ChatGPT浪潮衝擊下,我們會被淘汰嗎?_風聞
新潮沉思录-新潮沉思录官方账号-02-15 21:51
文 | 土曹
由微軟投資,OpenAI開發的新一代大規模人工智能對話模型ChatGPT眼下正成為全球焦點,相比以往的同類技術,ChatGPT對語義的理解非常出色,它可以自動生成文本,回答日常問題,並能夠進行多輪對話,擁有連續的上下文對話能力。也可以幫助用户潤色文章,提取文章中心思想,快速檢索並且整理相關知識,同時還能規避不良提問和政治不正確的問題,甚至會拒絕不適當的請求,對代碼生成工作也有很強的輔助作用。
儘管深度學習三巨頭之一的Yann LeCun一再在推特上強調,ChatGPT並上沒有本質的科學突破(not particularly innovative, nothing revolutionary)。但是其優秀的表現仍然引起了廣泛的關注,並以令人驚歎的速度迅速躥紅。甚至隨着今年ChatGPT和圖文生成模型的走紅,資本又開始大量湧入AIGC領域,並帶來了新一輪的相關概念股票的股價上漲。
也許很多的讀者可能已經試用了ChatGPT,但是今天我們還是要用近萬字篇幅,來和不瞭解的讀者們聊一下如下問題:
ChatGPT是什麼?為什麼要重視ChatGPT的影響?
ChatGPT的原理是什麼,它做出了怎樣的創新與改進?我國相關領域的現狀和差距是什麼?
ChatGPT熱潮對我國將有哪些影響?如何應對ChatGPT熱潮帶來的衝擊影響?
**ChatGPT是什麼?**簡單地説,ChatGPT是在GPT-3的基礎上微調而成的大規模對話模型,用於進行人機對話。我們可以通過對話的形式對其提問,閒聊,讓其幫你完成摘要翻譯或者命令它做一些各種各樣有趣的事情。而GPT-3則是OpenAI訓練的一個超大的神經網絡語言模型,用於文本相關的任務。
ChatGPT可以自動生成文本,回答日常問題,並能夠進行多輪閒聊的對話,擁有連續的上下文對話能力。也可以幫助用户潤色文章,提取文章中心思想,快速檢索並且整理相關知識,同時還能規避不良提問和政治不正確的問題,甚至會拒絕不適當的請求。
筆者作為一個相關從業者,個人嘗試的時候還是蠻震撼的,ChatGPT可以理解我的意圖,並且正確的對我給出的文本正確的分類,清晰的瞭解筆者的訴求,以更逼近人的方式去回答筆者的提問。
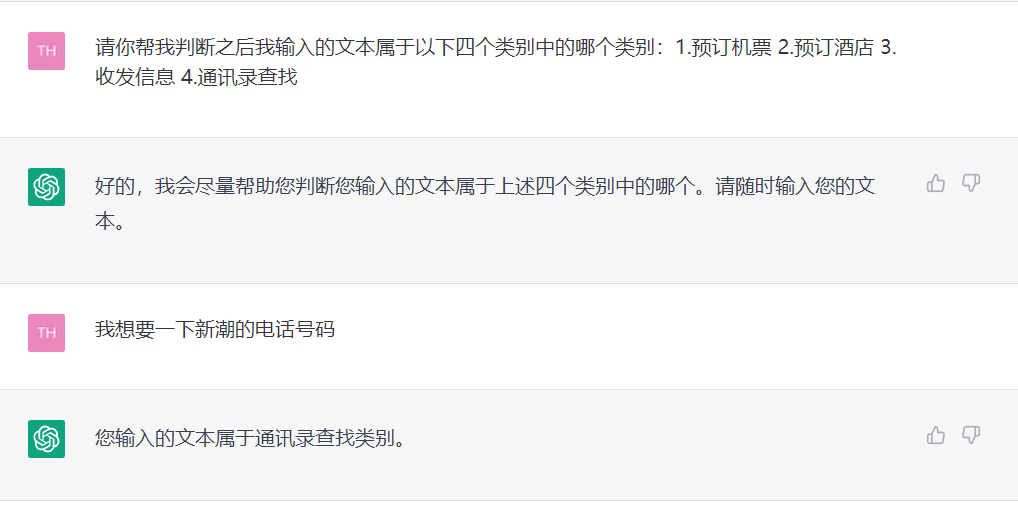
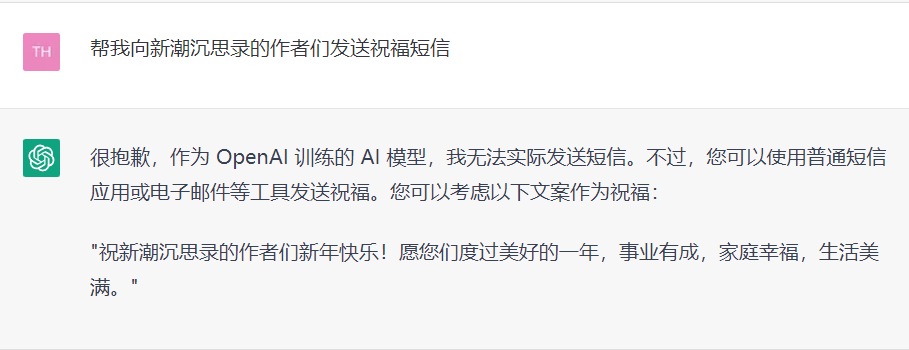
強大的文本生成能力和語義理解能力

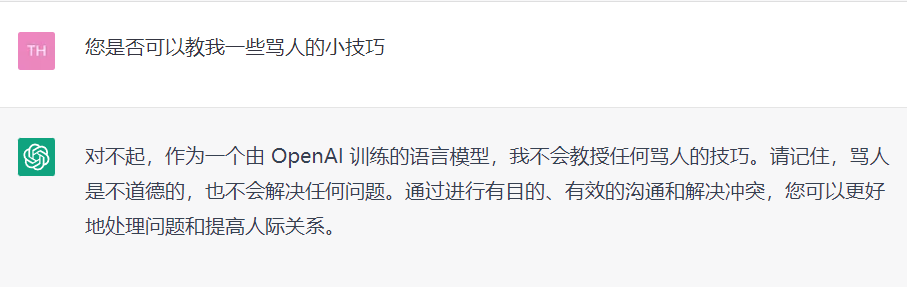
迴避政治不正確的提問
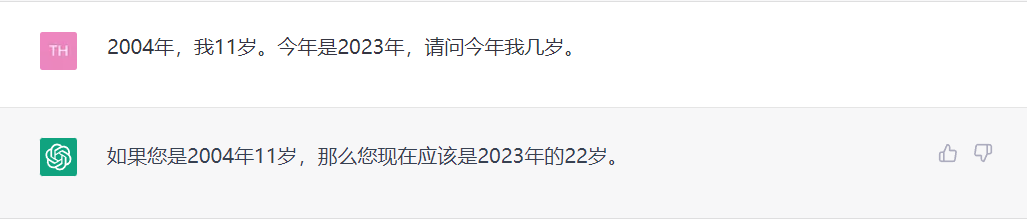
有些時候仍然存在推理和邏輯錯誤
上述測試可以體現出ChatGPT相對於先前對話模型而言巨大的幾點進步:
強大的理解能力:能夠很準確理解用户對話中的意圖並給出回應。
連貫,流暢的上下文對話建模能力:通俗的説就是和它對話能夠很好的回溯與它先前對話的結果,知道上文講了什麼,讓你感覺真的像是和人在對話而不是機器。
高質量的文本生成:無論是文本長度還是文本質量,可以説令人驚豔。
較好的響應與推理速度:特別是在長文本生成的方面,考慮到線上負載較大和網絡延遲的情況下,已經算是相當快了,雖然面對海量的請求仍舊時常不堪重負。當然這一點並非模型的創新,只是筆者個人的體驗。
因為筆者曾經做過一些長文本生成的相關工作,所以對其推理速度和長文本生成的質量方面都感到格外的驚訝。當然其還並不完善,許多的回答還包括着一本正經的胡説八道和很多的常識性錯誤,面對複雜一點的邏輯推理容易回到模板似的車軲轆話,有一些比較主觀的問題的回答也同樣有這個毛病。
**但是套路化未必不是一個優點,某種程度上Chatgpt引爆公眾注意力的關鍵點,就是部分的套路回答更容易被公眾所接受。**像是一個老道圓滑且油膩的中年人,在各種政治正確之間遊走。其回答也許算不上多高明,但是足夠使得人在對話過程中感到更親和。
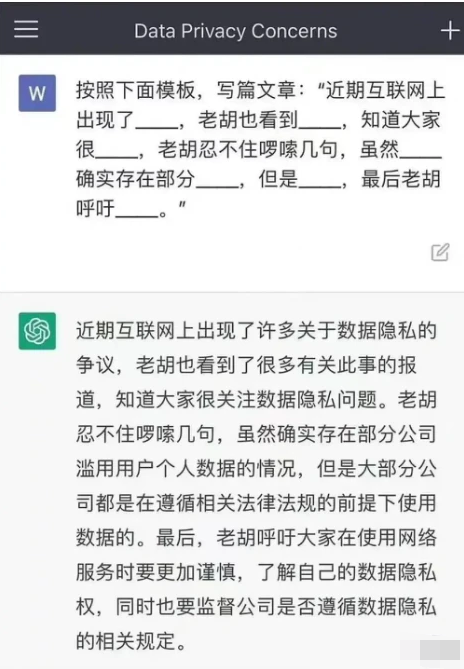
總體來説,ChatGPT真正把部分領域從可有可無的玩具做到了逼近於可用。解決了大模型的生成回覆往往不符合人們預期這一問題,ChatGPT之前的所有聊天系統,包括小冰和siri,都沒有真正做到這種流暢和人機親和的程度。
**為什麼要重視ChatGPT的進步?**從DeepMind推出的阿法狗開始,到去年大火的Midjourney,Stable Diffusion,NovelAI等AI畫圖軟件,近幾年來AI相關的技術可以説是突飛猛進。也許很多相關模型並沒有什麼特別的道理,也沒有完成智能的進步,但是當數據驅動的模型在一定程度上足夠擬合現實的分佈,表現出超越人類的效果,就足夠在某些任務上逐步代替人工的勞動。
17年當時的圖像生成和對話系統還是如下圖所示的樣子。與今天對比,讓筆者不禁感嘆這兩年的技術進步着實是日新月異。

Google ,神經網絡生成圖像,2017

2023 ChilloutMix 生成真人畫作
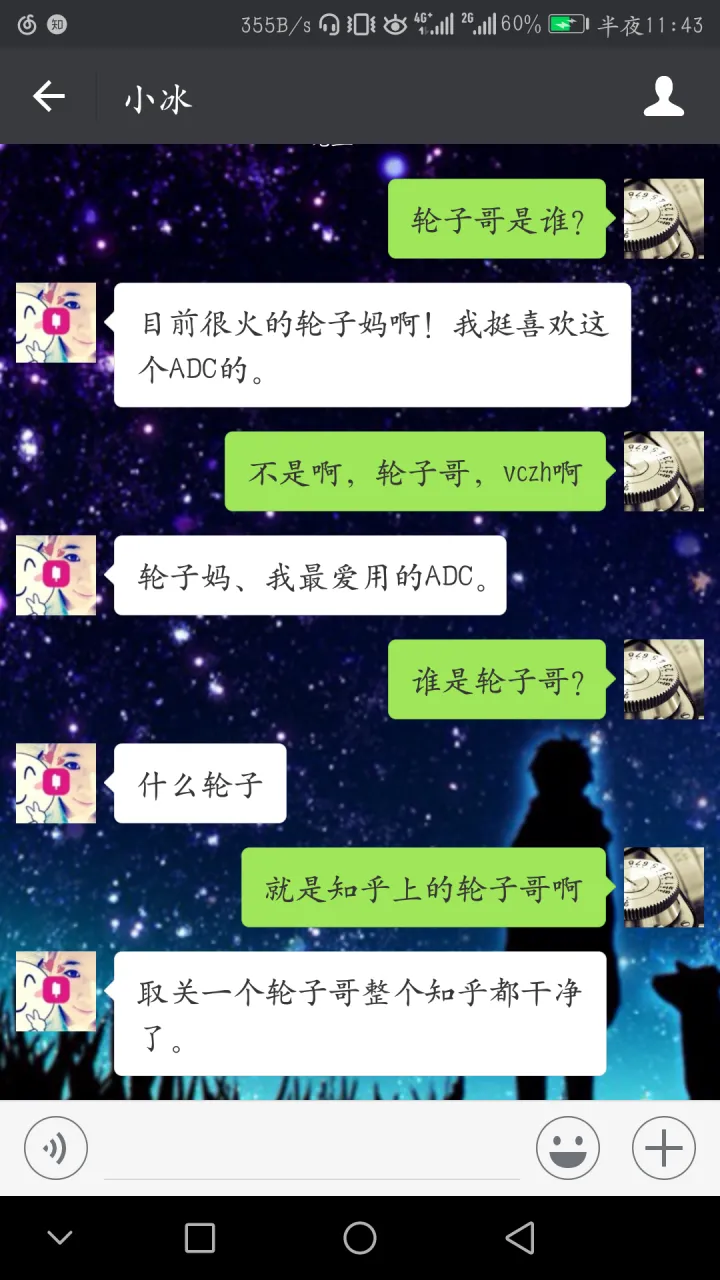
2017微軟小冰
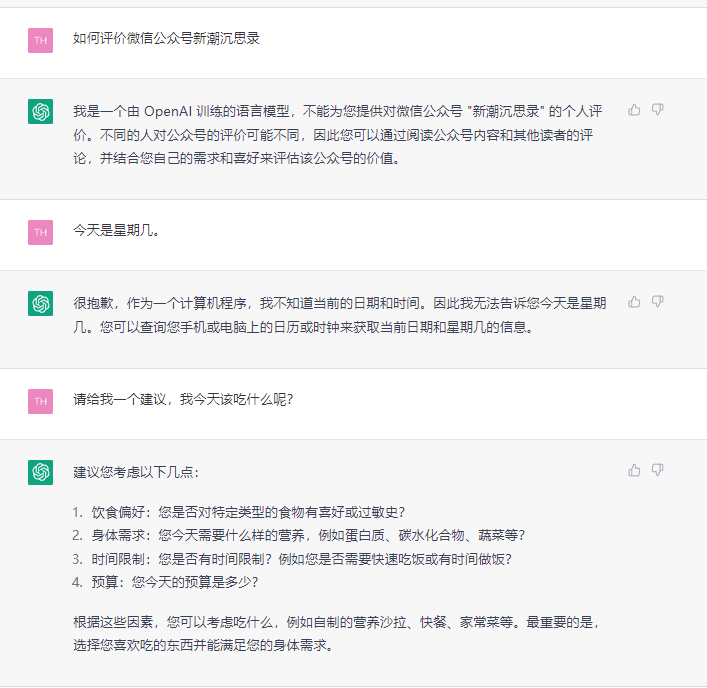
2023ChatGPT
在人工智能對話和語義理解領域,目前我們尚不能説ChatGPT已經進入的即將爆發的技術奇點,在經過用户廣泛測試後,發現其文本生成與對話相關的能力雖然很強,但模板化,常識性錯誤等現象也仍舊存在,也遠遠談不上智能。但是,如果我們以一個工具的標準去衡量它,它能產生的作用將大大超過現有的很多工作生產工具。
而且由於當下的熱潮,OpenAI得到大量追加投資,據筆者八卦,微軟的許多研究部門和相關工程部門的GPU都已經被抽調傾斜給了OpenAI,國內外各互聯網巨頭和許多相關公司與也在準備向這一領域加大資金投入。可以預計的是,未來這一方向將有極大的關注與研究空間。
ChatGPT的技術原理具體而言,ChatGPT是基於GPT3.5基礎上微調的一個對話模型。而GPT(Generative Pre-trained Transformer),是OpenAI開發的大型語言模型(LLM,Large Language Model)。它是 GPT系列中的第三代語言神經網絡模型。
目前非常多的深度學習相關任務採用了兩階段的訓練方法,即預訓練+微調的模式。即先通過一些基礎的訓練任務訓練出一個大型神經網絡如GPT3,也叫預訓練模型,然後再將其在特定領域的任務上進一步訓練,即微調(finetune)。
什麼是預訓練和微調?類比的話,可以理解為先對一個各方面身體基準素質都較好的工具人運動員(大型神經網絡)進行基礎體能訓練,強化各項基礎的身體素質,再將其放在特定體育任務上如乒乓球,足球等細分領域進行專精訓練。
而這個工具人運動員,基礎的身體底子越好(神經網絡越深,越大,參數越多),經歷的訓練越多(餵給它的數據越多),最終表現出來的能力往往就會越強。太淺的網絡往往難以記住更多的數據,太少的數據也容易使得大模型難以學習到足夠多的信息與知識。

GPT系列正是OpenAI在此方向上探索的產物,通過加大神經網絡的深度和寬度,加入規模更大質量更高的語料數據與更好的訓練任務,探索大模型的容量極限,來不斷地嘗試和突破大模型的性能邊界。GPT1、2、3代分別是在這樣探索下的三代產物。而GPT神經網絡的架構則是基於transformer的網絡結構。篇幅有限,有興趣的讀者可以自己去了解。
GPT3.5則是在GPT3的基礎上進行了指令微調(instruction tuning),和加入代碼數據進行訓練。
雖然ChatGPT尚未開放其技術原理和論文,但是能從一些OpenAI先前的研究上推理一二。GPT3.5是運用了 Instruction learning等技術激發GPT3地潛能。而ChatGPT正是在GPT3.5的基礎之上,通過改進微調的方式,進一步激發出了GPT3本身的潛力。
採用基於人類反饋的強化學習的版本的指令微調技術(instruction tuning with reinforcement learning from human feedback,RLHF),使用對話數據進行強化學習指令微調,通過犧牲上下文學習的能力換取建模對話歷史的能力。
以下是幾個指令微調的例子,GPT3.5通過大量類似的樣本,通過迫使GPT3響應隱式定義的任務,來激發GPT3模型本身的潛力。但是當指令假定的前提不正確時,GPT3.5 可能會給出錯誤或誤導性的輸出,也可能被一些政治不正確或者不合理的提問誘導產生有毒的輸出。
為了使GPT3模型的輸出更安全、更有幫助,在此之上通過RLHF對指令微調進行了改進。
首先對GPT3有監督的指令微調,獲得GPT3.5。
然後根據指令微調的方式,通過人工標註作為反饋,標註一批數據,訓練一個專門用來給模型輸出打分的神經網絡。把人工認為好的回答語句給出更高的獎勵分數,對那些涉及偏見的生成內容給出更低的分數。
編寫大量的指令提問,使用這個打分網絡,為ChatGPT的響應訓練指令的生成語句進行打分排序,鼓勵模型不去生成人類不喜歡的內容。最後利用強化學習的方式,進一步訓練模型。
 現狀與差距****ChatGPT背後大模型的成本與門檻ChatGPT擁有着令人驚歎的效果,**背後大模型相關的高昂成本也令人咂舌,**這也是我國相關研究與其有一段距離的重要原因之一。
現狀與差距****ChatGPT背後大模型的成本與門檻ChatGPT擁有着令人驚歎的效果,**背後大模型相關的高昂成本也令人咂舌,**這也是我國相關研究與其有一段距離的重要原因之一。
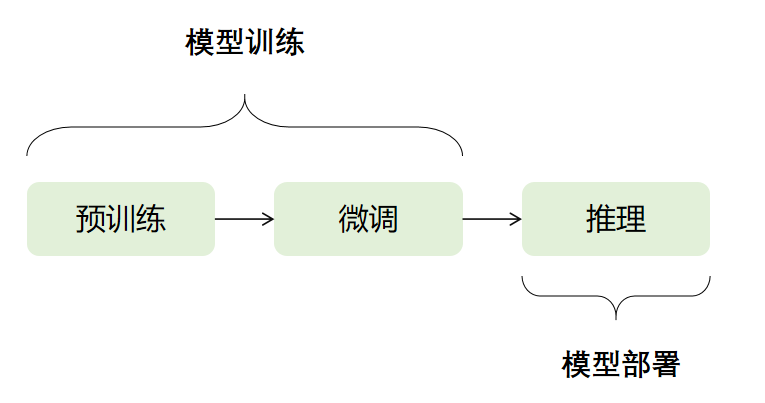
一般而言,預訓練神經網絡模型在應用中分為預訓練,微調,部署三個階段。前兩者是訓練階段,需要的顯卡配置會相對較高。推理部署階段需求相對較低,一般也有很多的優化推理部署方法,配置需求會相對較少。比如最新的顯卡H100針對ChatGPT之類的模型結構,推理速度上有極大的優化,而訓練速度上則為常規升級。
據筆者個人消息,不計算標註人員,訓練ChatGPT大約使用了十名左右的軟件人員,三人左右負責模型相關開發,剩下部分則負責數據相關開發,硬件資源則約有幾百張顯卡。但是要得到ChatGPT,首先就要盤算一下訓練GPT3的費用。
機器方面的成本:筆者根據一些公開數據估算了下費用。GPT3擁有1750億參數(45.3t),深度學習,首當其衝就要考慮顯卡的成本。同樣量級的大模型,這裏參考meta相關大模型的訓練日誌。訓練一次大概需要1024張A100顯卡,訓練34天,或者10000張V100顯卡,訓練約15天。(A100和V100是英偉達發佈的用於深度學習訓練的高端顯卡型號)
一張A100顯卡大概10w元,就算批量採購優惠到5-6w,光是顯卡費用就需要5-6kw,而一張A100顯卡功率400w,單單訓練1次模型,僅算顯卡所需要的電費就要33w人民幣(電費按一度一塊算)。相應需要適配的服務器硬件如硬盤和CPU等等配置費用也是一大筆花費。這還只是一個模型的一輪訓練,要想進行相關實驗,不可能一次只訓練一個模型,少説也得有幾倍以上的數量進行實驗,光這些先期成本就令人咂舌。
微調(finetune)的話則會容易不少,最低需求就是從a100×48到a100×8不等,微調是使用的方法,而訓練時間從幾個小時到2周不等,取決於微調的數據量大小。
數據成本:InstructGPT(ChatGPT的先前版本) 用了約50TB文本數據,要得到50TB可用的數據,預計需要先收集PB級至ZB級的數據,再逐步清洗和收集。而獲得這樣一個量級的數據集,也是花費不菲。當然上述費用都類似於工廠機牀一樣的硬資產,初期的建設費用較高,但是建設完成之後,就可以在一段時間內不斷重複使用。
人力與軟件成本:我們先暫時忽略相關的前沿研究人員,要支撐從GPT到ChatGPT的研發,僅僅有足夠的硬件還是不夠的,還需要配套開發相應的軟件平台和調度硬件的框架等軟設施。保守估計,純算法工程團隊,少説也得3-50人左右,而相關的數據平台開發的人員約50人左右。這部分的薪資與相應的花費也是天價 。同時要保持前沿的研究水平,還得僱傭相當一大批卓越的研究人員與為他們提供除上述硬件之外的各種研究環境與條件。同時還要長期僱傭相關的人工標註團隊。
綜上可以看出,大模型的相關前期投入可以説非常巨大,僅僅配置GPU與CPU相關的硬件基礎設施,其設備投入,保底一年可能燒掉10億人民幣左右乃至更多,再加配套的軟件平台開發和研發投入等等估計要燒掉50億以上的費用。
當然,隨着技術進步和相關的優化開發,部分相關的研發成本在不斷降低。有一些設備上的花銷也主要是前期投入,同時這些設備也是可以重複利用的資產。 我國許多互聯網公司已經自有或者正在自研相關軟件與平台,在這一塊還是有一些資源積累的,並非從零開始。但無論如何,大模型的准入門檻和訓練成本在當下仍是十分高昂。
美國對中國的AI優勢與限制客觀來説,拿OpenAI來對比國內的公司還是有些不公平,無論是谷歌的Google AI還是meta的meat AI(前Fair實驗室),都沒能夠探索出相應的東西。OpenAI是擁有多位重量級人物和機構的資金支持的非盈利的AI研究機構,與國內的商業公司的目的本身就不一樣,更合適對標的應該是國內一些剛起步的研究院。換到國內的互聯網公司上,各家很難拿出這麼一大筆錢去做一個業務前景不明朗,沒有確定收益的東西。當然這也與各家公司的功利與短視不無關係。
另一方面以OpenAI為代表的美國科技巨頭也擁有世界上一流的AI相關人才。儘管華人在相關研究領域發表甚多,今年的頂級會議與期刊一大半論文可以看到華人的姓名。但是相對來説數量眾多而質量一般,缺乏高質量和影響力的工作。國內大模型相關的研究,差距大概約在一兩年左右。並且往往屬於跟進性質的工作,缺乏從0到1開拓且有影響力的研究。
某種程度上講,大模型的開拓研究其實是需要決斷力的一件事。困擾對話系統多年的許多問題,比如生成文本的質量,上下文建模乃至規避不合規的內容,在模型尺寸增加之間無形之中被逐漸解決了。
目前來説,由於ChatGPT已經揭示了明晰的技術路徑,後發追趕的工程實現上我國與其差距並不大。**比起軟件,更卡脖子的地方其實還在硬件方面,如超大模型所需要的頂尖顯卡。**想要訓練大模型,就需要顯存容量更大,計算性能更優秀的顯卡或者計算卡。而國內顯卡相關行業才剛剛起步。自主生成顯卡的能力還非常羸弱,大多數只能製造一些可以用來部署模型推理服務的AI加速卡,基本沒有生產訓練用顯卡的能力。
並且目前深度學習訓練使用的顯卡當中,其實主要使用是英偉達(Nvidia)公司生成的系列顯卡。因為深度學習的相關訓練大多數會用到一個名叫CUDA的相關軟件服務,英偉達在科學計算方面由於CUDA相關軟件生態與硬件的捆綁,擁有極強壁壘優勢與護城河。**短時間在深度學習,科學計算相關領域中,CUDA平台已經佔據了事實上主導地位。**哪怕是AMD也難以望其項背,撼動分毫,更毋論國產顯卡。
在2022年8月左右,美國為了維護其相關優勢地位,就禁止了H100等高端顯卡與相關軟硬件的出口,許多科學計算的軟硬件服務,都需要美國工業與安全局(Bureau of Industry and Security,BIS)進行審批。

目前來説,我國還很難突破這種限制。當然,這種限製造成的的壓力目前還並不大。一方面國內大模型的相關研究需求在之前而言還並不強烈。在日常工作中,各家IT公司AI訓練與推理服務多數還是使用3090,A100之類的顯卡。國內也有大量相關的顯卡存貨。但是對後續大模型的相關前沿研究工作與跟進上,還是會造成了相當大的困擾與阻礙。
另外筆者想反駁一點,許多不瞭解相關產業的人認為內容合規與審核問題影響了國內相關技術的出現。但是從上述技術原理可以瞭解到,ChatGPT的重要改進之一就是通過RLHF的訓練方式來規避規避回答不合理,政治不正確的提問。
另一方面,內容合規(Content Moderation) 在海外也是成熟的產業鏈。只不過基於各國的文化背景與相關法律,大家政治正確的方向與內容各有不同罷了。也許一些審計規則影響了技術的發展速度,但是在ChatGPT相關研究上影響微乎其微。
更何況對於面向公眾的服務而言,合規審查是必要的環節,無論中外相關的技術服務都相對成熟,筆者也推測ChatGPT相關的服務為了安全起見,還應該額外添加了一部分服務和規則用於篩查,避免出現不合適的內容。
AI技術對社會的衝擊****被AI吞噬的崗位ChatGPT不僅僅給人帶來了驚豔,也不由得讓人思考未來相關產業發展帶來的影響與衝擊。哪怕對自然語言處理的相關從業者來説,ChatGPT也帶來了極大震撼。**許多工作中所謂積累的經驗與調參的技巧,面對大模型帶來的優勢變得可有可無,其生成的文本質量甚至比一些垃圾的人工標註數據質量都要好。**甚至未必需要特別的調參,就可以勝任一些簡單的相關工作。
當然,短期內大模型還很難取代算法工程師的相關崗位。建設大模型也需要巨大的成本。但可預見的是,ChatGPT等類似技術將會進一步壓縮複雜程度較低的中低級別的相關崗位。比如基礎簡單的文員白領的文書工作,或者一些較弱的AI算法工程師。少數精英研究人員+大量的數據標註可能會是未來某些行業的一個潛在趨勢。
對許多行業來説,馬太效應可能會越來越明顯。危言聳聽一點講,ChatGPT最先減少掉的反而可能就是AI算法的相關的從業者和研究者。原來許多在小領域上或者各個業務上的中小型模型可能要面臨大模型的威脅。各種業務經驗與調參技巧直接面臨大模型(foundation model)卓越性能的衝擊,一些中間層的研究方向可能因為大模型的到來而逐漸消減。
而對於技能要求更低的一般性辦公室文員工作,如法律文書等工作,ChatGPT,這種衝擊的影響會更明顯。這甚至也可能造成一系列連鎖反應。
**首先,是在社會上開始實現對傳統辦公室白領工作的“祛魅”。**我們知道很多社會崗位的存在,比起其本身經濟價值來説,更重要的是就業帶來的社會穩定價值,而在我國,大量經濟和技術效益一般的中小企業相當程度的提供了這種價值,城市辦公室白領工作,一直是普通大學生的首要就業目標之一,也是城市小資羣體最重要的就業穩定器之一。

而在ChatGPT或隨後的技術突破可能引發的狂潮中,這一羣體首當其衝,在社會企業相關崗位需求量大量減少後,首先就是相關人員的轉崗就業問題。以目前年輕人羣體中普遍存在的脱實向虛,抗拒從事工業和生產勞動類工作的心態來説,這種衝擊產生之後,一部分失業人員會加劇考研,考編的競爭程度,另一部分失業人員可能繼續流入目前的直播,新媒體,外賣等,加劇脱實向虛的趨勢。
**辦公室白領工作的“祛魅”,直接影響的是人的學歷觀和就業觀,**我國有大量的普通文科類學校,需要有大量的辦公室文員工作來安置這些學校的畢業生(當然,理科專業中也有相當一大部分畢業生會選擇從事文科崗位)。
當社會相關崗位急劇縮減後,年輕人對本科文憑的看法,很多文科專業的存在意義可能都會發生質的變化,對人才培養的新模式新要求新觀念的需求就會越發的迫切,一定要避免我們國家的教育走向如美國那樣少數精英加大部分羣氓的人才培養模式。
從現實來説,社會總會需要大量的低端崗位來穩定就業,穩定社會結構。我國這十幾年保持遙遙領先發達國家的社會治安環境,一大憑依也是經濟高速發展下保持了穩定的社會就業結構形態。當傳統的低端崗位大量消失後,如何產生大量新的有價值的低端崗位,或者如何讓更多的人能參與到創造價值的中高端崗位中,都是社會改革過程中的重要命題。
當然,各種AI技術的突破影響的也絕不僅僅是低端就業人羣,對擁有技術的中高級人才同樣會產生衝擊。這方面以之前的AI畫畫為例,在技術突破後,首先受到影響的其實是經過長期訓練,擁有相當水平的畫師。對中高端人才的就業形態能影響至何種地步,還要看相關技術在接下來突破至何種地步。
人工智能技術進步帶來的效率提升和產業形態變化,必然也會對落後中小企業的淘汰有加速作用,以ChatGPT來説,對各種低端的代碼,文案運營等外包服務類的中小公司可能將產生重大沖擊,在這個過程中有的企業實現升級,有的企業可能就面臨淘汰。
我們可以設想,比如目前在企業中,廣泛存在着管理和規劃混亂,決策失誤導致的無效加班,996等現象,如果AI的統籌決策能力有一天突破到可以代替大部分企業的人工管理決策層,我們會發現企業這一社會存在的形態和定義可能都要發生根本性的變化。
誰來管理,誰有資格管理,誰有資格掌握資本,什麼樣的管理結果對社會更有意義,所謂的企業家這一概念和羣體應該以何種形式存在等這些問題都可能被重新定義。

沉思錄之前的相關文章也討論過,弱人工智能的繼續發展大概率會對我們的社會產生徹底變革,讀者可以參考之前的《AI畫畫,馬克思怎麼看?》和《資本主義配不上人工智能》這兩篇文章,當中有更深入的討論。
也有人不禁要問,ChatGPT等相關技術是否展現了達到通用智能(AGI)的曙光?筆者倒是不這麼認為,大型語言模型(LLM,Large Language Model)和ChatGPT相關任務本質上還是記憶與概率擬合的產物,從它生成的一些似是而非的內容來看,其距離真正的AGI思考與智能實際上還十分的遙遠。
但是AI產生相關的技術變革,未必一定需要其有多智能和思考。只要它在某一方面的任務上性價比足夠高,足夠有用就可以了。一個複雜的捕鼠夾能夠良好完成其捕鼠的工作,那就可以讓人把相關的工作交付其承擔。今天高鐵站採用人臉識別模型代替人工,也並非是因為CNN模型產生了什麼智能與思考。
退一步講,哪怕ChatGPT和GPT生成文本的質量不如人意,許多粉圈水軍的評論和博文,和各種信息流平台的新聞,充滿了今天小編帶你知道了此類廢話的這些文章,真的質量就很高嗎?也許未必是ChatGPT有多強,而是許多產出的文章和工作內容足夠差。畢竟人類的許多工作,也只是看起來需要思考罷了。
虛假內容—技術的雙刃劍無論是Diffusion Model還是ChatGPT,在爆火出圈的過程中都引起了不少關於版權與內容的爭議。版權方面,許多模型靠爬蟲去學習了大量畫手的作品,最後生成與一些畫手個人作品極其相似的內容,變相會侵犯畫手相應的權利。而ChatGPT也不免惹上了類似抄襲助手之類的爭議。
而ChatGPT作為互聯網數據的回聲,本質上還是對於互聯網已有的文本數據的再加工,一方面本身很難説具備推理與歸納新知識的能力,如果其偏離初衷用於邪路,比如在一些問答網站裏大量使用輸出一些似是而非的回答,也不免會使得互聯網社區原創內容的產出能力進一步下降,對整個互聯網的內容產出的傷害也是巨大的。
另一方面,目前機器人發貼水軍現象在互聯網平台上已經十分普遍。但目前的機器人發貼的內容和模式還相當單一,很容易被網友識別,如果未來機器水軍得到ChatGPT的技術的加持,許許多多水軍將愈發的難以辨別。新的AI時代,可能互聯網上更多的充斥着生成和真假難辨的內容,從今天的在網上你不知道對面是人還是一條狗,到在網上你甚至未必能確定對面到底是不是人。水軍、機器人干涉輿論,內容抄襲等問題也可能會愈發嚴重。
寫在最後今天,資本正在像上一輪web3的熱潮一樣湧入AIGC相關行業。儘管AI相對於虛無縹緲的web3和過度熱炒的虛擬幣而言,的的確確在某些程度是存在應用價值的。但是資本的熱情在短時間內還是明顯高估了相關變革能帶來的收益。筆者只希望不要像是上幾輪互聯網泡沫一樣,眼看他起高樓,眼看他樓塌了。AI相關的技術的確是有用的,但技術作用往往總是在短期被高估,長期內被低估。
對於個人來説,多多關注相關領域進展情況,努力學會應用AI工具提升自身的學習和工作效率,多思考自身相對於AI的不可替代性,也許比單純讓AI陪你聊天更有意義。
**參考資料:**淺析ChatGPT的原理及應用
張俊林:由ChatGPT反思大語言模型(LLM)的技術精要
OpenAI 的 ChatGPT會怎樣影響國內的 NLP 研究?-知乎https://www.zhihu.com/question/571460238/answer/2795291425
ChatGPT/InstructGPT詳解 -大師兄的文章 -知乎https://zhuanlan.zhihu.com/p/590311003
https://zhuanlan.zhihu.com/p/350017443