這個臭打遊戲的,想讓整個世界都姓黃?_風聞
酷玩实验室-酷玩实验室官方账号-04-09 07:37
Hello,各位好,今天我想聊一下英偉達。
2023年3月21日,在英偉達2023年GTC(GPU Technology Conference)開發者大會上,黃仁勳做了主題演講,通篇沒有一處提到遊戲顯卡。而是從頭到尾圍繞着“加速計算”和AI的“iPhone時刻”到來展開……

從去年到今年,整個科技圈最火的概念毫無疑問就是AI,尤其是AIGC也就是生成式AI的發展,讓人有一種AI即將覺醒的壓迫感,什麼區塊鏈、Web3.0、元宇宙似乎已成昨日黃花,科技圈風口你方唱罷我登場,讓人不得不感嘆世界潮流之洶湧!
AI預測蛋白質結構、AI作畫、再到ChatGPT的連續風靡,讓AI成為最熱門的話題。
而這些讓人驚掉下巴的AI應用背後,一切的基礎當然還是那兩個字——算力。
AI背後的算力引擎,不是CPU而是GPU,而這個領域目前的主宰就是黃仁勳和他的英偉達(NVIDIA)。
英偉達從93年開始,做3D遊戲顯卡起家,後來99年發明GPU,再到認識到GPU不僅能做3D遊戲渲染而是代表了一種與CPU不同的並行算力,而後推出CUDA開發框架,再到GPU能挖礦,直到如今對AI的支持……並行計算的演化,在不知不覺中完成了史詩級的跨越。

誰又能想到當初那個臭打遊戲的,如今成了決定未來的霸主……
看完本次GTC大會,大有一種未來最前沿的科技都得姓黃的觀感。。。
黃仁勳在大會上都説了啥?GPU對AI的加持有多強?英偉達又發佈了哪些新硬件?扔出了哪些王炸?讓我們來跟蹤解讀一波。
01
加速計算和AI的“iPhone時刻”
黃仁勳整個演講最先拋出來的就是“加速計算”這個概念。
通篇看完我的感覺是,所謂加速計算,就是老黃要把之前由CPU完成的計算,其中凡是大規模的、複雜的,適合並行計算的計算,全部由GPU搶過來。
“加速計算”當然需要從芯片、系統、網絡、加速庫等方面綜合推進,但其中英偉達強推的核心部件就是所謂**“加速庫”**。

這就像我們做木工會用現成的工具一樣,程序要要解決特定的問題也不可能從0101001開始編程,而是從特定的“工具庫”中調取“工具”進行搭配,而英偉達的所謂加速庫,就是這個“工具庫”,專門針對某個特定領域計算的一組軟件的統稱,功能就是讓某一種計算的速度大大加快!
黃仁勳提到的這些領域包括,光線追蹤和神經渲染、物理、地球和生命科學、量子物理學、化學和計算機視覺、數據處理、機器學習等等,反正一眼望去都是未來最重要的科技行業,英偉達“加速庫”目前涉及的領域已經成百上千個。
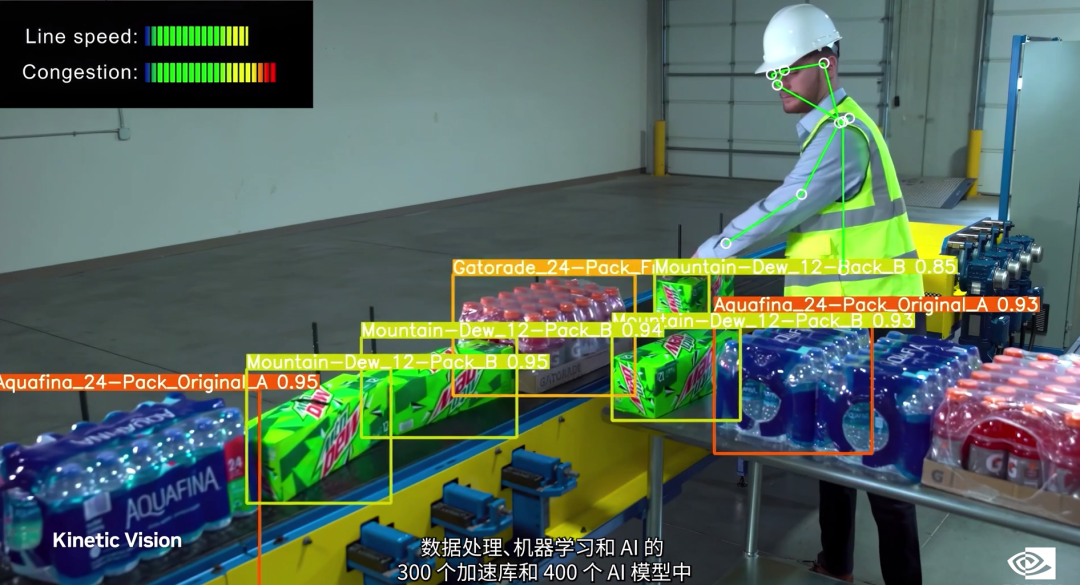
老黃首先展示了一個用於流體力學的加速庫CFD,這看上去確實很酷,整個演示極具科技感!其實這並不意外,對英偉達來説這本就是拿手好戲,這個技術基礎是從遊戲中直接過渡過來的。
3D遊戲裏的水流、爆炸、軟體等等,一直是遊戲效果長期研發的關鍵,畢竟NVIDIA長期以來有自己的物理引擎PhysX,這些技術與有限元分析結合,用於工業上數字孿生仿真,就可以挖掘出很多潛力價值。

流體模擬其實應用範圍很廣,從船舶到飛機、汽車,從建築到工業散熱,總之都是賺大錢的行業。
有了這個,在工業設計上確實能節省很大的成本。用軟件模擬工業效果,可能目前達不到真實風洞一樣完美,但起碼能省下不少步驟了。
老黃介紹用A100算卡做CFD,GPU比CPU而言,效率提高了9倍,成本節省了90%,能耗減少了17倍,確實強!猜測如果用上H100,那就更恐怖了!
黃仁勳説英偉達今年更新了其中的100個加速庫,其中最令人印象深刻的就是,對芯片製造光刻環節的加速庫cuLitho,這個加速庫將計算光刻加速了40倍以上。
這玩意兒本質上,就是對光掩模版製造的加速。芯片製造的核心環節是光刻,簡單講就是光通過一個掩膜版照到光刻膠上,讓光刻膠曝光融化。
這個掩膜版就是芯片的整體圖紙,然而如今芯片製程發展到3nm級別。已經不是簡單的宏觀物理下光直線傳播或者衍射就能解決的了,事實上掩膜版上的圖案跟最終光刻到晶圓上的圖案並不一致,所以需要通過麥克斯韋方程描述,逆物理算法來預測掩膜版上的圖案。
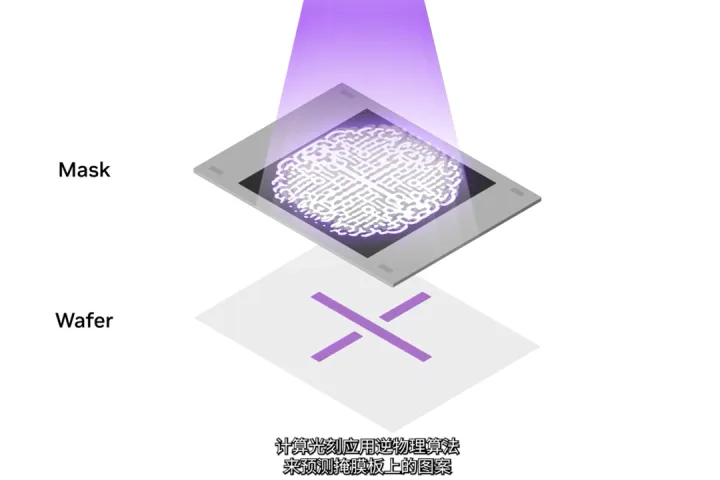
這是一個巨大的計算負載,以往都是用CPU來算,消耗極大。每年消耗數百億CPU小時,需要大型的數據中心做到24h*7d全天候的運行。
現在英偉達和台積電、阿斯麥等公司密切合作四年,搞定了這個“核彈”級別的光刻加速庫cuLitho。
最關鍵的是,一塊芯片的製造往往需要若干塊掩膜版,光刻很多次才能完成製造!
據老黃舉例:英偉達H100芯片的製造,總共需要89塊掩膜版,當前在CPU上運行時處理單個掩膜版的時間需要2周!但如果在GPU上運行cuLitho,只需要8個小時就可以處理完一個掩膜版。

台積電可以通過在500個DGX H100系統上使用cuLitho加速,將功率從35MW降至5MW,從而代替用於計算光刻的4萬台CPU服務器。
藉助cuLitho,台積電可以縮短芯片的製造週期,提高產量,減少製造過程的碳排放,併為2納米以上的生產做好準備。黃仁勳表示,台積電將於6月開始對cuLitho進行生產資格認證。
老黃本次演講中另個一重要的加速庫就是,圖像處理加速庫CV-CUDA和用於視頻處理的VPF,這倆是新的雲規模加速庫。簡單來説就是在雲上,做大規模的視頻和圖像處理用的,能夠極大的加速這兩方面的處理速度。
其實這兩個加速庫在總體演講中佔的篇幅並不大,為啥我們要重點講一下呢?我覺得這裏面是有兩個隱藏條件:
1、英偉達CV-CUDA的主要合作方是中國,研發夥伴是字節跳動,但TikTok目前在科技戰背景下,處境有點尷尬,所以老黃故意簡略了這塊內容,只提了騰訊。
2、目前互聯網上文字類內容其實並不佔大頭,圖像和視頻內容是更多的,這對雲算力來説是塊肥肉。
ChatGPT4最大的進步就是支持了圖像和視頻!現在互聯網上的信息尤其是短視頻,是最多的,所以必然這塊的算力需求也是天量,以往這些視頻處理負載都在CPU上處理,非常艱辛,老黃看到了之後非常感動,眼淚不禁從嘴角流了下來。
老黃自己在演講中也提到,目前80% 的互聯網流量來自於視頻,而50%-80%的雲視頻工作運行在CPU上。用户生成的視頻內容,正在推動流量大幅增長並消耗大量能源,我們應該加速所有視頻處理並降低能耗。
CV-CUDA是圖像處理加速庫,用於檢測、分割、分類,也就是説在用圖片搜圖片,AI識圖等方面很有用。當然視頻就是多張圖片連起來。VPF是一個視頻編碼加速庫,也就説能讓視頻處理速度增加,比如換背景啊、換濾鏡啊、視頻剪輯啊等等。

我們的視頻都是要上傳到雲上,再編輯各種效果,再發出去讓粉絲們來觀看,如果視頻處理速度慢,那麼就會出現各種卡頓!有了這倆那速度就快多了!目前騰訊使用CV-CUDA和VPF每天處理30萬個視頻。
英偉達數據顯示,以圖像背景模糊算法為例,將用GPU計算的CV-CUDA替換用CPU計算的OpenCV作為圖像預/後處理的後端,整個推理過程吞吐量能增加20 多倍。
除了以上這些,老黃還更新了包括:量子電路仿真的加速庫cuQuantum,加速物流服務的cuOpt,用於基因工程的Parabricks等等加速庫,不一而足……
這些加速庫可以在物流分發,工程調度統籌,量子計算機糾錯,基因工程模擬等等方面給予極大的算力支持,未來這些方面的科技效率將大大提高。
説白了,以老黃的眼光來看,在加速庫盛行之前,很多工作是在用“蠻力”去算,調動更多的CPU工作,花費更多的電力和時間。打個不恰當的比喻,就是用幾個博士在做大規模的四則運算工作。
GPU的並行計算可以讓大量中學生去做四則運算,CPU當好自己的總指揮就行了!CPU適合複雜的計算,GPU才適合簡單的大規模計算。更加合理的安排計算卡上的算力資源(CUDA核)和存儲資源(顯存),才是根本。
加速庫的作用是,給大規模的小學生更加合理的安排優化統籌,哪些學生做加法,哪些學生做減法,男生做十以內的運算,女生做十以上的運算。更加優化的流程和分工,讓效率更高一步!如此一來整體節省下來的效率,比幾個博士去靠“蠻力”算,不知道高到哪裏去了!
並且這些加速庫都是基於英偉達的CUDA框架,跟特定領域的專業團隊聯合開發的。也就是説,英偉達的CUDA框架和與之協同的一系列加速庫,構成了人類關於如何加速計算這些問題的封閉的知識庫,現代的亞歷山大圖書館。
現在我們做任何關於GPU功能的開發,已經無法離開CUDA框架,而這個壟斷的局面顯然會隨着這一系列加速庫的發展而被加強。
02
扔出硬件王炸,助力AI起飛
説了半天加速庫,説到底老黃的基礎邏輯就是,未來算力的重點在數據中心,而用加速庫讓GPU搶更多CPU的活,既可以提高算力,也可以節省能源,降低碳排放,豈不美哉。
但畢竟英偉達是一家做硬件芯片的公司,所以大家最關心的,還是英偉達扔出什麼樣的硬件芯片,是否有王炸產品。那老黃肯定不能讓大家失望啦,於是他接下來就發佈了四大硬件。
英偉達推出了4款全新GPU 推理芯片,分別是L4,L40,H100 NVL和Grace Hopper ,分別用於加速AI 視頻、圖像生成、大型語言模型部署和推薦系統。也就是對網絡上用的最多的幾種AI應用,有針對性的發佈硬件去處理它們,又是一種針對AI的刀法。
60歲的老黃還是當年那個皮衣刀客,沒有一點點改變!

L4和L40都是基於Ada Lovelace架構的張量核心GPU,需要注意的是Hopper架構和Ada Lovelace架構都是英偉達最新的GPU架構,分別面向數據中心和遊戲顯卡。H100就是Hopper架構,而最新的40系列顯卡是Ada Lovelace架構。
L4主要針對的是AI視頻工作優化,尤其是視頻解碼,轉碼,還有視頻內容審核,感覺這東西對抖音B站這類視頻網站簡直是神器啊。相信有了這東西,我們在APP或者視頻網站上傳視頻,剪輯視頻等等,速度將大大提高。

因為之前這些工作往往在數據中心,部署在CPU完成。現在一台8-GPU的 L4服務器,將取代一百多台用於處理AI視頻的雙插槽CPU服務器,8個L4捆在一起就是一個核彈級服務器。
L40的功能也很厲害,主要針對的是圖形渲染、文本轉圖像和文本轉視頻,L40的性能是目前最受歡迎的T4 GPU的10倍。這東西的作用主要是能通過AI,讓所有人都輕鬆做視頻特效,並且做到專業級別。
再加上30多種雲端工具和加速庫CV-CUDA的加持,讓我看到了普通人做剪輯和特效也能達到專業水準的可能性。事實上好萊塢已經在電影中用到這個技術了。
簡單幾筆就能消除視頻裏的某個對象,以後如果哪個明星再翻車,在電視劇或晚會里把他擦去就太簡單了!
視頻換背景、做特效這種事兒,原來需要幾小時的工作,現在幾分鐘就搞定了!

第三個核彈就是H100 NVL。
現在ChatGPT這麼火,怎麼能夠沒有針對ChatGPT的神器呢?
H100 NVL是已有 H100 系列的特殊加強版,專為大型語言模型 ( LLM ) 優化,是部署 ChatGPT 這類應用的理想平台。
由於ChatGPT是大模型訓練,所以對顯存需要特別大,所以這個H100GPU直接配上了94GB的HBM3 顯存,H100 NVL 還可以雙卡組成一個計算組,顯存188GB,一個服務器四對H100,訓練ChatGPT如虎添翼。

事實上基於Transformer 引擎加速的ChatGPT,之前唯一運行這個大模型的GPU就是A100,現在H100 NVL與上一代 A100 相比,在GPT-3 上的推理性能提高了多達10倍。
看了上面三個核武器,我隱約有種不祥的預感,你英偉達通過GPU和加速庫,搶了這麼多的CPU的工作,X86家族能接受嗎?活兒都讓你GPU幹了,還要我幹嘛?

沒錯,這正是老黃絕情之處。我管你配合不配合,老子自己出CPU,於是Grace CPU來了,完全沒有把X86當人。

Grace是基於ARM架構的72核心CPU,並且老黃還掏出來一個兩個核心連接在一起的,144核心超級核彈CPU——Grace Superchip,內部通過900GB/s的低功耗接口NVLink連接。

這東西還配備了1Tb的高度內存,而且竟然是被動風冷散熱,簡直驚掉下巴,老黃對自己的CPU功耗和性能真是太自信了。

當然這東西不是專門針對不同領域發佈的四大核彈之一,最後一個大核彈是Grace Hopper 超級芯片,也是內部通過900GB/s的芯片到芯片接口NVLink-C2C連接。
不過這次連接的是一個Grace CPU+一個Hopper GPU,牛逼啊!
有了Grace Hopper,媽媽再也不用擔心,大型數據集、大型AI大數據庫的處理了!一個簡單的技術原理是,AI往往處理的是非結構化數據,不是一定準確無誤特別規則的文本!也許就是個聊天記錄,或者產品的評論什麼的。

而這些數據往往是向量數據庫,就是説它本質上不是查詢一個準確的結果,而是某一種風格,某一種個性。
而AI在後台的處理,就是對比一些不可描述的高維向量的形狀,輸出的就是最相似形狀的結果。
所以像個性推薦這種事,以後就要靠這個核彈來解決了!
Grace Hopper可以充分利用大容量內存,讓CPU查詢巨型嵌入表,然後將結果傳輸到GPU進行推理,速度比PCIE快7倍。客户希望構建規模大幾個數量級的AI數據庫,Grace-Hopper是理想的引擎。
説了這麼多,其實還都是老黃的刀法玩的好呀。針對不同的領域,不同的功能,不同的市場在做的各種佈局!
説白了就是細分優化,多搶錢!
而真正的現代AI工廠,並不是上面這些,而是DGX超級計算機。

老黃所謂iPhone時刻已經到來,他説這話的底氣,就是基於DGX超級計算機的數據中心。
老黃説的清楚,NVIDIA的一切加速計算始於DGX(AI超級計算機),之前就是他把首款DGX交給了OpenAI,才有了今天的ChatGPT。

現在DGX已經成為AI領域的標配!這東西里面有8個H100 GPU模組,這8顆H100 GPU也是用NVLink來連接,速度極快無阻塞,8個合在一起成為了一個超級GPU,然後更多個這樣的模組,組成AI超級計算機,有點恐怖啊。
老黃給DGX H100超級計算機設計的目標,是為全球客户構建AI基礎設施的藍圖。

是的,他想通吃!
他想給所有想做自己AI模型的公司,直接提供雲服務,甭管你是初創公司還是老牌公司,你想弄自己的AI模型,又沒有那麼大的投入能力?
沒事,花小錢辦大事兒,直接用我的雲服務,你也可以擁有自己的ChatGPT,我説的!
NVIDIA AI可以讓客户定製自己的AI服務,通過一個瀏覽器,就可以將DGX AI超級算力接入你的公司,這就是NVIDIA DGX Cloud雲服務。
這個雲服務跟我們一般理解的雲服務還不一樣。
因為AI深度神經網絡的訓練過程,是一個黑箱,你一旦換了雲服務就不知道能不能達成一樣的訓練效果了,也就是遷移成本極高,會有很強的依賴性。
基於雲這塊,老黃的野心可不小啊!
03
雲服務
關於本次大會英偉達展示的雲服務,有兩個亮點讓我印象深刻。
Picasso Service雲服務和NVIDIA BioNeMo服務,他們都是基於雲計算的生成式AI技術,當然老黃在演講的最後也還是不出意外的吹了一波Omniverse。
雲服務裏面未來最有科技感的,我反而覺得是BioNeMo Service,這是一種用於早期藥物發現生成AI的雲服務,具有九種最先進的大型語言和擴散模型。
可通過Web界面或完全託管的API訪問,並且可以在NVIDIA DGX Cloud上進一步訓練和優化,生物學生成式AI的工作流程得到了優化和統包。
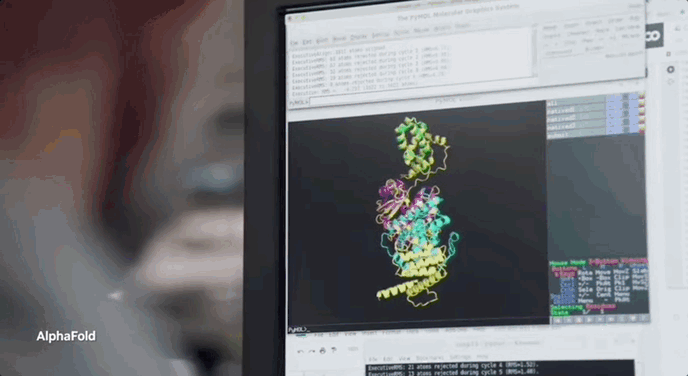
藥物研發是價值2萬億美元的行業,不誇張的説,分子生物學是除了AI以外當今世界最前沿的科學領域!而隨着AlphaFold等工具的出現,AI給分子生物學插上了翅膀,兩者Buff一疊加,未來的潛力可想而知。

**藥物研發説一千道一萬,最重要的流程就三個,找病因-設計藥物-實驗效果!**目前,利用AI發現疾病的靶點,也就是病因,然後生成各種化合物或蛋白質類藥物,再模擬藥物對人體的效果,BioNeMo全鏈條支持,有點酷。
據老黃講,目前已經有一些公司通過這個技術搞出來了新藥,並且就要用於臨牀了。

BioNeMo服務具有九個AI生成模型,涵蓋了開發AI藥物發現管道的廣泛應用:AlphaFold 2、ESMFold和OpenFold用於根據一級氨基酸序列預測3D蛋白質結構、用於蛋白質特性預測的ESM-1nv和ESM-2、用於蛋白質生成的ProtGPT2、MegaMolBART和MoFlow用於小分子生成、用於預測小分子與蛋白質結合結構的DiffDock等。
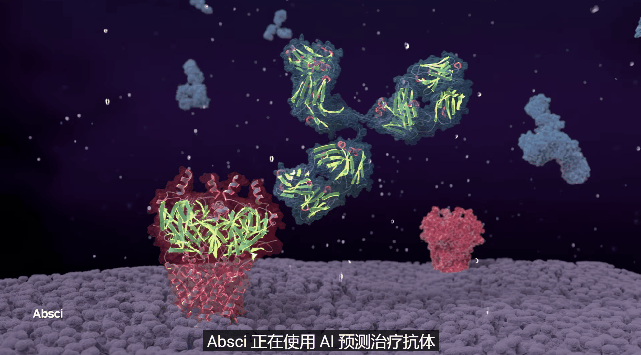
BioNeMo未來可以為藥物研發,節省大量時間和資金成本。毫不誇張的説,也許在未來幾年,會有現在的疑難雜症被AI解決。
雲服務裏面第二個令人印象深刻的就是Picasso Service雲服務。説到底我最感興趣的其實就是AI生產3D場景,這東西號稱是用於構建和部署生成式AI驅動的圖像、視頻和3D應用程序,具有高級文本到圖像、文本到視頻和文本轉3D功能,可通過簡單雲API提高創造力、設計和數字模擬的生產力。
説白了就是,ChatGPT可以為你生成文本,比如寫詩、寫文章、寫代碼。而到了ChatGPT最新版本的ChatGPT4,它已經可以為你生成圖片和視頻了,短時間內吊打了上一代。
那Picasso就是生成式AI中,另一種視覺創建內容方式,A****I大規模生成3D場景。
現在做3D遊戲VR應用最大的瓶頸就是3D內容生產成本太高,當圖片、視頻和3D場景都能生成到以假亂真的時候,什麼元宇宙啊,數字孿生啊都不在話下。
當你跟電腦隨便描述一段話,它就能給你生成你想要的任何視頻或3D效果的時候,這種衝擊力將是巨大的!這將會是AI的又一個里程碑,到時候建模的設計師們有可能會失業,而建築、工業、電影、娛樂等等行業都會被徹底改變。
這個技術對於英偉達來説非常合適,畢竟他長期研究3D遊戲,又有物理引擎,再加上AI的加持,未來可期。
04
對大會內容的一些理解
本次GTC開發者大會,英偉達總體是面向未來新技術的整體佈局,從軟件到硬件再到雲服務。英偉達正朝着,以算力為基礎的平台型公司發展。
算力是英偉達的殺手鐧,通過GPU設計能力和CUDA開發框架壟斷算力,推廣到加速庫、雲、大數據、AI等等方面,再延展到各個高科技行業做整體佈局。
回望過去,英偉達的發展歷史給人一種一路開掛的錯覺,從3D遊戲到GPU,從挖礦到AI,一波接一波的算力需求浪潮,讓英偉達每次都走在了時代的浪尖上,隨之就是公司規模的擴大,並行計算算力的極速擴張。
但不要忘了,英偉達的起點也只是三個三十多歲的年輕人創立的小公司,在早期的圖形加速卡競爭當中並不是Voodoo的對手,靠世嘉的提攜才陰差陽錯站穩腳跟,也曾因為錯過了移動互聯網革命而跌入低谷,但黃仁勳這個人身上確實一種強烈的科技企業家的特質,就如漆黑中的螢火蟲一樣讓人過目不忘。

比如他也跟一般的商人一樣喜歡吹牛逼、提新的概念,但他提新概念不是基於一時的市場趨勢,而是基於技術前景+市場趨勢的有機結合。
比如他一直説英偉達在1999年發明了GPU,但其實早期GPU跟圖形加速卡並沒有本質區別,只是因為他認為圖形加速計算的發展潛力很大,外加3D遊戲市場已經被打開,所以負責圖形計算的那塊卡應該被重新定義,應該擁有自己的姓名。
再比如他也會像一般的商人一樣,企業做大了之後就會想橫向多元化發展。但他的橫向發展不是轉進到房地產,而是基於對技術底層的充分理解,對於一項技術本質上是在解決什麼問題的充分理解。
英偉達之所以在所有顯卡廠商當中一騎絕塵,能夠乘上後來的視頻網站、區塊鏈挖礦到AI的一波又一波的風口,關鍵的步驟是在2006年發佈CUDA架構,把業務從3D遊戲擴展到所有需要大規模並行計算的領域。
這背後是黃仁勳認識到,GPU這種芯片的潛力並不僅僅在於同時算幾百萬的三角形,世界上需要大規模並行計算的場景很多,GPU可以使這一切都得到加速。
中國也需要像黃仁勳這樣的科技企業家,中國也需要英偉達。