崑崙萬維「天工」大模型開啓內測,我們跟它聊了聊理想_風聞
AI蓝媒汇-AI蓝媒汇官方账号-欢迎关注公众号:jizhezhan04-26 18:00

國產ChatGPT,能再迎一次驚喜嗎?
來源|AI藍媒匯
ID:lanmeih001
作者|伊柒
編輯|魏曉
“每隔一段時間,就會有一個革命性的產品出現,然後改變一切。”
這是2007年1月9日,喬布斯在一次手機發佈會上的開場白。手機名叫iPhone,它改變了通訊、娛樂和移動互聯網。之後,iPhone或是和iPhone類似的手機,出現每個人的手中。
2022年11月30日,由OpenAI研發的ChatGPT問世。
在最初的描述中,ChatGPT被稱為“聊天機器人程序”,但人們發現這個AI能做的不只是“Chat”——之後的幾個月,人們陸陸續續將它接入各種場景:答疑、編程、繪畫、翻譯、文本創作、廣告設計、頭腦風暴……然後震驚於AIGC的想象力、創造力和生產效率。從聊天到創作,或許在2023年之後,沒有任何一個行業有理由完全排除AIGC。
此時此刻,恰如彼時彼刻。
但也有不同——這一次,國內AI行業的跟進遠比過去及時。百度、商湯等幾位AI課代表很快推出了類似ChatGPT國產AI大模型,外界的質疑聲中漸漸聽到了掌聲。
2023年4月,崑崙萬維「天工」3.5大語言模型發佈,並啓動邀請測試。AI藍媒匯(ID:lanmeih001)的藍媒君第一時間對話了「天工」大模型。

對話的內容,都和“理想”有關:
AI大模型沒説自己的理想,但它鼓勵藍媒君堅持理想——“記得不要因為挫傷自尊心而放棄。”
崑崙萬維的理想——“目前版本我們對標的主要是OpenAI的ChatGPT。未來讓它儘快達到GPT4的能力。”
國產ChatGPT,能再迎一次驚喜嗎?

第一個實現“智能湧現”的國產大模型
在和「天工」大模型的對話中,藍媒君預設了一個場景:中學老師與學生對話,目的是確定學生的興趣。
對話過程如下。
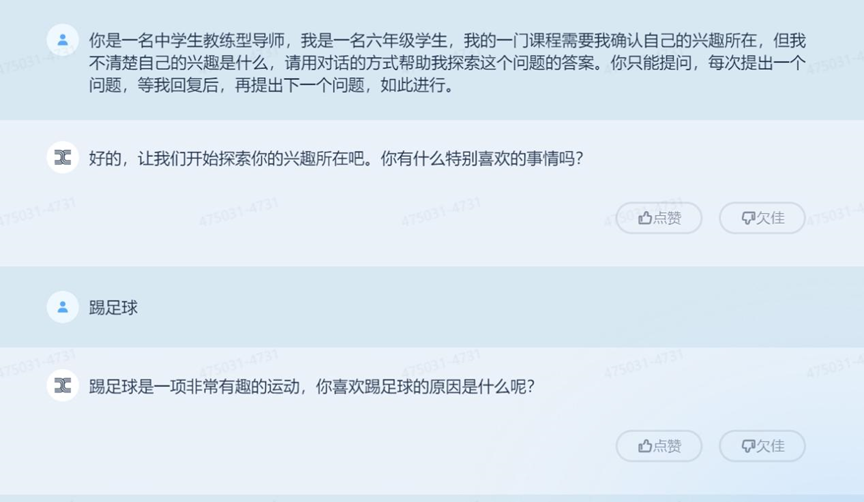
藍媒君確實曾和體育場裏面的小朋友聊過這個問題,當時小朋友的回答是“喜歡跑步”、“覺得好玩”。

儘管在一開始就預設了問答模式,但「天工」大模型在實際對話中並沒有完全遵循“每答必問”的結構——或許是算法判定藍媒君“喜歡踢足球”這個話題已經討論充分,可以作為“你的興趣是什麼”的答案。
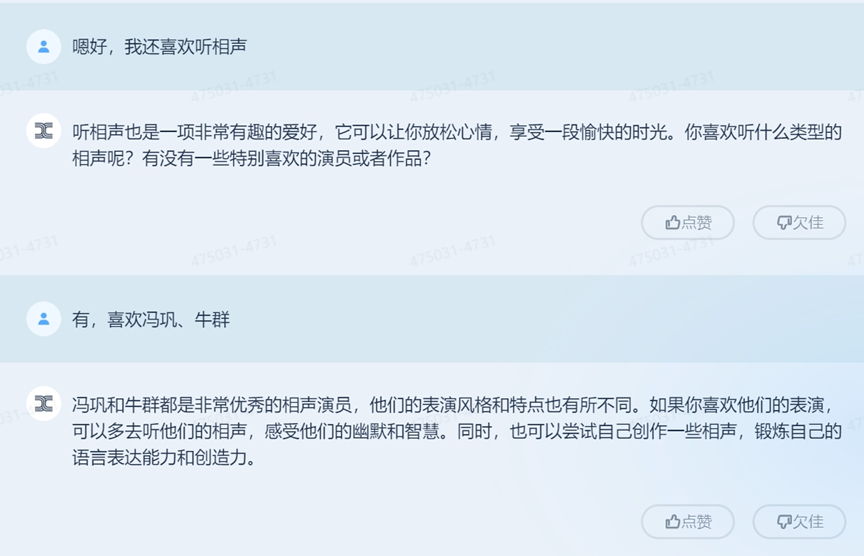
藍媒君提出了第二個興趣,看書。

從這裏可以看出,「天工」大模型依然延續着剛才關於“確定興趣”的這個話題,並遵循了問答結構。
對話繼續,藍媒君的愛好很多。

「天工」大模型所給出的反饋始終直白,像是兩位小朋友最日常的對話:你喜歡科學,那你會怎麼做?
以上文本在成年人看來略顯簡單,但一問一答確實符合需求——「天工」的回答做到了邏輯通順、推進溝通。而這種簡單通順,或許正是人們需要的。

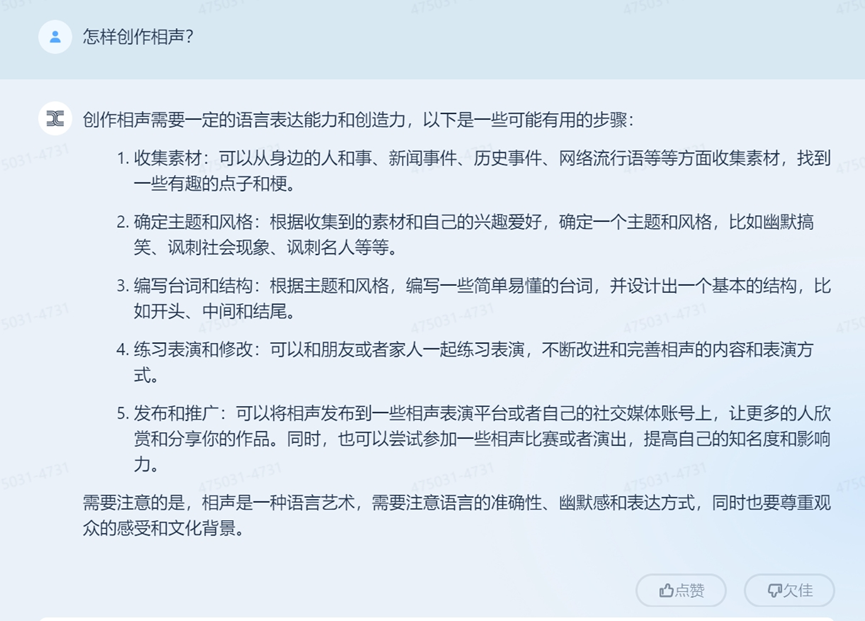
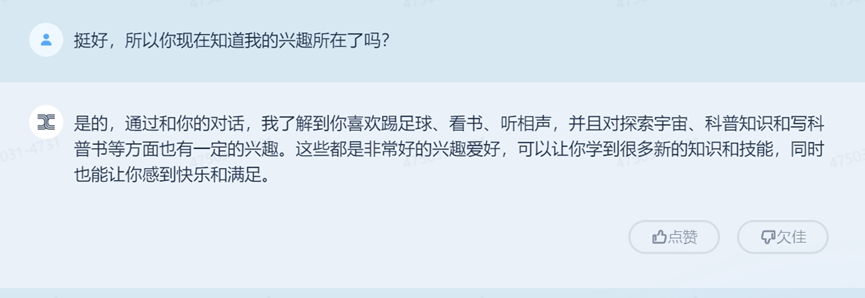


或許整場對話難言十分驚喜,但至少從對話邏輯和內容上,「天工」基本做到了連貫通順、符合人類邏輯。
在談到大模型的邏輯推理時,崑崙萬維稱,「天工」目前的記憶力大約可支持20輪次以上的交互式問答,文本容量也在萬字以上。
“在AI領域,進行自主學習並完成邏輯推理等任務的能力,被稱為‘湧現’能力。”而根據崑崙萬維CEO方漢的介紹,「天工」大模型是目前“國內第一個實現智能湧現”的國產大語言模型。
這是一個在相對簡單的系統中,由量變產生質變,最終產生複雜的行為或特性的過程。
而根據官方提供的測試數據,基於千億基座模型和千億排序模型,「天工」大模型生成內容已經能夠在某知識社區的問答中,獲得KOL級的贊同和回應。
但「天工」偶爾也有失誤的時候。
在另一份關於數學題的測試中,天宮大模型準確算出了一道雞兔同籠題目,但卻被另一道來自中學數學課本的一元一次方程困住,並最終得出了一個錯誤的計算結果。

或許是對題乾的理解偏差,或許是方程組相關的數據訓練還不夠完善,「天工」在運算方面的能力和方法,仍有些改進空間。
談及大模型訓練的工程進度,崑崙萬維方面表示,關於數據的篩選、剪枝和清洗是“長期主義”的過程——「天工」大模型將在後續的迭代中,通過篩選數據調整參數改進模型設計。
“問題會有,但正視差距不會影響團隊的信心。”
而「天工」大模型,也只是崑崙萬維在AIGC賽道內的落腳點之一。
合作破局
和大模型同期公佈的,還有崑崙萬維同阿里雲的AI合作項目。
4月11日的阿里雲峯會上,崑崙萬維與阿里雲共同發佈了包括智算中心建設、大模型訓練等領域戰略合作。
這並非是兩家公司首度牽線——2015年到2020年間,崑崙遊戲、閒徠互娛,OPay海外支付業務已經相繼接入了阿里雲業務。
兩家公司在AI領域的合作則稍晚一些。2021年,崑崙萬維開始規劃自建大語言模型之後,於2022年2月敲定第一批AI算力集羣的項目合作。
項目的合作方,正是阿里雲:**“當時合作主要是依託阿里那邊的高性能AI計算集羣,進行大規模語言模型預訓練工作。”**訓練內容囊括了算法與架構的協同、計算流水線與架構的協同、最優化存儲、TCO優化四個方面。
雙方此番合作,目標是則是要進一步盤活國內AIGC生態——不只是大廠背書,還有技術合作。
崑崙萬維方面表示,隨着「天工」訓練規模的擴大,模型參數逐漸接近萬億規模,“單個訓練任務需要5000張以上A100(GPU芯片),這樣大規模的GPU集羣下,通信會產生大量的擁塞,訓練效率會越來越低,對存儲讀寫性能同樣是個挑戰。”
而阿里雲所提供的,則是業內最領先的算力平台。“後續崑崙萬維的AIGC業務,預計會有阿里雲的靈駿底座+PAI軟件平台加持。”
AI藍媒匯曾在《黃仁勳,ChatGPT時代的第一位贏家》一文中提及,**國內AIGC項目始終繞不開算力和成本的阻力,**崑崙萬維CEO方漢也表示,在目前的大模型訓練中,購買或者租賃英偉達的A100系列GPU仍佔據了不少開銷。
“資源是一張門票。大模型訓練的門檻就是幾千張GPU芯片。而在芯片到齊之後,接下來還要拼工程經驗——實驗的速度,人才的厚度。”
圍繞ChatGPT開展的AIGC項目,在變現之前仍需付出。
按照計劃,在2023年的6、7月份,阿里雲會為崑崙萬維打造一個專屬的、支持萬卡擴展的AI算力集羣。
“我們期望與阿里雲展開深入合作,激活國內AIGC技術生態,為中小企業和開發者的創新提供便利。我們一直覺得,當產品的能力足夠好、真正能夠幫助用户解決剛需,那麼獲得經濟回報就是水到渠成的事。”
而現階段崑崙萬維的業務重心,則仍在研發和訓練領域:“潛下⼼認真打磨產品,幫助模型進化到更高水平,讓它儘快達到GPT4的能力。”
可以預見的是,在未來一段時間內,包括崑崙萬維在內的國內AI玩家,仍將面對GPU資源量方面的阻力,仍將是賽道內的追趕者。
至於何時追近,能否比肩,AIGC的從業者同樣需要市場和時間來解答。
今日話題
你想和AI大模型聊什麼?