企業級推動 DataBricks 和 MosaicML的13億美金 AI 交易_風聞
BImpact-宇婷,To B行业观察者、资深媒体人、博主。-06-28 20:17
撰文|宇婷

Databricks已同意以13億美元收購生成式AI創企MoaicML 。此前MoaicML融資6400萬美元,擁有62名員工,在上一輪的融資中,公司估值為2.2億美元,而本次收購中MosaicML的估值直接提高近6倍。
MosaicML在生成AI軟件基礎架構、模型訓練和模型部署方面擁有專業知識,加上Databricks的客户覆蓋範圍和工程能力,以及對於打破大模型壟斷的價值觀,和研究者出身的創業家團隊,成為13億 交易的基礎。
生成AI正處於一個關鍵時期。未來主要依靠少數人擁有的大型通用模型,還是見證由世界各地的開發人員和公司構建自定義的模型?這是 DataBricks 對 MosaicML 收購之外的未解答案。
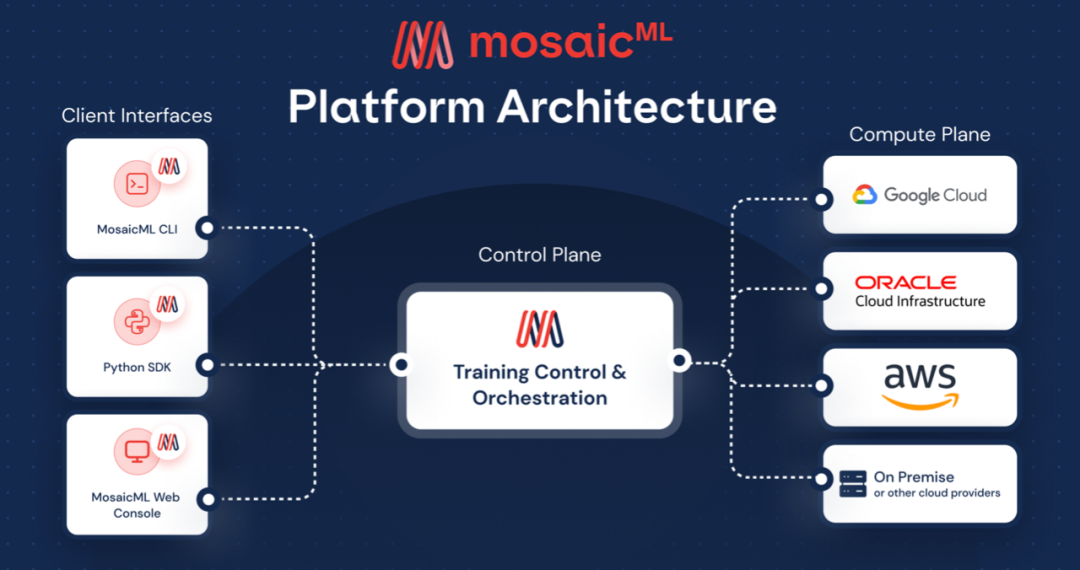
在安全環境中,在任何雲上能夠構建AI模型,這也是這筆交易成立的關鍵。MosaicML 平台的架構能夠讓企業級客户在任何雲提供商上訓練大規模的AI模型,同時數據仍然安全地存儲在企業自己的私有網絡中。
初創企業和大型企業都可以在訓練模型和工作負載時保持最大的自主性。
對於擔心數據隱私和安全的組織來説,將企業的數據發送到不一定可靠的第三方API,儘管大型語言模型(LLMs)和其他先進的AI可以帶來豐厚的商業機會,一些企業級客户仍然會有所踟躕。
MosaicML 使企業及廠商能夠使用自定義數據進行預訓練、微調和部署模型,全部在企業的內部完成。
在完全擁有模型所有權和數據隱私的情況下,金融服務和醫療保健等受監管的行業可以利用自定義大型語言模型(LLMs)的全部能力來處理業務用例,而不會依賴不可靠的第三方API。
MosaicML平台是現代ML研究不可或缺的工具,它在規模基礎設施的複雜性方面進行了抽象,這使得企業能夠開發針對性屬於自己的AI應用之路,在加速模型研發和節省成本的情況下大步開拓。
1、和Databricks的共同審美:研究員轉型為企業家,打破AI通用模型的壟斷
美國時間6月26日,MosaicML宣佈加入Databricks,以進一步實現讓任何組織能夠自定義AI模型開發的目標。
主創團隊表達,創建MosaicML是為了普惠每一個工程師能夠享受大規模神經網絡訓練和推斷技術。隨着生成AI浪潮,這一使命更加確定,而且絕不是把這種能力集中在少數通用模型廠商手中中。
Ali、Patrick和其他Databricks聯合創始人接觸到 MosaicML 尋求合作時,MosaicML 立即認識到他們是志同道合的人:研究員轉型為企業家,共享相似的使命。他們強大的公司文化和工程重點反映了我們認為成熟的 MosaicML 將是什麼樣子。
這筆交易將受到某些慣例的關閉條件和監管審批的限制,直到這些審查完成,公司將保持獨立,MosaicML 主創團隊表達對與 Databricks 一起所能做的事情感到興奮。
MosaicML 旗艦產品將繼續銷售。對於當前的客户和那些在等待列表上的客户:這種合作會更快地為客户提供服務。MosaicML的訓練、推斷和MPT家族基礎模型,已經為全球企業和開發人員提供生成AI支持。
對於Databricks而言, MosaicML在生成AI軟件基礎架構、模型訓練和模型部署方面的專業知識,加上Databricks的客户覆蓋範圍和工程能力,將使雙方平衡彼此的優勢。
MosaicML 的董事會成員Matt Ocko在DCVC,Shahin Farshchi在Lux Capital,Peter Barrett在Playground Global,等投資者支持了這筆交易。
2、MPT-30B:提高開源基礎模型的標準
MPT-30B,這是MosaicML 開源模型Foundations Series中更為強大的新成員,使用H100s上的8k上下文長度進行訓練。
今年5月推出MPT-7B以來,ML社區熱切地擁抱了開源的MosaicML Foundation Series模型。MPT-7B基礎版,-Instruct,-Chat和-StoryWriter模型一共被下載了超過300萬次。
以下是其中的幾個:LLaVA-MPT為MPT添加了視覺理解,GGML在Apple Silicon和CPU上優化了MPT,而GPT4All則使用MPT作為後端模型,在筆記本電腦上運行類似於GPT4的聊天機器人。
MosaicML Foundation Series的MPT-30B,這是一個新的、授權商用的開源模型,比MPT-7B更強大,並且勝過了原始的GPT-3。
此外,MosaicML 還發布了兩個經過微調的變體,MPT-30B-Instruct和MPT-30B-Chat,它們是基於MPT-30B構建的,分別擅長單輪指令跟隨和多輪對話。
所有MPT-30B模型都具有特殊功能,使它們與其他LLM不同,包括訓練時的8k令牌上下文窗口,通過ALiBi支持更長的上下文,以及通過FlashAttention實現高效的推理和訓練性能。
MPT-30B家族還具有強大的編碼能力。該模型在NVIDIA H100s上擴展到了8k上下文窗口,這使它成為(據目前所知)第一個在H100s上訓練的LLM。
有幾種方法可以使用MosaicML平台進行自定義和部署。
*MosaicML訓練通過微調、領域特定的預訓練或從頭開始訓練,使用私有數據自定義MPT-30B。企業始終擁有最終的模型權重,並且數據永遠不會存儲在 MosaicML 的平台上。按每GPU分鐘計費。
*MosaicML推理:入門版。使用Python API,通過標準定價每1K個令牌,與託管的MPT-30B-Instruct(和MPT-7B-Instruct)端點交流。
*MosaicML推理:企業版。使用優化推理堆棧,在MosaicML計算或您自己的私有VPC上部署自定義MPT-30B模型。按每GPU分鐘計費,支付使用的計算費用即可。
