人紅是非多:大模型“犯法”,OpenAI大模型再再再再遭起訴_風聞
谭婧在充电-谭婧在充电官方账号-偏爱人工智能(数据、算法、算力、场景)。-06-29 15:42
原創:親愛的數據
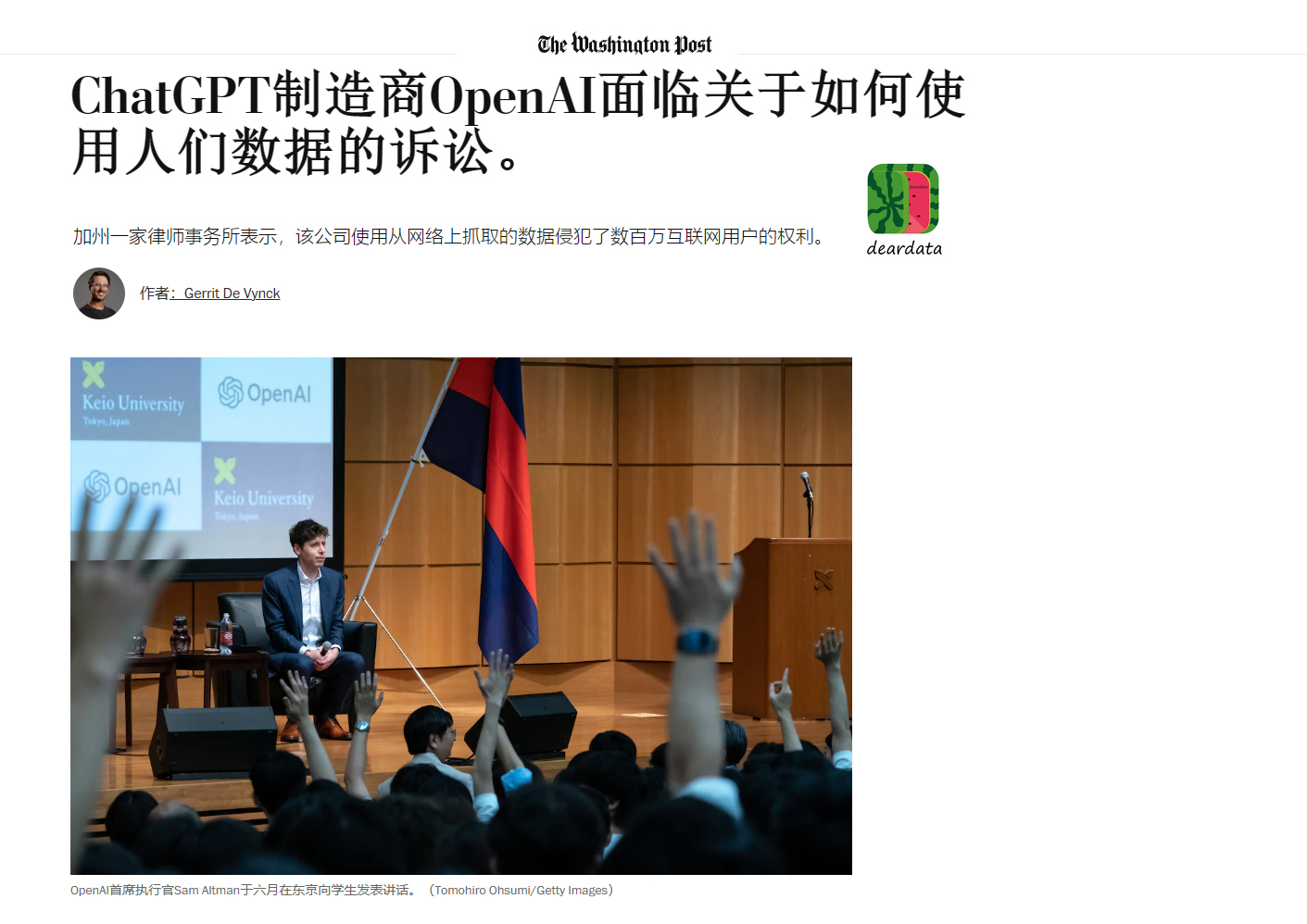
OpenAI正面臨集體訴訟,指控該公司使用網絡抓取來訓練其人工智能模型。原話是:以“前所未有的規模”盜用個人數據。
該訴訟稱,OpenAI在使用從互聯網上抓取的數據來訓練其技術時侵犯了無數人的版權和隱私。該訴訟導致參與人工智能技術開發的公司面臨越來越多的法律糾紛。
OpenAI,Microsoft和GitHub也在集體訴訟中被點名,聲稱他們的AI代碼生成軟件Copilot違反了版權法。
訴訟已經不是第一次,甚至國外有版權網站專門整理了訴訟清單。

這次的具體細節是:
一家總部位於美國加利福尼亞州的律師事務所,正在對OpenAI提起集體訴訟,指控創建流行聊天機器人ChatGPT的人工智能公司使用從互聯網上抓取的數據來訓練其技術時,大規模侵犯了無數人的版權和隱私。
“大規模”是肯定的,因為用的是“大數據”。
維基百科文章和家庭食譜博客版權都被侵犯了,這起訴訟背後的律師事務所克拉克森此前曾就從數據泄露到虛假廣告等問題提起大規模集體訴訟。
該公司希望代表“信息被盜和商業盜用的真實人物,以創造這種非常強大的技術,”該公司的管理合夥人瑞安克拉克森説。
該案於週三上午在加利福尼亞州北區的聯邦法院提起。OpenAI的發言人沒有回應置評請求。
這起訴訟觸及了一個懸而未決的重大問題的核心,這個問題懸而未決。

在消耗足夠的數據後,由此產生的“大型語言模型”可以預測在響應提示時該説什麼,使他們能夠寫詩,進行復雜的對話並通過專業考試。但是,寫下數十億字的人從未同意讓像OpenAI這樣的公司利用它們來牟利。
“所有這些信息都是大規模獲取的,數據所有者從未同意被大型語言模型利用,”克拉克森説。
不愧是集體訴訟,該公司已經有一羣原告,並正在積極尋找更多原告。
不過集體訴訟的難度大,訴訟週期長。也就是我們常説的維權成本高。
使用從公共互聯網中提取的數據來訓練可能對開發人員來説非常有利可圖的工具的合法性尚不清楚。一些人工智能開發人員認為,使用來自互聯網的數據應被視為“合理使用”,這是版權法中的一個概念,如果材料以“變革性”方式進行更改,則會產生例外。
“變革性”能將大模型免責嗎?

藝術家和其他創意專業人士可以證明他們的版權作品被用來訓練人工智能模型,可能會反對使用它的公司,但那些只是在網站上發佈或評論的人不太可能贏得賠償。
“當你把內容放在社交媒體網站或任何網站上時,你通常會向網站授予非常廣泛的許可,以便能夠以任何方式使用你的內容,”加德納説。
“對於普通最終用户來説,很難聲稱他們有權獲得任何形式的付款或補償。畢竟,作為大模型訓練的一部分數據是使用別人的數據。
該訴訟還增加了越來越多的法律挑戰,這些公司正在建設並希望從人工智能技術中獲利。11月,針對OpenAI提起了集體訴訟,Microsoft這些公司如何使用Microsoft擁有的在線編碼平台GitHub中的計算機代碼來訓練AI工具。
今年2月,Getty Images起訴了規模較小的人工智能初創公司Stability AI,指控該公司非法使用其照片來訓練其圖像生成機器人。本月,OpenAI被美國佐治亞州的一位電台主持人起訴誹謗,他説ChatGPT製作的文字錯誤地指控他欺詐。
OpenAI並不是唯一一家使用從開放互聯網上抓取的大量數據來訓練其AI模型的公司。谷歌、Facebook、Microsoft和越來越多的其他公司都在做同樣的事情。 但克拉克森決定追隨OpenAI,因為它在去年通過ChatGPT吸引公眾的想象力時,在刺激其更大的競爭對手推出自己的人工智能方面發揮了作用,克拉克森説。
“他們是點燃這場人工智能軍備競賽的公司,”他説。“他們是自然的第一個目標。
OpenAI沒有分享其最新型號GPT4的數據類型,但該技術的先前版本已被證明已經消化了維基百科頁面,新聞文章和社交媒體評論。谷歌和其他公司的聊天機器人也使用了類似的數據集。
美國監管機構正在討論制定新的法律,要求公司提高透明度,説明哪些數據進入了他們的人工智能。法庭案件也有可能促使法官迫使像OpenAI這樣的公司交出有關其使用哪些數據的信息,知識產權律師加德納説。
一些公司試圖阻止人工智能公司抓取他們的數據。據英國《金融時報》報道,今年4月,音樂發行商環球音樂集團要求蘋果和Spotify封鎖。社交媒體網站Reddit正在關閉對其數據流的訪問,理由是大型科技公司多年來如何抓取其網站上的評論和對話。
Twitter老闆埃隆·馬斯克(Elon Musk)威脅要起訴Microsoft使用從該公司獲得的Twitter數據來訓練其人工智能。不過,馬斯克正在建立自己的人工智能公司。
針對OpenAI的新集體訴訟在其指控中更進一步,認為該公司對註冊使用其工具的人不夠透明,以至於他們放入模型中的數據可能用於訓練公司將從中賺錢的新產品,例如其插件工具。
訴訟還聲稱OpenAI在確保13歲以下的兒童不使用其工具方面做得不夠,多年來包括Facebook和YouTube在內的其他科技公司一直被指責。確實如此,親愛的數據此前翻譯過這類報道。
有網友認為,
1.大模型活該,確實用了很多別人的隱私和數據,
2.美國會率先打這種官司。
親愛的數據認為,美國的此類案件,對我國極有啓示意義,一方面,對於數據所有方,企業,個人如何防範和保障自己的利益,另一方面,對於大模型製造商應該如何避免犯法。
如果需要全文157頁的訴訟全文PDF,歡迎聯繫我們。
One More Thing:好書推薦

