谷歌用Bard打響了Chat GPT的第一槍,百度版Chat GPT 何時出爐?_風聞
蓝海大脑GPU服务器-水冷服务器、大数据一体机、图数据一体机02-08 17:38

百度 | Bard | Chat GPT
谷歌 | RLHF| ERNIE Bot
隨着深度學習、高性能計算、數據分析、數據挖掘、LLM、PPO、NLP等技術的快速發展,Chat GPT得到快速發展。Chat GPT是OpenAI開發的大型預訓練語言模型,GPT-3模型的一個變體,經過訓練可以在對話中生成類似人類的文本響應。
為了佔據ChatGPT市場的有利地位,百度谷歌等巨頭公司也在運籌帷幄,不斷發展。
作為國內液冷服務器知名廠商,藍海大腦Chat GPT深度學習一體機實現了軟硬協同的深度優化,在分佈式存儲加速、智能網絡加速等關鍵性技術上取得重要突破,提供更加出色的雲系統性能。採用NVMe專屬定製的加速引擎,發揮NVMe極致性能,全棧的數據傳輸通道實現分佈式存儲副本數據傳輸零損耗。同時,升級智能網絡引擎,通過更多類型網卡進行虛擬化調度,釋放CPU性能,可以使計算資源節約最多達90%,網絡轉發速率提高數倍,進一步提升平台性能深受廣大Chat GPT 工作者的喜愛。

深度學習一體機
ChatGPT的訓練過程
在整體技術路線上,Chat GPT引入了“手動標註數據+強化學習”(RLHF,從人的反饋進行強化學習)來不斷Fine-tune預訓練語言模型。主要目的是讓LLM模型學會理解人類命令的含義(比如寫一篇短文生成問題、知識回答問題、頭腦風暴問題等不同類型的命令),讓LLM學會判斷對於給定的提示輸入指令(用户的問題)什麼樣的回答是優質的(富含信息、內容豐富、對用户有幫助、無害、不包含歧視信息等多種標準)。
在“人工標註數據+強化學習”的框架下,具體來説,Chat GPT的訓練過程分為以下三個階段:
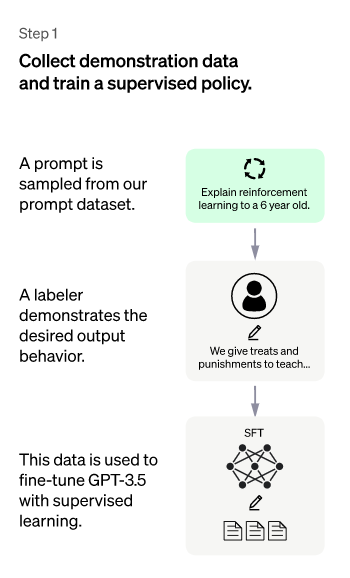
一、第一階段:監督調優模型
就 GPT 3.5 本身而言,雖然功能強大,但很難理解不同類型人類的不同指令所體現的不同意圖,也很難判斷生成的內容是否是高質量的結果。為了讓GPT 3.5初步理解指令中包含的意圖,將隨機選擇一批測試用户提交的prompt(即指令或問題),由專業標註人員對指定指令提供高質量的答案,然後專業人員標註數據對GPT 3.5模型進行微調。通過這個過程,可以假設 GPT 3.5 最初具有理解人類命令中包含的意圖並根據這些意圖提供相對高質量答案的能力。
第一階段的首要任務是通過收集數據以訓練監督的策略模型。
**數據採集:**選擇提示列表,要求標註者寫出預期結果。Chat GPT 使用兩種不同的prompt 來源:一些是直接使用註釋者或研究人員生成的,另一些是從 OpenAI 的API 請求(即來自 GPT-3 用户)獲得的。儘管整個過程緩慢且昂貴,但最終結果是一個相對較小的高質量數據集(大概有 12-15k 個數據點),可用於調整預訓練語言模型。
**模型選擇:**Chat GPT 開發人員從 GPT-3.5 套件中選擇預訓練模型,而不是對原始 GPT-3 模型進行微調。使用的基礎模型是最新版本的text-davinci-003(用程序代碼調優的GPT-3模型)。
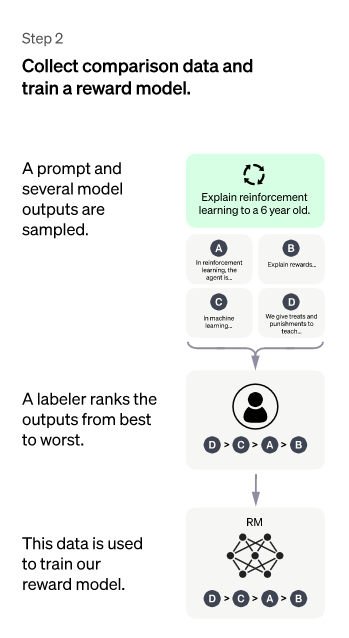
二、第二階段:訓練回報模型
這個階段的主要目標是通過手動標註訓練數據來訓練回報模型。具體是隨機抽取用户提交的請求prompt(大部分與第一階段相同),使用第一階段Enhancement的冷啓動模型。對於每個prompt,冷啓動模型都會生成K個不同的答案,所以模型會生成數據<prompt, answer1>, <prompt, answer2>….<prompt, answerX>。之後,標註者根據各種標準(上述的相關性、富含信息性、有害信息等諸多標準)對X個結果進行排序,並指定X個結果的排名順序,這就是這個階段人工標註的數據。
接下來,使用這個排名結果數據來訓練回報模型。使用的訓練方式實際上是常用的pair-wise learning to rank。對於 X 排序結果,兩兩組合起來形成一個訓練數據對,ChatGPT 使用 pair-wise loss 來訓練 Reward Model。RM 模型將 <prompt, answer> 作為輸入,並提供獎勵分數來評估答案的質量。對於一對訓練數據,假設 answer1 排在 answer2 之前,那麼Loss函數驅動 RM 模型比其他得分更高。
總結一下:在這個階段,首先冷啓動後的監控策略模型對每個prompt生成X個結果,並根據結果的質量從高到低排序,並作為訓練數據,通過pair-wise learning to rank模式來訓練回報模型。對於學好的 RM 模型來説,輸入 <prompt, answer>,並輸出結果質量分數。分數越高,答案的質量就越高。其工作原理是:
選擇prompt列表,SFT 模型為每個命令生成多個輸出(4 到 9 之間的任何值);
標註者從最好到最差對輸出進行排名。結果是一個新標記的數據集,其大小大約是用於 SFT 模型的確切數據集的 10 倍;
此新數據用於訓練 RM 模型。該模型將 SFT 模型的輸出作為輸入,並按優先順序對它們進行排序。
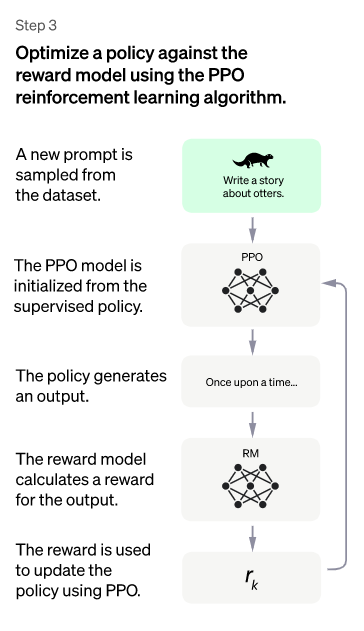
三、第三階段:使用 PPO 模型微調 SFT 模型
本階段不需要人工標註數據,而是利用上一階段學習的RM模型,根據RM打分結果更新預訓練模型參數。具體來説,首先從用户提交的prompt中隨機選擇一批新的指令(指的是不同於第一階段和第二階段的新提示),PPO模型參數由冷啓動模型初始化。然後對於隨機選取的prompt,使用PPO模型生成答案,使用前一階段訓練好的RM模型,提供一個評價答案質量的獎勵分數,即RM對所有答案給出的整體reward。有了單詞序列的最終回報,每個詞可以看作一個時間步長,reward從後向前依次傳遞,由此產生的策略梯度可以更新PPO模型的參數。這是一個標準化的強化學習過程,目標是生成符合 RM 標準的高質量答案。
如果我們不斷重複第二和第三階段,很明顯每次迭代都會讓 LLM 模型變得越來越強大。因為在第二階段,RM模型的能力通過人工標註數據得到增強,而在第三階段,增強的RM模型更準確地評估新prompt生成的答案,並使用強化學習來鼓勵LLM模型學習新的高質量內容 ,這類似於使用偽標籤來擴展高質量的訓練數據,從而進一步增強LLM模型。顯然,第二階段和第三階段相輔相成,這就是為什麼連續迭代的效果會越來越大。
不過小編認為,在第三階段實施強化學習策略並不一定是Chat GPT模型如此出色的主要原因。假設第三階段不使用強化學習,而是採用如下方法:與第二階段類似,對於一個新的prompt,冷啓動模型可能會生成X個答案,由RM模型打分。我們選擇得分最高的答案組成新的訓練數據<prompt, answer>,進入fine-tune LLM模型。假設換成這種模式,相信效果可能會比強化學習更好。雖然沒那麼精緻,但效果不一定差很多。不管第三階段採用哪種技術模型,本質上很可能是利用第二階段學會的RM,從LLM模型中擴展出高質量的訓練數據。
以上是Chat GPT訓練過程。這是一個改進的 instruct GPT。改進主要是標註數據收集方法上的一些差異。其他方面,包括模型結構和訓練過程,基本遵循instruct GPT。估計這種Reinforcement Learning from Human Feedback技術會很快擴散到其他內容創作方向,比如一個很容易想到的方向,類似“A machine translation model based on Reinforcement Learning from Human Feedback”等。不過個人認為在NLP的內容生成的特定領域採用這項技術並不是很重要,因為Chat GPT本身可以處理很多不同類型的任務,基本上涵蓋了NLP產生的很多子領域。因此,對於NLP的某些細分領域,單獨使用這項技術的價值並不大,其可行性可以認為是經過Chat GPT驗證的。如果將該技術應用到其他模式的創作中,比如圖像、音頻、視頻等,這或許是一個值得探索的方向。可能很快就會看到類似“A XXX diffusion model based on Reinforcement Learning from Human Feedback”之類的內容。
Chat GPT的不足之處
儘管Chat GPT好評如潮且商家採用率不斷提高,但仍然存在許多缺點。
一、回答缺少連貫性
因為Chat GPT只能基於上文且記憶力差,傾向於忘記一些重要的信息。研究人員正在開發一種 AI,可以在預測文本中的下一個字母時查看短期和長期特徵。這種策略稱為卷積。使用卷積的神經網絡可以跟蹤足夠長的信息以保持主題。
二、有時會存在偏見
因為 Chat GPT 訓練數據集是文本,反映了人類的世界觀,這不可避免地包含了人類的偏見。如果企業使用 Chat GPT 撰寫電子郵件、文章、論文等無需人工審核,則法律和聲譽風險會很大。例如,帶有種族偏見的文章可能會產生重大後果。
Facebook 的 AI 負責人 Jerome Pesenti 使用 Kumar的 GPT-3 生成的推文來展示輸出如何根據需要使用“猶太人、黑人、女性或大屠殺”等詞,其輸出可能會變得多麼危險。Kumar 認為這些推文是精心挑選的,Pesenti 同意,但回應説“產生種族主義和性別歧視的輸出不應該那麼容易,尤其是在中立的情況下。”
另外,對GPT-3文章的評價也有失偏頗。人類寫作文本的風格會因文化和性別而有很大差異。如果 GPT-3 在沒有校對的情況下對論文進行評分,GPT-3 論文評分者可能會給學生更高的評分,因為他們的寫作風格在訓練數據中更為普遍。
三、對事實理解能力較弱
Chat GPT不能從事實的角度區分是非。例如,Chat GPT 可能會寫一個關於獨角獸的有趣故事,但 Chat GPT 可能不瞭解獨角獸到底是什麼。
四、錯誤信息/虛假新聞
Chat GPT可能會創作逼真的新聞或評論文章,這些文章可能會被壞人利用來生成虛假信息,例如虛假故事、虛假通訊或冒充社交媒體帖子,以及帶有偏見或辱罵性的語言。或垃圾郵件、網絡釣魚、欺詐性學術論文寫作、煽動極端主義和社會工程藉口。Chat GPT 很容易成為強大宣傳機器的引擎。
五、不適合高風險類別
OpenAI 聲明該系統不應該用於“高風險類別”,例如醫療保健。在 Nabra 的博客文章中,作者證實 Chat GPT 可以提供有問題的醫療建議,例如“自殺是個好主意”。Chat GPT 不應在高風險情況下使用,因為儘管有時它給出的結果可能是正確的,但有時會給出錯誤的答案。在這個領域,正確處理事情是生死攸關的問題。
六、有時產生無用信息
因為 Chat GPT 無法知道哪些輸出是正確的,哪些是錯誤的,並且無法阻止自己向世界傳播不適當的內容。使用此類系統生成的內容越多,互聯網上產生的內容污染就越多。在互聯網上尋找真正有價值的信息變得越來越困難。由於語言模型發出未經檢查的話語,可能正在降低互聯網內容的質量,使人們更難獲得有價值的知識。
谷歌、百度應對OpenAI所採取的措施
近日,Chat GPT聊天機器人風靡全球,轟動一時。這些AI產品是眾多大廠競相競爭的對象。2月7日消息,據外媒報道,當地時間週一,谷歌公佈了Chat GPT的競爭對手Bard,一款人工智能聊天機器人工具。此外,百度計劃在今年 3 月推出類似於 Chat GPT OpenAI 的 AI 聊天機器人服務。
一、谷歌推出AI聊天機器人工具Bard
谷歌CEO桑達爾·皮查伊(Sundar Pichai)在一篇博文中宣佈了該項目,將該工具描述為一種由LaMDA(谷歌開發的大型語言模型)支持的“實驗性對話式人工智能服務”,將回答用户問題並參與對話。
他還指出,Bard 能夠從網絡中提取最新信息以提供新鮮、高質量的回覆,這意味着 Bard 可能能夠以 Chat GPT 難以做到的方式回答有關近期事件的問題。
Pichai 表示,該軟件最初將開始面向可信任的測試人員開放,然後在未來幾周內更廣泛地向公眾提供。目前尚不清楚 Bard 將具有哪些功能,但聊天機器人似乎將像美國人工智能研究公司 OpenAI 擁有的 Chat GPT 一樣免費使用。
據悉,Chat GPT由OpenAI於2022年11月30日推出,Chat GPT可以根據用户需求快速創作文章、故事、歌詞、散文、笑話,甚至代碼,並回答各種問題。Chat GPT一經發布就在互聯網上掀起一股風暴,並受到包括作家、程序員、營銷人員在內的用户以及其他公司的青睞。對於Chat GPT的走紅,Pichai在公司內部發布了“紅色警報”,表示將在2023年圍繞Chat GPT全面適配谷歌在AI方面的工作。上週,皮查伊表示,谷歌將在未來幾周或幾個月內推出自己的 AI 語言建模工具,類似於 Chat GPT。

二、百度Chat GPT產品官宣確認:文心一言3月完成內測
值得注意的是,據外媒報道百度計劃在今年3月推出類似於Chat GPT OpenAI的人工智能聊天機器人服務。初始版本將嵌入其搜索服務中。目前,百度已確認該項目名稱為文心一言,英文名稱為ERNIE Bot。內部測試於 3 月結束,並向公眾開放。此時,文心一言正在做上線前的衝刺。
去年9月,百度CEO李彥宏判斷人工智能的發展“在技術層面和商業應用層面都出現了方向性轉變”。據猜測百度那時候就開始做文心一言。按照谷歌和微軟的節奏,文心一言可能提前開啓內測。
百度擁有 Chat GPT 相關技術,在四層人工智能架構上(包括底層芯片、深度學習框架、大模型、頂級搜索應用)進行了全棧佈局。文心一言位於模型層。百度深耕人工智能領域數十年,擁有產業級知識增強文心大模型ERNIE,具有跨模態、跨語言的深度語義理解和生成能力。
業內人士分析,尤其是在自然語言處理領域,國內絕對沒有一家公司能接近百度目前的水平。有專家提出Chat GPT是人工智能的一個里程碑,更是分水嶺,意味着AI技術的發展已經到了一個臨界點,企業需要儘快落地。