全球ChatGPT“羣雄爭霸”,百度憑什麼率先推出文心一言_風聞
贝克街探案官-贝克街探案官官方账号-03-08 08:44
貝克街探案官

作者
車行運

AI的星辰大海,百度的時代即將到來

自從ChatGPT爆火之後,全球AI企業紛紛推出自家研發的同類產品,其中進度最快的當屬百度。
根據百度公眾號2月28日發佈,**百度計劃於3月16日14時在北京總部召開新聞發佈會,主題圍繞公司旗下的大語言模型文心一言。**百度創始人、董事長兼首席執行官李彥宏,百度首席技術官王海峯將出席。
對於百度而言,文心一言絕不是跟風蹭流量,而是公司多年技術沉澱積累的必然結果。畢竟大語言模型不是一朝一夕就能做出來的。
過去十餘年,百度深耕人工智能領域,目前已經擁有芯片、框架、模型和應用四層技術棧,基礎能力完全具備、具有綜合優勢,不僅能夠實現整體持平ChatGPT,甚至還有機會做到局部超越。超越部分包括知識增強、檢索增強和對話增強。

什麼是大模型
百度2010年轉型AI時,就曾暢想過類似ChatGPT的使用場景。
在2019年,百度正式推出文心大模型,至今已經多次迭代,從單一的自然語言理解延伸到多模態,包括視覺、文檔、文圖、語音等多模態多功能,因此“文心一言”所基於的ERNIE系列模型也已經具備較強泛化能力和性能。
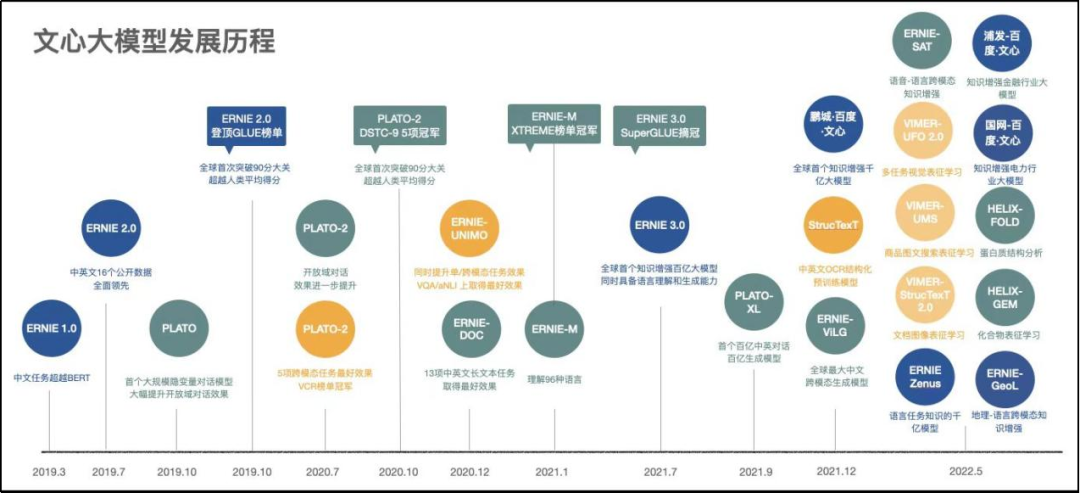
在模型層,文心大模型已經包括36個大模型,涵蓋基礎大模型、任務大模型、行業大模型的三級體系,全面滿足產業應用需求,構建了業界規模最大的產業大模型體系;在工具與平台層,通過大模型開發套件、文心API和提供全流程開箱即用大模型能力的EasyDL和BML開發平台,全方位降低應用門檻;產品與社區層,包括AI藝術與輔助創作平台“文心一格”、產業級搜索系統“文心百中”和暘谷社區,**讓更多人零距離感受到最先進的AI大模型技術帶來的新體驗。**文心是百度自主研發的產業級知識增強大模型,全景圖由模型層、工具與平台層、產品與社區層構成。
值得一提的是,2021年12月,百度與鵬城自然語言處理聯合實驗室發佈全球首個知識增強的千億AI大模型——ERNIE3.0Titan。ERNIE3.0Titan擁有2600億的參數,參數量較GPT-3的1750億多出48.6%,在複雜知識推理能力上較GPT-3提升8個百分點。ERNIE3.0Titan已在60多項的NLP任務上取得了世界領先,在Super GLUE和GLUE都超過了人類排名第一的水平。
ERNIE3.0與GPT系列相比,其最大特點在於採用多範式統一的大規模預訓練框架,融合了自迴歸網絡+自編碼網絡,並在訓練時引入大規模知識圖譜類數據。時至今日,百度文心一言已經與近500家頭部企業達成合作,行業覆蓋互聯網、媒體、金融、保險、汽車、企業軟件等。
而且和ChatGPT相比,前者由於其背後公司的侷限性,在中文領域使用體驗遠不如英文,百度佔據地利優勢,正如李彥宏所説,百度的文心大模型是中國市場非常本土化的大語言模型,這意味着百度現在正在研發的文心一言,將比國外開發的模型更適合中文和中國市場。
正如中國數實融合50人論壇智庫專家、國研新經濟研究院創始院長朱克力所説:在AI大賽場的主賽道中,百度已佔據國內賽道第一身位。這也回答了,為什麼在全球羣雄爭霸的背景下,依舊是百度最先推出了大語言模型文心一言。

文心一言能帶來多少改變
在今年2月的AI+工業互聯網高峯論壇上,百度智能雲宣佈**“文心一言”**將通過百度智能雲對外提供服務。
百度智能雲採用雲智一體架構,以雲計算為基礎,以AI為抓手,藉助百度大腦、飛槳平台等對傳統生態輸出AI能力,為企業和開發者提供全球領先的人工智能、大數據和雲計算服務。
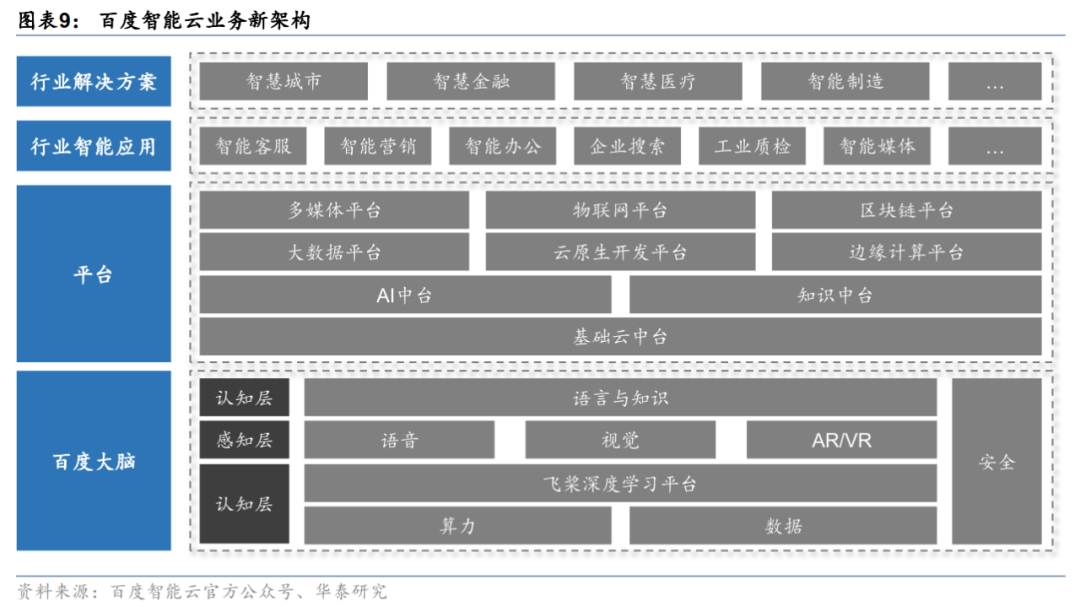
**值得注意的是,大語言模型接入智能雲,將直接改變雲市場遊戲規則。**雲服務從數字時代躍遷至智能時代,之前選擇雲廠商更多看算力、存儲等基礎雲服務,未來,更多會看框架好不好、模型好不好,以及模型、框架、芯片、應用之間的協同。這一趨勢下,百度“雲智一體”戰略也將體現出更強競爭力,百度智能雲有望進入新一輪高質量增長週期。
**按照規劃,文心一言會率先落地在百度搜索。**在李彥宏看來,文心一言將重塑信息的生成和呈現方式,推動搜索體驗的代際變革,並作用於百度移動生態服務場景與市場規模的擴大。一方面帶來更好的搜索和答案,另一方面提供全新的交互和聊天體驗,以及獨特的生成內容,極大地豐富內容生態和供給,吸引更多用户,並有機會形成新的流量入口。
**根據百度財報,**公司現階段經營利潤和現金流的重要來源依舊是百度移動生態,其中2022年第四季度移動端搜索查詢次數和信息流分發量繼續實現同比兩位數的增長。今年12月,百度App月活躍用户達到6.48億,同比增長4%。
**百度移動生態能保持如此穩定的增速,主要得益於公司長期穩定的研發投入,**根據百度財報,2022年百度核心研發費用214.16億元,佔百度核心收入比例達到22.4%。2022年四季度,百度研發投入為56.58億元。
回顧百度轉型AI至今的十多年裏,即便是在最困難的時候,公司在縮減預算的時候,**百度唯一不變的一個前提,就是絕不減少技術投入。**公司創始人李彥宏不止在一個場合強調,如果百度只有一塊錢,也會投到技術裏。
這絕不是李彥宏一面之詞,在2021年中國民企500強名單中,百度位列技術研發強度排名第一,保持着高達23%的研發投入。
正如“互聯網+百人會”發起人張曉峯所説:當一家科技企業連續十二年將營業額的15%以上投入人工智能研發,我們值得認真聽取他們的聲音。這是上萬科技人、數千億投入厚積薄發的**“科技的聲音”**。
當一家企業持續打造開發者開源生態、協同創新生態、各得其所產業生態,追隨者、協同者會逐步破除疑慮、擁抱生態大協同,這是“生態的力量”。
百度能在這波AI潮中迅速反應並整合已有技術框架及模型,成為國內最先官宣產品模態的民營企業,這屬實是行業佼佼者。

常年積累鑄就文心大模型
正如前文所述,文心大模型的問世需要長期積累,在公司轉型AI後,百度於2013年正式開始深度學習技術的投入,2017年百度還牽頭籌建了深度學習技術及應用國家工程實驗室,2021年升級為研究中心,這也是中國唯一一個深度學習國家級研究中心。
基於這個研究中心,百度打造了中國首個自主研發、開源開放的產業級深度學習平台飛槳。飛槳包含了核心的開發框架,包含完善的訓練,推理,部署能力,有豐富的基礎模型庫,端到端的開發套件和工具組件。考慮到用户需求,還分別提供了零門檻AI開發平台EasyDL和全功能AI開發平台BML,同時還有AI Studio學習與實訓社區來幫助開發者成長。
現在來看,飛槳有大量在產業實踐當中沉澱出來的模型,並提供官方的支持,能夠保證開發者的應用效果是最佳的、真正可靠的。為了降低產業應用人工智能的門檻,實現最後一公里的適配問題,飛槳和30多家芯片廠商進行了適配,極大的降低了企業應用人工智能的門檻。飛槳還提供大規模分佈式訓練能力,可以支持超大模型的訓練任務。
經過多年的投入,目前飛槳在中國深度學習市場應用規模第一,擁有龐大的生態體系,截至2022年11月,有535萬開發者,20萬家企事業單位,創建了67萬個模型。
可以説飛槳是我們訓練大模型,打造文心大模型,以及未來即將上市一言的堅實基礎。沒有這樣一個穩定可靠,性能極致的深度學習平台,那麼是很難打造中國自己的大模型能力的。
大模型的主要作用就是解決重複數據標註的麻煩,需要通過學習大量無標註的數據來做預訓練,增加整體模型前期學習的廣度和深度,這樣可以提升大模型的知識水平,就能降低成本,從而提高適應性,提升大模型在後續任務中的應用效率。
在實際操作過程中,預訓練大模型在基於海量數據的自監督學習的階段,完成了“通識”教育,再借助“預訓練+精調”等模式,帶來了新的AI研發方式,所以讓AI模型可以更統一、更簡單的方式下規模化生產。
對於百度而言,文心大模型除了可以推出類ChatGPT產品外,還可以全面接入百度地圖、Apollo、小度、愛奇藝等百度系產品,對社會而言,文心大模型在推動自動駕駛、智能交通業務方面,也會發揮關鍵作用。
比如在通用大模型基礎上,建立交通行業大模型,形成智能信控、智慧停車、智慧高速等解決方案。在智能信控方面,通過讓紅綠燈能“數車”,讓車能“讀秒”等,可以提升15%-30%的通行效率,從而推動GDP2.4%-4.8%的增長。
換言之,文心大模型是一個可以充分降本增效的工具,可以用於各行各業,而不僅侷限於人機對話交流領域,這也是類chatgpt產品能引起社會關注,資本湧入的主要原因。
據2023年數智金融峯會信息,“對於金融行業來説,文心一言將率先在智能檢索、投研助手、金融數字人、智能客服、智能創作等場景落地”。其他落地場景或將包括智能客服、智能對話、智能創作、知識管理等內容、信息相關的場景。關於百度文心大模型的具體應用效果,值得市場期待。
未經許可,請勿轉載。