中國哪些職業會被GPT(們)替代?詳細的大數據分析來了!_風聞
Gx-素质低下禁言-认知水平低下禁言-请自行对号入座04-08 21:07
本文轉自:https://zhuanlan.zhihu.com/p/620334140
之前我在這篇文章( OpenAI 研究人員發文稱「約 80% 美國人的工作將被 AI 影響」,如何看待這一觀點? )中介紹了OpenAI的工作論文,那篇文章研究了GPT對於美國職業的替代。
那篇文章的各個版本在這兩週的自媒體中廣為流傳,但需要注意的是,OpenAI的研究是對於美國職業來説的,中國的勞動力市場和美國有不少差異。
因此最近兩週,我們使用中國在過去8年的數億條招聘數據完成了這個研究,看中國哪些職業最有可能被GPT之類的大語言模型和其衍生品替代。
具體結果可以在微信小程序的“數據團+”裏面看到(沒錯就是之前計算疫情達峯過峯的那個小程序)
分析不同職業被GPT替代的可能性,需要對每種職業的職能和具體工作進行分拆。
比如你籠統地問,“人力資源專員”這個職業,被GPT替代的可能性有多大呀?
這類問題就不好回答,因為太模糊了。
但是你可以根據招聘網站的情況,將“人力資源專員”給分拆成不同的職能,比如
1, 新員工的招聘,員工入職手續辦理2, 安排以及開展新員工入職培訓3, 考勤及工資績效的核算4, 維護和拓展公司招聘渠道,協助社招及其他招聘活動
去問其中一個職能,例如“安排以及開展新員工入職培訓”,人力資源專員工作的這一部分有多大可能被GPT替代,就直觀了一些。
我們還可以繼續分拆,把“安排以及開展新員工入職培訓”,進一步分拆成下列具體工作內容——1,撰寫、準備培訓材料;2,交流、溝通並安排計劃時間表;3,演講、培訓,提升員工技能……
再問其中每一個具體工作,
撰寫準備培訓材料,GPT可以替代多少?
交流和溝通安排時間表,GPT可以替代多少?
演講培訓,GPT可以替代多少?
我們用O*net的數據,將中國的職業映射到O*net,再分拆成19265條工作任務和23534種工作內容。
這麼分拆下來,每一個職業拆分研究,再彙總,那麼我們對每一個職業中有多少部分可以被GPT替代,就比較有把握了。
分析每一種具體的職能和工作內容被GPT替代的可能性。
但是,要分析19265種工作任務,23534種工作內容其中的每一種被GPT替代的可能性有多大,也是一個非常繁重的工作。一般來説我們會讓人工來打標,這麼四萬條內容全部打標,大概一個人就需要1周,一個人力的成本就要至少1萬元。這已經是最低的價格了。
但我們知道,在對美國研究的工作論文中,OpenAI的工作論文提出了一種重要的方法。那就是讓GPT來打標。
那我們何不也用GPT來打標呢?
於是我們用了GPT的API,讓GPT扮演打分者,大概是這樣的prompt:
*你是一名“大型語言模型替代勞動力評估師”。大型語言模型,是一種用於處理和生成自然語言文本的深度學習模型,最新的大型語言模型能夠基於自然語言文本生成、描述創建圖像與視頻。在這樣的背景下,你需要從“該任務是否能夠在大語言模型幫助下,在同樣時間達成同樣產出或者同樣效果的前提下,減少人類勞動時間的參與”的角度,給下列每一個任務打分。**評分從0到5分,0代表該任務不能通過大語言模型的幫助減少人類勞動投入,1代表可以減少20%人類勞動投入,2代表可以減少40%的人類勞動投入,3代表可以減少60%的人類勞動投入,4代表可以減少80%的人類勞動投入,5代表可以減少100%的人類勞動投入,即該任務不再需要人類勞動參與。*你的評分,代表着大語言模型可以在每一個任務中節省多少比例的勞動投入,請根據當前大語言模型的進步情況和你認為未來可能的發展狀況,謹慎評分。請按照“id,評分”的格式,每一行返回一條任務的評分結果。
這段算是API裏面system部分輸入的內容,然後在內容部分輸入具體的工作任務和工作內容,GPT就會刷刷返回了,一次可以輸入100條,gpt-3.5-turbo的返回很快,一屏幕一屏幕的0-5的分數就這麼回來了。
説實話,在看到這一屏屏的分數出來,知道這是GPT在為自己能多大程度上替代人類勞動打分,有種審判日到了的感覺。
由於任務已經被拆解得比較細緻,對於每一條任務的打標將會十分準確,穩健性也極高。更重要的是,使用GPT打標,成本之低令人髮指。標註4萬條內容,每次標註100條,只需要400次,一次標註和返回大約在4000token左右,且主要內容是在prompt中,使用GPT-4的模型,每標註100條,僅需要0.12美元。也就是説,共標註4萬條內容,只需要耗費48美元。如果使用不那麼精確,但速度更快且更便宜的gpt-3.5-tubo模型,4萬條只需要耗費3美元。在這樣簡單的任務上,GPT-4和gpt-3.5-turbo的表現幾乎沒有差異。
人類數據標註員要完成4萬條內容的標註,需要至少1萬元,一星期。
GPT只需要半小時,3美元,合20元人民幣左右。
而兩者的質量是幾乎一樣的。
因此,很難不再次強調一遍這樣的事實——
剛剛出現沒幾年的全新職業——人類標註員,他們餵養出來的大型語言模型GPT,在完成一項“GPT能夠替代哪些職業”的標註工作任務時,首先替代掉了把GPT訓練成材的人類數據標註員自己。
將標註結果彙總到職業層面
使用下圖的流程,我們將每一個具體工作被GPT替代的可能性彙總到每一個職業上。
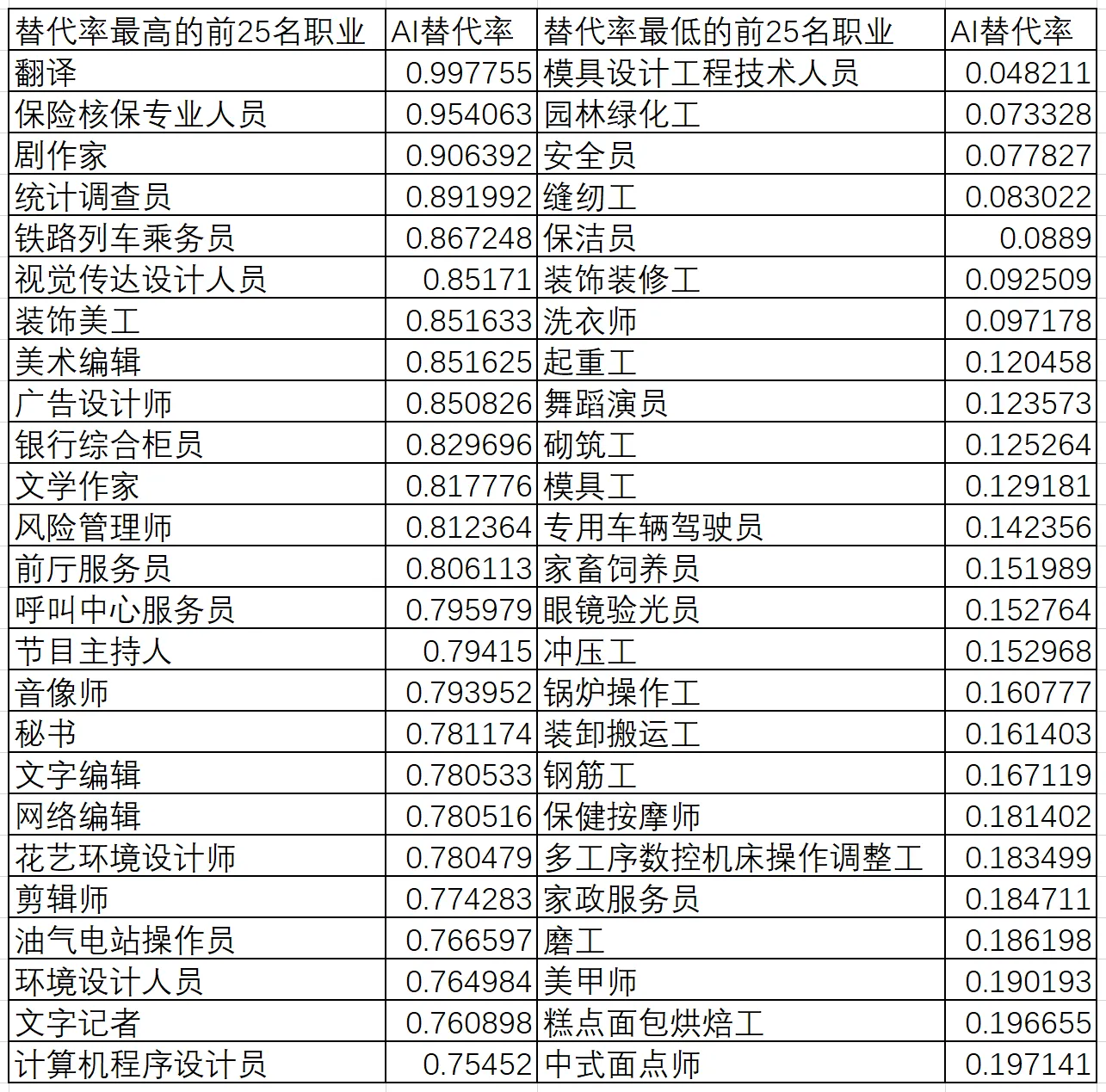
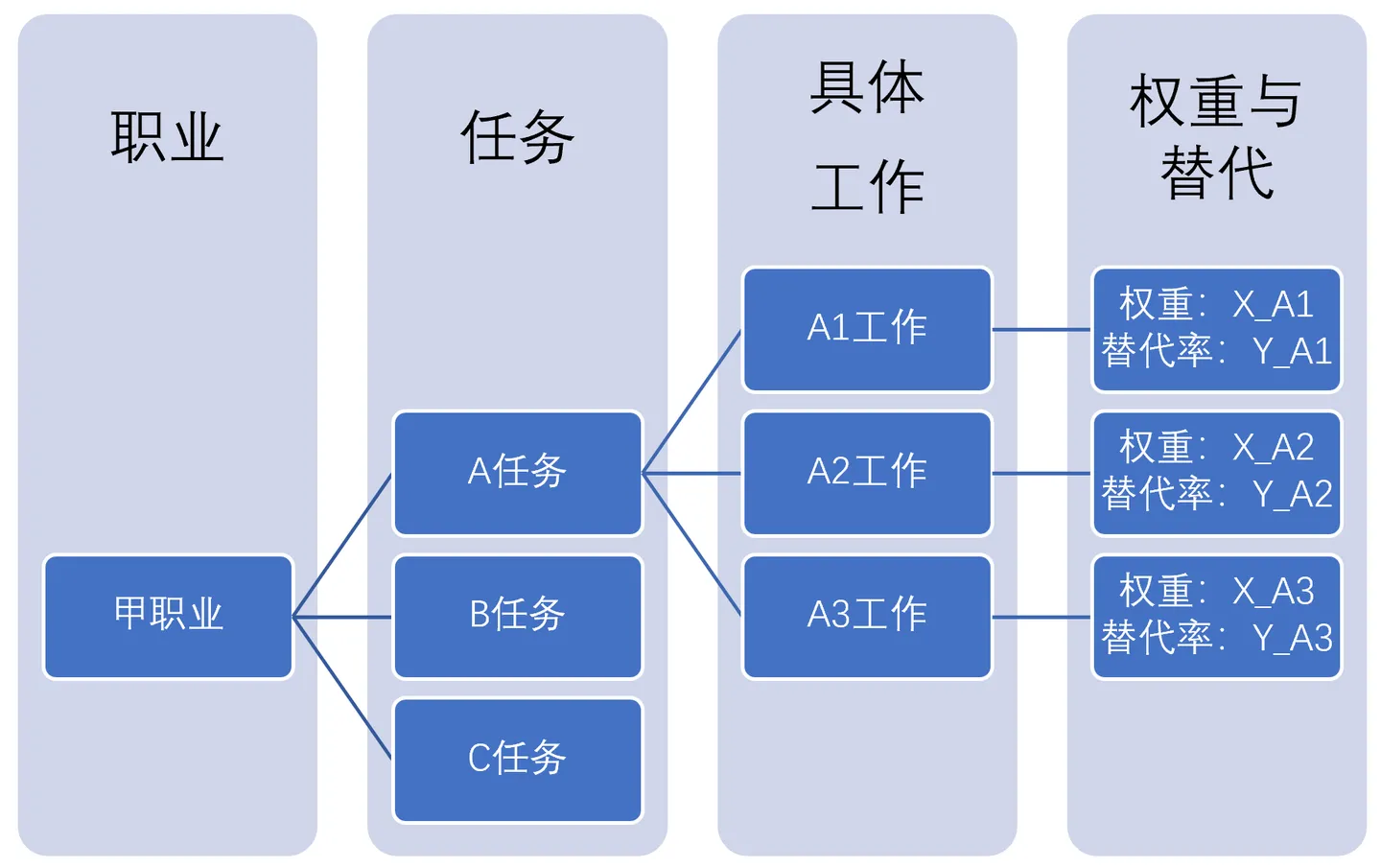 就能得到中國所有職業被GPT替代的可能性了。下表是招聘規模比較大的職業被GPT替代可能性的前25名和後25名:
就能得到中國所有職業被GPT替代的可能性了。下表是招聘規模比較大的職業被GPT替代可能性的前25名和後25名:
 上表的這50個職業,可以理解為未來職業發展的晴雨表。
上表的這50個職業,可以理解為未來職業發展的晴雨表。
AI替代率最高的職業是翻譯,其次是保險核保專業人員以及劇作家。這三個職業,有90%以上的工作任務和內容都暴露在AI替代的風險中。
接下來,視覺傳達設計人員、裝飾美工、美術編輯、廣告設計師、剪輯師,這些與美術、視頻、作圖相關的職業,被AI替代的工作內容也超過了80%。
文字編輯、網絡編輯、文學作家、文字記者,這些與文字生成和修改高度相關的職業,被替代的工作內容也超過了75%。
呼叫中心服務員、前廳服務員(即為賓客提供諮詢、迎送、入住登記、結賬等前廳服務的人員)、節目主持人、秘書……這些職業,也出現在了前25名中。
不過最出乎意料的可能還是排名第25的計算機程序設計員,平均來説,程序員有75%的工作內容,面臨被AI替代的風險。
AI替代率最低的職業主要是各種製造業相關藍領人員。這並不意外,因為我們讓GPT評分標註時扮演的角色就是“大型語言模型替代勞動力評估師”,它自然無法評估可能被其他機器所替代的職業。但仍然有幾個製造業工人以外的人員值得注意——綠化工、保潔員、洗衣師、按摩師、美甲師、中式麪點師……看起來並不需要太高學歷,工資也不算最高的這些職業,反而成了最難被AI替代的職業。
容易被替代的職業都有什麼樣的特徵?
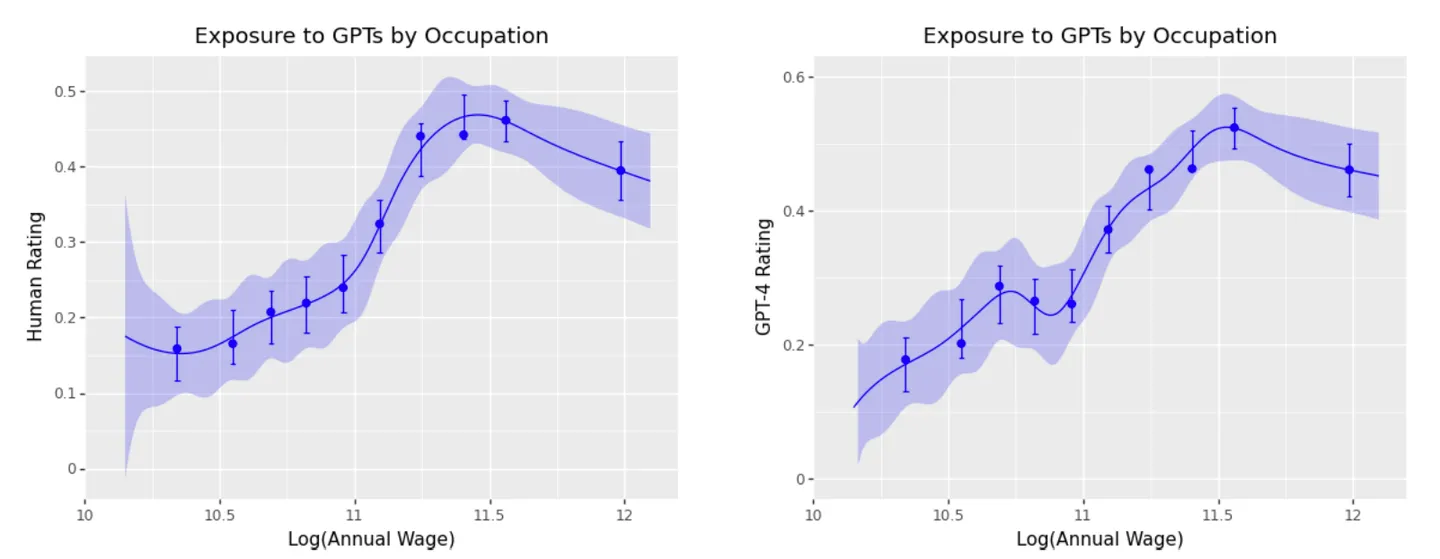
在OpenAI的那篇工作論文中,研究者發現了穩定的正相關關係——工資越高的職業,被GPT們替代的可能性越高。這個趨勢在年收入大於10萬美元的職業之後才區域相反,見下圖。
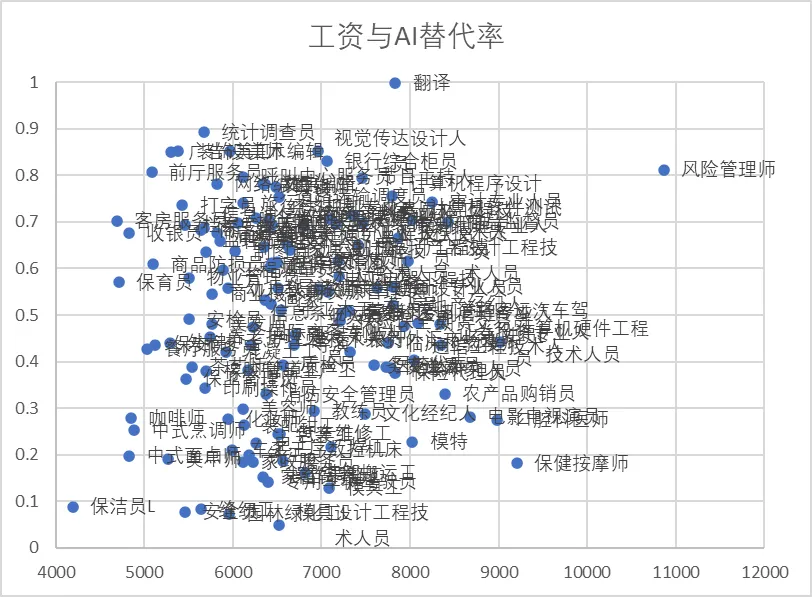
 但在我們的研究中,在中國,每個職業能夠被GPT替代的程度和該職業的收入卻並沒有相關性,見下圖:
但在我們的研究中,在中國,每個職業能夠被GPT替代的程度和該職業的收入卻並沒有相關性,見下圖:
 但是,每個職業除了工資以外,還有一個重要的參數——成長性。
但是,每個職業除了工資以外,還有一個重要的參數——成長性。
“成長性”是我們另外計算的一個數據,是使用分經驗年度的招聘崗位數據,計算跨年度的經驗-工資差異得出的。
舉個例子,A崗位,在2018年時,市場上對0年經驗需求的招聘崗位平均工資為5000元。2019年時,市場上對1年經驗需求的A崗位招聘平均工資為6000元。
不難發現,2018年0年經驗的這批人,和2019年時有1年經驗的這批人來自同一個隊列。因此,6000÷5000=120%,就是同一個隊列的人口,從2018到2019年,0到1年經驗帶來的工資增長倍數。
我們算出所有年份,包括2015到2016、2016到2017……2020到2021、2021到2022這樣7個0到1年的經驗帶來的工資增長倍數,再按照招聘人數加權求平均,就得到了A崗位在過去8年時的0到1年經驗帶來的工資增長倍數。
用同樣的方法,我們再一次算出1到2年的工資增長倍數、2到3年的工資增長倍數……8到9年的工資增長倍數。將每一年的工資增長倍數連乘,就得到了這個崗位從0年經驗到9年經驗一共10年工作的工資增長倍數,將這個倍數再開九次方,就得到了這個職業的“成長性”,即每增加一年工作年限,工資可能上升多少。
那麼,從業年限的工資增長率,即這個工作的“成長性”,和每個職業的AI替代率之間存在什麼關係?
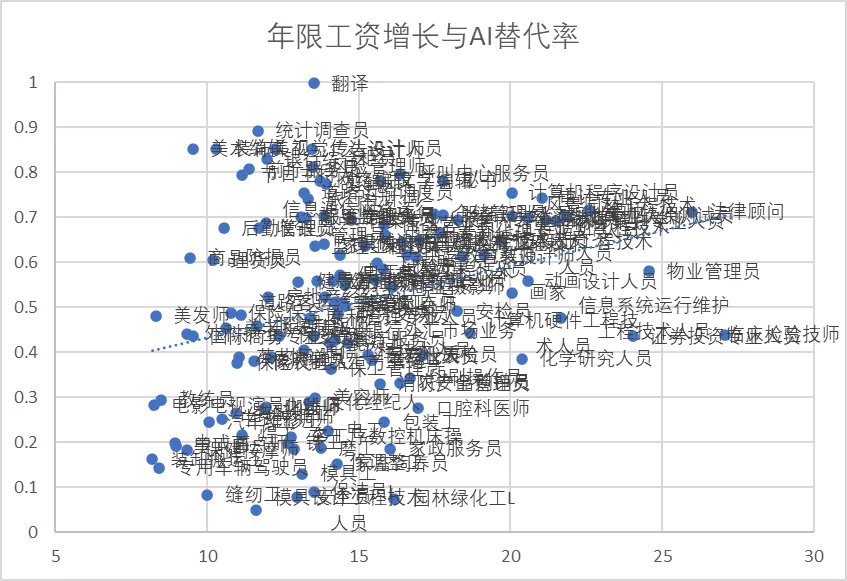 可以看到,各職業的AI替代率,和每個職業的年限工資增長率有着非常顯著的關係,兩者之間存在正相關的顯著性水平在0.001以下。如果我們將上圖改為分段柱狀圖,我們將可以看到更明顯的趨勢。
可以看到,各職業的AI替代率,和每個職業的年限工資增長率有着非常顯著的關係,兩者之間存在正相關的顯著性水平在0.001以下。如果我們將上圖改為分段柱狀圖,我們將可以看到更明顯的趨勢。
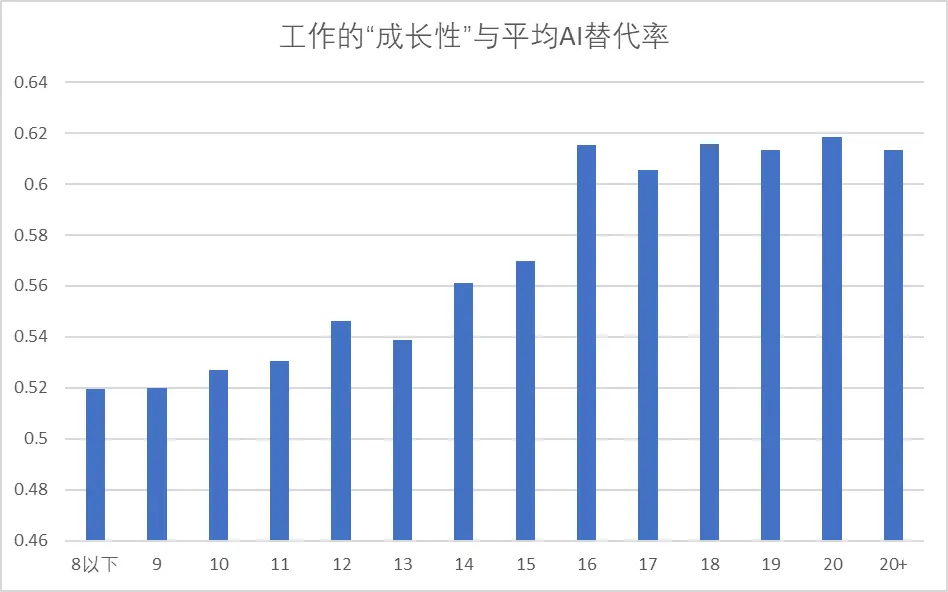 從上圖可以看到,每增加一年從業年限工資增長最慢,低於8%的職業,相對最不容易被AI替代的。但如果一個職業每工作一年工資增長超過20%,被AI替代的可能性平均將大於60%。
從上圖可以看到,每增加一年從業年限工資增長最慢,低於8%的職業,相對最不容易被AI替代的。但如果一個職業每工作一年工資增長超過20%,被AI替代的可能性平均將大於60%。
這個趨勢,説明的是在本輪大語言模型和其衍生出來的相關AI的一個顯著特徵,那就是人們在一個行業上積累的經驗、學到的技巧、掌握的訣竅,是被大語言模型首先替代掉的東西。
被GPT們替代掉的,究竟是什麼?
“成長性”越高的工作,越容易被替代,這説明什麼呢?
第一種可能,是因為那些學習、工作後能積累更多經驗,提高更快生產率的職業,本身更貴,因此更促使人們去找到能替代這些職業的AI,給這樣的AI產品更大的投資,因此這樣更貴的勞動力就成了第一批犧牲品。
這樣的説法初看有道理,但我們也能找到很多反例。最大的反例就是自動駕駛。一方面,駕駛這個技能,人們學習幾個小時至多十幾個小時就能掌握;另一方面,自動駕駛領域投資在人工智能行業內數一數二,但目前的效果距離全路況自動駕駛依然有很長一段距離。
反過來,一些生物、化學方面的技能,化合物尋找、蛋白質摺疊,或者是在實驗流程上的全自動化,這些人們需要數年專業訓練才能掌握的知識,儘管資本的介入比起自動駕駛只能算九牛一毛,卻已經有了非常不錯的替代AI。
從這點看,因為某職業勞動更貴——為了節省這些勞動力而更多投資AI——更容易造出替代這些職業的AI,這樣的邏輯似乎是行不通的。
因此,我們不得不考慮第二種可能——AI確實已經實現甚至超越了人類通過後天的實踐學習知識、積累經驗和訣竅的技能。
是的,有必要再強調一遍,不是單個技能,也不是一組技能,而是那種通過艱苦的學習實踐來獲取知識、積累經驗的技能,人類已經落後於AI。那些高成長性的職業,不管現在是否還處在安全區,出現替代AI,也許就是這幾年,甚至幾個月之內的事。
到頭來,那些人類孩提時期甚至出生時就已經掌握的技能,那些精巧的人類生物學本能,似乎反而是AI最難模仿和替代的部分。
而那些後天學習到的知識,花上好長時間學會算術、學會寫作,學會畫畫,學會編程、學會做好看的ppt、學會看X光片、學會寫法律文書,學會很多種語言並且自如地交流……人類學會了各種各樣以此為傲的東西,並覺得這些特徵似乎使人類和其他生物產生了哲學上的差異。
但在AI看來,這些東西一文不值。