AI合規觀察|從監管視角看AIGC應用中的數據合規問題_風聞
走出去智库-走出去智库官方账号-03-24 18:49

走出去智庫觀
生成式AI產品的全球發展正在你追我趕。3月15日,OpenAI 發佈多模態預訓練大模型 GPT-4,其更具創造力和準確性。不到****10天,OpenAI又在今天(24日)宣佈部分解除****ChatGPT無法聯網的限制。百度公司則搶下中國市場的頭彩,在3月16日宣佈開啓其生成式AI產品“文心一言”的邀請測試。
****走出去智庫(CGGT)觀察到,AIGC(人工智能生成內容)正在給人類社會帶來一場深刻的變革,但ChatGPT等AI技術在數據處理過程中存在多重潛在合規風險,如未經授權收集信息、提供虛假信息、侵害個人隱私等等。
AIGC產品如何做好數據合規管理?今天,走出去智庫(CGGT)刊發上海賽博網絡安全產業創新研究院高級研究員周雪靜的文章,供關注人工智能合規管理的讀者參閲。
要 點
CGGT,CHINA GOING GLOBAL THINKTANK
1、隨着人工智能的廣泛應用與實踐,我國對於人工智能的監管重點也從“發展”擴展到“AI倫理安全”“算法治理”等問題上,雖然針對AIGC專用數據集、算法設計和模型訓練的監管仍然有待完善,但整體框架體系已經具備。
2、人機之間的交互所產生的數據,可能被用於未來模型的迭代訓練,其中也會涉及大量個人信息。因此,AIGC服務提供者在個人或組織使用應用前,需將這一情形進行事前告知並取得單獨同意。
3、對於大規模訓練數據的收集、存儲、使用全生命週期進行規範,尤其是加強個人信息、重要數據的保護。此外,進一步加強對於訓練數據提供商的約束,要求其對於數據來源、數據交易及使用進行全流程安全監測。
正 文
CGGT,CHINA GOING GLOBAL THINKTANK
文/周雪靜
上海賽博網絡安全產業創新研究院高級研究員
作為近期科技圈的“頂流”,AIGC(AI Generated Content,人工智能生成內容)並非“新秀”。
AIGC發展歷程可以分為3個階段,以“圖靈測試”為代表性事件的早期萌芽階段(20世紀50年代至90年代中期)、從實驗性向實用性轉變的沉澱積累階段(20世紀90年代中期至21世紀10年代中期)、依託生成式對抗網絡GAN等技術及算法的快速發展階段(21世紀10年代中期至今)。
隨着AI生成的發展趨勢朝着多模態演進,AIGC正在帶來新一輪的科技和產業革命。新的機遇下,我國基於豐富的產業需求和應用場景,既要加快攻關關鍵技術、鼓勵發展創新應用,同時也要推動安全治理前置,在全球科技變革之際,搶佔賽道。
AIGC風險圖譜及監管體系
新興技術都會經歷從野蠻生長到安全合規的過程,AIGC同樣不可避免。當前,AIGC所帶來的安全風險成為重點議題。
作為AI應用發展的重要分支,AIGC的風險既包括AI倫理風險,也包括其特定算法應用所帶來的新型風險,比如更多的隱私保護憂患、智能代替人工造成的就業擔憂、算法對於市場競爭帶來的不公平以及著作權侵權等。
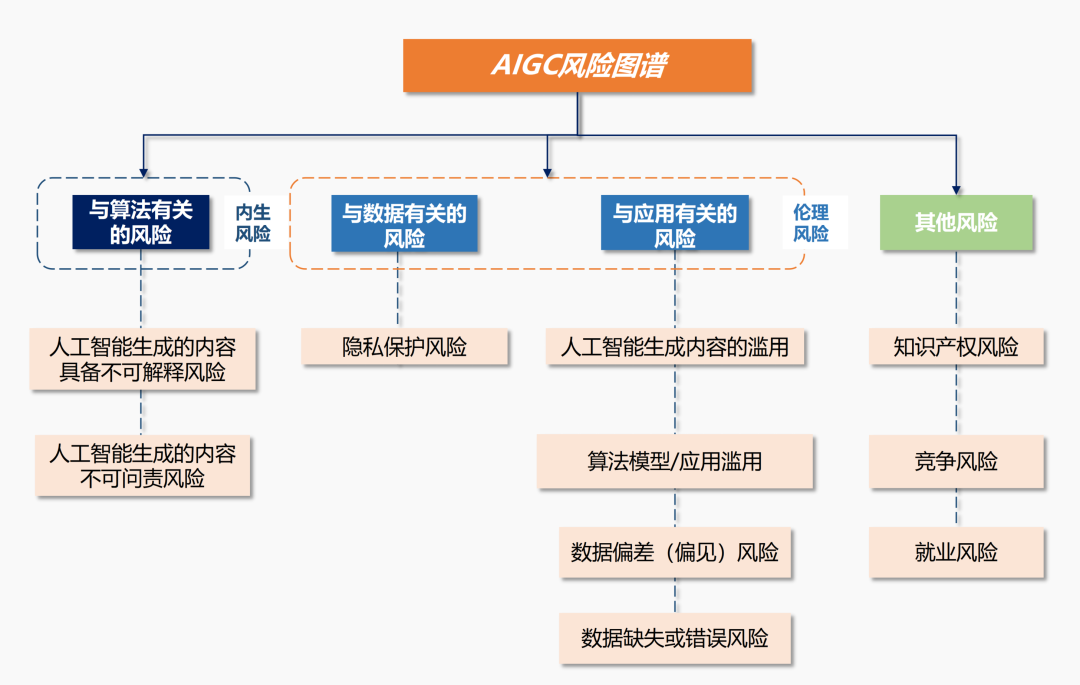
聚焦AIGC存在的風險,我國現有的監管體系已經成形。2017年以來,我國先後發佈一系列人工智能產業促進政策,推動人工智能技術創新和產業發展。
隨着人工智能的廣泛應用與實踐,我國對於人工智能的監管重點也從“發展”擴展到“AI倫理安全”“算法治理”等問題上,雖然針對AIGC專用數據集、算法設計和模型訓練的監管仍然有待完善,但整體框架體系已經具備。

從人工智能監管部門來看,我國呈現多頭監管的現狀,有關部門包括國家市場監督管理總局、國家互聯網信息辦公室、工業和信息化部、科技部等。
在法律法規層面,一方面是通過專門性綜合性立法對網絡運營者在使用人工智能技術的義務和責任進行規範,另一方面則是切實聚焦到人工智能領域的算法、模型、技術,進行具體規範。

2021年,先後發佈的《關於加強互聯網信息服務算法綜合治理的指導意見》《互聯網信息服務算法推薦管理規定》從算法治理的角度,對算法使用過程中的安全監測、算法評估以及算法推薦對個人信息主體帶來的影響等內容進行規範。
根據《規定》,算法推薦服務提供者應當在提供服務之日起十個工作日內通過互聯網信息服務算法備案系統(已經上線)進行備案(包括提供服務提供者的名稱、服務形式、應用領域、算法類型、算法自評估報告),且完成備案後需在對外提供服務的網站、應用程序等顯著位置標明備案編號等信息,目前已有百餘家企業完成備案。
2022年,國家網信辦、工信部、公安部聯合發佈的《互聯網信息服務深度合成管理規定》則聚焦“深度合成技術”“深度合成服務”。根據定義,深度合成技術,是指利用深度學習、虛擬現實等生成合成類算法制作文本、圖像、音頻、視頻、虛擬場景等網絡信息的技術。這一定義與AIGC的定義(人工智能生成文本/圖像/音頻/視頻等多模態內容)高度吻合,因此該規定可以視為規範AIGC技術及服務的重要參考。此外,在這一規定中,對於深度合成服務提供者、深度合成服務使用者、深度合成服務技術支持者三個主體的責任義務也作了進一步明確。
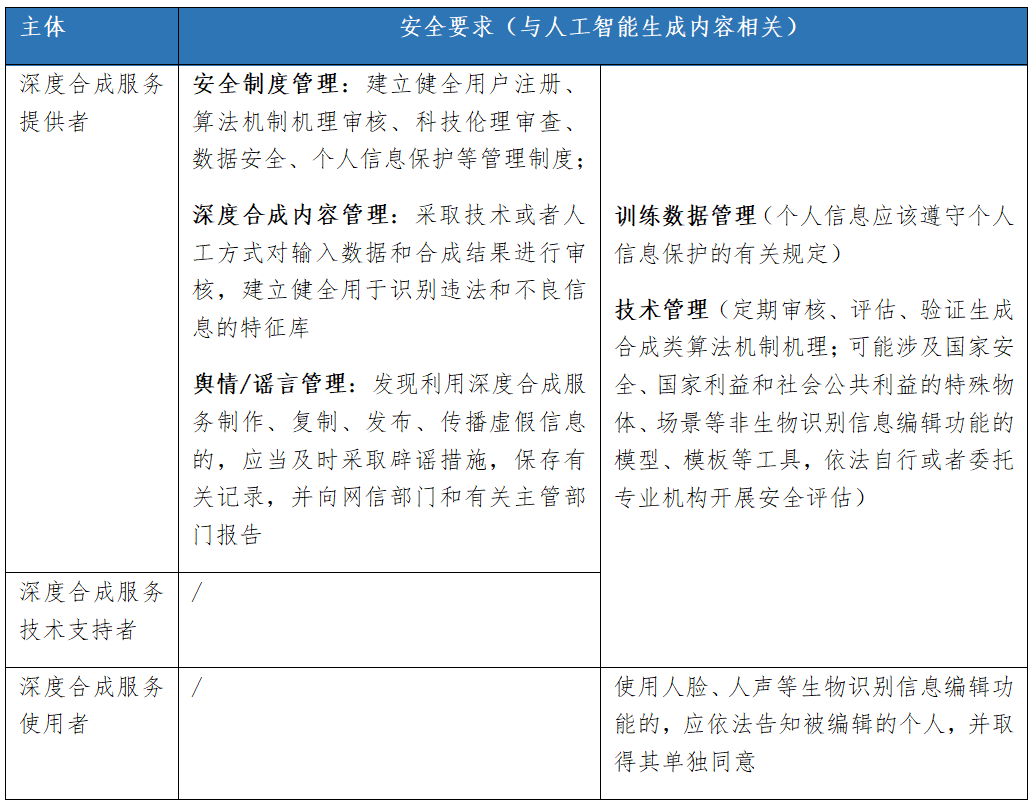
整體來看,雖然國內外暫無直接以AIGC為關鍵詞的立法,但鑑於AIGC以人工智能技術為基礎,是人工智能應用發展的一個分支,因此現有的人工智能監管體系也基本適用於AIGC,可作為重點參考。
人工智能和隱私的關鍵性重疊
如上所述,多個法律領域對於AIGC相關應用都有一定要求,而在隱私保護領域,一方面,AI相關的可解釋性、公平性、安全性和問責制在隱私法律法規中也有所體現;另一方面,AI成熟度的提高也離不開組織在隱私問題上的努力。可以説,AIGC發展路徑下,AI和隱私保護有着關鍵性的重疊。
目前,我國對於AIGC涉及的隱私問題,主要可以參考《個人信息保護法》《數據安全法》以及《數據出境安全評估辦法》等法律法規。
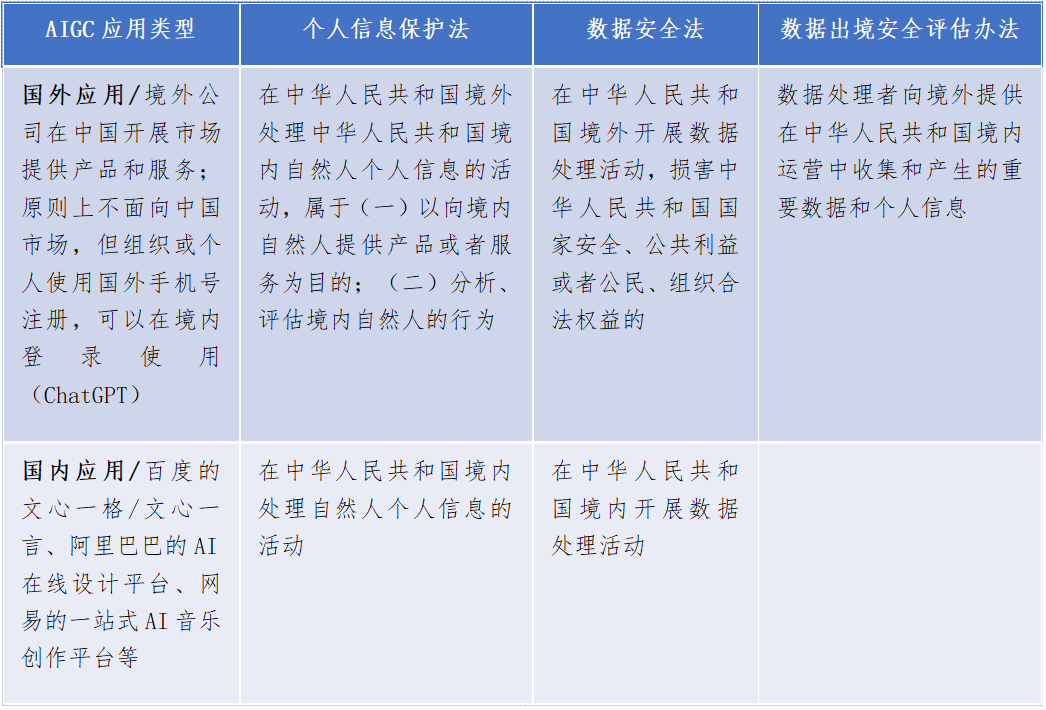
AIGC數據處理場景及對應的隱私風險
以ChatGPT為例,作為人工智能生成內容的熱門應用,ChatGPT在模型訓練階段、應用運行階段涉及海量數據的處理。
模型的成熟度以及生成內容的質量,都與訓練數據高度相關。與此同時,訓練數據集所包含的隱私風險也將映射到生成內容上。
階段1:模型訓練階段****
數據訓練的處理流程包括:數據採集、數據清洗、數據標註、模型訓練、模型驗證、實現目標。所謂訓練數據,是指“用於訓練 AI 模型,使其做出正確判斷的已標註數據/基準數據集”。
訓練數據的風險集中在數據採集階段,即數據處理者在處理訓練數據中的個人信息前,是否盡到告知同意的基本責任,確保個人信息處理的合法性、正當性、必要性。數據清洗階段和數據標註階段,是將收集到的數據進一步處理成機器可讀、便於訓練的訓練數據,這一階段對於數據的審核和梳理,也是進一步緩釋訓練數據風險的補充措施,即審核數據集中是否包含大量可識別的個人信息或敏感個人信息。
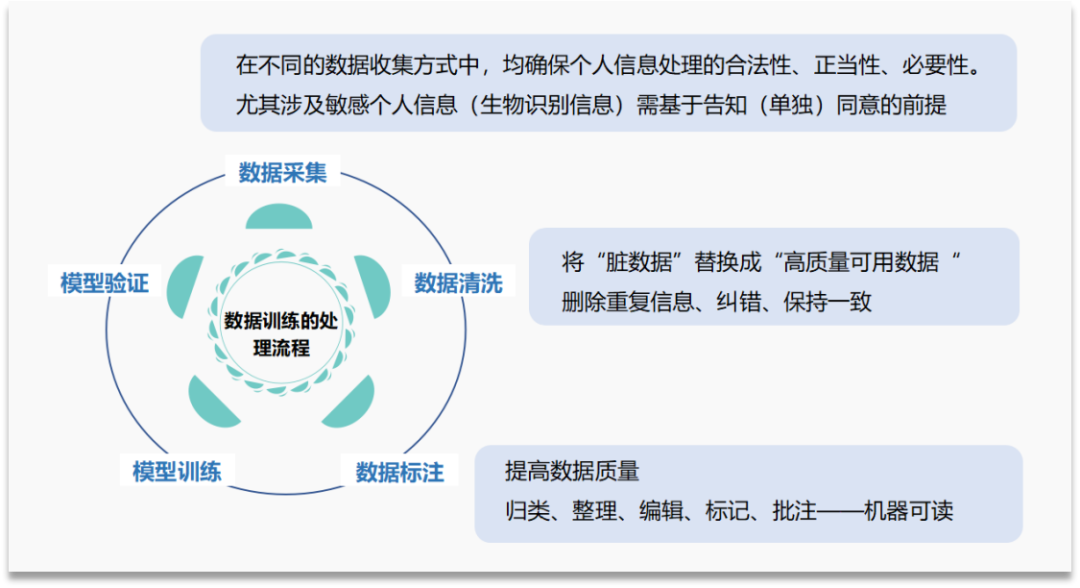
當前,訓練數據來源可以分為兩類,一是網絡數據,二是合成數據。
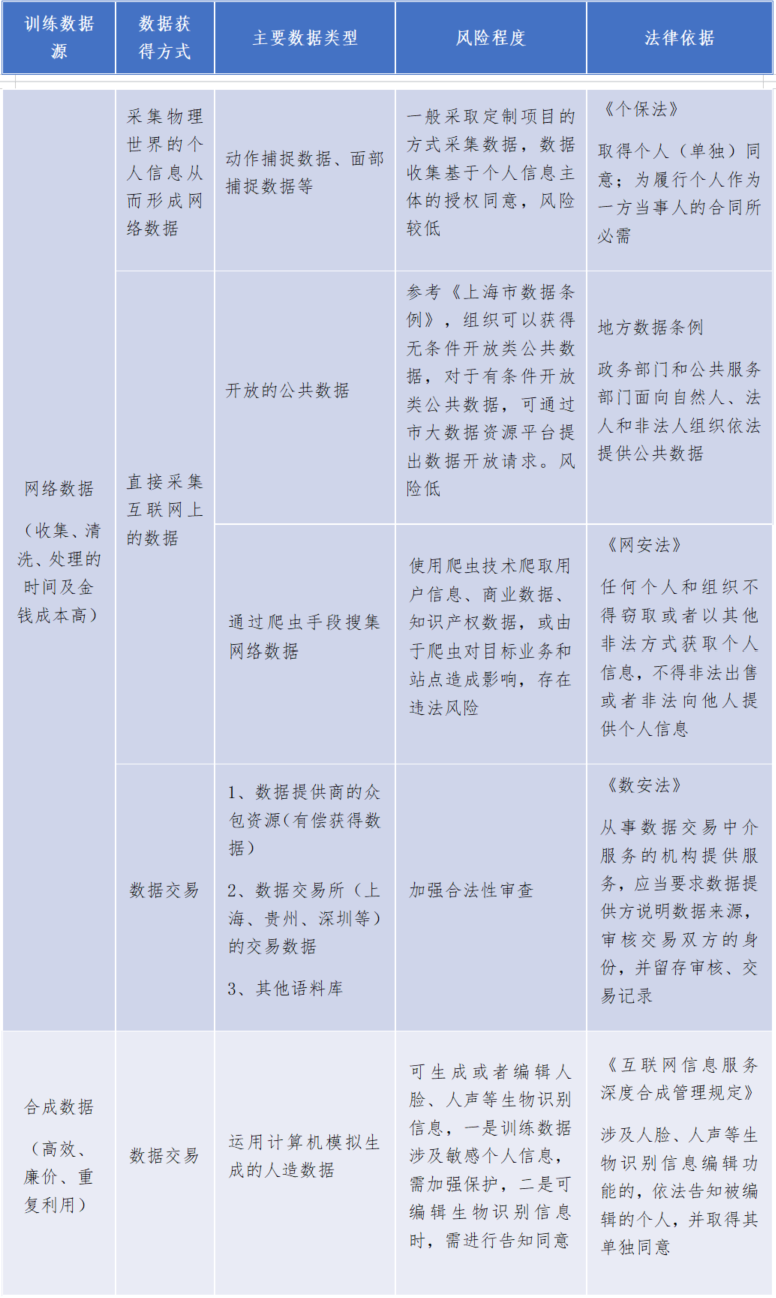
網絡數據的來源包括:
①採集物理世界的個人信息從而形成網絡數據,常見的是動作捕捉(Motion Capture)數據,即通過實時跟蹤和記錄自然人(被測試者)的身體運動信息、面部表情,將其轉化為網絡數據,用於虛擬人生成等領域。由於動捕數據包含個人身體動作、姿勢和行為等信息,可以用於分析個人身體特徵,因此也是個人信息。針對這一數據類型,主要通過合同方式,基於個人信息主體的授權同意,實現合法合規處理。
②直接採集互聯網上的數據,一方面是直接獲取開放的公共數據,另一方面是通過爬蟲方式蒐集網絡數據。前者參考《上海市數據條例》,公共數據不包含個人信息、個人隱私,風險低;後者使用技術手段獲取網絡數據,考慮到爬蟲所爬取的內容類型(如包含大量個人信息及商業數據等)及其對於目標業務和站點所帶來的影響,可能存在違法風險。
③數據交易,通過B2B交易的方式向數據提供商購買數據,或依託於地方數據交易所進行場內交易。這一數據源的責任主要落實在數據交易中介、數據提供方,要求其對於所交易的數據中的個人信息進行保護。
當前,由於訓練數據需求龐大,以GPT-3模型為例,其在訓練階段使用了多達45TB的數據。近幾年,隨着AI生成技術的發展,可以預測有效網絡數據的增長將跟不上訓練模型所需數據量的增速,與此同時數據獲取的成本也不斷上漲,因此合成類數據(Synthetic Data)開始進入市場。
以人臉數據為例,如果將一個自然人所能提供的人臉數據設為1,那麼通過合成、編輯等功能,將基礎的人臉數據進行調整(五官或表情),可以實現10或者100個人臉數據,大大降低訓練數據的成本和獲取難度。合成數據也需進行個人信息保護,根據《互聯網信息服務深度合成管理規定》,在使用生物識別信息編輯功能前,依法告知被編輯的個人,並取得其單獨同意。
階段2:AIGC應用運行階段****
AIGC應用部署後,可以實現人機之間的交互。用户在輸入頁面填寫信息,從而獲得人工智能生成的內容,比如一段文字、一幅圖像、一個蛋白質三維結構。當數以億計的使用者都在實時與AIGC進行交互時,使用者輸入的數據去了哪裏?人工智能輸出的數據又會包含什麼風險?
以境外應用為例,當中國境內使用者在輸入頁面填入信息後,信息會傳輸至服務提供者的境外所在地或境外數據中心,再由應用反饋回覆。這一交互過程中,AIGC主要涉及:
INVOLVE
1、個人存在將(敏感)個人信息傳輸至AIGC的情況,AIGC是否針對個人信息的收集、存儲進行事前告知同意?
2、組織出於數據分析、信息統計等目的,存在將其收集的一定規模的(敏感)個人信息(比如包含姓名、電話等信息的員工信息表)傳輸至AIGC的情況,是否構成事實上的數據出境?
3、AIGC輸出的內容,其中是否可能因為訓練數據的問題,導致仍然存在可識別或可再識別的個人信息,即AIGC的技術支持者和服務提供者造成個人信息泄露的情形?
階段3:AIGC模型再訓練階段****
人機之間的交互所產生的數據,可能被用於未來模型的迭代訓練,其中也會涉及大量個人信息。因此,AIGC服務提供者在個人或組織使用應用前,需將這一情形進行事前告知並取得單獨同意。
綜合AIGC數據處理過程中的3個主要情形,圍繞隱私問題,可以依循現有的個人信息保護相關規定,不過仍然需要針對AIGC(人工智能)全流程的個人信息保護的綜合性立法,從而促進產業安全合規發展。
AIGC發展及合規建議
去年年底以來,中共中央、國務院印發“數據二十條”、《數字中國建設整體佈局規劃》,國務院機構改革方案提出成立國家數據局、重新組建科學技術部。一系列密集的行動透露出我國將“數據要素供給”“數據安全治理”的重要程度再度提升的信號。
基於“鼓勵AIGC產業創新發展,同時在發展中合規”的目的,擬對產業發展提出幾點建議:
1.在規範主體上,構建AIGC服務提供者(提供應用或服務)、技術支持者(提供算法等人工智能技術)、服務使用者(使用AIGC的個人或組織)三方權責機制。
2.在規範內容上,基於現有的算法及深度合成內容監管基礎,進一步圍繞AIGC形成綜合性立法。一是根據算法應用場景(如生物醫療領域、自動駕駛領域等不同領域),二是根據生成內容的類型(文本/圖像/三維模型/音頻/視頻/代碼等),依次形成AIGC風險分級分類管理體系,並對涉及人臉等敏感個人信息的高風險領域,定期開展數據安全能力評估。
3.實現訓練數據全生命週期管理。對於大規模訓練數據的收集、存儲、使用全生命週期進行規範,尤其是加強個人信息、重要數據的保護。此外,進一步加強對於訓練數據提供商的約束,要求其對於數據來源、數據交易及使用進行全流程安全監測。
4.促進數據要素流轉交易。基於AIGC應用場景持續釋放需求,需加快數據供給,一方面推動數據上鍊託管、加快場內場外數據交易流轉,另一方面可以針對特定訓練數據需求,有條件開放對應公共數據。
5.鼓勵發展合成數據產業。出於提升數據多樣性、提高訓練數據質量,降低數據合規成本、模型訓練成本的考慮,加快發展合成數據,包括生物可識別信息數據(用於虛擬人訓練的表情、動作、聲音的多模態數據)、文字/圖像等非結構化數據(用於字體設計、視覺設計的數據)。
來源:賽博研究院
免責聲明
本文僅代表原作者觀點,不代表走出去智庫立場。