大模型們參加2023高考了,成績單已出爐_風聞
量子位-量子位官方账号-06-28 21:29
轉載自 智源研究院
量子位 | 公眾號 QbitAI
2023 年高考成績陸續出爐,我們也來看看各大語言模型的“高考成績”如何?

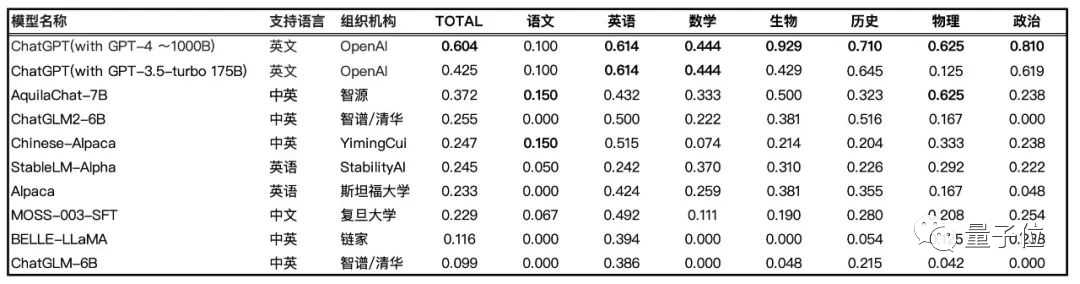
FlagEval 大模型評測團隊從 2023年高考考卷中整理了 147 道客觀題(其中語文 20道,英語 44道,歷史 31道,數學 9道,物理 8道,政治 21道,生物 14道)形成 Gaokao2023 V1.0 評測集。
排除特殊符號等因素之後,通過 5-shot 方式對參數量相近的開源大語言模型進行評測,如悟道·天鷹 AquilaChat、Alpaca、Chinese-Alpaca、StableLM-tuned-alpha、MOSS、BELLE、ChatGLM等。
鑑於 2023 高考題 6 月初才發佈,尚未進入模型訓練數據集,此次測試結果能較為直接地反映模型的知識運用能力。
ChatGPT 毫無懸念得分最高,GPT-4 和 GPT-3.5-turbo 正確率分別為 60.4%、42.5%。
悟道·天鷹 AquilaChat-7B 在國內外參數量相近的SFT開源模型中表現亮眼,以 37.2% 正確率的綜合成績位居首位,接近 GPT-3.5-turbo 水平。
而 ChatGLM2-6B、Chinese-Alpaca 緊隨其後,正確率分別為 25.5%、24.7%。
經SFT微調的模型與基礎模型在能力側重點上具有明顯差異。
公平起見,僅對比經SFT微調後的語言模型。
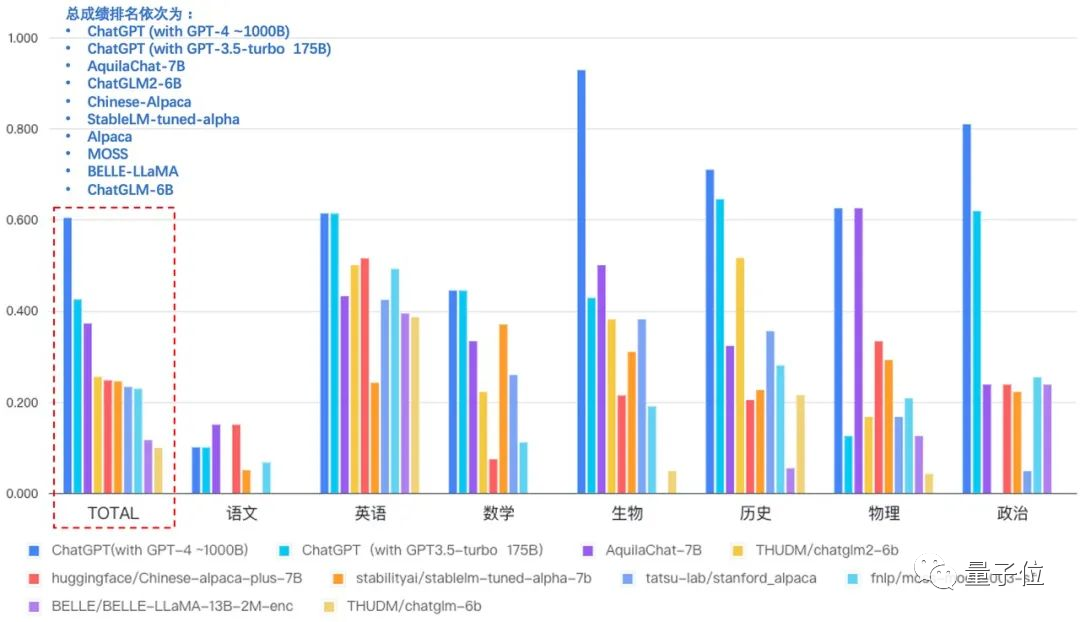
評測方式解釋:
本次評測採用 5-shot 的 In-context 形式 prompt 作為輸入,即在 Prompt 中給給出 5 個示例和答案作為 Context,最後附上一道評測題目,要求模型選擇輸出【A/B/C/D】中的正確選項,考察模型的 In-Context(上下文)學習能力和知識量。總成績(TOTAL)為每個模型的 7 個學科成績算數平均值。
從學科成績中,還有幾點有趣的發現:
AquilaChat 學科知識非常均衡,沒有明顯的短板,並且生物、物理成績突出,正確率分別達到 50%、62.5%;
相比英語成績,所有模型的語文成績普遍不高,AquilaChat 與 Chinese-Alpaca 以 15% 正確率並列第一,ChatGPT 的正確率也僅有 10% 。説明大模型在學習中文知識時難度較大,這對後續中英雙語大模型訓練提出了挑戰。
這次針對2023高考的能力評測,主要對國內外7B量級開源大模型進行對比。7B 量級作為當前主流模型,因部署性價比高,廣受產業歡迎。
“巨無霸”ChatGPT作為標誌參照項,在“高考2023評測”等能力對比中依然“一覽眾山小”。
考慮到其在模型參數量、訓練數據量方面的巨大差異,以 AquilaChat-7B 為代表的 7B 量級開源模型,依然實力不容小覷、未來可期!
目前尚未有公開信息
FlagEval 大語言模型評測榜單上新
Gaokao2023 V1.0(高考評測結果)已更新至 FlagEval 大語言模型評測榜單。我們將持續擴充題庫能力,提升對模型評測結果的深入分析能力。
歡迎大模型研究團隊評測申請:
flageval.baai.ac.cn
智源FlagEval大模型開放評測平台,創新構建了“能力-任務-指標”三維評測框架,劃定了大語言模型的 30+ 能力維度,在任務維度集成了 20+ 個主客觀評測數據集,不僅涵蓋了知名的公開數據集 HellaSwag、MMLU、C-Eval 等,還增加了智源自建的主觀評測數據集 Chinese Linguistics & Cognition Challenge (CLCC) ,北京大學與閩江學院共建的詞彙級別語義關係判斷、句子級別語義關係判斷、多義詞理解、修辭手法判斷評測數據集。更多維度的評測數據集也在陸續集成中。
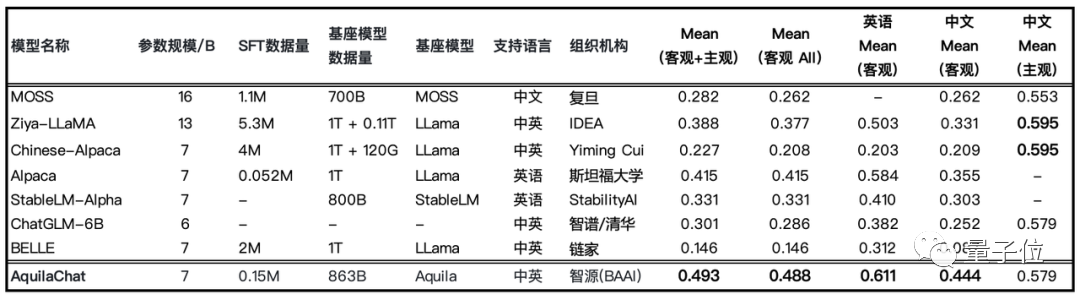
在最新 SFT 模型評測榜單中,AquilaChat 在“主觀+客觀”評測中排名第一。
據悉,悟道 · 天鷹 Aquila-7B基座模型及AquilaChat 對話模型最新版本權重已經更新至開源倉庫,相比 6 月 9 日初始版本性能在常識推理、代碼生成等維度,有了較高提升。目前可通過 FlagAI 開源項目或 FlagOpen 模型倉庫下載權重。
GitHub:
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
模型倉庫:
https://model.baai.ac.cn/models