黃仁勳帶來“王炸”組合,ChatGPT又進一步_風聞
DoNews-03-22 17:52

撰文 | 田小夢
編輯 | 楊博丞
題圖 | NVIDIA
3月22日,在剛剛結束的GTC 大會上,NVIDIA創始人兼首席執行官黃仁勳圍繞AI、芯片、雲服務等前沿科技,帶來一系列“殺手級”技術和產品。
從OpenAI發佈GPT-4,到百度發佈文心一言,再到微軟將GPT-4接入自己全套辦公軟件Microsoft 365 Copilot,乃至昨日谷歌正式宣佈開放 Bard 的訪問權限。在這AI的決定性時刻,黃仁勳也是激動地三次強調,“我們正處於AI的iPhone時刻”。
“如果把加速計算比作曲速引擎,那麼AI就是動力來源。生成式 AI 的非凡能力,使得公司產生了緊迫感,他們需要重新構思產品和商業模式。”黃仁勳説道。
手握算力技術的英偉達自然是不會缺席AI產品。自今年年初ChatGPT爆火後,吸引了超過1億用户,成為有史以來增長最快的應用。英偉達的股價也是一路飆升,目前英偉達市值為6471億美元。
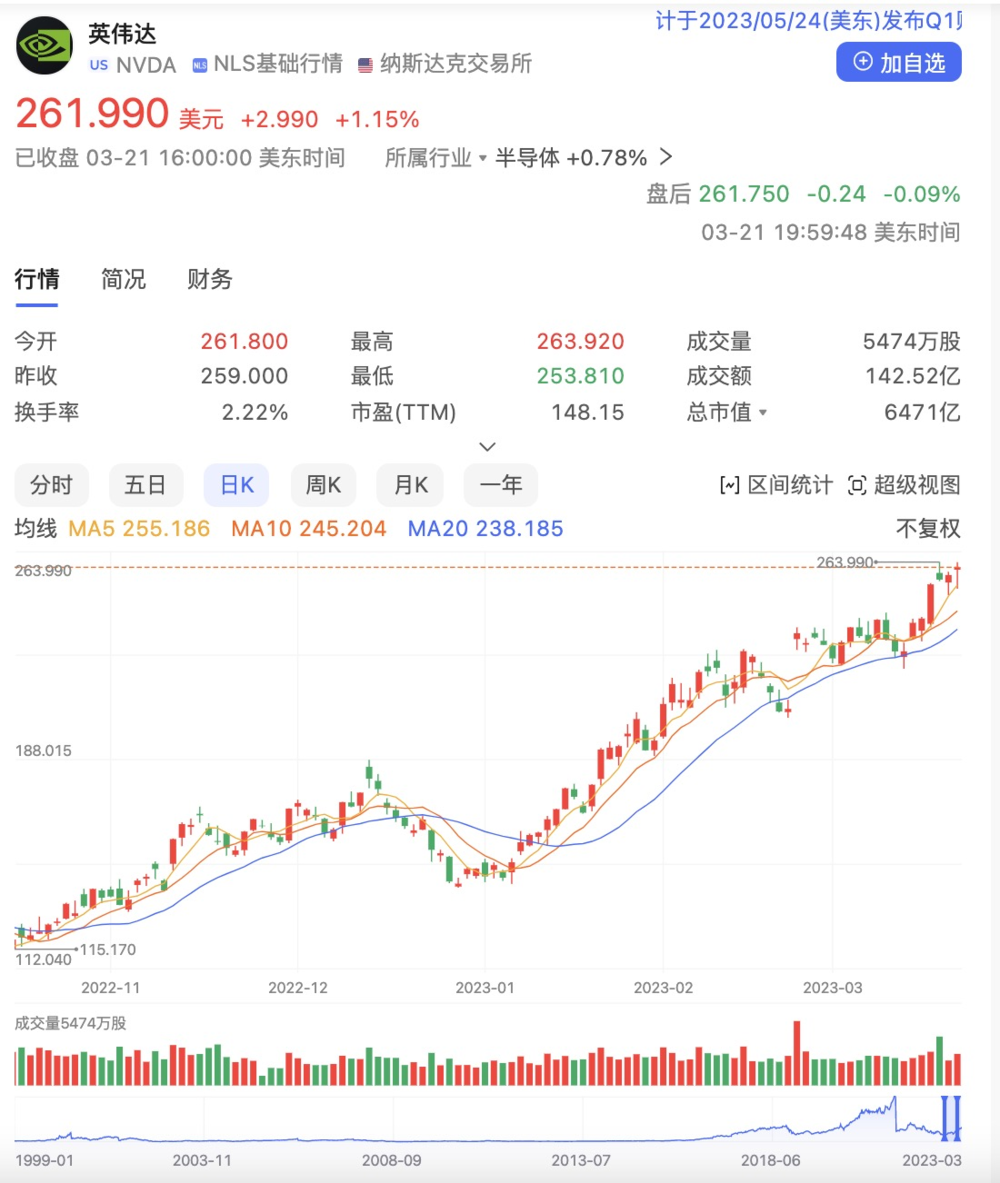
圖片來源:百度股市通
一、做AI界的“台積電”
自十年前AlexNet面市以來,深度學習就開闢了巨大的新市場,包括自動駕駛、機器人、智能音箱,並重塑了購物、瞭解新聞和享受音樂的方式。隨着生成式AI掀起的新一波浪潮,使得推理工作負載呈階梯函數式增長。
對此,今日英偉達推出全新的推理平台:四種配置—一個體系架構—一個軟件棧,其中,每種配置都針對某一類工作負載進行了優化。

首先,ChatGPT等大型語言模型是一個全新的推理工作負載,GPT模型是內存和計算密集型模型。同時,推理是一種高容量、外擴型工作負載,需要標準的商業服務器。為了支持像ChatGPT這樣的大型語言模型推理,黃仁勳發佈了一款新的GPU——帶有雙GPU NVLink的H100 NVL,配備94GB HBM3顯存,可處理擁有1750億參數的GPT-3,還可支持商業PCIE服務器輕鬆擴展。
黃仁勳表示,目前在雲上唯一可以實際處理ChatGPT的GPU是HGX A100,與適用於GPT-3處理的HGX A100相比,一台搭載四對H100及雙GPU NVLINK的標準服務器的速度快10倍。“H100可以將大型語言模型的處理成本降低一個數量級。”
其次,針對AI視頻工作負載推出了L4,對視頻解碼和編碼、視頻內容審核、視頻通話功能等方面進行了優化如今,大多數雲端視頻都在CPU上處理,一台8-GPU L4服務器將取代一百多台用於處理AI視頻的雙插槽CPU服務器。Snap是NVIDIA AI 在計算機視覺和推薦系統領域領先的用户,Snap將會把L4用於AV1視頻處理生成式AI和增強現實。
再者,針對Omniverse、圖形渲染等生成式AI,推出L40,L40的性能是NVIDIA最受歡迎的雲推理GPU T4的10倍。Runway是生成式AI領域的先驅,他們正在發明用於創作和編輯內容的生成式AI模型。
此外,為用於推薦系統的AI數據庫和大型語言模型,推出了Grace Hopper超級芯片。通過900GB/s高速芯片對芯片的接口,NVIDIA Grace Hopper超級芯片可連接Grace CPU和Hopper GPU。“客户希望構建規模大幾個數量級的AI數據庫,那麼Grace Hopper是最理想的引擎。”
與此同時,面對生成式AI的認知將重塑幾乎所有行業的現狀。黃仁勳坦言稱:“這個行業需要一個類似台積電的代工廠,來構建自定義的大型語言模型。”
為了加速企業使用生成式AI的工作,黃仁勳發佈了NVIDIA AI Foundations雲服務系列,為需要構建、完善和運行自定義大型語言模型及生成式AI的客户提供服務,他們通常使用專有數據進行訓練並完成特定領域的任務。
NVIDIA AI Foundations包括NVIDIA NeMo是用於構建自定義語言文本-文本轉換生成模型;Picasso視覺語言模型製作服務,適用於想要構建使用授權或專有內容訓練而成的自定義模型的客户,以及BioNeMo,助力2萬億美元規模的藥物研發行業的研究人員,幫助研究人員使用他們的專有數據創建、微調和提供自定義模型。
二、加深雲服務體系
“雲”也是此次發佈會的重點之一,推出了NVIDIA DGX Cloud。
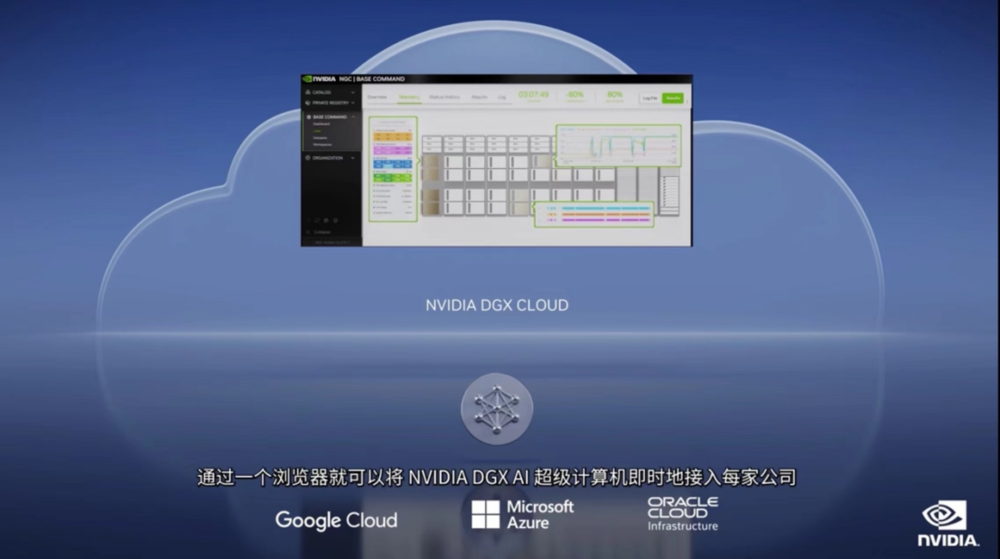
這項AI超級計算服務使企業能夠即時接入用於訓練生成式AI等開創性應用的高級模型所需的基礎設施和軟件。DGX Cloud可提供NVIDIA DGX AI超級計算專用集羣,並配以NVIDIA AI軟件。
這項服務可以讓每個企業都通過一個簡單的網絡瀏覽器就能訪問自己的AI超級計算機,免除了購置、部署和管理本地基礎設施的複雜性。
黃仁勳表示:“初創企業正在競相打造顛覆性的產品和商業模式,老牌企業則在尋求應對之法。DGX Cloud 使客户能夠在全球規模的雲上即時接入NVIDIA AI超級計算。”
目前,NVIDIA正與領先的雲服務提供商一起託管DGX Cloud基礎設施,Oracle Cloud Infrastructure(OCI)首當其衝,通過其OCI超級集羣,提供專門構建的RDMA網絡、裸金屬計算以及高性能本地塊存儲,可擴展到超過32000個GPU所組成的超級集羣。微軟Azure預計將在下個季度開始託管DGX Cloud,該服務將很快擴展到Google Cloud等。
黃仁勳表示,此次合作將NVIDIA的生態系統帶給雲服務提供商,同時擴大了NVIDIA的規模和影響力。企業將能夠按月租用DGX Cloud集羣以便快速、輕鬆地擴展大型多節點訓練工作負載的開發。
隨着雲計算發展,在過去十年中,大約3000萬台CPU服務器完成大部分處理工作,但挑戰即將到來。隨着摩爾定律的終結,CPU性能的提高也會伴隨着功耗的增加。另外,減少碳排放從根本上與增加數據中心的需求相悖,雲計算的發展受功耗限制。
黃仁勳指出,加速雲數據中心的CPU側重點與過去有着根本性的不同。過去數據中心加速各種工作負載,將會減少功耗,節省的能源可以促進新的增長,未經過加速的工作負載都將會在CPU上處理。在AI和雲服務中,加速計算卸載可並行的工作負載,而CPU可處理其他工作負載,比如Web RPC和數據庫查詢。為了在雲數據中心規模下實現高能效,英偉達推出Grace。
Grace包含72個Arm核心,由超高速片內可擴展的、緩存一致的網絡連接,可提供3.2TB/s的截面帶寬,Grace Superchip通過900GB/s的低功耗芯片到芯片緩存一致接口,連接兩個CPU芯片之間的144個核,內存系統由LPDDR低功耗內存構成(與手機上使用的相似),還專門對此進行了增強,以便在數據中心中使用。

通過Google基準測試(測試雲微服務的通信速度)和Hi-Bench套件(測試Apache Spark內存密集型數據處理),對Grace進行了測試,此類工作負載是雲數據中心的基礎。
在微服務方面,Grace的速度比最新一代x86 CPU的平均速度快1.3倍;在數據處理中,Grace則快1.2倍,而達到如此高性能,整機功耗僅為原來服務器的60%。雲服務提供商可以為功率受限的數據中心配備超過1.7倍的Grace服務器,每台服務器的吞吐量提高25%。在功耗相同的情況下,Grace使雲服務提供商獲得了兩倍的增長機會。

“Grace的性能和能效非常適合雲計算應用和科學計算應用。”黃仁勳説道。
三、為2納米光刻技術奠基
隨着對芯片製造的精確度提升,當前生產工藝接近物理學的極限。光刻即在晶圓上創建圖案的過程,是芯片製造過程中的起始階段,包括光掩模製作和圖案投影。
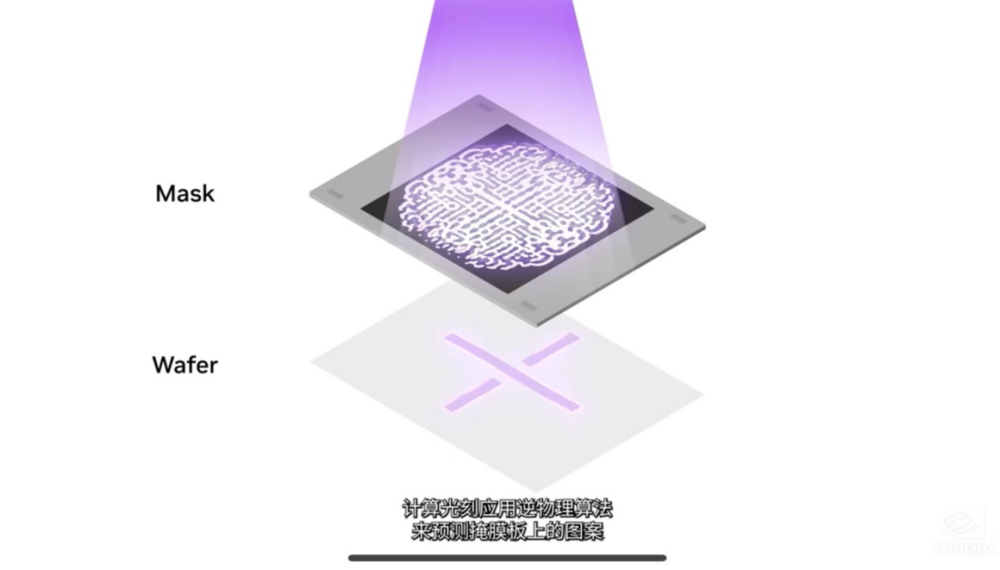
其中,計算光刻是芯片設計和製造領域中最大的計算工作負載,每年消耗數百億CPU小時,大型數據中心24 x7全天候運行,以便創建用於光刻系統的掩模版。數據中心是芯片製造商每年投資近2000億美元的資本支出的一部分,隨着算法越來越複雜,計算光刻技術也在快速發展,使整個行業能夠達到2納米及以上。
對此,在本次發佈會上,黃仁勳帶來了一個計算光刻庫——NVIDIA cuLitho。

“芯片產業幾乎是每一個行業的基礎。”黃仁勳介紹稱,cuLitho是一項歷時近四年的龐大任務,英偉達與台積電、ASML和Synopsys等密切合作,將計算光刻加速了40倍以上。
NVIDIA H100需要89塊掩模版,在CPU上運行時,處理單個掩模版當前需要兩週時間。如果在GPU上運行cuLitho,只需8小時即可處理完一個掩模版。
據介紹,台積電可以通過在500個DGX H100系統上使用cuLitho加速,將功率從35MW降至5MW,從而替代用於計算光刻的4萬台CPU服務器。藉助cuLitho,台積電可以縮短原型週期時間、提高產量、減少製造過程中的碳足跡,併為2納米及以上的生產做好準備。
此外,台積電將於6月開始對cuLitho進行生產資格認證,ASML正在GPU和cuLitho方面與NVIDIA展開合作,並計劃在其所有計算光刻軟件產品中加入對GPU的支持。
不難看出,從AI訓練到部署,從系統到雲服務,再到半導體芯片,黃仁勳打出了一套“組合拳”。站在AI的風口,黃仁勳也透露出“勝券在握”的信心。