算力256TOPS,典型功耗35W,存算一體芯片殺入智能駕駛_風聞
HiEV大蒜粒车研所-HiEV大蒜粒车研所官方账号-05-11 09:01
作者 | 張祥威
編輯 | 德新

國產智駕芯片有了新玩家
“最高物理算力256 TOPS,典型功耗35W,基於12nm製程工藝。”
5月10日,後摩智能發佈首款基於存算一體架構的智駕芯片——鴻途™H30,並公佈上述關鍵指標。
算力、數據和算法,並稱AI的三大核心要素。其中,算力屬於基礎設施,又被稱為新時代的原油。隨着ChatGPT語言大模型的出現,AI迎來了自己的iPhone時刻,算力的重要性也愈加凸顯。
走在最前的英偉達,不斷推出更高算力的芯片,一些玩家選擇了跟隨,另外一些選擇另闢道路,通過存算一體、量子計算等突破算力瓶頸。
後摩智能的存算一體芯片H30,便是一道新的解題思路,也讓主機廠、Tier 1有了更多新選擇。

飆升的算力需求,
待打破的“存儲、功耗”牆
英偉達旗艦AI芯片H100,隨着AI生成式大模型受到廣泛關注,售價近期一度被炒到46000美金。
H100是英偉達於去年推出的一款全新架構的GPU芯片。
8塊H100,再加上4個NVLink可以組合一個DGX H100,AI算力高達32 PetaFlops。英偉達CEO黃仁勳稱,20塊H100就可以承載全球互聯網的流量。
熱衷自動駕駛的特斯拉CEO馬斯克,不久前購買了數千塊H100,笑稱“看起來每個人和他們的狗此時都在買GPU。”
H100大熱,體現了市場對於芯片算力需求飆升,時代進入了一個AI爆發的新階段。
不過,算力飆升後也讓大家看到了芯片面臨的瓶頸,即:存儲牆和功耗牆。
目前市面上的大多數芯片,均基於1945年提出的馮·諾依曼計算系統進行設計,計算和存儲功能分別由中央處理器和存儲器完成。
在這一架構中,每次計算需要先讀取內存的數據,計算後再存回內存,大部分過程都在讀取和存儲數據。
處理器的性能跟隨摩爾定律逐年提升,存儲器發展滯後。
隨着數據處理量增大,存儲速度跟不上數據處理速度,形成了“存儲牆”。數據在處理器和存儲器之間來回搬運,還造成了功耗損失,形成了“功耗牆”。
為了拆掉兩塊牆,芯片領域提出存算一體的新架構,直接利用存儲器進行數據處理,這種新架構具備大算力、低功耗、低延時等優點。
後摩智能創始人兼CEO吳強的偶像是Jim Keller,後者是操刀過特斯拉FSD芯片的大神。Jim Keller曾説過,“不滿於常規的改良,而是要做底層的重構和創新。”
因此,兩年前創立後摩智能時,吳強選擇了一個不依賴先進工藝,通過底層架構創新來實現AI計算效率的新方向。
這就有了後來的基於存算一體架構的鴻途™系列芯片。

面向智能駕駛,
H30已支持點雲、BEV網絡

“256TOPS是物理算力,不是市面上常説的稀疏虛擬算力。”吳強向大家介紹H30芯片時重點強調。
物理算力是指芯片的理論峯值算力。
有人將算法比作公式,將物理算力比作人的智商。從物理算力的維度,市面上已量產的國產智駕芯片,基本上都不如H30。
H30的能效比也非常高。
基於更為成熟的 SRAM 存儲介質,採用數字存算一體架構,H30在INT8 數據精度下AI 核心IPU 能效比高達 15 Tops/W,是傳統架構芯片的7 倍以上。
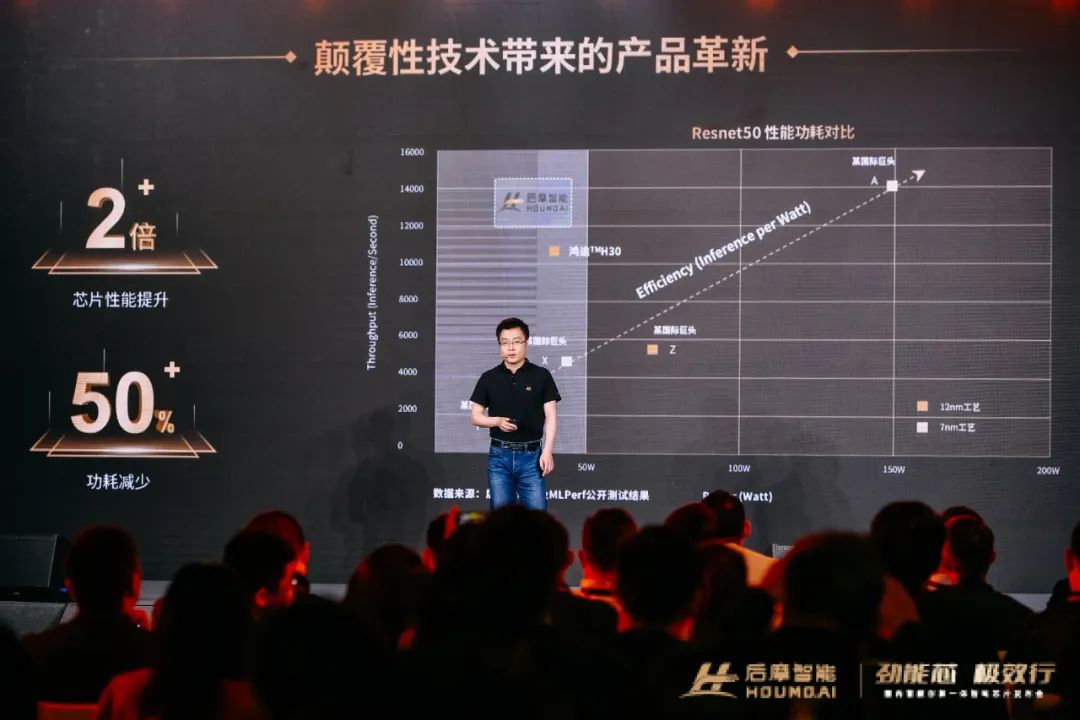
根據後摩實驗室及MLPerf公開測試結果,以經典的基礎網絡Resnet50為例,在 Batch Size 等於1 和 8 的條件下,分別達到了 8700 幀/秒和 10300 幀/秒的性能,是英偉達基於8nm芯片性能的5.7倍和2.3倍。
簡單來説,H30 在芯片性能提升2倍的同時,功耗減少了50%。
那麼,這塊芯片能做什麼?
後摩智能將第一款芯片產品的應用場景選在了智能駕駛領域。
吳強認為,智能駕駛芯片一定是要無限接近於人腦的計算方式和效率,而存算一體的價值正在於此,與智能駕駛的終局需求天然吻合。
作為一款面向智能駕駛的芯片,H30對於當下熱門的神經網絡均可以支持。而且,H30的架構專門針對智能駕駛場景,在低延時下性能可以更加充分地展現。
後摩智能表示,一些高階自動駕駛領域常用的經典CV網絡和自動駕駛網絡等,目前已經成功移植到H30上,比如點雲網絡、BEV網絡等。

此外,基於H30的智駕方案已經部署在後摩智能合作伙伴的無人小車上。比如,後摩智能與新石器無人車合作的無人駕駛解決方案,便是基於存算一體芯片。
基於H30,後摩智能還打造了力馭智能駕駛硬件平台,作為主機廠面向智能駕駛的參考設計和評估平台。

官方數據顯示,力馭的CPU算力為200Kdmips,AI算力達到256 TOPS(INT8物理算力)。
按照規劃,基於第一代產品H30的力馭計算平台將在今年6月向Alpha客户送測。第二代產品H50將於明年一季度回片,支持主機廠客户2025年的量產車型。

基於存算一體,變革底層架構

讓H30擁有如此成績的,是一套全新的架構。
主流芯片產品中,英偉達、高通、地平線等自動駕駛的芯片,基於馮·諾依曼架構,也就是存儲分離。
H30則基於存算一體,從架構上進行底層創新。
後摩智能聯合創始人兼研發副總裁陳亮總結,H30這款芯片實現了六項技術突破:
大算力、全精度、低功耗、車規級、可量產、通用性。
後摩智能自研了IPU處理器架構,第一代IPU天樞架構專為智能駕駛打造。
天樞架構的設計思路是,採用多核、多硬件線程的方式來靈活擴展算力,AI 計算可以在核內完成端到端處理,保證通用性。
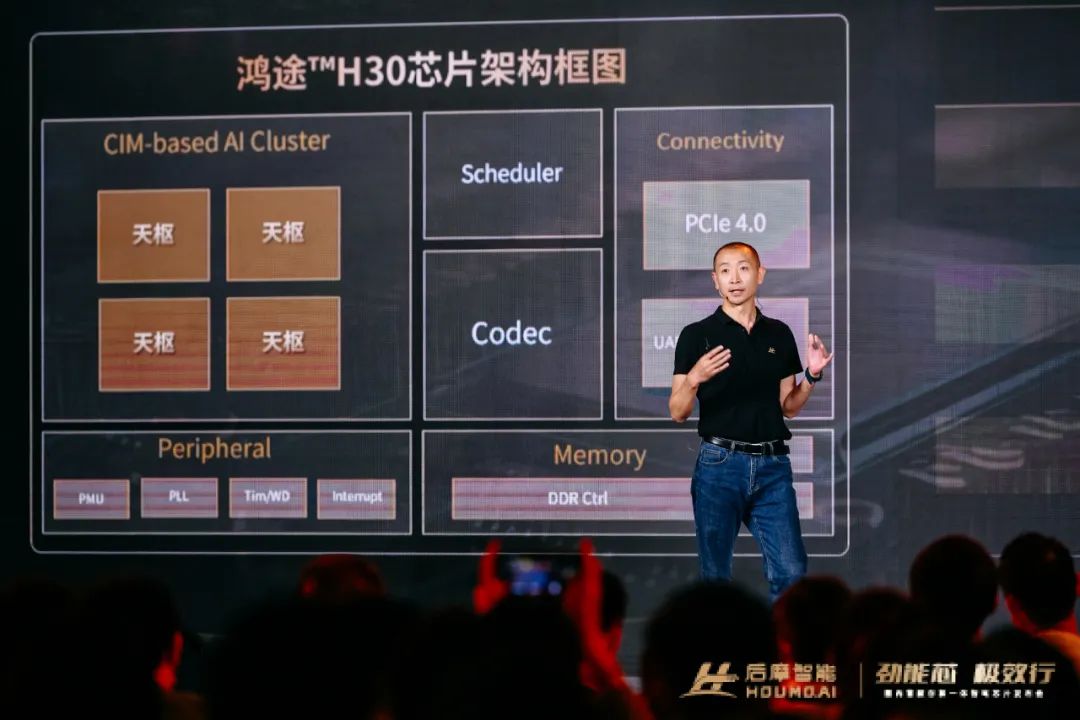
H30芯片裏面有4個IPU核,部署在系統總線NoC上。
每個IPU 核又由4個Tile組成,每個Tile對應一個硬件線程,既可以獨立進行不同任務的計算,又可以聯合進行同一個任務的計算。
每個Tile的內部,包含CPU、Tensor Engine、CIM、Feature Buffer、Special Function Unit、Vector Processor、DMA、Shared Memory&Controller。
其中,CPU可以調度這些執行單元,也可以做一些對算力要求不高的計算。
這些計算單元,還可以直接共享一個多Bank的共性存儲資源。
基於後摩的IPU架構,AI計算不需要在CPU、GPU、DSP等不同的處理器之間分配任務,而是可以在核內完成端到端的計算。
此外,後摩智能設計了專用的數據傳輸總線,搭配多通道,可以在4個Tile和各個IPU 核之間建立高速的數據傳輸通道。
為了發揮數據複用的特性,後摩智能還設計了多播的傳輸機制,一個Tile裏數據,可以通過一次DMA傳輸,廣播給其他多個Tile,從而不需要多個Tile多次讀取數據。
存算一體的架構,讓H30可以更好地計算與存儲,AI Core計算利用率達到80%以上。
最後,由於具備良好的擴展性,讓這款芯片有了更多想象空間。
據瞭解,後摩智能的下一代芯片,將支持擴展更多核,基於Mesh互聯結構,可以將計算單元靈活配置,實現算力規模的可大可小。
可以合理推測,後摩智能的下一代架構的芯片有望支持類似GPT的大模型,甚至有可能應用於更大算力的自動駕駛場景。
實際上,存算一體領域,不止有後摩智能一家,其它還包括知存科技、億鑄科技等,不同的是,後摩智能選擇了智能駕駛賽道作為落地。
隨着算力需求的爆發和更多芯片產品落地,存算一體正在獲得越來越多的認可。
總之,在降本增效的趨勢下,擁有成本優勢的存算一體智駕芯片,也讓主機廠在英偉達、地平線等芯片外,有了更多新的選擇。
退一步説,站在芯片安全的角度,存算一體智駕芯片可以與先進製程工藝解綁,也讓智能汽車被“卡脖子”的隱患得到了一定緩解。
