從大神Alex Smola李沐離職創業融資順利,回看ChatGPT武器演進_風聞
谭婧在充电-谭婧在充电官方账号-偏爱人工智能(数据、算法、算力、场景)。-03-07 15:18
圖文原創:親愛的數據
“We’re building something big … stay tuned. Talk to me if you want to work on scalable foundation models.”
“我們正在建造一個大項目……請繼續關注。如果你想在可擴展基礎模型上工作,請告訴我。”
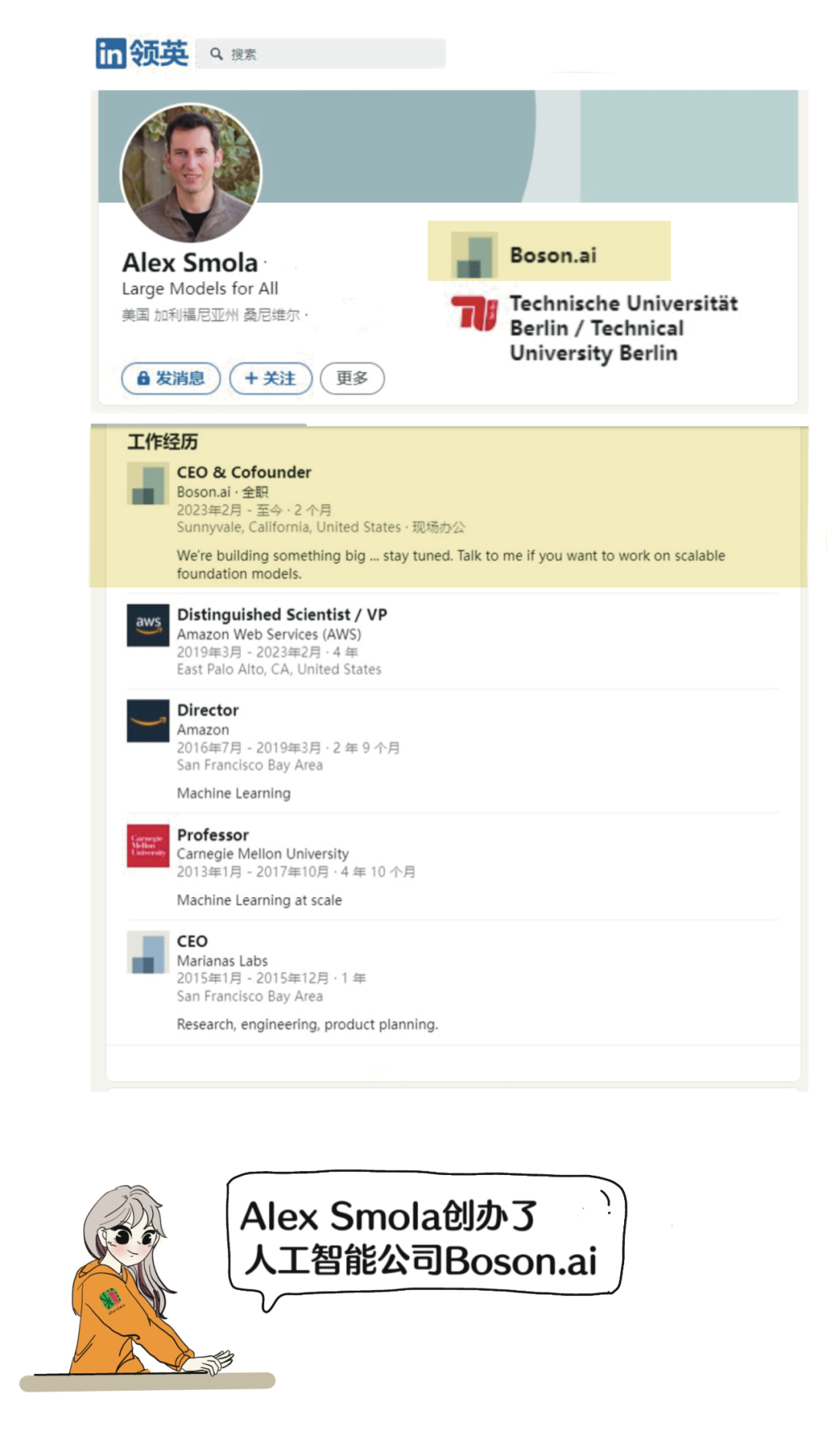
“參數服務器之父” Alex Smol教授已於2023年2月從美國著名公有云廠商亞馬遜雲科技(AWS)離職,創辦了一家名為Boson.ai的人工智能公司。
公元2023年的春天,顯然也是人工智能的又一春。
Alex Smol教授重新出發並在領英公佈了新目標:
“scalable foundation models”(可擴展基礎模型)。
這類廠商可被視為ChatGPT跟隨者,説是挑戰者也行。
不久之前,或者説一週前,他的就職宣言是:“我很高興地告訴大家,我將在 Boson.ai 開始擔任首席執行官兼聯合創始人的新職務!”
官宣語不驚人,實則不然,大神李沐也會加入,一同創業。
李沐既沒有官宣離舊職,也沒有官宣入新職。
業內人士對我説的原話是:“一起創業。”
更進一步的消息是:“融資也很順利****。”
兩位神級AI科學家同期離職,共同創業。
有什麼事情能感召AI大佬離開頂級大廠創業,那非ChatGPT這樣的大模型機會莫屬。
AI從不缺驚喜,一路走來都是驚喜,缺的是驚豔。AI已經好久沒有新的神秘力量了,AI的尊嚴都被ChatGPT一把給找回來了。
多年觀察,這兩位大神師生的故事讓我既感慨,又羨慕。
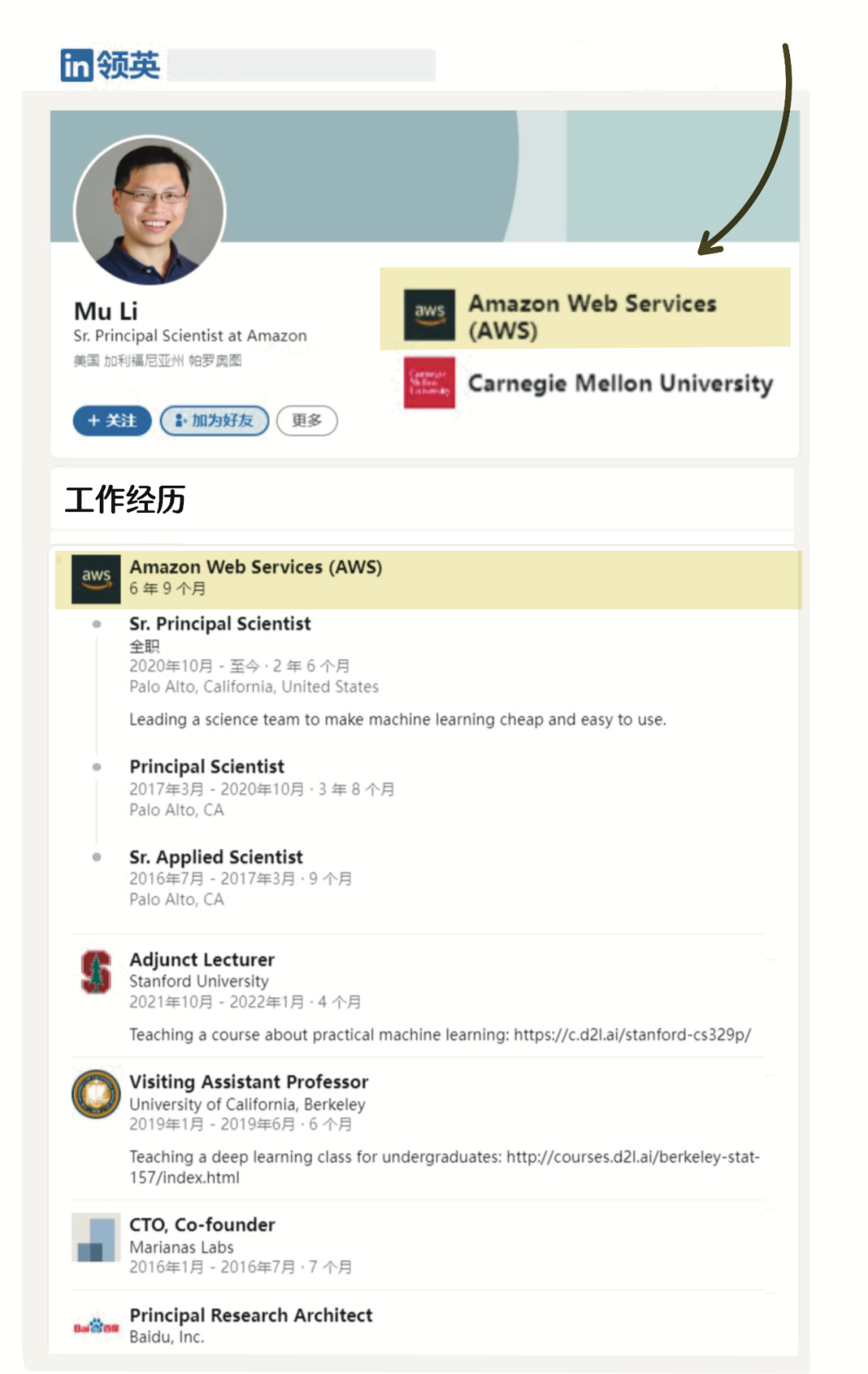
他們大約相識於2012年前後,計劃讀博的學生幾乎都會提前和導師有所溝通。第一次的接觸無處可考,可以確定的是2012年8月左右,李沐收到了美國卡內基梅隆大學(CMU)的入學通知。
人人都有萬里路,只看你與誰同行。
此後的歲月裏,大廠組隊,一起寫書,一起創業。
那本《動手學深度學習》被業內視為入門深度學習的優秀教材(雖然作者不止他倆)。
2021年2月,我曾在《搞深度學習框架的那幫人,不是瘋子,就是騙子》一文中寫過他們的部分經歷:
“談起亞馬遜和MXNet框架的緣分,就不得不提起一位美國卡內基梅隆大學(CMU)的高人,Alex Smola教授,他也是李沐在CMU的博士導師。2016年7月,Alex Smola教授重返工業界,加入亞馬遜AWS擔任副總裁級別的科學家(職級為Distinguished Scientist/VP)。大半年後,2017年3月,李沐加入AWS,直接向老師Alex Smola彙報。 師徒同框,雙手比V。”
此後,李沐大神洪水般的流量從知乎衝到B站,技術從業者追捧指數業界首屈一指。
“車庫教學”“論文精講”“師從李沐”……説實話,別説初學者、資深工程師、碩博牛人在看,連譚老師我也一連看了好幾集,不僅彈幕歡樂,而且回味無窮。
7年光陰轉眼間。
雖然Alex Smola是美國名校教授,前AWS高管,但是很多人對他還比較陌生。“參數服務器之父”的名頭也不甚響亮。
參數服務器已經是“上古神器”,很早以前沒有別的方法,只有它這一種。當年深入觀察之後,至今令我印象深刻的,是其思路的巧妙。
這裏一定要講講參數服務器的前世今生,以及一些AI訓練方法上的演進。
一切糟心事的根源都在於模型在變大。
往哪裏存,往哪裏放,是其中的關鍵。
除了參數,還有樣本抽取的輸入,中間結果等等。這些東西,哪樣搞壞搞錯了,結果都承受不起。
模型小、單機單卡的情況下,信息都在一台機器上,一人闖天下。
要團隊,就要分工。分佈式訓練中,信息要被多人分享。分享效率低,工作就會排隊,排隊就會浪費時間。
3個人分工,和300人分工,3000人分工,事情不是一個性質。
算力已經很厲害了,於是,AI計算呼喚高性能高帶寬的存儲和網絡。
此時,Alex Smola教授的參數服務器就大有用處。如果你要問其本質是什麼,我的答案是:分佈式存儲和分佈式計算。
兩者的佔比關係是,分佈式存儲佔大頭,分佈式計算佔少量。
參數服務器是一個衝鋒隊,有領隊(server),有分工隊員(worker)。專業一點的説法是,分佈式訓練集羣中的節點被分為兩類:parameter server和worker。
説worker是分工隊員似乎也不是很準確,因為worker這個程序,不是參數服務器的一部分,大家一起協同而已。
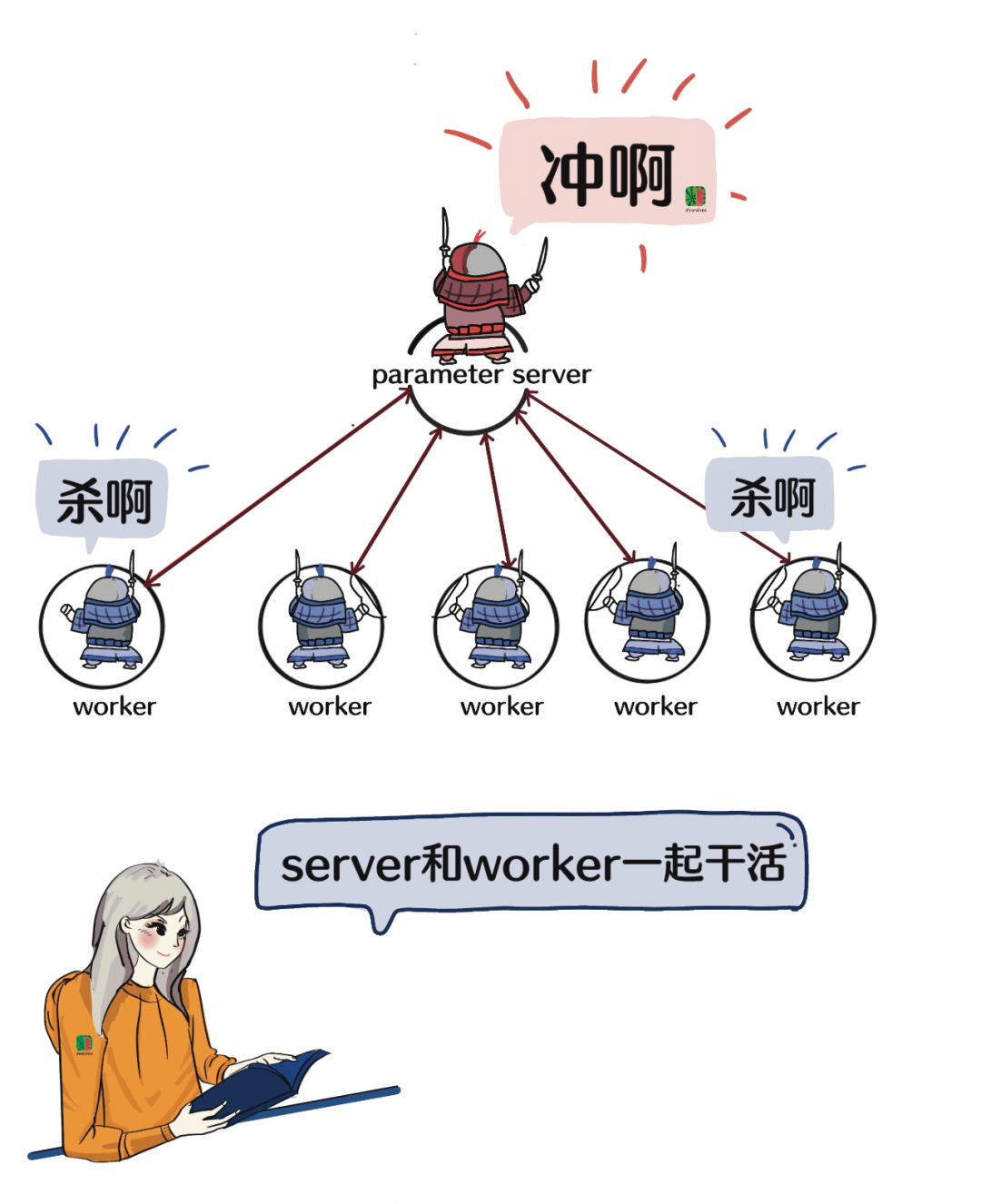
總之,server和worker一起幹活,server存放模型參數,彙總完了再更新給worker。worker認真幹活,server不停地給worker同步“消息”。
這樣看上去server像職場裏消息靈通的保管員。
除了存儲,那一小部分計算是什麼?是參數彙總和參數更新的策略等等。
簡單原理如上。
一個底層軟件層面的巧妙設計,讓模型的擴展性戰鬥指數狂飆起來了。
假如沒有參數服務器呢?那麼,模型大的壓力,就只剩硬件解決方案在硬抗。
比如,工程師做個兩級或者三級存儲,一部分放顯存,一部分放內存,一部分放硬盤。
如此這般,還只是考慮了存儲,把計算結果同步的事情擱置在一旁。
於是,我們會説參數服務器對深度學習模型訓練的性能和效果的影響都很大。
AI時代,任何影響性能和效果的事情,都是天大的事情。模型靠這個吃飯,幹砸了碗就砸了。
AI領域有難題,永遠不缺乏解決問題的人。
這時候,超級計算機裏的一個技術被拿來解決AI的問題。這個技術就是已經用在並行計算架構裏的通信機制。
標誌性的里程碑是Ring All reduce,出自2016年百度公司的一篇論文,技術是從“隔壁”借鑑而來的。這事從論文標題一眼就能看出來——《將高性能計算技術引入深度學習》。All Reduce翻譯為規約,Ring是環狀的意思。
原理就不講了,Ring All reduce“表現”優秀,使用者越來越多。
或者我們調侃一句:“人工智能的臭毛病,讓高性能計算治好了。”
再後來,谷歌和IBM等大公司又不斷地拿出新思路。
很難知道OpenAI公司支撐ChatGPT大模型的類似技術是什麼思路。
但我們知道,難題在產生,也在被攻克。
比如,大模型分佈式存儲需要支持1T到10T級別的存儲量。
前面也提過,計算(訓練)過程裏,模型大,中間量(中間變量,優化器狀態,參數更新頻次和頻次表,還有其他變量等等)的體量可能會膨脹4倍。
原來一室一廳夠住了,現在高低得整個四室一廳。
這裏只談了一部分工作,協同訓練是很有挑戰的技術難題。
世事不難,吾輩何用。
在分佈式上怎麼把算力調動起來這件事遠沒有止境,並且正在持續吸引更多才俊加入到這個領域裏來。
談了很多都是陳年舊事,而人工智能方法上的提高從來沒有停止,我只考古了其中幾步。
重要之處在於,正是有了底層軟件支持,才有了上層大模型的繁榮與爆發。
Alex Smola教授和李沐是這個領域裏的大神,他們的實力和眼光都是世界一流的。
ChatGPT火了,在AI應用層急切呼喚驚豔產品的當下,硅谷著名風投A16Z説“基礎設施提供商是這個市場中的最大贏家”。
我認為把AI平台、AI框架和AI芯片一起打包定義為“AI基礎設施”較為合適。
AI芯片的贏面所有人都已看見,我認為在可預見的將來,Alex Smola教授在本文開頭談到的 “scalable foundation models” ,也就是基礎大模型,會成為AI基礎設施的一部分。
美國公司OpenAI的基礎模型已經足夠強大,對它進行改造和再加工的成本很低(相對於從頭開發)。

如此一來,雲計算廠商即將決勝的戰場就是基礎大模型能力,有則PaaS層勝出,無則慘敗。
在“大模型一出,誰與爭鋒”的宏大背景音樂裏,獨立軟件公司只要做得足夠好,機會就在招手。我想Alex Smola教授和李沐大神選擇加入這場戰役的原因在於此。
他日“得AI框架者得天下”,
今朝“得基礎大模型者得天下”。
大神們獨立門户,有決心,有夢想,有市場機會,有資本支持,有對技術的熱忱與投入,時不我待。
回憶幾年前,好幾家雲計算廠商對大模型的投入,都想瞅着他人情況行事,沒有投入的決心。甚至有的廠商,哪個技術中幹開會提要做大模型,老闆就當場痛罵誰。
這樣也沒錯,誰不是扛着業績邊擦淚邊奔跑。
只是跟隨者這把椅子有時候坐着舒服,有時候不舒服。
此地彼方,唏噓不已。
(完)
