自動化所發佈多模態同步語言神經影像數據集
【環球網科技綜合報道】10月9日消息,據中國科學院自動化研究所消息,中國科學院自動化研究所自然語言處理研究組歷時近兩年,採集處理完成了漢語同步多模態神經影像數據集,並於近日正式對外發布。
據介紹,該數據集是當前國際上最大規模的用於腦語言處理機制研究的多模態同步神經影像數據集,針對12個被試收聽約6個小時故事時的功能核磁共振(fMRI)、腦磁圖(MEG)、每個被試的T1/T2加權結構像、擴散磁共振成像(diffusion MRI)和靜息態核磁共振(resting MRI)數據採集整理而成,採集流程如圖1所示。
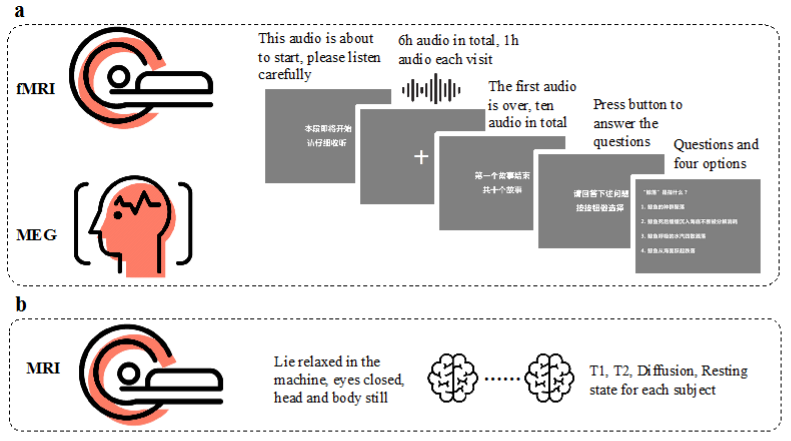
此外,為了便於利用計算模型進行腦語言處理機制的研究,所有故事材料都由人工標註了句法結構樹,計算了文本中每個詞彙對應的音頻時間點、詞頻以及多種不同字和詞彙的向量,如圖2所示。
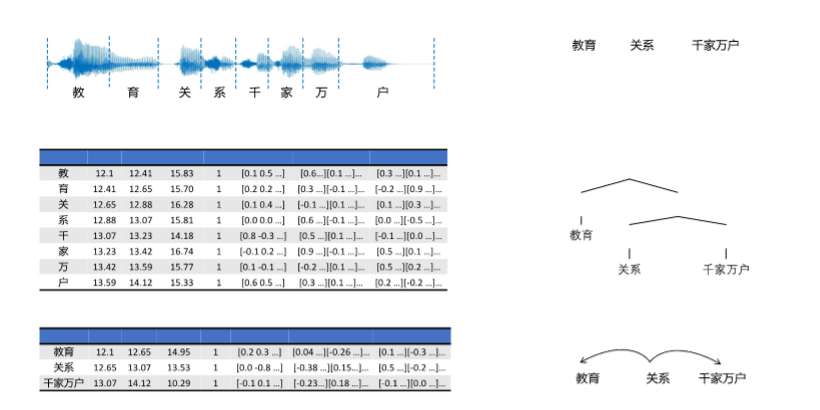
該數據集的公開發布可以為全方位研究大腦在真實場景下理解詞彙、短語和句子時如何調動不同腦區以及不同腦區之間如何協同工作等科學問題提供重要支撐。相關論文發表於Nature子刊Scientific Data。