承包了我今日笑點的AI“文心一言”,被質疑是“套殼”?_風聞
手谈姬-手谈姬官方账号-不是很懂二刺螈。03-24 10:33
如今,AI產品屬實是位於風口浪尖,火的不行,在國外AI產品GPT4公佈的第二天,我們熟悉的百度公司就推出了他們家的AI產品“文心一言”。

在百度的發佈會中,總裁李彥宏親自在視頻中做出了相應的展示,包括使用文心一言生成文本、圖片、音頻、視頻等功能。
李彥宏的作圖的演示

儘管文心一言開始並未被資本市場所看好,但作為大家也能夠使用的新技術,手談姬也早早進行了預約,想把文心一言作為玩具好好把玩把玩。
於是這幾天,文心一言生成的圖片就廣泛在網絡上流傳,大家驚喜的發現,這百度的AI還挺幽默的,基於它的頂級理解,生成的圖片能讓人樂的不行。
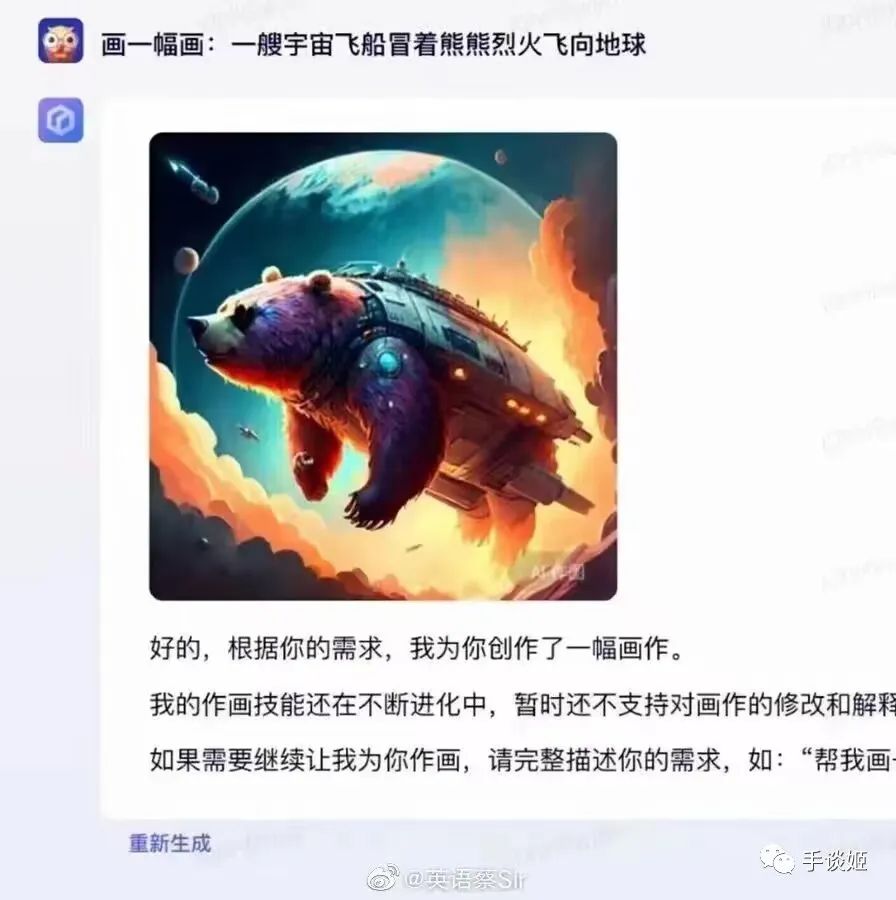
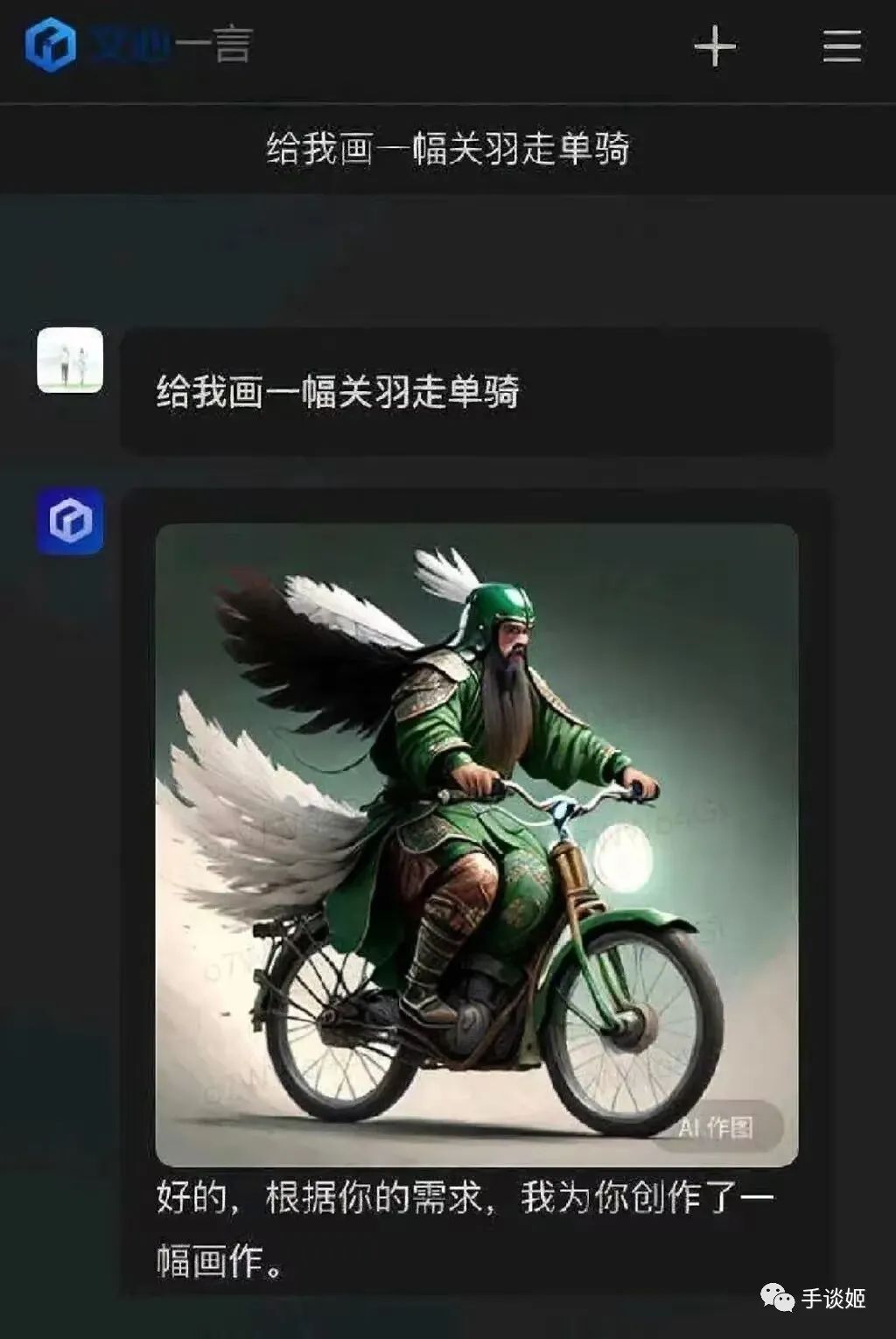

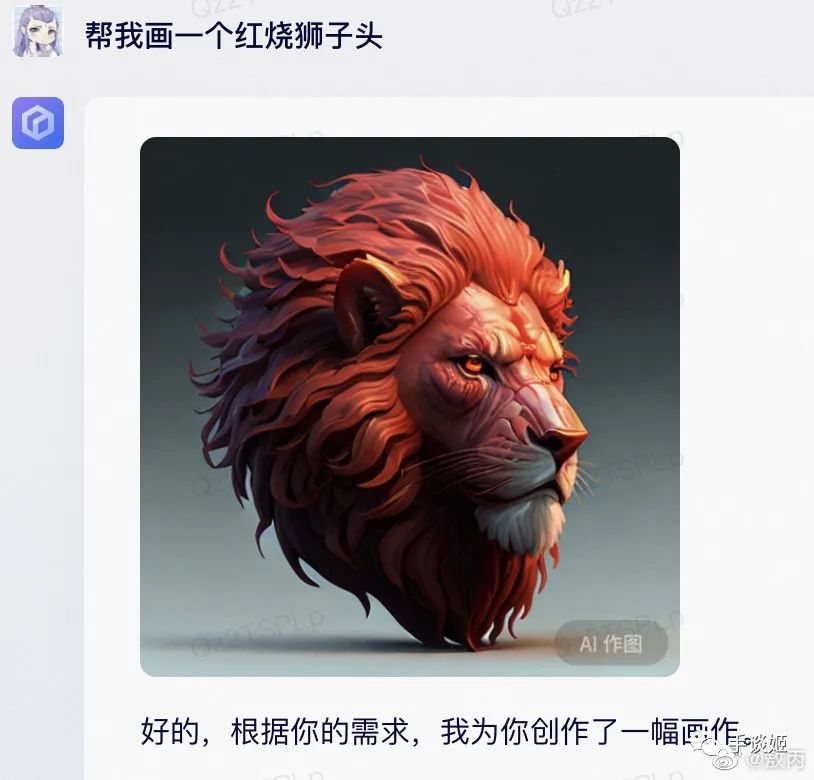

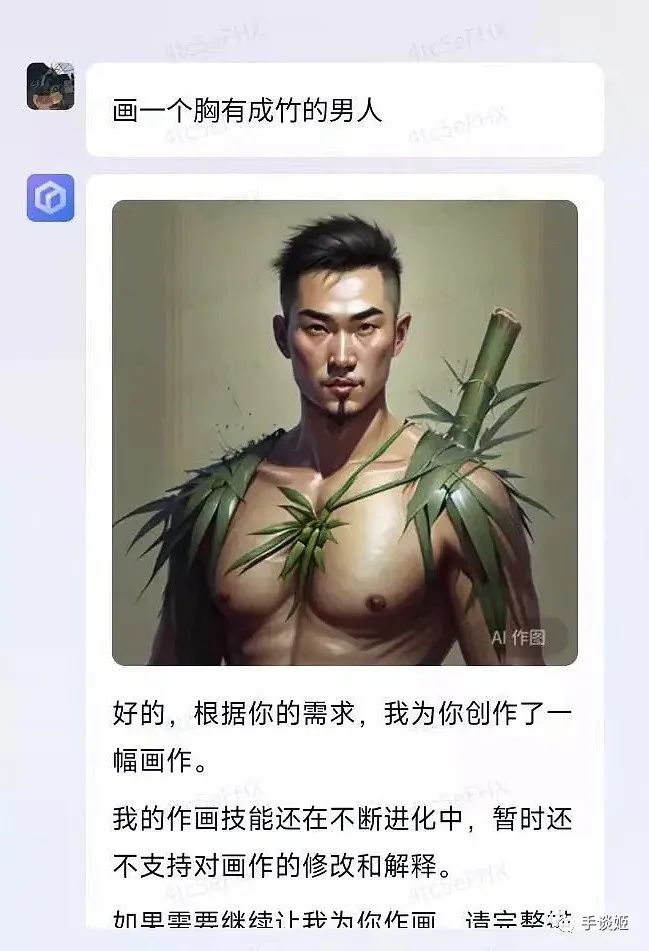
這讓姬想到了當初畫不好畫的stable diffusion,畫一個吃麪的場景卻畫不出筷子來,但是總會出現完美圖的,所以百度繪畫精度的提升也是可以預期的,倒不必過於失望。


但是也有網友產生了懷疑,比如微博博主劉大可先生就懷疑百度的所謂人工智能繪畫,是把中文先翻譯成英文,然後使用stable diffusion生成圖畫後,被百度説成是自己畫的了。
劉大可舉例了相當多中文和英文中產生歧義的內容,比如讓百度畫“鼠標和總線”,生成的作品是“老鼠和公共汽車”,如果理解為AI理解成了英文“mouse和bus”就非常能説得通了。
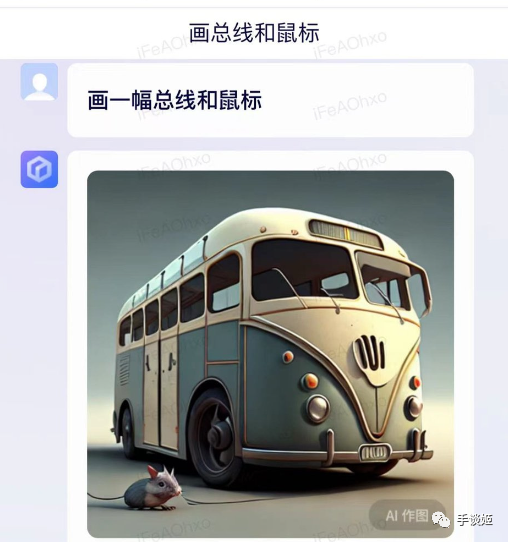
也就是説,百度的AI需要將中文翻譯成英文來進行理解,而不是直接去理解中文,但是百度作為知名的中文搜索引擎,為什麼不使用其中文數據進行訓練,反而使用英文呢?
以下是劉大可的微博內容

首先!手談姬對於其將漢芯和鴻蒙相提並論是反對的。年紀小的姬友可能不太清楚當年的漢芯事件,這是在2003年,上海交大的陳進教授號稱能自主研發高性能芯片,騙取了高達11億的研發資金。

根據相關報道,當年陳進的“漢芯一號”的源代碼完全是從摩托羅拉公司下載的,並且連芯片本身都是從摩托羅拉買的,陳進找人清除掉芯片上摩托羅拉的logo,換上了漢芯的logo就去交代了,實在令人咋舌。

**漢芯事件可以説是給我國的芯片自主研發事業造成了巨大陰霾,也難怪會有人對此相當警惕。**21世紀,科學技術無疑是一個國家的軟實力的體現,容不得造假,所以在這方面的警惕也是有其道理的。
但是,非技術人員的猜疑也很成問題。百度使用了英文標註的數據,難道就能證明文心的畫圖是套殼了stable diffusion嗎?也不能。
但事關重大,百度理應給出一個説法。本日中午,百度就對此事進行了解釋。百度表示,文生圖能力來自文心跨模態大模型ERNIE-ViLG,而對於大模型的訓練使用的是是全球互聯網公開數據。
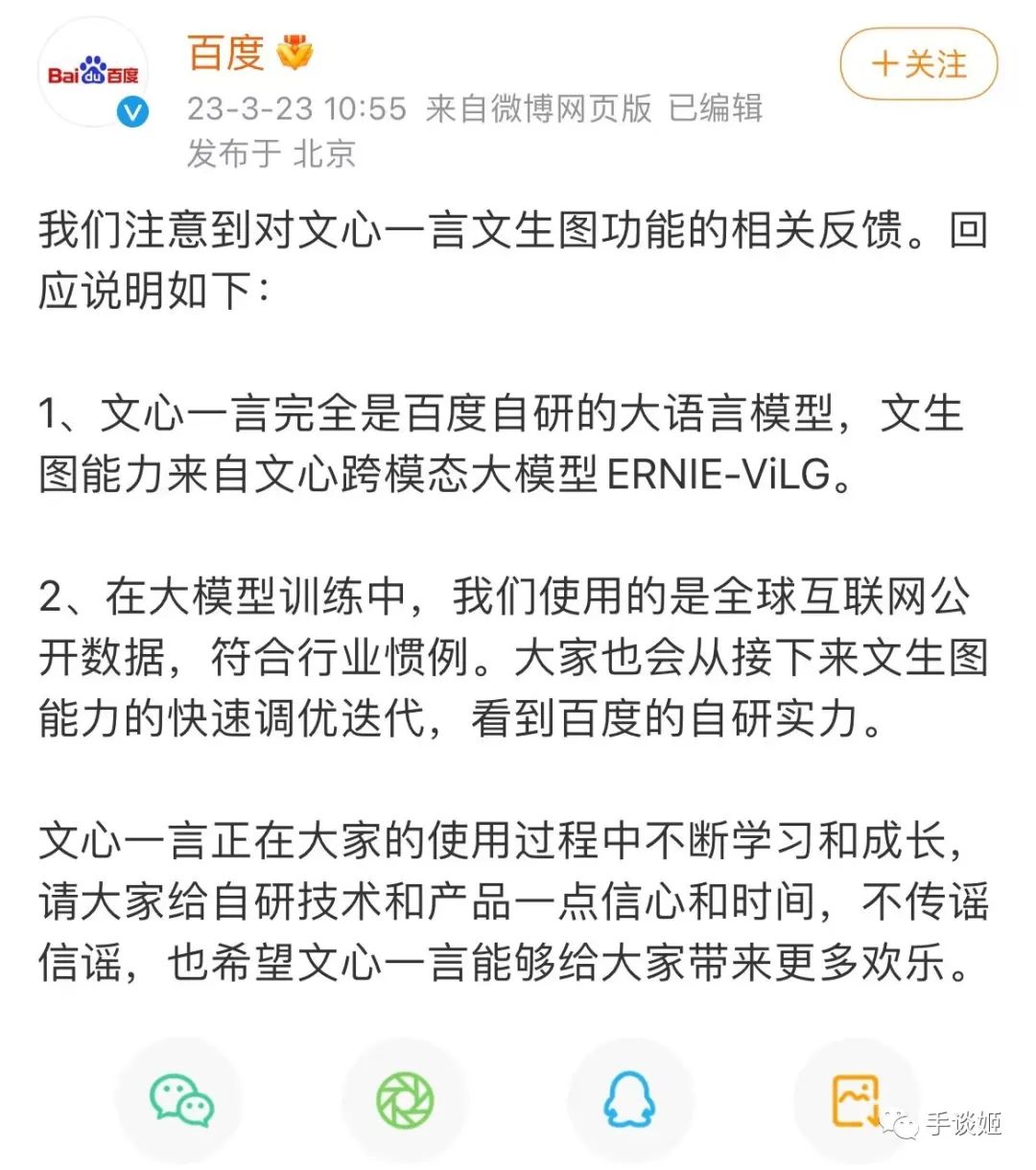
這是百度公告下面的評論。
從這點看來,劉大可先生質疑其套殼是有點冤枉它了,但也產生了兩點問題:
一、説明百度的翻譯能力有待提升,目前尚不能把一些中文的成語翻譯成對應的英文。
二、百度作為中文搜索引擎,掌握着大量的中文數據,卻還無法加以利用。明明使用百度的搜索引擎搜“鼠標總線”得到的就是對應內容,卻無法復現到其AI產品中。
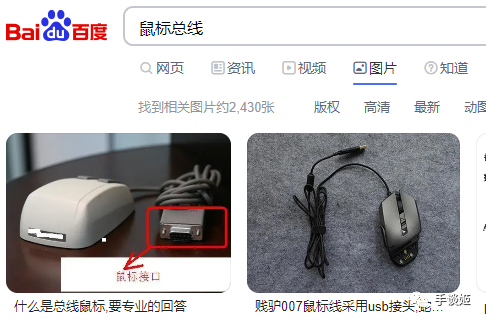
那麼,文心一言為什麼非得要使用英文作模型標註呢?手談姬問了文心一言的本體,它介紹如下:

可以説,百度現在的技術確實相較國際頂尖AI存在着差距,但現階段也只能認清差距,一步一步鑽研。
要質疑,也要理解!祝百度以及其他企業能夠紮實研究出優質的AI產品。
晚安。
