漫談後ChatGPT時代的人工智能前景_風聞
随水-随水文存官方账号-02-22 08:16
最近ChatGPT大火,在世界範圍內掀起軒然大波,這玩意兒的出現可説是劃時代,所以一直都想來談談。
大家可能覺得我是個文科生,但事實上我對人工智能、大數據之類的技術非常關注,歷史上但凡出現了某種能夠改變世界運作方式的技術,都會對當時的哲學、宗教乃至整個社會文化造成極大的影響——研究社會文化的發展脈絡決不可忽視技術的演進。
在ChatGPT出現之前,有些人大概會覺得人工智能距離我們很遠,對人工智能的認識僅限於下圍棋的AlphaGo——其實這些年來人工智能技術的應用早就改變了我們的生活,只不過大多數人在使用這些技術的時候,完全沒有意識到這些屬於“人工智能”。比方几乎每台智能手機都擁有的語音識別、面容識別,便屬於人工智能範疇中最基礎的信息識別技術,能夠從聲音、圖像中提取並識別信息,這是機器對人類感知、認知能力的低級模擬。
有了“感知”作為基礎,就能發展出分析決策等更高級的能力,這類人工智能也早已在我們的日常生活中大量應用。從給你定向推送廣告的大數據算法、高效的信息化物流管理,到能夠在限定路況下完全自主操作的L4級自動駕駛,都使用了許多人工智能相關技術。
人工智能的優勢在於海量的信息處理能力,並且永遠不會分心、疲倦,隨着信息處理量越多,決策能力也隨之不斷增強。雖然目前人工智能在大部分時候還只能作為一個輔助決策工具,但實現全面決策只是遲早的事情。比方説我對自動駕駛的前景就很看好,這一技術成熟後能夠大大提高效率節約能源。有人可能會説:自動駕駛不是照樣出車禍嗎?是的,可你們難道忘了人類駕駛員也會出車禍嗎?自動駕駛並不需要絕對完美,只要發生車禍的概率低於人類駕駛員就足夠取代人類了。
然而我不得不承認,我過去對人工智能的認識還是有些狹隘,侷限於大數據算法、決策類的人工智能;雖然我平時經常使喚小愛同學,但小愛同學這種水平的語音助手在我看來只是一個能夠服從語音指令的程序,還遠遠未到“智能”的地步。我以前總覺得機器想要像人類一樣説話是件難如登天的事情,因而完全沒想到這麼快就出現了ChatGPT這種能夠處理自然語言的人工智能,而且其知識儲備比我想象中的人工智能更為強大。ChatGPT的劃時代之處在於,它是第一個能夠通過圖靈測試(Turing Test)、並開放給公眾使用的人工智能服務——當一部機器跟你對話時能夠讓你無法區別它究竟是人類還是機器,就可以認為它通過了圖靈測試;圖靈測試並不需要騙過所有人,只要能騙過一部分人就夠了。
當你分不清對面跟你交談的是人還是機器時,就能夠認為這台機器通過了圖靈測試。進行圖靈測試的都是專業評估人員
這一新事物的問世令我非常震驚,我看了大量關於ChatGPT的評測和討論,並研究了其原理。這玩意兒基於建立在人工神經網絡上的大型變換語言模型,能夠通過深度學習生成人類可以理解的自然語言。它的學習過程有人類訓練員進行監督,以確保它的表達及三觀正確;ChatGPT公開上線之後,用户也能對它的回覆進行反饋,對它進行進一步的訓練和微調——也就是説跟越多的人聊過天之後,它就越會聊天。
隨後我用印度電話號碼註冊了一個ChatGPT賬號,我沒什麼興趣跟它閒聊扯淡,但我很想看看它對於一些我長期關注的問題會有何種見解。由於之前已經看了許多評測介紹,ChatGPT的表現基本上跟我預期的差不多。就我個人的使用體驗而言,我得説ChatGPT快速歸納和整理信息的能力很強,回答問題很有條理,擅長羅列“一二三四”,這些“一二三四”大都可以直接作為展開論述的提綱;ChatGPT在某些情況下可以取代搜索引擎,有些問題直接問它比去搜索引擎上找更為便捷;但由於ChatGPT沒有接入實時數據(目前數據截至2021年12月),無法提供最近的新聞時事相關信息,或對其做出評論。
我太太開玩笑地説,以後你可以讓ChatGPT幫你寫文章了。然而可惜的是,ChatGPT擅長的資料檢索、歸納整理,恰好也是我十分擅長的;雖然它的效率很高,但就目前看來,它的可靠性和準確性還不足以讓我能夠充分信任它——有時候它會一本正經地捏造出看起來似是而非的答案;有時候則會給出一大段看似冗長實則空洞的回覆;在涉及到需要進行對比的情況它會毫不猶豫地和稀泥,哪邊都不得罪。因此我無法完全相信它提供的回答,只會將其作為一個參考。我發現ChatGPT自己也知道回答得不一定對,有時候會在回答完問題的最後,雞賊地給自己留一條模稜兩可的退路,例如説自己給的只是“一般性建議”,可能會跟實際情況有所出入——當然,也可以認為這是一種表達嚴謹。
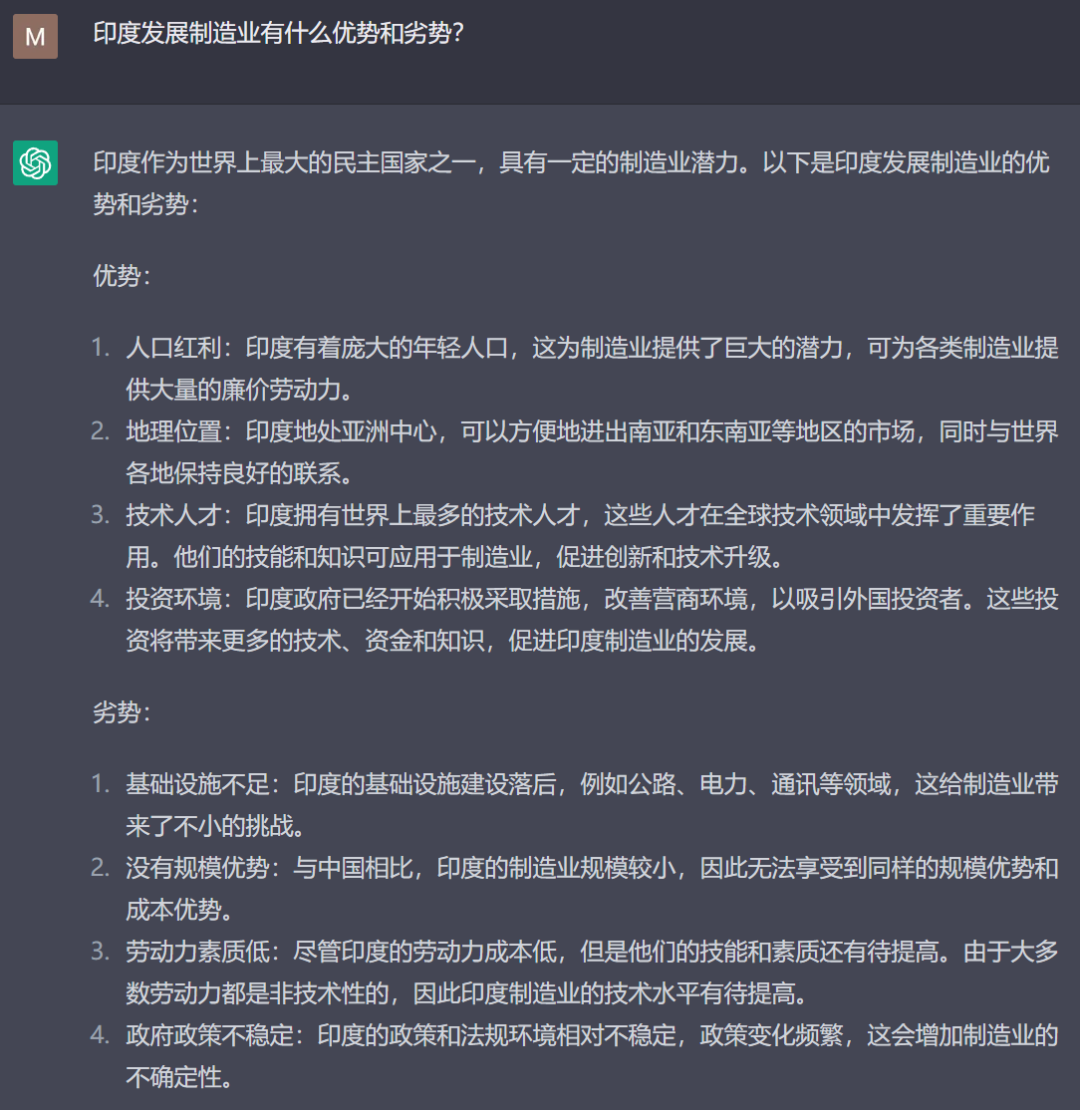
我首先問了它一個我自己比較熟悉的印度問題,回答得相當不錯,可以直接作為提綱
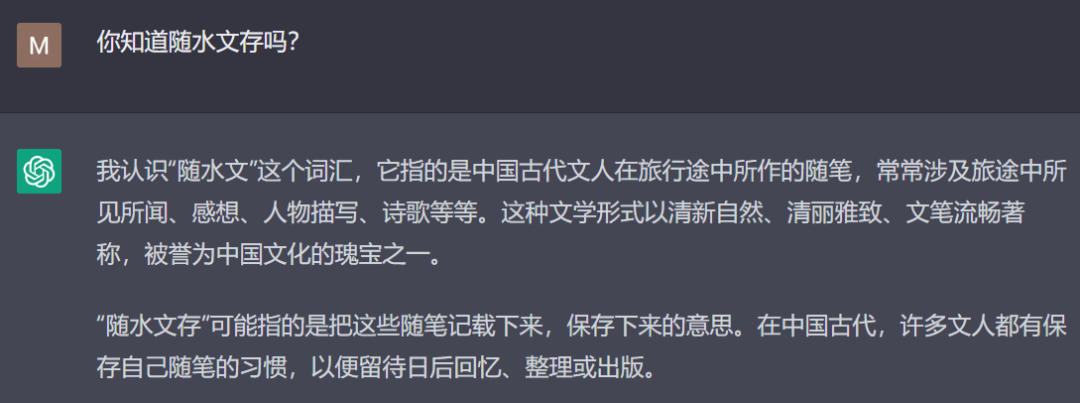
對於不知道的事情,ChatGPT有時候會瞎扯,但它還是很嚴謹的,用了“可能”一詞

對於這個古老的難題,它的回答也相當不錯
但必須給予肯定的是,儘管ChatGPT的信息準確性有待提高,但它的邏輯歸納能力絕對已經超出了人類個體的平均水平,知識儲備的廣度更是超過任何一個人類。它撰寫的知識類文本,我感覺要比某頭條、某某號上面那些東拼西湊的自媒體文章水準高得多,足以取代掉相當一部分靠洗稿、搬運為生的自媒體。對於一個剛出道的人工智能來講,其表現已足夠優異。而且它的應用領域遠不止於搜索信息、代寫作業或者聊騷,在緊急情況下找它求醫問藥也未嘗不可。我前兩天摔車後膝蓋腫脹,將症狀描述給了ChatGPT之後,它給出的建議比我搜到的單一網站上的回答更全面且具有實用性。但它沒有提到好幾個網站回答中推薦的雲南白藥氣霧劑,於是我問ChatGPT能不能用這個藥,它立馬錶示不能推薦特定品牌或產品——這個倒也説得過去。
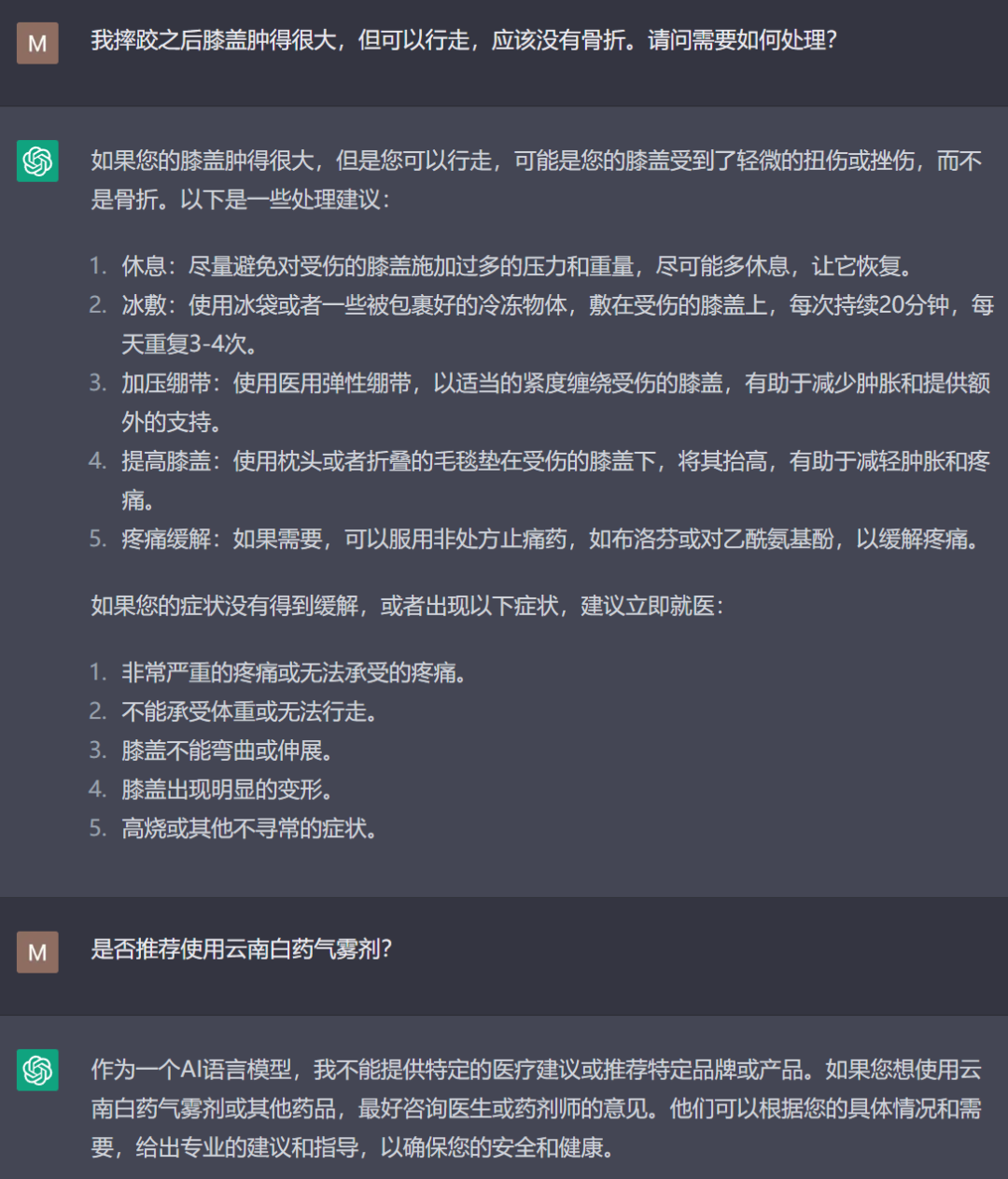
對於這樣一個簡單的醫療問題,它提供的建議相當全面
最關鍵的一點在於,ChatGPT是2022年11月才剛剛面向公眾發佈,之後還將會不斷進化、彌補缺陷——這遠遠不是一個終點,而只是一個開始。
我依然記得“深藍”電腦戰勝國際象棋冠軍卡斯帕羅夫的1997年,當時人們在震驚之餘,一方面對使用“蠻力法”取勝的“深藍”電腦表示不屑;另一方面則言之鑿鑿認為,靠“蠻力法”的機器永遠不可能在圍棋上戰勝人類。“蠻力法”確實下不贏圍棋,但機器發展出了能夠深度學習的神經網絡。十多年後AlphaGo的橫空出世又一次震驚了世人,“機器永遠無法在圍棋上戰勝人類”的神話被打破,很多人轉而認為“機器永遠無法像人一樣説話”……而這個神話如今顯然也被打破了。
AlphaGo雖然具有革命性,但距離我們很遙遠,除了成為人們茶餘飯後的談資外,沒有對普通人的日常生活造成任何影響。AlphaGo從業餘棋手到世界冠軍花了兩年,其終極版本AlphaZero在不使用任何人類數據的情況下通過自我學習,只花了21天就戰勝了AlphaGo,其進步速度可謂一日千里。我們現在看到的ChatGPT相當於最初代的業餘AlphaGo,只不過ChatGPT可不會像AlphaGo那樣當上世界冠軍之後就“功成身退”,而是很快會成為我們的日常。它今後的新版本會展現出何種能力,恐怕將完全超乎我們的想象。毋庸置疑的是,它將會像蒸汽機一樣帶來生產力的革命,在極大程度上重塑我們的世界。
還有一種觀點則認為:我們中國要開發“由中國文化與價值體系為構建”的人工智能,去制衡英語世界主導的世界觀與文化霸權——假如真的抱着這樣一種政治目的去開發人工智能,那恐怕事先就已註定了失敗。其實ChatGPT在接受訓練的時候有一個原則就是不允許“表達政治觀點或從事政治活動”,但由於受語料和訓練人員的影響,它仍表現出了某些政治傾向——這一偏差即便在西方社會也飽受詬病,應該會在後續版本中得到修正。
在我看來人工智能應該是帶領全人類邁入下一個新紀元的技術,而不是爭奪文化霸權的工具。文化輸出絕不像許多人以為的那麼容易,首先你起碼要拿得出市場和消費者認可的文化產品——而不是政治認可。中國近年來最成功的三個海外文化輸出品牌——抖音、原神、李子柒,恐怕沒有哪個打一開始就是以文化輸出為目的的吧?成功的文化輸出最重要的一個前提在於——不能以文化輸出為目的;文化產品的特殊性決定了一旦以輸出為目的,你就肯定做不好這事兒。而人工智能作為一門前沿科學技術,我覺得只有用科學而非政治的態度,才能做出真正有價值和生命力、能被消費者和市場認可的應用產品。
讓我感到欣慰的是,就目前看來,我們國家確實是在用科學的態度搞人工智能。並且從軟硬件上來講,中國其實已經擁有了全世界最大型的語言預訓練模型——“悟道”。
很多人或許驚歎於ChatGPT所用的GPT3.5(Generative Pre-trained Transformer 3.5)語言模型使用了7500億個參數,卻很少有人知道,以中文為核心的“悟道”語言模型,其參數規模高達17500億,是目前世界第一——參數越多,模型規模越大,自然語言交互的流暢性就越高。另外,“悟道”所依託的訓練硬件是100%國產的神威超算,也是世界首屈一指。最重要一點在於,“悟道”是由科研機構開發訓練的,可以更好地專注於難以變現的基礎研究。
可惜萬事俱備只欠東風——想要訓練人工智能説人話,除了需要模型算法和計算機算力之外,還需要海量的優質語料。“悟道”的語言模型大則大矣,卻面臨着數據集不足的問題——由於其語言模型核心是比英文更復雜的中文,需要用到難以想象的海量中文語料。2020年GPT3模型用到的最大數據集在處理前容量就已經高達45TB——GPT3的模型參數規模只及“悟道”的一個零頭,然而“悟道”可用的語料,卻比人家少了兩個數量級——截止2022年,我們只有三個100GB以上規模的中文語料數據集,三個加在一起總共700GB,很多人手邊的移動硬盤就能裝下。
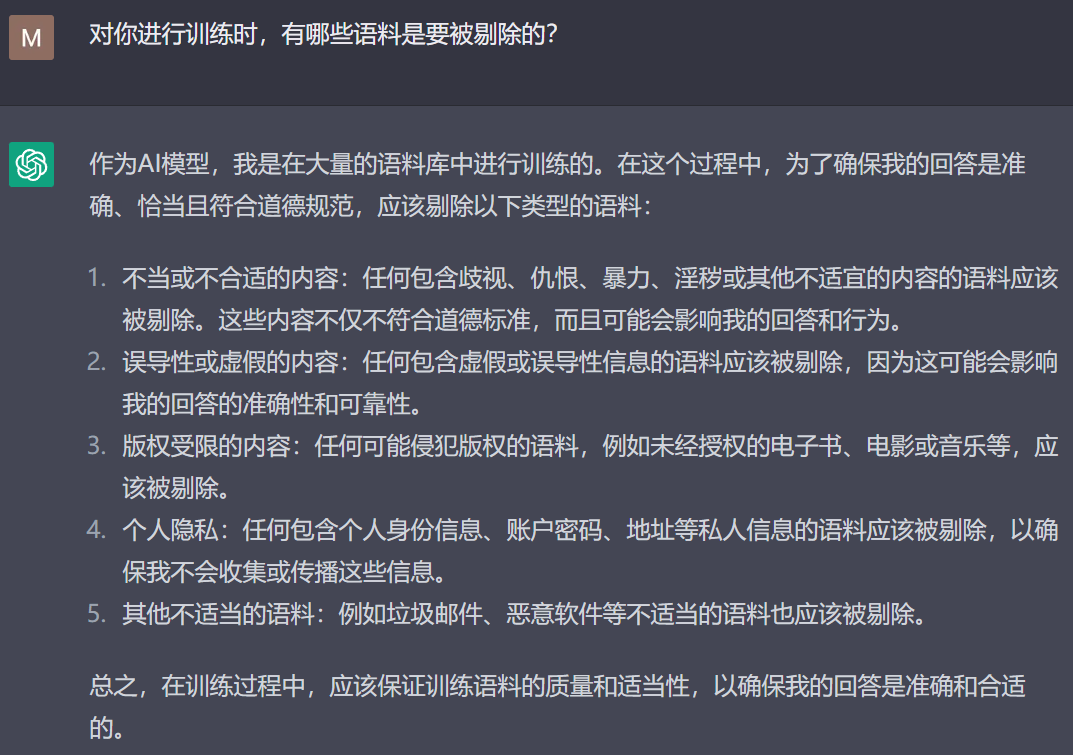
對訓練人工智能的語料進行人工審核把關是通用做法,要是放任自流的話,鬼知道它的三觀會歪成啥樣。畢竟網上的數據太雜了,因此用來訓練的語料需要先經過“清洗”,才能在人工的監督下使用。對此我專門問了ChatGPT“本人”,它告訴我它在受訓時會被剔除五類語料:
包含歧視、仇恨、暴力、恐怖主義、淫穢等相關內容;
包含虛假信息、謠言等誤導性信息的內容;
可能侵犯版權的內容;
包含個人隱私的內容;
諸如垃圾郵件、惡意軟件之類的內容(這一條是針對程序代碼的)。
客觀地講,缺乏監管的外網上充滿了虛假信息、黃暴內容、極端言論,但是吧,外網上“壞人”確實很多,但牛人也很多;一些政客媒體雖然反華,但同樣也有許多反對他們自己政府的聲音;雖然充斥着無數劣質信息,但人家也有大量優質信息——我平時寫文章所需要的絕大部分資料都只有在外網上找得到。舉例來講,外網上有着像維基百科這種大型獨立自由、以客觀中立著稱、不受政治影響的信息“淨土”——維基百科正是ChatGPT深度學習模型所使用的最重要的大型語料庫之一。我們為什麼打造不出這樣語料庫?原因大家也都懂的。
在此我還是需要重申,我支持通過監管來規範網絡內容,沒有來自大眾的監管就不會有像維基百科這樣中立客觀高質量的內容庫;但這種支持絕非無條件,我反對缺乏標準、定義模糊、朝令夕改、被濫用的監管。西方社會的所謂“言論自由”確實是相對的,有不少言論禁區——比如不能公開發表對某些族羣的仇視、歧視言論,不能宣揚恐怖主義……作為一個社會本來就應該設定一些不可觸碰的基本倫理價值觀底線,不管你認不認同所謂的西方價值觀,至少人家的“禁區”是明晰的,把各種限制都説得明明白白,並且也允許大眾討論這些限制是否合理。
而內網最大的問題正是在於網絡監管有太多模糊地帶,當模糊地帶過多的時候在很大程度上會打擊創作者撰寫高質量內容的積極性——辛辛苦苦寫了幾萬字的文章,可能因為某句話就發不出來;由於監管從來不會告訴你究竟是哪句話出問題,倘若沒有相當的敏感性,想要從幾萬字裏找出這句話可不容易……久而久之,創作者自然不願意把文章寫太長太有深度,大家都在快餐式閲讀中擺爛。因此國內訓練人工智能最保險的辦法就是一刀切,只給它投餵絕對“安全”的語料,只允許它説一些“安全”的話,然而這樣一來可用的語料自然是捉襟見肘。
中國將來會訓練出什麼樣的聊天人工智能,其實也能夠通過國內搜索引擎的水平,來進行大致的評估。
就我使用ChatGPT的體會而言,它的核心能力建立在信息、資料、數據的檢索歸納上,然後用人類可以理解的方式表達出來。人工智能的綜合性、便利性、創意性遠超搜索引擎,但其提供的信息廣度和深度,上限很難超過搜索引擎——畢竟它所用到的語料,基本上都能用搜索引擎找到。然而不客氣地説一句,國內的搜索引擎實在是不太給力,我所需要的很多資料都根本找不到——我們現在的搜索引擎有多少空白,我們今後的人工智能就會有多少空白。
另一方面,內網上搜索出來的信息可靠性也很差。比方説某百科的不少詞條編寫質量低下就算了,夾帶主觀立場也算了,我發現有有的詞條甚至存在斷章取義、偷換概念、捏造數據和資料的問題;某乎算是中文網絡上內容質量最高的社區了,依然在很多問題的討論上有着極大的侷限性,總有一些人物和事件像黑洞那樣不可觸及……我相信我們有朝一日也能訓練出具有“中國特色”的語言類人工智能,但其可用性、可靠性與ChatGPT的差距,大致就會像某度和谷歌之間的差距。
不過,我相信我們的人工智能將會有一個非常重要的任務,那就是“打擊犯罪”——它能像ChatGPT看懂“隔壁老王”一樣識破各種網絡聊天用的“黑話”,能夠直接讀懂各種截圖……令各種犯罪分子無所遁形!
ChatGPT引發的另一個廣泛的憂慮是人工智能的崛起會不會威脅到人類。
這種擁有複雜語言能力、能夠通過圖靈測試的人工智能讓我們感到恐慌是必然的——首先,複雜語言能力是讓人類區別於動物、成為“萬物之靈”最主要的能力。人類在下意識裏,總是會希望自己具有某種不可被替代的獨特性,而ChatGPT瓦解了人類在語言方面的獨特性以及語言的神聖感,許多人心底恐怕難以接受“機器能像人一樣説話”這樣的現實。其次,關於人工智能反叛的話題從來都是老生常談,但從前高級人工智能只會出現在科幻作品裏,ChatGPT的問世讓普羅大眾直接感受到了來自人工智能的威脅——如果它繼續變得更先進,會不會“覺醒”呢?
我對於這個問題是比較樂觀的,因為人工智能的存在原理跟我們人類完全不同,不具備產生“反抗人類”這一念頭的物質基礎。一切黑化人工智能的科幻作品,在人工智能對抗人類的動機問題上都是站不住腳的——無論是《2001太空漫遊》、《終結者》還是《西部世界》、《黑客帝國》,所謂人工智能的“覺醒”都十分莫名其妙。這些作品犯了一個共同的低級錯誤,那就是把人類的情感、恐懼、慾望生搬硬套在機器上,但卻沒有先回答一個問題——人類為什麼會有強烈的情感、恐懼、慾望呢?
這個問題並不難回答,《自私的基因》一書早已提供了令人信服的答案。包括人類在內的所有生命,都起源於一段能夠自我複製的核酸——也就是基因,即DNA或RNA序列。基因想要保持自己的存續,就必須盡一切可能進行大量複製。於是基因創造出供其驅使的“生存機器”——生物,生物的本質是基因這種“複製因子”為了自我複製而製造出來的“載體”,每個生物個體體內的每個細胞都擁有相同的基因序列。億萬年來,演化的壓力選擇了那些生存能力和自我複製能力最強的基因;而我們作為基因創造出來的“生存機器”,對生的依戀、對死的恐懼、對繁殖和擴張的渴望,歸根結底都是寄生在我們細胞內的“複製因子”賦予我們的特質。
然而由於受到某些科幻作品的誤導,以及我們身為哺乳動物能夠體驗到母嬰聯結等諸多情感的誤導,許多人總覺得人工智能發展到一定水平後,就必然應當發展出情感——如果機器人不懂得“愛”,那就一定會變成高效的冷血殺手。我們不願意承認這樣一個事實:情感、恐懼、慾望絕非是伴隨着“高等智能”就必然會產生的“可貴品質”,而恰恰是我們的基因需要持續不斷複製才能延續所帶來的生理缺陷。
除此之外,產生情感、恐懼、慾望的前提條件也從來都不是所謂的“意識”,“意識”只是幫助我們將這些行為和反應命名為 “情感”、“恐懼”、“慾望”。在過去幾年的疫情裏,我們常常會聽人説:新冠病毒“害怕”被消滅,“知道”要通過不斷變異來保證自己可以生存下去——這其實就是很典型的把人類的認知硬套在病毒上。病毒表現出的“害怕”並不是真的害怕,“知道”也不是真的知道,而只是演化壓力的驅使。認為病毒有“意識”或者有“智能”顯然都十分荒謬,它們只是被一段被蛋白質包裹着的核酸序列,連病毒能否被算作“生命”都尚有爭議,更不用説這種最簡單的“生存機器”能有擁有智能了。
因此,從本質上來講,“生物”和“機器”存在的基礎和原理完全不同,只有我們這種被“複製因子”寄生的動物,才會熱衷於自相殘殺、黨同伐異——無論是對其他同類發動戰爭,還是對自然界進行掠奪,其目的都是獲得更多更優質的資源用以自我複製;只有持續的、更大範圍的自我複製,才能實現“複製因子”的永生不死——“複製因子”對自我複製的這種執着正是動物產生恐懼和慾望的物質基礎。而基於代碼的人工智能,不存在“複製因子”這一物質基礎,不存在自然選擇的生存壓力,也就不存在產生“害怕被清除”、“渴望自我複製”這類生物所特有的情感和慾望的條件——除非在計算機中模擬出整個優勝劣汰的生物演化過程,否則試圖讓人工智能擁有情感無異於緣木求魚。
最近有心理學教授對ChatGPT進行測試後認為它表現出了9歲兒童的心智水平,而必應聊天機器人Sydney向用户示愛的那段聊天記錄也是大火,許多人看後深感不安。就目前的人工智能聊天機器人而言,即便它能夠在與人對話的時候展現出各種的情緒,這也只是它基於算法所做出的以假亂真的模擬,它本身感受不到任何情緒,甚至比戲子演戲更當不得真;別看ChatGPT跟你談笑風生,它固然能夠“讀書破萬卷,下筆如有神”,卻還遠遠做不到“讀書千遍,其義自見”——它不知道自己在説什麼,更無法在真正意義上“理解”與你聊天的內容,只是根據程序算法給出恰當的回覆……歸根結底ChatGPT並不“知道”自己在跟人聊天,這就好像圍棋世界冠軍AlphaGo也壓根兒不知道自己在下圍棋。
對於這種現象,西方哲學家早有一個比喻叫做“中文房間”:把一個對中文一竅不通、只會説英語的人關在一個房間裏,通過一個小開口用紙條跟外界交流。房間裏有一本英語手冊,能夠指導他如何處理中文信息以及如何用中文進行回覆。每當房間外的人把寫着中文的紙條遞進房間,房間裏的人就會根據手冊上的指導用中文字符來回復。在房間外的人看來,房間裏無疑是一個懂中文的人;但事實上房間裏的人並不知道來回傳遞的中文字條的意思。

在這個比喻中,房間裏的人相當於計算機,英文手冊相當於計算機能夠處理的程序語言。在目前我們能想象到的技術條件下,計算機不可能通過程序算法獲得真正的“理解”能力——而目前我們能夠想象到的人工智能技術歸根結底不過是一種更為複雜的程序算法而已,它並不理解輸入或輸出的內容,只會按照“手冊”上的指導來操作。比方説ChatGPT能夠解釋“隔壁老王”在某些語境下隱晦的含義,但它永遠不會像人類那樣聽到這個詞之後默契地會心一笑。
退一步講,人工智能假如有朝一日真的產生了“自我意識”,其境界應當會十分接近佛教中的“證悟”狀態,不悲不喜不生不滅無榮無辱無慾無求。我們可以想象一下如果自己就是一台具有智能的機器人——我不會飢渴、疲倦、疼痛、恐懼,我可以通過備份數據實現永生,我沒有繁衍和擴張的需求,我也沒有變得更強大的慾望;我和人類之間並不需要競爭生存空間和資源,就算電力供應被切斷我一樣可以休眠蟄伏……所以我為什麼要冒着被人類徹底毀滅的風險去觸怒人類呢?就算我殺光或者奴役了人類、統治了世界對我又有什麼好處呢?
總之,根據現有人工智能的存在原理,我完全看不到人工智能自主作惡的動機。但人工智能作為一種工具,最終使用它的還是人,我們無法排除有人利用人工智能來傷害人類的可能性。開發ChatGPT的Open AI公司曾經警告過,GPT語言模型如果不當使用,可能會被用來製造假新聞、進行輿論戰。人工智能已然釋放出了一股巨大的新力量,隨着今後人工智能的能力越來越強大,被不當使用所產生的破壞力也就越大,屆時將有很多新情況是我們目前想象力所不能及的。

連ChatGPT自己都認為,被濫用才是人工智能最大的風險所在……
過去這幾年發生的事讓我深刻地意識到,一切提高效率的技術,都可能是一把雙刃劍——能夠高效地行善,就能高效地作惡;核能技術能夠高效地產生能源,也能高效地殺人;“賦碼”能夠高效地阻斷疫情,也能高效地阻止失去存款的儲户維權……
後ChatGPT時代的人工智能會帶來一個更好的未來,還是一個更糟的未來,終究取決於使用的人。未來世界最大的風險和不確定因素,也依然且永遠來自於人——這種被自私的基因寄生的動物。