫在最後
隨着數字化不斷發展,數據的價值正不斷顯現。毫無疑問,圍繞數據的生產、存儲和消費構成的系列服務,將成為數字經濟社會的核心價值鏈條,而其背後的支撐正是數據庫。這也意味着,數據庫將比以前發揮更大的作用。
從傳統關係型數據庫到雲託管關係型數據庫再到雲原生數據庫,數據庫不斷變革。我們看到,當企業業務從本地到上雲再到原生髮展時,雲原生數據庫也將成為雲時代數據庫的主角之一。作為支撐企業業務的關鍵 IT 基礎設施,雲原生數據庫只有發揮出最大的價值,才能推動業務發展。而這需要不斷創新,不僅是先進的架構設計,而且與其他前沿的軟硬件產品和技術搭配,軟硬協同,從而實現最佳效用。
想了解更多關於數據庫的知識嗎?點擊鏈接:https://bizwebcast.intel.cn/wap/eventstart.aspx?eid=348&tc=9a9ntqmfw3&frm=wechatkol,觀看英特爾聯合國際學術期刊《科學》共同推出的“架構師成長計劃”第九期《軟硬一體實現數據庫性能優化》,瞭解更多技術乾貨~