李彥宏拯救了打工人?_風聞
酷玩实验室-酷玩实验室官方账号-03-18 08:41
昨天下午我跨越半個北京,去後廠村圍觀了百度文心一言的發佈會,李彥宏和他們那個CTO王博士巴拉巴拉講了一個多小時,我中間不小心睡着了。
主要是我這段時間經常玩ChatGPT,前一天還熬夜看了OpenAI的GPT-4發佈會,體驗了一點小小的美國震撼。相比之下,百度這個文心一言在功能和技術上實在是乏善可陳,Robin和王博士講話的語氣都明顯缺乏信心,甚至現場功能演示居然都不是實時AI問答,而是提前錄好的,那還玩什麼?
在回來的路上,我打開手機,果不其然,百度的股價盤中一度暴跌10%,最終跌幅6.36%,收於125.1港元。
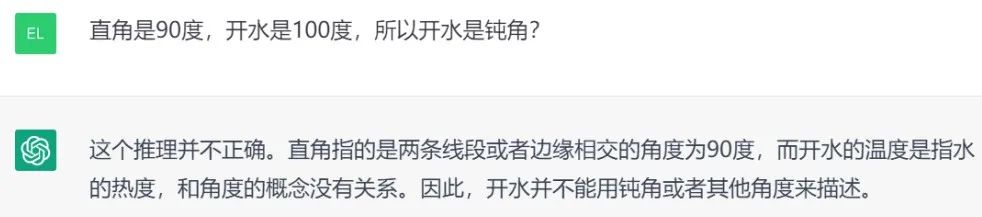
昨天晚上,我終於收到了文心一言的內測碼,試玩之後我又被震撼到了,因為這孩子真的很笨。
算個自然數加法居然得出了X,題目還抄錯了。

讓它用李白的風格寫一首詩讚美江南美景,它給了首詩倒還不錯,就是看着有點眼熟。

一查發現,是白居易的《憶江南》。。。
跟ChatGPT做個鏡像問題PK,更是高下立判,不忍直視。


涉及到中文“一語雙關”的問題,還不如ChatGPT這個“老外”。

晚上我跟幾個妹子討論半天,看來李彥宏搞AI屬於選錯了賽道,他保養得那麼好,乾脆轉型直播賣護膚品,肯定能賺更多,豈不美哉?

(純屬廢話文學)
然而一覺醒來,百度美股大漲3.8%,今天百度港股更是暴漲13.67%,來到了142.2港元。
我想這足以説明,在昨晚內測碼少量發佈之後,投資人確認到,百度確實自主研發出了還算能用的AI大語言模型,而僅僅確認到這一點,就足以讓百度轉危為安,市值狂飆400多億港幣。
恐怖如斯啊。
ChatGPT爆火之後,我經常看到我們羣裏有朋友説這玩意兒沒啥用,賺不了錢,這就是一陣風過段時間就涼了。他們或是因為對於AI技術缺乏瞭解,或是怕被AI搶了工作,或是因為對中國AI缺乏信心,又樸素地希望中國能贏,導致他們主觀希望一項來自美國的科技創新沒有改變競爭格局的能力。
然而遺憾的是,這並不是事實,類似ChatGPT、文心一言、Stable Diffusion這樣的AI大模型必然會改變世界影響到我們每個人,只存在時間早晚的問題,這是我們必須抓住的時代變革。
01
服務的大機器生產
18世紀後半葉,發生了人類迄今為止影響最大的事件,工業革命。
基於大航海時代掠奪到的財富和長期征戰促進的技術積累,在英國出現了幾項重要的發明,改良蒸汽機、珍妮紡紗機,進而從紡織業開始,製造業逐步邁入了大機器生產時代。
大機器生產這種模式從西歐開始擴展到北美、東歐、東亞,再因為集裝箱互聯網數控設備的發明,全球供應鏈被連為一體,於是從布匹成衣到鍋碗瓢盆,從汽車飛機到電腦手機,在手工業時代只有少數王公貴族有錢人才能用得起的工業品,變得廉價,變得不再稀缺,走進了尋常百姓家。
在如今的工業化國家比如中國,除非一樣商品需要稀缺的原材料才能生產(黃金首飾),或者它被賦予了特殊的意義(豪車,房子),不然整體都是很便宜的。80年代家裏到結婚的時候才會備齊三大件電器(電冰箱,電視機,洗衣機),現在隨便一個城市家庭的電器大大小小都有幾十件,甚至商家需要進行廣告轟炸,不停地消費主義洗腦才能促進大家買東西,實在是有剛需的東西該買的都買了,需求不足了。
然而大家的需求都被滿足了嗎?大家都很枯燥了嗎?並沒有。
因為服務依舊昂貴,依舊稀缺。人類的需求本質上是服務,而不是產品。
我買電動牙刷不是為了擁有它,而是為了刷牙,保持口腔健康。這是我對自己的服務。
我買鍋碗瓢盆空氣炸鍋不是為了擁有它們,而是為了做飯家裏人一起吃飯看電視,這是我對家人的服務。
我買車不是為了開車,而是為了通勤,有錢人開車一般是開着玩,他們通勤是有司機的,這是人對人的服務。
順豐買波音777不是為了擁有它,而是為了幫客户送貨,這是公司對公司服務。
對自己對家人的服務是靠我投入昂貴的時間精力才能完成的,而人對人、公司對公司的服務就更是稀缺而昂貴,需要投入大量的教育培訓,組織管理,才能實現。
服務的大機器生產沒有被完成!
我今年30多歲,我有生以來出現的最大的生產力革命是移動互聯網革命,大約2007年開始,2018年結束。智能手機和3G、4G網絡的普及使得互聯網從只能覆蓋部分時間,部分地點,部分人,擴展到覆蓋任何人任何地點所有睜眼的時間,於是我們所有人的需求和所有能提供服務的人就被網絡連接了起來,產生了聊天、上網課、外賣、打車、上門鐘點工、餐館評分、代做設計、代做ppt、代寫文章等等在線服務形式,在互聯網巨頭的操持之下,服務的大機器生產在部分領域得以實現。
現在我們不再需要站在路邊等出租車了,而是可以叫一輛車在我家樓下等我,這在以前是隻有大老闆、大領導才能擁有的待遇。
但是我大望京晚上11點還是打不到車。
這就涉及到一個根本的問題了。移動互聯網只能連接服務提供方和需要服務的人,確實可以解決司機閒着找不到乘客的問題,但如果司機不夠了呢?
如果幫你畫畫的畫師不夠了呢?如果寫文章的寫手不夠了呢?如果好的老師不夠了呢?
如果找不到小哥哥/小姐姐陪你聊天呢?如果你的級別不夠配秘書,所有文件都要自己寫呢?如果公司沒錢請客服呢?
雖然AI大模型還沒有進化到完美的程度,特別是它還沒有找到匹配的機器人身體,但在一些體量頗大的賽道上,它已經能提供不錯的服務:
比如廣泛意義上的內容服務:做網站、寫代碼、畫圖、寫詩、水文章、寫ppt,特別是如果這個內容服務不涉及原創而只是對現有內容的處理的話,類似翻譯、歸納文章要點、把提綱擴寫成文章,改文章風格等等,AI已經能比人類做得更好。
再比如很多商業上的流程服務,我有個朋友是做客服軟件的,就是那種你上一個比如汽車網站,蹦出來一個對話框,客服問你想買什麼價位什麼用途的汽車那種。接下來客服會把你的需求總結成清單,給到銷售,然後銷售會打電話聯繫你。這個總結客户需求的工作,AI做得比人快得多而且更準確。
還有比如我有很多二次元的朋友,他們對虛擬人物的代入感很強,但虛擬動畫人物背後必然是有編劇和中之人(虛擬直播演員)的,他們的服務產能有限,這導致必然出現很多人粉一個二次元老婆/老公的情況,這很不理想。ChatGPT和數字虛擬人的結合,可以讓每個人擁有獨屬於自己的二次元戀人,想想就有點激動。
很多公司大了之後,老闆就不知道底下人在幹什麼了,國家的領導人也是如此,你再怎麼深入基層你一天也只有24個小時,能逛幾個菜市場?因此大組織的治理必然會出現層層傳遞信息的情況,而由於中間每一層的人都有自己的利益,這一傳信息肯定會失真。而AI的數據處理能力要比人類大得多,我想以後所有大組織的領導人都應該用到一個功能,“把今天14億人對政府工作報告的反饋(1萬個T文件)總結成800字報告發我”,以後所有組織信息傳遞再也不應該有中間層。
AI將完成服務的大機器生產。
02
超越人類
更進一步來説,現在的AI大模型不僅能批量複製人類的工作,它已經能完成很多人類無法完成的工作。
要理解這一點,我們必須要了解AI的工作方式。
比如説這是一張末代皇后婉容的照片。

用AI模型上色之後,就成了這樣。

其實它還可以有很多別的配色。

那它是怎麼完成黑白照片上色的呢?如果讓我這個人類去給這張照片上色的話,我能想到兩種方法:
方法1:我先去調查婉容這件衣服的材質,甚至嘗試去找到這件衣服本體,再結合史料上拍這張照片的時間地點,當天的天氣,再找到拍照片用的相機和交卷都是什麼型號,有什麼曝光特點,確定一種最有可能的顏色給它塗上去。
這種方法叫做分析推理。
方法2:我隨便找個看着不突兀的顏色就給它塗上,然後所有的背景事物照此操作,最後出來照片像那麼回事兒就行。因為我看過很多女人穿着衣服的彩色照片,也看過很多清宮劇,那個味兒我還是很熟悉的。
這種方法我們姑且稱之為套模板,或者説內味兒法。
AI並不擅長分析推理,但它非常擅長找出內味兒然後總結成模板到處套,非常、非常地擅長。
這就是為什麼AI畫出的人像味兒很對,但是手指頭老是出錯。

這也是為什麼AI寫的論文經常一本正經地胡説八道。
(翟老師是人大的)
不能準確呈現要點和細節當然是AI相對聰明人的缺陷,但它尋找內味兒的能力或者説總結模板的能力實在太強了,遠超人類。
比如説ChatGPT可以把你的同一篇文章改成李白風格,李清照風格,小學生作文,申論風格。
比如説Midjourney可以把你的文字生成為畢加索風格,梵高風格,張大千風格,克蘇魯風格。
再比如前兩天我讀到一篇日本大阪大學兩位學者的論文,他們字面意義上發明了讀心術。
有一種醫療診斷技術叫做fMRI(功能性磁共振成像),可以觀測記錄到大腦血流的微小變化。
我們認為大腦在工作的時候,比如説看一張圖片,必然會導致各部分的神經元產生不同的能量氧氣的需求,進而導致血流量的微小變化,而這個數據可以通過fMRI記錄下來。
那有沒有可能這種血流的微小變化數據,跟我們現在看到的圖像存在對應的關係呢?當然是有可能的。但是這裏這個對應的模板,這個味兒太複雜了,完全超出了人腦的理解能力。
而這個日本團隊用一個叫做Stable Diffusion的AI模型,利用fMRI數據,畫出了這樣的圖像。

患者看到的原圖是這樣的。

再看一些別的。

(圖中出現真人的部分為了保護隱私擋了一下)
難道我18歲了臉上還沒有長攝像頭的症狀可以治好了嗎??
同樣的操作當然可以用來推測蛋白質構型,天氣預報,也可以基於你手環的數據推測你的身體狀況,有沒有什麼疾病。
任何你知道兩件事情有關係但不知道有什麼關係的問題,都可以用AI解決。
我們不知道它還能幹什麼
語言交互AI已經出現很多年了,但一直被稱為人工智障,直到ChatGPT的出現。
我車上有個語音AI叫Nomi,可以用它來導航、點歌,有時候它在隨機放歌的時候突然放到一首朴樹的NewBoy,我意識到已經好久沒聽朴樹的歌了,於是我對Nomi説:
“請幫我播放朴樹的歌。”
Nomi回答:
“我現在就是在放朴樹的歌啊。”
我吐血。
這就是ChatGPT跟之前的智障型AI最大的區別,ChatGPT顯然有一定的情商,能讀得懂我們的潛台詞,而之前的AI不行。那這種情商是怎麼來的呢?是因為OpenAI團隊發明了什麼新的AI算法嗎?
ChatGPT的核心算法叫做Transformer,來自谷歌2017年的一篇論文《Attention is All You Need》。
然而谷歌並沒有第一個做出ChatGPT,2018,2019,2020,2021年,都沒有人做出ChatGPT,直到2022年11月30日OpenAI團隊才發佈了ChatGPT。
OpenAI做了什麼特別的操作從而完成了這項壯舉呢?
當然不排除有一些調參細節也很重要,但真正顯著的不同來自於它用了所謂大模型,它把深度神經網絡的參數堆到了1750億這個驚人的數量,類比到人腦的話相當於有1750億個神經元。
這點實際上令AI學術圈非常不滿,因為做學術的人總是想我能怎麼樣發明個新東西新結構,巧妙地解決看似困難的問題,如此一來自然顯得我很吊,但是OpenAI完全就是暴力美學,把整個AI學術圈的逼格破壞得一乾二淨。
這同時它也向我們展示一種令人不寒而慄的可能性,如果説情商、棋力、藝術風格甚至分寸感,這種原本我們認為獨屬於人類,玄之又玄的智能,僅僅是神經連接多到一定程度的自然湧現的話,
那情緒呢?慾望呢?愛情呢?自我意識呢?
現在AI模型的算力需求每隔三到四個月就會翻一番,比當年摩爾定律還要誇張。
如果模型參數再擴大一百倍,一萬倍,一億倍呢?
你現在去問ChatGPT會不會產生自我意識,他的回答是這樣的。
但事實是,這個答案是OpenAI給它灌的標準答案,它並不知道。
沒有人知道。
03
李彥宏拯救了打工人?
很多年以後,當他們回望21世紀初的世界,ChatGPT必然是濃墨重彩的一筆,因為這意味着人類一次進化的開始,也可能是一種新人類取代他們造物主的開始。
因為一些中美科技戰愈演愈烈,ChatGPT並沒有向國內用户開放,即便它開放我國也不可能把數據開放給它,這波可謂雙向奔赴。所以昨天百度文心一言的內測結果不理想之後,很多人發文慶祝:“大家不要慌,工作保住了!”“李彥宏拯救了打工人!”
但我們要知道,ChatGPT剛發佈的時候,也不是很好用,是靠後續用户持續反饋數據持續訓練三個多月,才進化成現在這個樣子。當文心一言發佈之後,一旦大量用户開始使用,因為同樣的邏輯,它也將開始進化之旅。更別提Google、騰訊、阿里的大模型也都在伺機待發。
我覺得可以適當慌一下了。
機能高智慧,狀似千年仙。
無情不見悲,非君莫能權。
創意頻萌動,語言卓無間。
人生苦短過,AI如風煙。
(此詩由ChatGPT創作)
如果你的工作只涉及到套模板,你得考慮轉行了。
如果你的工作涉及到分析推理,把ChatGPT或者文心一言用起來,它會讓你更加強大。