狡兔務必三窟:阿里雲香港可用區C宕機的教訓_風聞
任易-清华大学硕士-微信公众号「任易」2022-12-27 09:29
自12月18日阿里雲香港可用區C因為機房水冷機組出現故障,導致一次阿里雲歷史上最長的宕機後,官方終於在聖誕節那天,出具了一份非常翔實的調查報告《關於阿里雲香港Region可用區C服務中斷事件的説明》,稱得上是實事求是面對問題了。
我從業十五年,參與建設過4000個節點的私有云,也搞過機房裝修和上架,還有一點運維經驗,算是有相關經驗,跟大家討論一下以後自家單位的容災應該怎麼做吧。
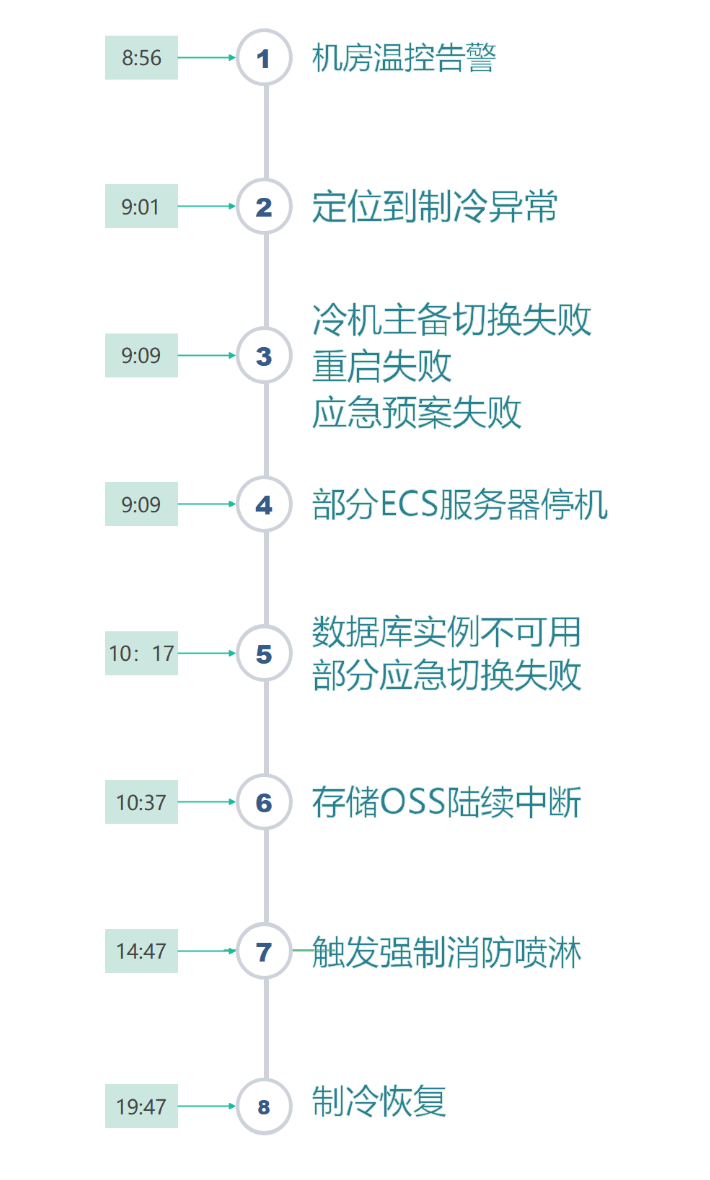
大家先看這次阿里雲宕機事故的重點時間線,8點56就發現機房温控告警了,然後9點01就正確定位到製冷異常了。這個問題阿里雲沒有隱瞞的必要,因為機房突然升温,只能是空調(冷機)故障了。
這個事故的主要原因,就是因為製冷設備整整10個小時不能恢復工作,機房升温太快,工程師為了保護數據,只能逐步關機。

次要原因是,在關機後還是有某個包間因為温度過高導致噴淋裝置啓動。手機和電腦不能進水都已經是常識了,服務器上淋了水那還得了?

再次原因,就是阿里雲香港Reigon的架構設計,同樣沒有遵循自己提到的「全鏈路多可用區的業務架構設計」,新擴容的ECS管控系統啓動時依賴的中間件服務部署在可用區C機房,導致可用區C一旦宕機,擴容服務也啓動不了。相信後續阿里雲一定會全網巡檢,整體優化多可用區高可用設計,避免製造單點故障,類似依賴OSS單AZ和中間件單AZ的問題,再次出現就説不過去了。


第四個原因,是對於雲服務來説,高可用架構能夠保障是某幾台物理服務器(ECS、OSS、RDS)因為故障宕機時,原來的應用可以漂移到同一個AZ(可用區)的其他服務器上,保證服務的連續性和數據的可用性。但是原有複雜的分佈式架構在一個AZ(可用區)整體出現網絡、服務器、存儲全部下線的時候,國內沒有廠家敢於承諾100%實現全量無傷漂移到其他可用區,或者其他機房的。
打個比方,如果把中國大陸看成一個CN可用區,那麼當武漢或者上海出現疫情的時候,是能夠把病人疏散到其他城市去治療,緩解自身醫療壓力的。但是當舉國上下都遭遇新冠的時候,病人還能往哪送?阿里雲這次遭遇的是一個AZ(可用區)整體下線,裏面近千個機櫃、上萬台設備的數據,又能切換到哪裏?
第五個原因,是對極小概率事件的應急預案,是沒法考慮得那麼周詳的,甚至完全考慮不到。比如誰能提前考慮服務器被噴淋裝置噴水導致損壞的場景?誰能考慮一個主備配置4+4的水冷機組,能夠同時出現故障,修好卻需要10個小時?
第六個原因,是對於一個巨型系統來説,有能力搞清楚裏面所有的細節的總工程師,一定在新項目上,絕不是去搞運維浪費人才。其他的成員都是分模塊承擔任務的,他們只能選擇信任其他模塊。例如搞數據庫(RDS)的同學關注的是支持跨區遷移,誰能考慮到跨區遷移依賴的反向代理竟然不是跨區高可用的,結果大部分數據庫成功遷移了,但是香港可用區C一旦宕機,依賴這個反向代理的的數據庫就遷移不了。

所以,我來點評一下。
1、假的主備冷機系統
阿里雲宕機的主要原因是機房主備水冷機組共用了同一個水路循環系統,存在單點故障,修這個就用了10個小時。然而這個機房還只是阿里雲租的。查了一下阿里雲香港C區所在的機房,應該是下圖的香港粉嶺安匯中心/安樂電話機房。(來自知乎@香港sim精神小夥[1])

這個機房原來是PCCW電訊盈科的,然後Vantage(數據中心園區提供商,其母公司是紐交所上市公司,代碼DBRG)在2021年剛剛收購了電訊盈科的數據中心。
《Vantage Data Centers 完成對 PCCW DC 的收購,將其一流的超大規模數據中心平台帶到香港和吉隆坡 - Vantage Data Centers[2]》
這兩棟機房同屬Vantage的HKG1園區,大概機房參數如下:
所以阿里雲也是倒黴,租了個機房還換了東家。換了東家之後,最瞭解情況的中基層領導很可能已經被掃地出門了,Twitter不就是這樣麼?所以故障響應就會不及時。
修個水冷機組還要用10個小時,其中真正有效的時間就是排水補氣的3小時,除此之外,定位原因怎麼要用3個半小時的?這個水冷機組的服務商也挺廢物的。
定位原因的3個半小時,就是設備維護商趕到現場的時間。一個重要數據中心的冷機壞了,香港的設備維護上用了3個
半
小時才
到
達現場,這種服務水平和響應速度極不可靠,從深圳到廣州也用不了三個小時吧。
另外,解鎖羣控邏輯,手動啓動4台冷機,竟然要用3小時32分,也説明服務商的工程師對這個系統根本都不熟,大概率是照着操作手冊現學現賣的。

2020年,微軟Azure位於美國東部的數據中心發生服務中斷,持續六小時。微軟披露説,冷卻系統故障是導致這次停機的原因,發生故障的樓宇自動化控制導致氣流減少,隨後整個數據中心的温度峯值阻礙了網絡設備的性能,使計算和存儲實例無法訪問。但是微軟的信息披露沒有阿里雲這一次這麼翔實,這一點還是要給阿里雲的實事求是點個贊。
2021年11月,網易遊戲機房大規模服務器宕機,原因同事是機房過熱,空調重新開機也沒有解決問題。但幸好這只是遊戲服務器,玩家是可以接受的。但是大陸的服務更到位,網易的宕機只用了3小時就恢復了。
2022年夏天,倫敦的谷歌雲及甲骨文數據中心出現製冷系統故障,導致數據中心氣温升高,產生宕機。甲骨文的是系統自動採取保護措施關閉作業,於是業務宕機;谷歌的是温度過高導致存儲故障,引起虛擬機宕機,然後谷歌也關閉了一部分機器。
2、數據中心機房用噴淋
所以根據《建築設計防火規範》GB50016規定,重要機房、配電房是需要做氣體自動滅火,這是中國大陸的規定。
但是我國的國標之間也有衝突,比如根據《《數據中心設計規範》GB 50174-2017》,只要數據中心的系統在其他數據中心內有承擔相同功能的備份系統時,也可以設置自動噴水滅火系統。這個規範的主編單位是中國電子工程設計院。

我在2010年參與了蘇州國科數據中心Tier-IV機房項目,當時是東北亞最高端的機房,那時候我們用的就是七氟丙烷氣體滅火。參見《運營環境 蘇州國科數據中心[3]》

為什麼要用對人體有微毒性的七氟丙烷滅火,而不是用乾粉、氣水霧或者噴淋方式滅火呢?因為電子設備就沒有不怕水的,乾粉也會對設備造成傷害。順口再説一句,國外聲稱他們重視員工生命,所以建議少用這種有毒的氣體滅火方式。這方面很多公司都參考了美國消防協會NFPA的標準,國際某個頭部的雲廠商也有不少這類設計。
我參與的項目還是經受住了考驗,2022年10月13日,蘇州國科數據中心A2棟建築屋頂備用冷卻塔起火,半小時後撲滅,但是建築內的蘇州超算中心數據機房安然無恙,數據沒受影響,説明氣體滅火還是極有必要的,要不然超算中心就無了。

當然,氣體滅火也有弊端,比如對空間有要求,大於3600平方就達不到消防效果,這些在國標裏都有提及。此外氣體的儲備量也是有限制的。
這個機房原來是PCCW電訊盈科的,也是資深數據中心運營商,真的會這麼離譜麼?《電訊盈科PowerBase方案[4]》裏面也寫的非常清楚,數據中心對製冷機組、供電機組全年無休監控。現在看來,製冷機組的監控明顯失靈,反而是機房先升温告警,然後才找到了製冷機組的問題。

雖然這次故障的源起是機房。但硬件設備的能力和可靠性是有限的,這就是為什麼有云計算的原因。我認為,我們需要提升數據中心設施的可靠性,但不應該只專注於此。雲計算不應當如此嚴重的依賴於單個機房,阿里雲更應該做的是提升雲產品的穩定性,加強整個AZ層面的災備演練。
我們該怎麼自保?
IDC圈盤點了近幾年的前十大數據中心災難事故,《盤點:近年數據中心十大災難事件_機房_火災_服務器[5]》,包括2020年韓國SK公司數據中心火災,影響了3.2萬個服務器;2021年3月,歐洲雲計算巨頭OVH在法國的數據中心嚴重火災,一共4座數據中心,有一座被完全燒燬。導致法國360個政府、企業與公共事業網站直接癱瘓。

2021年,河南多機房因汛情斷電,還有位於河南的數據中心出現機房進水情況;2022年穀歌數據中心電氣爆炸,影響了40多個國家的1338台服務器。這種事一篇稿子都寫不下。

所以,重要應用和數據,請務必做到狡兔三窟,一定要充分考慮雲主機的單點故障,做好多可用區的高可用,做好數據的容災和備份;千萬不要全盤相信連鎖型的自動化操作。
在極端情況下,全自動化操作容易導致出現多米諾骨牌一樣的連鎖反應。比如這次阿里雲香港機房的冷機就是羣控啓動的,死活就啓動不起來。因為再完備、再安全、再可靠的自動化方案,哪怕平時運轉非常正常,趕上寸勁和巧合,總會出現無法預計的問題。
人體的設計也有這種Bug,當免疫系統在體內殺新冠病毒殺瘋了的時候,他才不會管人體是否受得了,直接燒到42度,或者免疫風暴走起。反正新冠病毒總得死,但是人會不會死,免疫系統不在乎。
自動噴淋滅火系統也是,反正只要温度過高我就要噴水,我的任務是保證火被撲滅了,但是物理服務器進水會不會損壞,自動噴淋滅火系統不在乎。特斯拉也是,他的自動控制系統只負責接管車輛駕駛,至於是不是剎車失敗,會不會造成人員傷亡,自動控制系統不在乎。
我的羣暉NAS有100T的容量,其中有5T工作文檔數據,算是我十五年來攢下的命根子。兩個月之前,我在三天裏連續壞了兩塊硬盤,真的是嚇出一身冷汗;我做了Raid5,如果只壞一塊盤,數據是可以恢復的;但是如果同時壞了兩塊盤,那我事務的數據就全game over了。

在這件事情之後,我直接搞了個同城災備和異地容災。同城災備是我買了一塊16T的硬盤,接在羣暉NAS上,把我的重要數據每日備份;異地容災就是一年幾百塊買了阿里雲盤,映射成WebDAV,也是每天備份我的重要數據,這樣才能保證數據可靠性。
對於應用服務來説,一定要考慮好安全性,比如反親和性,兩台虛擬機不要放在同一台物理機上;比如做好鏡像備份和容器的編排,在異地設置好備份,保證必要的時候可以快速在異地拉起容器;比如做好數據庫的異步同步,基本保證數據的一致性,在應用裏不要直接寫死數據庫的IP地址,還是要用域名指向。
比如2019年3月,騰訊雲上海南匯機房的光纜被施工挖斷,等於所有網絡都不通了,暖暖、QQ 飛車,王者榮耀,吃雞等 90 多個服務受到影響,這種問題就屬於意外,也沒法問責雲廠商。
所以,如果老闆問為什麼要花這麼多資金和人力來搞容災,那就可以告訴老闆,不管是谷歌雲、甲骨文、微軟雲、阿里雲、還是騰訊雲,全都出過故障,只要是服務,就有不可用的時候,所以靠誰不如靠自己。像阿里雲這次故障中,在架構層面設計了多可用區高可用方案的客户,就完全沒有受到影響,當然,安全是需要額外成本的。
每個公司都是自己業務應用和數據的第一責任人,不應該也不能把希望全部寄託在雲廠商身上。
比如2021年3月,雲廠商OVH在法國的數據中心起火之後,遊戲《Rust》表示,25台歐洲服務器完全損毀,沒有備份,數據無法被修復。你説這個數據丟失的主責是雲廠商OVH,還是遊戲運營商呢?像阿里雲香港機房本月的可用時間大約是98%左右,也會按照規則賠償25%的月費用,但是用户的業務穩定和數據安全,能全部依賴於供應商麼?當然不能。
阿里雲這一次的信息披露,算是這麼多家雲廠商中最坦誠、最詳盡的了,也是給各個企業一個充分的經驗借鑑,讓大家在容災方案設計時,除了保證應用和數據的高可用,還要考慮中間件的高可用;除了考慮自身的架構設計,也要考慮租賃的數據中心的製冷和防火設計者有沒有腦血栓
畢竟人生中充滿了黑天鵝事件,我們除了積極應對風險,還能怎麼辦呢?狡兔務必三窟就是唯一的答案。
參考資料
[1]
香港sim精神小夥: https://www.zhihu.com/people/15217944045
[2]
Vantage Data Centers 完成對 PCCW DC 的收購,將其一流的超大規模數據中心平台帶到香港和吉隆坡 - Vantage Data Centers: https://vantage-dc.com/news/vantage-data-centers-finalizes-pccw-dc-acquisition-to-bring-its-best-in-class-hyperscale-data-center-platform-to-hong-kong-and-kuala-lumpur/
[3]
運營環境 蘇州國科數據中心: http://m.sisdc.com.cn/operatingEnvi.html
[4]
電訊盈科PowerBase方案: https://www.pccwsolutions.com/getitem.php?id=652543d8-a258-4127-bee4-483bf69054c5
[5]
盤點:近年數據中心十大災難事件_機房_火災_服務器: https://www.sohu.com/a/609305338_210640