3納米,怎麼辦?_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。06-08 18:39
在對更小、能效更高的晶體管的不懈追求中,半導體行業遇到了更大的挑戰,最近的尖端工藝節點將這些挑戰推到了最前沿。台積電的最新節點是其 3 納米“N3”工藝技術系列。台積電最初計劃在 2022 年下半年量產,最終於2022年12月29日在其Fab 18舉行了 3 納米量產和產能擴張儀式。
正如我們在文章《台積電3nm細節全曝光,成本驚人》中詳述的那樣,台積電正在推出多種“3nm”版本。兩種主要類型是基本 N3 節點 (N3B) 和增強型 N3 節點 (N3E)。最近,在他們的 2023 年技術研討會上,該公司還宣佈了一些額外的衍生節點。然而,儘管它們的名字相似,但兩者並不相關,但遵循截然不同的設計規則。出於所有意圖和目的,我們將它們視為兩個獨立的血統。台積電還計劃稍後推出一些性能更高的 N3E 變體。
N3B
台積電首個3納米級工藝技術——N3B最近已經進入量產。儘管台積電延續了其最近的傳統,即披露了關於其工藝的極少實際細節,但這篇論文無疑比幾年前的 N5 論文要好。台積電在這裏透露,該節點具有 45 納米的接觸柵極間距,這是迄今為止所有代工廠報告的最窄間距。值得指出的是,從歷史上看,台積電在其標準單元實施中依賴稍微寬鬆一些的 CPP。這使得 N3B 在實際實施中與 CPP 的距離為 45-47 nm。
台積電在其 N3B 節點中引入的其中一件事是一種新的自對準接觸 (SAC:self-aligned contact) 方案。這讓我們感到驚訝,因為我們認為他們現在已經推出了它。相比之下,英特爾早在 2011 年就在其 22 納米工藝中引入了 SAC 以及其 FinFET 晶體管架構。三星也在其 7 納米系列中引入了 SAC。
工藝工程師在縮小晶體管時面臨的眾多挑戰之一是由於未對準造成的變化。在現代節點上,由於接觸着陸面積(contact landing area)較小,未對準的餘量會顯著下降,從而影響良率。除了觸點到柵極(contact-to-gate)短路之外,還會出現寄生電容和性能問題。為了緩解這個問題,台積電表示,對於他們的 N3B 及更高版本,他們必須引入 SAC。SAC嚴格來説是一種提高良率的流程,可防止柵極因前沿工藝節點中的緊密間距而發生接觸短路。
在 SAC 下,柵極通過柵極頂部的電介質硬掩模(dielectric hard mask)防止短路。它還允許觸點充分利用與墊片(spacers)相鄰的空間。最終產品是一個工藝流程,在工藝變化方面更加寬容。值得注意的是,由於在未對準的情況下接近接觸,該過程確實會導致電容惡化。

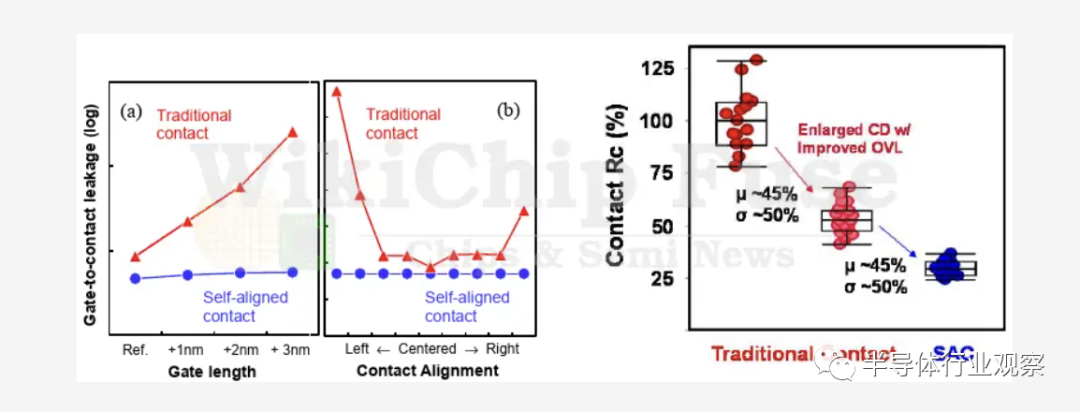
台積電還談到了間隔工程(spacer engineering)。隨着間隔物(spacer)厚度的增加和接觸距離的減小,接觸電阻急劇增加。因此,減小間隔物厚度對於將電阻保持在可接受的公差範圍內至關重要。它通過降低柵極電容到鰭片的源極/漏極區域並在頂部接觸來實現。雖然更需要更薄的間隔物,但它們難以實施,因為它會對器件的產量和可靠性產生不利影響(對於 FinFET 器件尤其如此)。
為此,台積電表示已確定並實施了適合量產的 K 值 < 4.0 的low-K 間隔器。在他們的 N3B 工藝中,台積電報告説,在通過 TDDB 規範的同時,與之前的間隔物實現相比,Vmax 提高了高達 230 mV。
同樣的測試芯片還集成了256 Mib的HC和HD SRAM宏。
N3E
N3E 節點是台積電計劃在今年下半年推出的一個完全不同的工藝節點,大約在 N3B 推出一年後。對於大多數客户來説,這將是真正N3 節點。這個節點的一切都與 N3B 不同。為此,N3E 節點提供了 48 納米的多晶硅間距(poly pitch)、26 納米的鰭狀間距( fin pitch)以及 23 納米的最小金屬間距(metal pitch)。這分別表示 0.94 倍和 0.93 倍的縮放比例。
為了促進 23 nm pitch的最小金屬間距,台積電表示它採用了“用於 Cu 的創新襯裏”(innovative liner for Cu),以便將標稱金屬寬度的 RC 降低 20%,對於 2 倍金屬寬度降低 RC 多達 30%。同樣,台積電表示,“創新的阻擋工藝”(innovative barrier process)被用來將 Via RC 減少多達 60%。相比之下,英特爾使用的是增強型銅 (eCu:enhanced Copper),它包含一個鉭阻擋層,鈷包層圍繞着一個純銅核心。
在具有更鬆弛間距(relaxed pitches)的上層金屬層,據説勢壘厚度(barrier thickness)已經減少,並且使用極低low-κ 電介質來最小化整體 BEOL RC 延遲。
簡要提到了一些額外的製程特徵。這是第 6 代high-K 替代金屬柵極工藝。台積電表示,對於這一製程,它已經改進了墊片工程(spacer engineering),這似乎與 N3B 所詳述的相似。台積電還提到使用帶有雙外延工藝的凸起源極/漏極,該工藝針對溝道應變進行了優化,以降低源極/漏極電阻。
台積電 N3E IEDM 論文的一大焦點是“FinFlex”(hybrid cells),該公司將其描述為“an innovative standard cell architecture with different fin configurations”。與往常一樣,台積電開發了三個主要的邏輯標準單元庫——短高度、中高度和分別包含 1、2 和 3 個鰭片高度單元的高標準單元庫。除了獨立的應用程序之外,FinFlex 還提供三種預定義的配置,將這些庫混合在一起以提供各種密度-性能權衡。在某種程度上,FinFlex 可以被認為是一個固定的雙高標準單元,但台積電確實以一種巧妙的方式將它們結合起來,以在需要的地方利用更高的性能,在性能不是必需的地方利用更高的密度。


綜合起來,N3E 單元高度基於 26 納米擴散線(diffusion lines)。因此,對於 48 納米 CPP 的 1、2 和 3 fin cell,我們有 4.5、5.5 和 6.5 擴散線高度,在 54 納米 CPP 上有 6.5、7.5 和 8.5 線高。這轉化為 48 nm CPP 處的 143 納米高密度單元高度和 54 nm CPP 處的 195 納米高密度單元高度。

在 48 納米 CPP 下,143 納米 HD 單元的晶體管密度約為 215.6 MTr/mm²。

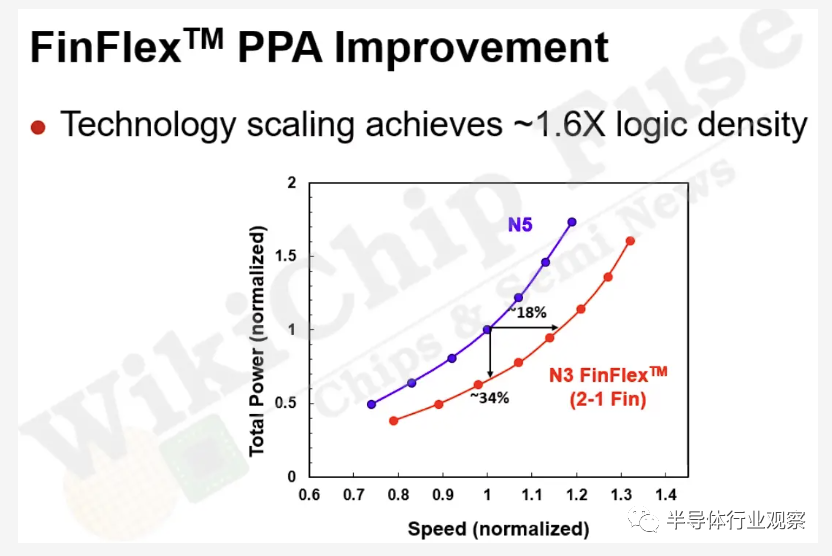
在 2-2、2-1 和 2-3 的上下文中,密度將根據所選配置計算為這些密度的平均值。在 PPA 方面,據説與 2-2 配置相比,3-2 配置比 N5 2-fin 提供 10% 的額外性能,同時面積減少為 2-2 配置的一半。同樣,據説 2-1 配置與 N5 2 fin相比,2-2 配置的面積減少了 8%,同時性能提高了一半。
靜態隨機存取存儲器
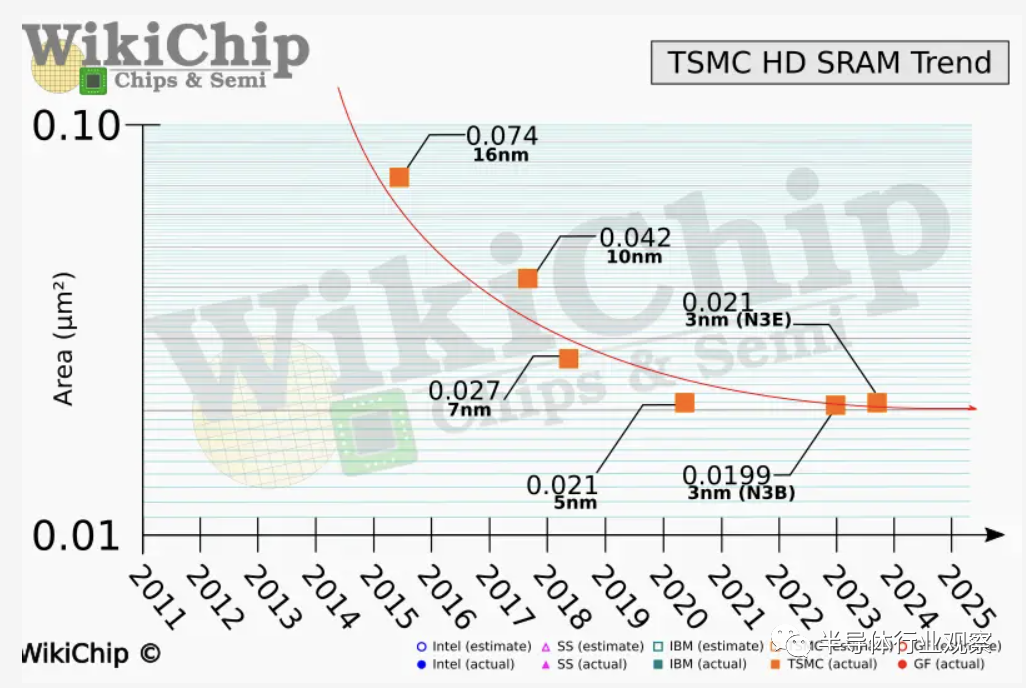
密度故事中一個有趣的轉折點是 SRAM。我們在之前分享了一篇關於SRAM 縮減終止的文章《我們將見證SRAM的死亡》。這裏的底線是 SRAM 並沒有在 3 納米上縮小,同時它在絕對面積和總晶體管計數比率方面都佔了芯片的更大部分。SRAM 是芯片設計人員用來提高性能的一個非常重要的槓桿,主要是通過緩存。
當台積電首次宣佈 N3E 時,它忽略了 SRAM 密度的改進。我們現在知道 N3E SRAM 位單元與 N5 相同。這對芯片設計師來説是一場災難。N3B 的表現也好不到哪兒去。台積電最初透露,N3B SRAM 密度是 N5 的 1.2 倍。IEDM 最近的一項披露顯示,它實際上只增加了 5% 的密度。N3B 顯着更高的價格很難證明增加的密度和 SRAM 改進很少。
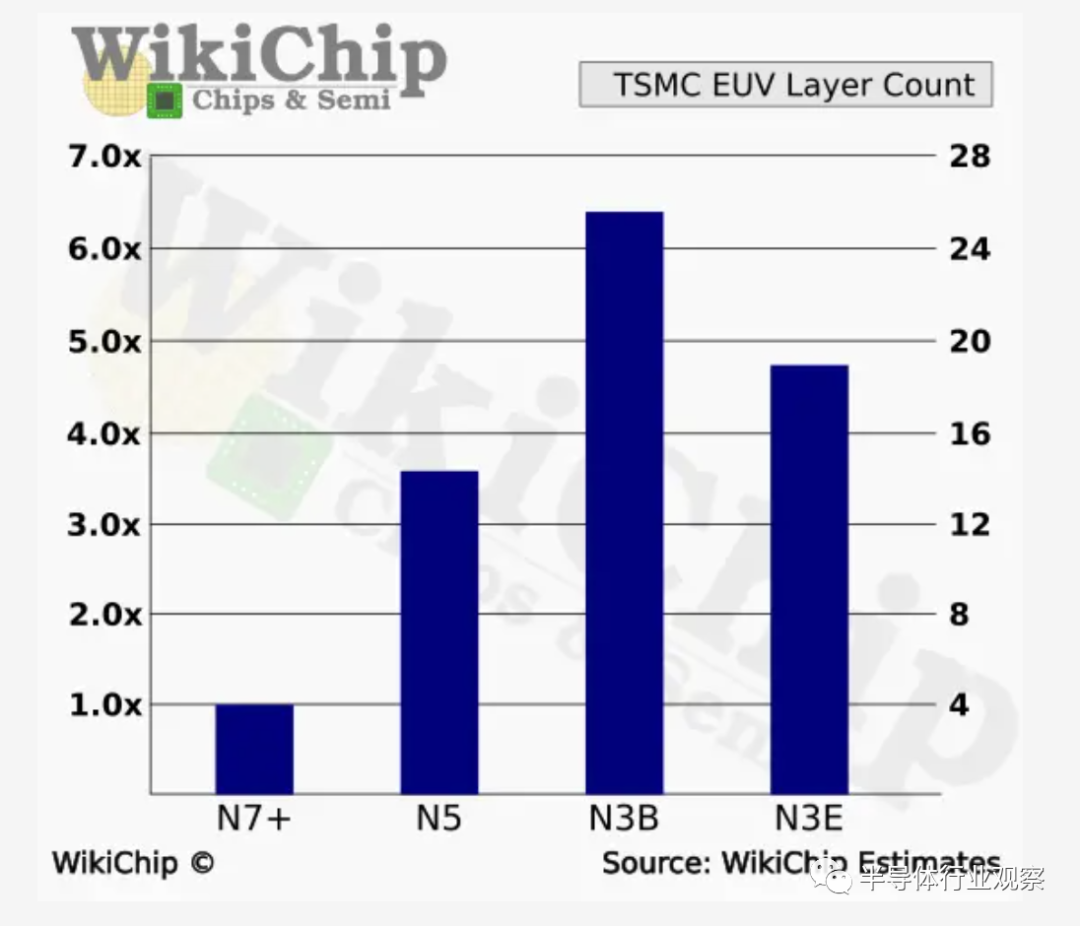
最近的工藝節點變得越來越複雜,有上千個步驟。除了一絲不苟的執行,流程設計本身還需要仔細考慮風險與回報的計算。N3B 顯然旨在成為 N5 的重大進步;然而,這一進步是以相當大的代價和上市時間延長為代價的。在光刻層面,我們估計 N3B 已將 EUV 層數增加到 25。這代表了近 80% 的驚人增長。這意味着曝光量、光刻總週期時間和最終成本增加了 80%。值得注意的是,N5 本身的 EUV 層數是 N7+ 的三倍。顯然,即使對於另一個節點,這種趨勢也不可持續。
N3B 還引入了SAC。這對我來説真的很奇怪,特別是因為它不存在於 N3E 中。這意味着觸點最初可能是雙重圖案化——表明 N3B 可能超過 26 個 EUV 層——但在 SAC 啓用下減少到 25 個。更寬鬆的 N3E 間距可能讓他們在沒有 SAC 的情況下逃脱,從而進一步降低成本。N2 將來肯定會使用 SAC。
N3E 在扭轉 N3B 成本方面邁出了一大步。台積電表示,以前需要雙重圖案化的三個關鍵層被單一 EUV 圖案化所取代。我們認為這意味着總共消除了 6 條線和過孔層曝光。這使得估計的層數為 19。這表明 N3E 的內在成本增加了 36%,這是更容易接受的。