網上最權威的芯片戰分析——反芯片制裁戰略研究(上)_風聞
汪涛_纯科学-自由撰稿人-纯科学创始人,致力于将完善的科学方法引入社会领域03-29 15:11
僅以此文獻給偉大的芯片專家和科技創新企業家戈登·摩爾。
致敬,逝去的摩爾和即將逝去的摩爾定律。
 本文核心觀點和結論是:美國對中國發起的芯片戰,是在一個錯誤的時間、錯誤的領域、向錯誤的對手發起的錯誤的戰爭。
本文核心觀點和結論是:美國對中國發起的芯片戰,是在一個錯誤的時間、錯誤的領域、向錯誤的對手發起的錯誤的戰爭。
我曾在**“《長津湖》及抗美援朝的軍事科學解讀”**一文中系統地指出:中國人民志願軍之所以能用相對劣勢的裝備戰勝優勢裝備的美軍,一個關鍵性的原因是朝鮮半島普遍山地的地形,而我人民解放軍從建立的一開始就極為善長山地作戰。志願軍最為充分地利用了朝鮮半島的崇山峻嶺,加上夜戰,這些對美軍造成了最大程度的能力限制。這有效地逆轉了雙方武器裝備的差異,並使我軍其他逆天的戰略戰術和素養(穿插、能聚能散、水銀泄地、三三制與勇敢犧牲精神等)得以充分發揮。
我們可以設想一下,如果當年抗美援朝戰爭是發生在當今俄烏戰爭一馬平川的戰場,結果會是如何?志願軍還能否戰勝美軍?這個問題可能是要打一個問號的。當年63軍為什麼要死守鐵原,15軍要死守上甘嶺?因為一旦失守,後面上百公里就是“一馬平川、無險可守”。“搶佔有利地形”,避免“無險可守”,這些是我人民解放軍近乎本能的戰術概念和反應。即使在平原地帶,我軍也可以通過挖地道而獲得巨大優勢。但這個只能作為防禦手段。如果在一馬平川的平原上,能打出五次戰役裏雙方幾十萬人規模的圍殲作戰嗎?這更是要打一個大大的問號的。
2000年前,甚至2010年前,摩爾定律高度有效,所以芯片領域可以説是一馬平川,美國芯片企業可以説是一路狂飆突進,中國公司在沒有能力從美國獲得充分芯片技術資源共享前提下是難以對抗的。但在今天,隨着摩尓定律逐步遇到越來越多的極限,相當於逐步進入了越來越多崇山峻嶺的地形。這就是在目前這個階段美國發起全面的芯片戰爭,中國為什麼可以用相對劣勢的技術打敗美國最優勢技術的客觀條件所在。
本文目錄:
一、我的學術態度——追求卓越和原創
二、對摩爾定律的深度討論
三、CPU位長及64位極限
四、時鐘頻率(主頻)及9GHz極限
五、指令集與計算架構
六、存儲結構對計算性能的影響
七、片內多核與阿姆達爾定律
八、其他計算能力堆疊技術
九、其他影響計算能力的技術
十、中國芯片戰制勝之道
一到五為上篇,六到十為下篇。
一、我的學術態度——追求卓越和原創
本文準備了很長時間,正準備寫的時候突然見到網上傳來人類芯片發展歷史上最偉大的人物之一戈登·摩爾離世的消息。摩爾是一位對整個人類芯片技術歷史發展有着舉足輕重作用的人物,是我們這一代人心裏的大神之一。儘管美國現在正在對中國全面地展開芯片戰,儘管以他的名字命名的著名摩爾定律正在逐漸失去作用,也絲毫不影響我們對摩爾個人的高度尊敬和懷念。一個時代正在結束,可以用有人評價林肯的話來評價他:當一顆大樹倒下的時候,才能準確丈量它的高度。
為什麼要用“網上最權威”這樣不謙虛的説法?先參見我以下最權威文章系列:
網上最權威的人工智能分析
網上最專業的VR分析文章
資深IT人詳解什麼是“元宇宙”——細説歷史上那些“什麼都不是”的概念
戰略決戰:中國科技如何領導世界——最權威分析
中國人的文化中有“謙虛是最大的美德”説法,但我要告訴你在當今的時代,“謙虛是最大的缺德”。為什麼?
首先,在需要中國人大量地與西方人打交道的時代,你謙虛的話,別人不會認為你有美德,而只會認為是你真的沒本事,真的不行,真的應該被人看不起。
其次,對於創新來説,如果不是“世界上最”的東西,能叫創新嗎?所以,“最”是今天的中國學術界和科技界必需具備的、最起碼的參與遊戲的資格。如果你不是“世界最”的東西,有什麼資格搬出來説事?純屬浪費社會資源和別人的時間。因此,謙虛往往成為學術體制內的庸人無所作為混日子的保護傘。“我們與世界先進水平還有很大差距”“追趕世界先進水平還需要幾代人的努力”……這話聽起來很規矩、讓別人沒話説,但事實上的作用就是“無論我做成什麼樣,你都別有意見。即使我佔用了國家大量資源,也不需要做出世界最領先技術水平的東西”。
我們看到國外很多企業,依靠非常領先的技術,在公司介紹裏一開頭就是自己是某某領域國際領導性的企業,擁有什麼世界最領先的技術。但中國公司就不被允許這麼説,也不允許這麼想。中國的廣告法裏就一刀切地全面禁止説“最”“第一”。即使中國公司真做出了世界技術最先進的東西,也不允許説出事實情況。過去這麼規定是有合理性的,因為過去中國的確在技術上差太多,隨便去説“最”往往事實就是吹牛和欺騙。
但今天已經完全不一樣了,中國公司已經有大量世界最領先的技術,為什麼不允許説?只要有充分的客觀科學證據(第三方檢測報告等),展示它們不行嗎?要想做出世界上技術水平最高的產品,當然是要投入大量研發費用的。可是你長期費盡心力和投資、還可能失敗的風險,去做出世界上技術水平最高的產品時,卻被法律禁止説出事實來。你不説出來客户怎麼知道?客户不知道你怎麼能賣出好的價格?你賣不出好的價格怎麼能收回鉅額的研發投資?收不回投資,誰會願意去做從0到1的、原創的工作?
中國公司只被允許説價格更低,一切商業環境都是在比拼價格。但在美國卻沒有對“最”“第一”的任何禁止。他們甚至把技術上“最”“第一”當成一個企業可以立身於市場的最基本資格、最起碼的要求。美國企業説他們的產品技術是世界上最好的基本上是習慣性的,而中國企業做出了世界上最好的產品技術如果説出來卻是非法的。何止是毒教材,今天的中國在思想上、法律上、文化上、教育上、學術標準上……被滲透、控制和封鎖得有多麼深、多麼廣?
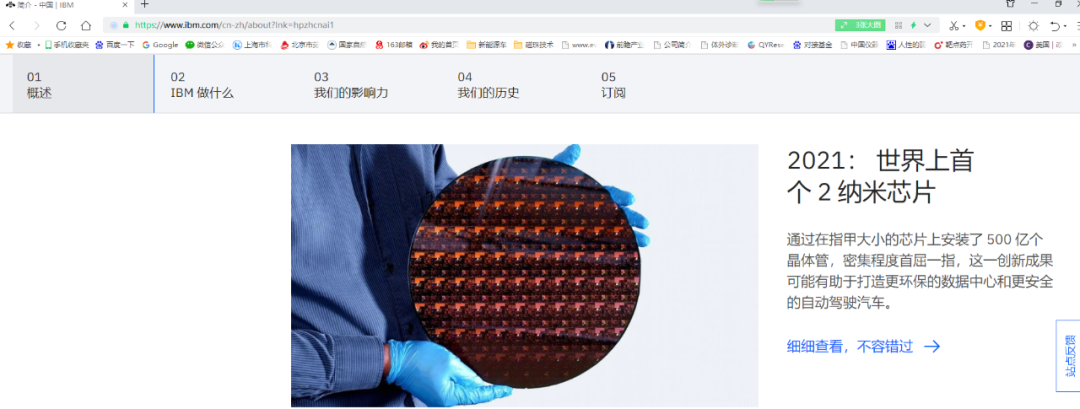 IBM官網上對自己技術的宣傳語“世界上首個……”“密集程度首屈一指”。按中國的廣告法,這涉嫌違法嗎?如果他不説,客户怎麼知道他是第一個做出來的、世界上最領先的產品技術?
IBM官網上對自己技術的宣傳語“世界上首個……”“密集程度首屈一指”。按中國的廣告法,這涉嫌違法嗎?如果他不説,客户怎麼知道他是第一個做出來的、世界上最領先的產品技術?
中國公司有沒有世界上最好的技術?多得是。因為我專門研究和支持中國的原創技術,所以有很多中國擁有原創技術或世界最領先技術的公司會與我聯繫。蘇州有一家公司蘇州恆兆,開發了世界上能量效率最高的空調,遠遠超過其他國內外友商。現在根據中國空調能效的分級,最高的是1級,能效是5,但蘇州恆兆可以做到6.5。另外,蘇州恆兆還開發了完全不用安裝的空調,很不好意思,世界首創,美國、歐洲、日本都沒有,不僅是“最”,而且是目前全球具備“唯一性”的產品技術。怎麼辦?允許説是“世界技術最先進的空調”這個客觀情況嗎?
蘇州恆兆不用安裝的空調。基本原理其實也不復雜,它是將反向的熱量儲存在機器內的水箱裏。
 北京有一家高科技企業北京美爾斯通,開發了超導磁測量技術,其靈敏度達到世界最高。它的靈敏度高到多少呢?如果裝在飛機上可以探測到水下很深處遊動的魚。實在不好意思,其技術水平遠遠超過美國,歐洲、日本根本就沒有同類技術。這些實際情況可以説嗎?
北京有一家高科技企業北京美爾斯通,開發了超導磁測量技術,其靈敏度達到世界最高。它的靈敏度高到多少呢?如果裝在飛機上可以探測到水下很深處遊動的魚。實在不好意思,其技術水平遠遠超過美國,歐洲、日本根本就沒有同類技術。這些實際情況可以説嗎?

美爾斯通創始人米旺先生。

以美爾斯通超導磁測量傳感器為基礎開發的心磁儀。
芯片被封鎖是很小、很小,小到幾乎可以不值一提的小事情。真正的問題和障礙是我們所有人都在高喊要創新的同時,卻在思想、文化、法律、教育、學術標準和商業模式上,對中國企業、工程師、學者們、投資者們原創性工作自己人為設置一道又一道封鎖線。在這種情況下,能去簡單責怪中國人不做原創嗎?
最後,“謙虛美德”往往成為壓制年輕人創新的最大思想枷鎖之一。已經成為學霸的人,當然可以説話非常謙虛,因為他有謙虛的資格。無論他再怎麼謙虛,説自己水平如何有限,因為他的地位在那裏擺着,他説什麼別人都得聽。你一個功成名就的人可以這樣,但也要求年輕人必須謙虛,不能説,即使做出了世界最領先的東西,也絕對不允許説出來。歷史上,大量世界最領先的東西往往就是年輕人做出來的。謙虛,是壓制中國科研創新環境的最大文化障礙和思想枷鎖之一。
抱持學習的態度肯定是很重要的,客觀地展示和要求做出世界最領先的東西絕對不是簡單心態上的張狂,而是客觀。我想説的是:我總是以“網上最權威”這樣的目標來要求自己,要寫就寫這種水準的文章,儘管真的可以謙虛一下未必都能做到。但取發乎上,可能得乎其中,而取發乎中,就只能得乎其下了。
在前一篇**“中美大變局已經到來”**文章中(該文1.6萬字),有一位叫“PL人生”的網友留言建議説“公眾號的文章請力求做到短小精悍,觀點鮮明”。
我回復他“非常感謝您提出的意見。為了方便讀者閲讀,我很早就開始用語音方式提供閲讀便利。事實上,只要通過複製鏈接,用科大訊飛等軟件也可以進行語音閲讀。但有很多老人不懂這些軟件的使用,所以我的每篇文章都提供了語音。但是,我寫文章從來不在觀點和論述方式上照顧讀者,因為所有遵從照顧讀者傳播學規律的文章基本都是迎合和忽悠讀者。我是要給讀者真正的知識和分析問題的方法,如果不想接受這一點,就不要讀我的文章。我不想去迎合和忽悠讀者,更不以提升粉絲量為目的”。
一切短小精悍,觀點鮮明的文章,必然會導致誤解。如果你只是簡單地、觀點明確地説“中國會超過美國”,各種各樣的誤解就會鋪天蓋地而來。有人認為,這是振奮人心(我的目的不是要簡單地振奮人心,而是要指明今天這個時代的中國應該幹什麼);有人會認為,這是民粹主義(我不是鼓動民粹,而是要中國人明白今天自己的責任和新時代需要掌握的第三代科學思維方法)。
有人認為,這是狂妄自大(我不是要人們單純享受中國領先的自豪感,而是要人們充分意識到時代對今天中國人的全新召喚,今天的中國人面臨的全新歷史使命)……然後你又得一個一個地去深入解釋,來回鬥嘴爭吵,最後篇幅不僅更長,而且導致大量散亂的、只是各自加深自己固有陳見的觀點和難以消除的誤解。人們聽到的很多格言式的非常精彩的警句,表面上看起來很漂亮,實則空無一物。因為擔心被誤解,也只能説得空無一物,從而儘量不讓人抓住把柄。因此,只有系統地閲讀一些邏輯完整,論述完備的文章,才有可能真正提升自己的知識和分析能力”。
但就是這個“不照顧讀者”的1.6萬多字長文,發表以後卻在網上以每小時10萬+的閲讀量迅猛增長,兩天不到今日頭條上的閲讀量居然突破300萬。
本文不僅是希望普通讀者、政策制定者有所獲益,而且能讓專業的、甚至是資深的芯片和信息技術領域人員也能有所獲益。
二、對摩爾定律的深度討論
請讀者注意我文章名稱中説的是“芯片戰分析”,不是説芯片技術分析。對芯片技術,我不能説權威。如果這麼説,肯定就有人要挑戰“那你怎麼不去做芯片?”。本文將給出大量在其他文章中極少見到、相對硬核的內容,去解決一個很重要的問題:人們都會天然地認為,芯片技術越先進,芯片線寬越細,技術水平越高,集成度越高,晶體管越多,性能就越強。這個好像是天經地義不用説的事情。但如果要問:為什麼它會是這樣呢?能給出系統完備的、精確的解答嗎?這個可能就算是這個領域的專家也未必都能説得清楚和完備。但這個問題如果説不透徹,就很難理解今天的芯片技術客觀現狀是什麼,以及它未來將如何發展。同時也難以準確理解芯片戰的結果走向如何。
“摩爾定律”是有3種表達方式的:
(1) 芯片上所集成的晶體管數量,每隔18個月翻一番。
(2) CPU的性能每隔18個月提高一倍,而價格下降一半。
(3) 用一美元所能買到的計算性能,每隔18個月翻兩番。
上面三種表達方式在過去被認為是一樣,或者説是“等價的”。但本文要告訴讀者的是:它們之間有很多細微、在今天影響越來越大的本質差異。因為計算性能提升的比例與芯片上集成度的提升比例並不完全是一回事情,它涉及到很多影響因素。這些因素在過去一個一個發生了本質變化,導致最終芯片以及整個系統的性能提升速度越來越慢。摩爾定律遇到極限,並不僅僅是芯片線寬最終遇到量子效應難以再縮小、從而集成度難以再提高,而是很多其他影響計算性能的因素,早就一個一個遇到極限了。
在前面“中美大變局已經到來”一文中,其實已經簡單提到一些相關問題,但在篇幅已經很長的該文中很難展開,本文就係統地把這個問題談清楚。影響計算性能的因素綜合起來有如下這些:
(1) CPU位長
(2) 時鐘頻率(主頻)
(3) 指令集與計算架構
(4) 存儲結構
(5) 片內多核與阿姆達爾定律
(6) 其他計算能力堆疊技術(3D集成、ChipLet、二次集成、板上多CPU、多計算板卡、多機櫃、MPP、計算機集羣等)
(7) 其他,如用帶寬和存儲換計算性能,從算法上降低計算量等等。
請注意以上分類相互之間有可能存在部分重疊之處或相互影響之處,以下我們就一一做出解釋。
三、CPU位長及64位極限
首先體現芯片性能的是CPU位長。最早出現的CPU是INTEL的4004,它是INTEL的工程師特德·霍夫開發的,這個是4位的CPU。後來CPU位長就不斷地升級,每次升級翻1倍。以下是CPU位長的發展情況。
要首先強調下,以上數據只是按INTEL的CPU來説的,歷史上的CPU芯片當然是有很多的,甚至還有摩托羅拉曾開發過24位長的怪異CPU,如68000系列和56k系列DSP。4004是INTEL最早開發出來,但其他各代並不一定都是INTEL最先推出。甚至於,中國的沈緒榜院士在1977年就開發出了16位的CPU,比INTEL還早一年。

2010年4月18日,我去參觀硅谷INTEL博物館


第一個CPU芯片4004
 4004芯片實物及介紹。這個小芯片的計算能力已經超過了佔用整整一個房間的第一台電子計算機ENIAC。
4004芯片實物及介紹。這個小芯片的計算能力已經超過了佔用整整一個房間的第一台電子計算機ENIAC。

對16位CPU8086及8088的介紹
現在要問這樣的一些問題:為什麼CPU位長更長,性能就更高?CPU位長更長性能就一定更高嗎?64位CPU可能是終級的CPU位長,為什麼?
如果要處理的數據是30位,並採用16位CPU來處理,那麼至少就得分兩次才能把數據送到CPU裏去處理。但如果採用32位CPU,只要一次送進CPU就處理完了。這就是為什麼CPU位長越長,處理速度就會越快的簡單原因。但是否CPU位長越長,處理速度就一定更快呢?不一定。
最初開發的4004只有4位,要處理的數據位長几乎100%都會超過這個長度。所以,當開發出8008時,因為CPU位長提升了1倍,數據處理性能就會直接提升1倍。如果處理的數據位長低於CPU位長,無論其位長多麼短,你都得使用至少一個CPU的週期去進行處理,這樣CPU的位長增加就對提升性能沒意義了。當CPU位長不斷提升時,超過其位長的數據比例就會越來越低。如果超過其位長的比例是50%,CPU位長增加1倍帶來的性能提升就不是1倍,而可能只有25%甚至更低了。
從目前來看,64位CPU是終極的CPU位長。得出這個結論需要一個前提假設:被處理的數據位長是受限的,並且極少會超過64位。為什麼説它是一個假設呢?因為我們肯定不能説需要處理的數據位長一定不會超過64位,它肯定會是無限的。但從現實世界來看,被處理的數據位長不會太長。超過一定限度的數據,其數量佔比會越來越低。為什麼會這樣?這個直接理解起來可能會有些模糊,我們就先舉一些實際例子來説明。
2000年時曾有一個很著名的信息領域問題,叫“千年蟲”。這是因為20世紀信息技術發展的初期,為節省當時極為寶貴的信息存儲、處理和顯示的資源,就把年份的數據只用兩位數表達。例如1960年3月24日是表達成60年3月24日。兩位數最多表達的年份是100年,然後就重複了。所以,這個問題其實最準確地説應該叫“百年蟲”。在2000年以後,年份就改成4位數表達了。但這樣做就沒問題了嗎?並不是,而是潛在了一個“萬年蟲”問題。因為當年份用到9999年時,下一年就會重複回到0000年、0001年……2000年……2023年對不對?
但我們需要擔心這個問題嗎?並不需要。因為電子設備的最長使用時間會長到幾十年,軟件使用時間會更長一些,但也不應該超過100年對吧?所以很多電子設備硬件和軟件在上個世紀真會跨越到2000年時出現問題,但對萬年蟲我們並不需要擔心。一個它是7970多年以後才會出現的事情,有太充分的時間來提前準備。另一個到那時的技術會遠比今天發達太多了。所以,百年蟲真是一個問題,而只要位長增加兩位形成的潛在萬年蟲就不是一個問題了。
再以貨幣來舉例,有些國家的貨幣因惡性的通貨膨脹可能形成極低的幣值,買一塊肥皂都可能要100萬億億元,這會造成表達貨幣的數字符號很長的位長(19位十進制符號表達100萬億億)。但如果這樣,往往人們就會發行新的貨幣,把位長降下來。例如,新貨幣的1元會等於老貨幣的10萬億億元,從而上面的100萬億億元就變成新貨幣的10元了。這就把原來的數字19位長度變成只有2位長度了。
從以上分析我們就可總結出信息位長有限性的兩個基本原因:
一是信息表達的經濟性,使人們會盡量採用更短的位長來滿足要求。
二是位長的增長帶來的信息空間增長是數量級的。越到後面的位長增長,帶來的信息空間增加會是前面位長增長的數量級倍數,使得滿足實際需要的能力數量級地增大。指數增長的能力會很快超過一般只是線性增長的實際需要。
下面我們再來談一個更為硬核的科學因素,就是科學測量數據的不確定度水平限制。一切科學測量數據最終都是建立在七個基本的國際計量單位基礎之上。其中在不確定度技術水平上最高的是時間單位,因此其他計量單位(長度米和重量kg等)都逐步地最終以自然界的常數(光速常數、普朗克常數等)和時間為基礎來進行定義,最終一切科學測量數據的最好不確定度也都取決於時間計量。時間計量單位1秒是等於銫133兩個超精細能級躍遷對應輻射頻率的9192631770個週期的持續時間。這個定義還是1967年就實現的,它有10位有效數字。
後來隨着時間測量技術的不斷進步,其不確定度上的技術水平越來越高。2017年中國計量科學研究院的NIM5銫原子噴泉鍾,其不確定度達到9E-16水平,這個時間測量數據會有16位有效數字。目前最高水平的光原子鐘不確定度接近1E-18的水平,這個會有18位有效數字。這種技術水平的原子鐘如果從138億年前宇宙大爆炸開始運行,到現在偏差也不會超過1秒。未來當然不排除還可能會有更高水平的時間測量技術出現,但可以看到,至少目前19位長度已經是當前一切科學數據最大極限長度。64位CPU位長用於科學計算時,足以解決幾乎所有科學測量數據的一次性處理。從工程應用上來説,這個不確定度水平的測量數據不要説是去火星,就是進行銀河系的星際航行其精度也足夠用了。這是位長有限性的第三個很硬核的原因。
第四個原因是採用量綱對數據位長的簡化。前面內容可能有網友會有疑惑,為什麼不確定度是1E-18,最大有效數字就是最多18位呢?比如説有一個科學數據不確定度是1E-6,有效數字是6位。可是實際的數字可能是遠遠多於6位啊?比如12,345,600,000,000,後面8個數字因為已經在不確定度以下,可以直接寫成零,寫別的數字沒有意義。這個不是14位長度,遠超過6位了嗎?的確如此,但科學中會採用量綱來簡化這個問題,一般遇到這種情況,不會像上面那樣直接表達,而是寫成123456億,或者12345.6G。通過k、M、G、T……等量綱,可以大幅度縮短數字的位長。
網友還可能會有一個疑問:IPv6地址不是128位嗎?採用IPv6的路由就不需要128位CPU嗎?回答是不需要。以IPv6最主要的單播地址規劃為例,它是將128位地址分成前面的64位網絡前綴和後面64位的接口標識。在網絡上不同的區域,會分別使用網絡前綴和接口標識進行路由。所以一般最多只需要64位地址路由,而不需要同時處理128位地址。
64位二進制信息的空間,換算成十進制可達19位長度(1845億億)。我們當然不會説實際要處理的信息一定不會超過這個範圍,但從現實世界信息看概率會是千分之一,甚至萬分之一以下的程度。
如果超過64位的數據量只佔極少數量,僅僅為這一點數據就去開發128位CPU的話,需要來比較一下如下兩種方案的優劣:
一是直接採用128位CPU,其佔用的晶體管數量簡單來説可能就是64位CPU的兩倍。
二是如果用同樣數量的晶體管,同樣的芯片生產技術,在一個芯片上做兩個64位的CPU。
上面兩個方案哪一個更好?因為99.9%以上的數據都是64位以下的,因此兩個64位CPU獲得的最終性能肯定會好過一個128位的CPU。這就是為什麼64位CPU很可能是終級位長的根本原因所在。32位CPU可直接訪問的內存地址空間是4G,這個還是非常受限的。而64位CPU可直接訪問的地址空間,目前最高性能的INTEL公司的CPU僅利用到128G,遠遠沒有開發完。
從2001年出現64位CPU至今20多年過去,2022年全球網絡數據總流量為799EB,同比增長為21%。64位CPU可直接管理的地址容量已經與全球互聯網總流量只差1個多數量級。
所以,當年在32位CPU還沒推出來時,就有人在討論128位CPU的開發問題。可是後來慢慢沒人提了。
以上討論説明了什麼呢?就是從提升CPU位長角度來提升芯片性能的方向,最初是非常有效的。但位長越長,這個方向帶來的實際效果越低,並在2001年實現64位CPU以後就達到極限,無法再提升了。因此,摩爾定律從那時候起其實就已經開始減慢。
2005年4月18日,中國科學研究院計算技術研究所發佈了龍芯2號,這是中國第一款64位CPU芯片,這比INTEL晚了4年。此後越來越多的中國公司開發出各類64位的CPU芯片。

小名“狗剩”的龍芯2號
因為64位是終極的CPU位長,所以僅從CPU位長角度説,2005年以後中美技術水平就拉平並且可説是永久性地被拉平了。當然,CPU位長只是決定芯片和計算性能眾多因素中的一個,這個技術被拉平當然不會使所有技術水平都拉平。但下面你會看到,一個接一個的技術因素,因為摩爾定律接近極限而被一個接一個地拉平了。
四、時鐘頻率(主頻)及9GHz極限
芯片進行計算是在時鐘頻率控制下進行的。無論芯片的邏輯是什麼,一個CPU在一個時鐘週期裏,最多就只能進行一次處理。即使完全相同的晶體管數量,完全相同的邏輯電路,如果時鐘頻率提升一倍,計算速度當然就會提升一倍。如果你把時鐘降到1Hz,無論多麼強大的芯片,它1秒鐘也就只能做1次計算而不是上億次。開發單板機的人在調試電路或軟件時候,會有人工控制的單步運行方式,讓你可以看到每一個時鐘週期運行的結果是什麼。此時電路性能就完全受人工的控制了。
如果自己攢過機的人就會很清楚一件事情:通過“超頻”(把主板的時鐘頻率人為設置到高於CPU標稱值)可以提升芯片性能。時鐘頻率提升多少比例,簡單來説計算性能基本上就可以提升多少比例。相當於用較低的價格買到了更高價格的芯片。還有一個概念叫“睿頻”。“超頻”是裝機的時候人工地把主頻設置得更高,而“睿頻”是在計算機啓動穩定之後,自己自動地把時鐘頻率提升,從而自動提升性能——讓你超還不如我自己超。不管具體技術是什麼,總之要理解到時鐘頻率對計算性能的基礎性決定作用。
當年INTEL的8086的主頻才4.77MHz。後來CPU的主頻從早期的幾MHz、十幾、幾十、幾百MHz,一直持續穩定增長,逐步發展到超過GHz的水平。如果是與當年8086完全相同的邏輯電路,能夠換成現在4.77GHz的主頻,其計算性能可以直接提升1000倍。可是,當主頻接近9GHz後,這已經是微波波段,因為半導體電路本身的物理限制,其增長就停止下來了。
2001年,INTEL的第一個64位CPU Itanium1的時鐘頻率為1.5GHz。
2012 年,AMD FX-8350 創造了 8794.33MHz 的主頻記錄,後來就再也沒超過。
英特爾的Raptor Lake-HX將在CES 2023上亮相,包括Core i9-13980HX,這是迄今為止最快的筆記本電腦CPU,擁有24個內核,32個線程。其主頻為5.4GHz。超頻者可以將 i9-13900K 超頻至 8812.85MHz,與10年前AMD創造的記錄持平。但9GHz基本就是極限了,極難被現在的硅半導體技術超過。
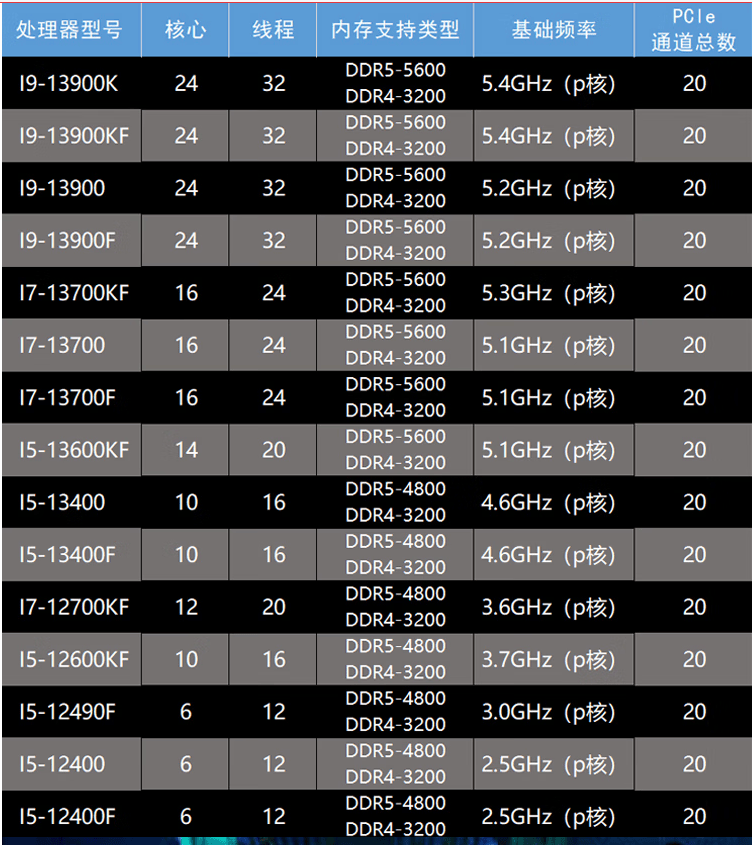
以下是目前INTEL市場上主流CPU的主要技術指標。主頻從2.5GHz到5.4GHz。
 所以早在2010年時,從主頻角度提升計算性能的方向也遭遇極限。摩爾定律再下一個台階。
所以早在2010年時,從主頻角度提升計算性能的方向也遭遇極限。摩爾定律再下一個台階。
2019年12月24日,龍芯發佈的新一代通用處理器3A4000/3B4000,其主頻為1.8 GHz -2GHz。2022年6月6日,龍芯發佈3C5000,主頻 2.1 GHz -2.3GHz,定位於服務器CPU。這些主頻相比INTEL還是差一些,但也差不太多了。關鍵是:INTEL的CPU主頻也就只能那樣,停滯在那裏,靜靜地等待被龍芯和其他中國研發生產的CPU追上。人們只關注到美國人在為中國芯片設置了封鎖線A,但沒幾個人(包括美國政客們)會知道:美國人自己也被設置了更強的、理論和技術上都不可能突破的封鎖線B,但A線卻是技術上可以突破的。因此,美國公司是生活在兩道封鎖線A、B之間,這個空間必將越來越狹窄。
更離奇的一個事實是:千萬不要以為A線只是鎖住了中國人,美國公司是要靠中國市場活下去的,也就是必須要通過A線運送吃喝給養。如果你把A線徹底封死了,餓死的不是中國公司,而是美國公司。美國製裁的制空權轟炸的主要不是中國的後勤補給線,而是“美軍”自己的後勤補給線,想明白了嗎?
五、指令集與計算架構
很早就有精減指令集(RISC)與複雜指令集(CISC)的區分。這兩個技術路線的基本邏輯是這樣:
精減指令集RISC是減少指令集的複雜度,從而精減CPU的邏輯電路,把節省下來的空間用於增加片內寄存器或高速緩存的數量。精減指令集以後可能會有什麼結果呢?某些計算可能在複雜指令集(CISC)的CPU中一個指令就完成,而在RISC的CPU中,可能需要多個指令來完成。
這怎麼還能提升效率呢?這就涉及到後面將詳細討論的存儲結構對計算性能的影響問題。此處只簡單提一下CPU內的寄存器或高速緩存可以顯著加速計算性能。如果這種加速的程度超過因精減指令而增加的指令執行數量,總體性能就可能是提升的。那如果加速的程度不能超過後者呢?就不一定了。還有一個問題,隨着集成度的提高,採用複雜指令集的CPU也可以同時增加片內寄存器和高速緩存的數量啊?所以,這兩種相互矛盾的思路到底最終作何選擇,是需要根據實際信息處理的具體情況,進行仔細評估後才可做出更好的選擇。
因此,按照複雜指令集的思路,是深入針對一些具體信息處理需求進行指令的優化。
專用數學協處理器。這個在80386時就出現了,這個CPU中另外集成了一個80387數學協處理器,專門針對浮點數學運算進行指令優化。這個可以使數學運算比通用處理器快上百倍。當然,這個同時又具有了多核與並行處理的特點,後面對此也會專門討論到。
圖形處理器GPU。這個最初是用於顯卡上專門進行圖形圖像處理優化的。這種優化並不僅僅是處理圖形圖像數據時更好,而且由於對大數據量的並行處理和數學計算都進行了優化,所以後來GPU在開發巨型機和人工智能芯片時都有很好的表現。它對各種有大數據量並行處理和數學計算的業務都有較好的性能表現。
指令流水線。最初的計算架構是著名的“馮·諾伊曼”型架構,也就是串行架構。這種架構是速度最慢的。但一個指令本身就需要多個操作步驟,如:取指(從內存中提取指令)、譯碼、計算操作數地址、取操作數、執行指令、寫操作數等。如果把一個指令執行的不同串行步驟分拆開,每一個步驟都交由專門的電路來執行,這樣在前一個指令走到下一個步驟時,下一個指令就可以開始第一個步驟了。這相當於把本來是串行的指令執行過程變成半並行的。而不是一定要等一條指令執行完了才開始下一條指令的執行。這樣就提升了計算性能。
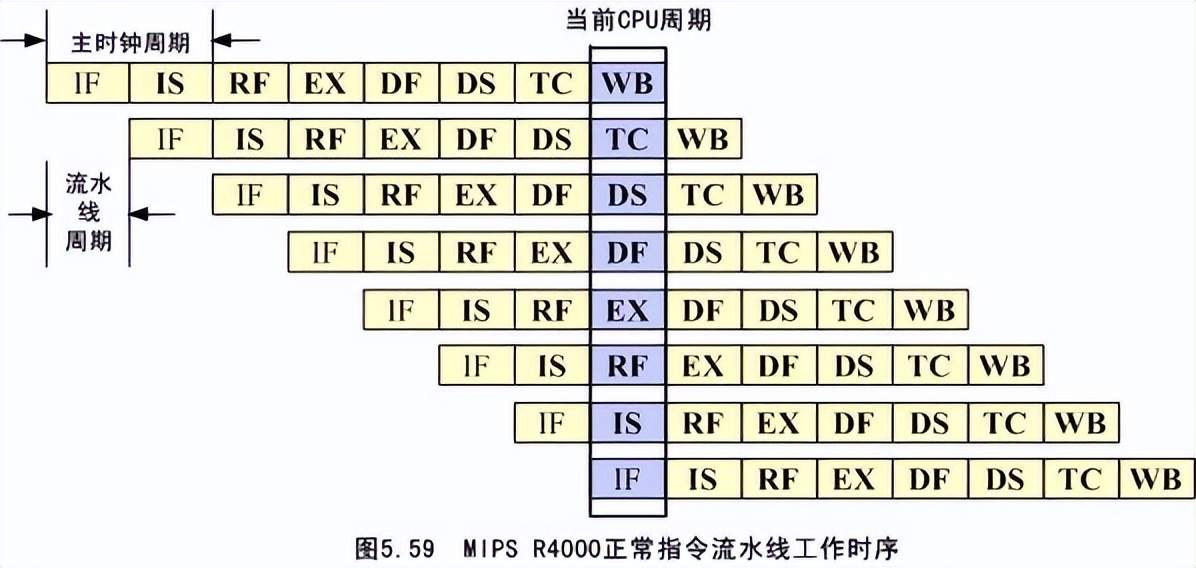 為什麼要叫“流水線”呢?它和工業生產中的流水線原理上的確就是有高度相同之處的。
為什麼要叫“流水線”呢?它和工業生產中的流水線原理上的確就是有高度相同之處的。

平板電視生產流水線
工業生產流水線就是把多道工序在流水線上進行分工,不同的生產工序交給不同的專業生產環節來進行。這樣在生產線上就可同時進行大量的產品並行生產,極大提升了生產效率。
另外還有超標量流水線,超流水線等,都是在流水線基礎上的改進,此處就不再深入討論。
延伸閲讀:(見“純科學”公眾號)
中美大變局已經到來
網上最權威的人工智能分析
汪濤:網上最專業的VR分析文章
資深IT人詳解什麼是“元宇宙”——細説歷史上那些“什麼都不是”的概念
戰略決戰:中國科技如何領導世界——最權威分析
《長津湖》及抗美援朝的軍事科學解讀


