CPU、GPU與算存互連的複雜比較與重要性分析之二_風聞
蓝海大脑GPU服务器-水冷服务器、大数据一体机、图数据一体机07-06 11:29
**算力互連:**由內及外,由小漸大
隨着"東數西算"工程的推進,出現了細分場景如"東數西渲"和"東數西訓"。視頻渲染和人工智能(AI)/機器學習(ML)的訓練任務本質上都是離線計算或批處理,可以在"東數西存"的基礎上進行。即原始素材或歷史數據傳輸到西部地區的數據中心後,在該地區獨立完成計算過程,與東部地區的數據中心交互較少,因此不會受到跨地域時延的影響。換句話説,“東數西渲"和"東數西訓"的業務邏輯成立是因為計算與存儲仍然就近耦合,不需要面對跨地域的"存算分離"挑戰。
在服務器內部,CPU和GPU之間存在類似但不同的關係。對於當前熱門的大模型來説,對計算性能和內存容量都有很高的要求。然而,CPU和GPU之間存在一種"錯配"現象:GPU的AI算力明顯高於CPU,但直接的內存(顯存)容量通常不超過100GB,與CPU的TB級內存容量相比相差一個數量級。幸運的是CPU和GPU之間的距離可以縮短,帶寬可以提升。通過消除互連瓶頸,可以大大減少不必要的數據移動,提高GPU的利用率。
一、為GPU而生的CPU
NVIDIA Grace CPU的核心基於Arm Neoverse V2架構,其互連架構SCF(可擴展一致性結構)可以看作是定製版的Arm CMN-700網格。然而在外部I/O方面,NVIDIA Grace CPU與其他Arm和x86服務器有很大不同,這體現NVIDIA開發這款CPU的主要意圖,即為需要高速訪問大內存的GPU提供服務。
在內存方面,Grace CPU具有16個LPDDR5X內存控制器,這些內存控制器對應着封裝在一起的8個LPDDR5X芯片,總容量為512GB。經過ECC開銷後,可用容量為480GB。因此可以推斷有一個內存控制器及其對應的LPDDR5X內存die用於ECC。根據NVIDIA官方資料,與512GB內存容量同時出現的內存帶寬參數是546GB/s而與480GB(帶ECC)同時出現的是約500GB/s,實際的內存帶寬應該在512GB/s左右。
PCIe控制器是必不可少的Arm CPU的慣例是將部分PCIe通道與CCIX複用,但這樣的CCIX互連帶寬相對較弱,不如英特爾專用於CPU間互連的QPI/UPI。
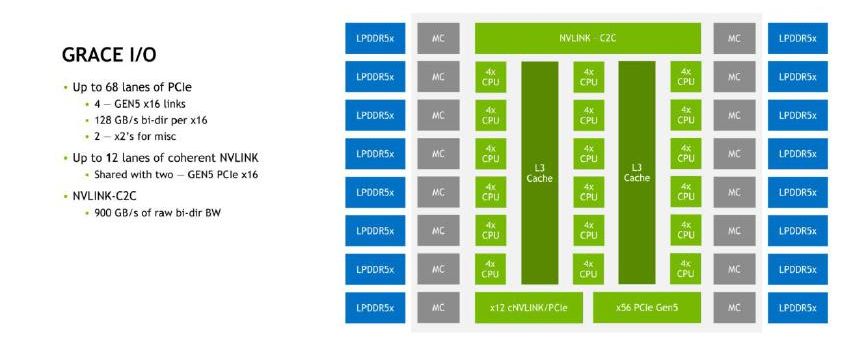
NVIDIA Grace CPU提供68個PCIe 5.0通道,其中有2個x16通道可以用作12通道一致性NVLink(cNVLINK)。真正用於芯片(CPU/GPU)之間互連的是cNVLINK/PCIe隔"核"相望的NVLink-C2C接口,其帶寬高達900GB/s。
NVLink-C2C中的C2C代表芯片到芯片之間的連接。根據NVIDIA在ISSCC 2023論文中的描述,NVLink-C2C由10組連接組成(每組9對信號和1對時鐘),採用NRZ調製,工作頻率為20GHz,總帶寬為900GB/s。每個封裝內的傳輸距離為30mm,PCB上的傳輸距離為60mm。對於NVIDIA Grace CPU超級芯片,使用NVLink-C2C連接兩個CPU可以構成一個144核的模塊;而對於NVIDIA Grace Hopper超級芯片,即將Grace CPU和Hopper GPU進行互聯。
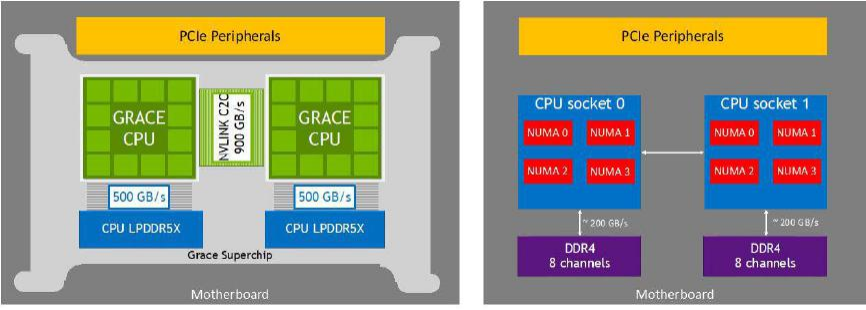
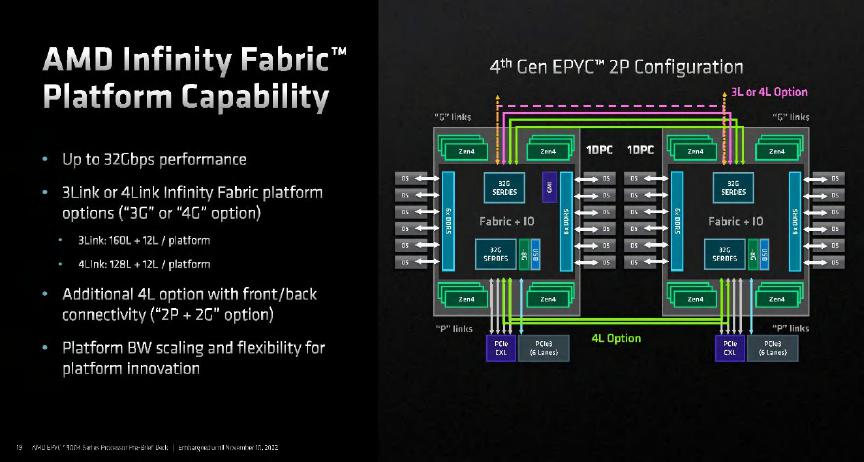
NVLink-C2C的900GB/s帶寬是非常驚人的數據。作為參考,Intel代號為Sapphire Rapids的第四代至強可擴展處理器包含3或4組x24 UPI 2.0(@16GT/s)多個處理器之間的總帶寬接近200GB/s;而AMD第四代EPYC處理器使用的GMI3接口用於CCD與IOD之間的互聯帶寬為36GB/s,而CPU之間的Infinity Fabric相當於16通道PCIe 5.0,帶寬為32GB/s。在雙路EPYC 9004之間可以選擇使用3或4組Infinity Fabric互聯,4組的總帶寬為128GB/s。
通過巨大的帶寬,兩顆Grace CPU可以被緊密聯繫在一起,其"緊密"程度遠超傳統的多路處理器系統,已經足以與基於有機載板的大多數芯片封裝方案(2D封裝)相匹敵。要超越這個帶寬,需要引入硅中介層(2.5D封裝)的技術。例如,蘋果M1 Ultra的Ultra Fusion架構利用硅中介層連接兩顆M1 Max芯粒。蘋果聲稱Ultra Fusion可以同時傳輸超過10,000個信號,實現高達2.5TB/s的低延遲處理器互聯帶寬。Intel的EMIB也是一種2.5D封裝技術,其芯粒間的互聯帶寬也應當達到TB級別。
NVLink-C2C的另一個重要應用案例是GH200 Grace Hopper超級芯片,它將一顆Grace CPU與一顆Hopper GPU進行互聯。Grace Hopper是世界上第一位著名的女性程序員,也是"bug"術語的發明者。因此,NVIDIA將這一代CPU和GPU分別命名為Grace和Hopper,這個命名實際上有着深刻的意義,充分説明在早期規劃中,它們就是緊密結合的關係。
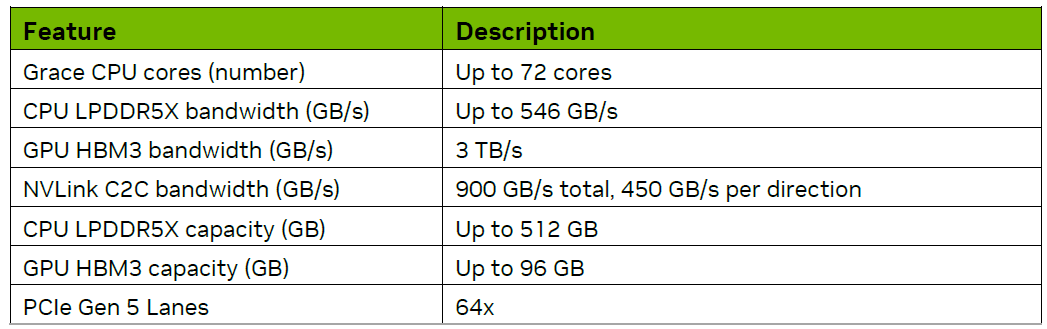
NVIDIA Grace Hopper 超級芯片主要規格
CPU和GPU之間的數據交換效率(帶寬、延遲)在超大機器學習模型時代尤為重要。NVIDIA為Hopper GPU配備了大容量高速顯存,全開啓6組顯存控制器,容量達到96GB,帶寬達到3TB/s。
相比之下,獨立的GPU卡H100的顯存配置為80GB,而H100 NVL的雙卡組合則為188GB。Grace CPU搭載了480GB的LPDDR5X內存,帶寬略超過500GB/s。儘管Grace的內存帶寬與使用DDR5內存的競品相當,但CPU與GPU之間的互連才是決定性因素。典型的x86 CPU只能通過PCIe與GPU通信而NVLink-C2C的帶寬遠超PCIe並具有緩存一致性的優勢。
通過NVLink-C2C Hopper GPU可以順暢地訪問CPU內存超過H100 PCIe和H100 SXM。此外,高帶寬的直接尋址還可以轉化為容量優勢,使Hopper GPU能夠尋址576GB的本地內存。
CPU擁有的內存容量是GPU無法比擬的,而GPU到CPU之間的互連(PCIe)是瓶頸。NVLink-C2C的帶寬和能效比優勢是GH200 Grace Hopper超級芯片相對於x86+GPU方案的核心優勢之一。NVLink-C2C每傳輸1比特數據僅消耗1.3皮焦耳能量大約是PCIe 5.0的五分之一具有25倍的能效差異。需要注意的是這種比較並不完全公平,因為PCIe是板間通信,與NVLink-C2C的傳輸距離有本質區別。
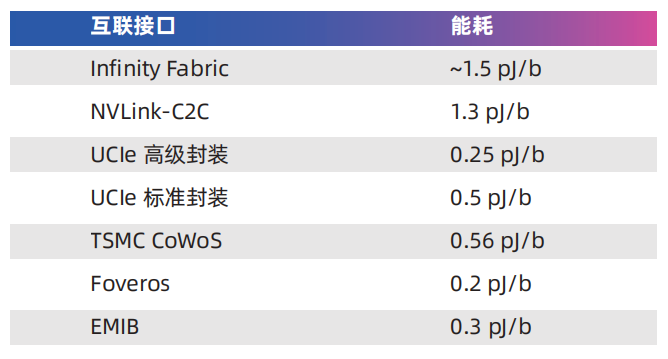
NVLink最初是為了實現高速GPU之間的數據交換而設計的,通過NVSwitch的幫助,可以將服務器內部的多個GPU連接在一起,形成一個容量成倍增加的顯存池。
二、NVLink 之 GPU 互連
NVLink的目標是突破PCIe接口的帶寬瓶頸,提高GPU之間交換數據的效率。2016年發佈的P100搭載了第一代NVLink,提供160GB/s的帶寬,相當於當時PCIe 3.0 x16帶寬的5倍。V100搭載的NVLink2將帶寬提升到300GB/s 接近PCIe 4.0 x16的5倍。A100搭載了NVLink3帶寬為600GB/s。
H100搭載的是NVLink4,相對於NVLink3,NVLink4不僅增加了鏈接數量,內涵也有比較重大的變化。NVLink3中,每個鏈接通道使用4個50Gb/s差分對,每通道單向25GB/s,雙向50GB/s。A100使用12個NVLink3鏈接,總共構成了600GB/s的帶寬。NVLink4則改為每鏈接通道使用2個100Gb/s差分對,每通道雙向帶寬依舊為50GB/s,但線路數量減少了。
在H100上可以提供18個NVLink4鏈接總共900GB/s帶寬。NVIDIA的GPU大多提供NVLink接口,其中PCIe版本可以通過NVLink Bridge互聯,但規模有限。更大規模的互聯還是得通過主板/基板上的NVLink進行組織,與之對應的GPU有NVIDIA私有的規格SXM。
SXM規格的NVIDIA GPU主要應用於數據中心場景其基本形態為長方形,正面看不到金手指屬於一種mezzanine卡,採用類似CPU插座的水平安裝方式"扣"在主板上,通常是4-GPU或8-GPU一組。其中4-GPU的系統可以不通過NVSwitch即可彼此直連,而8-GPU系統需要使用NVSwitch。
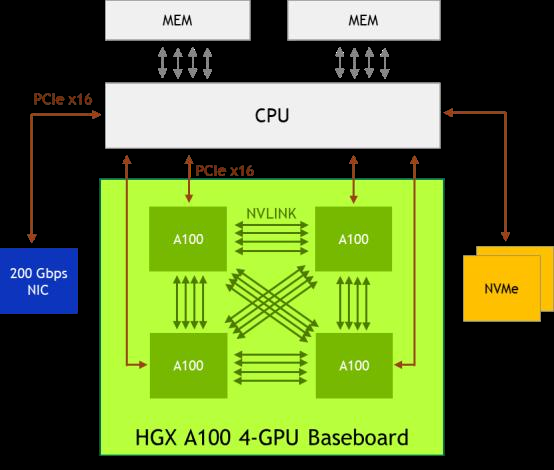
NVIDIA HGX A100 4-GPU 系 統 的 組 織 結 構。 每 個 A100 的 12 條 NVLink 被均分為 3 組,分別與其他 3 個 A100 直聯
經過多代發展,NVLink已經日趨成熟,並開始應用於GPU服務器之間的互連,進一步擴大GPU(以及其顯存)集羣的規模。
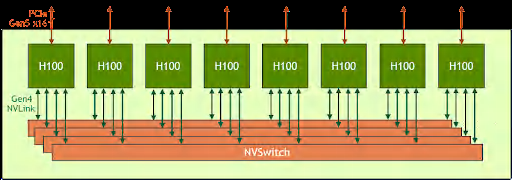
NVIDIA HGX H100 8-GPU 系 統 的 組 織 結 構。 每 個 H100 的 18 條 NVLink 被分為 4 組,分別與 4 個 NVSwitch 互聯。
三、NVLink 組網超級集羣
在2023年5月底召開的COMPUTEX上,英偉達宣佈了由256個Grace Hopper超級芯片組成的集羣,總共擁有144TB的GPU內存。大語言模型(LLM)如GPT對顯存容量的需求非常迫切,巨大的顯存容量符合大模型的發展趨勢。那麼,這個前所未見的容量是如何實現的呢?
其中一個重大創新是NVLink4 Networks,它使得NVLink可以擴展到節點之外。通過DGX A100和DGX H100構建的256-GPU SuperPOD的架構圖,可以直觀地感受到NVLink4 Networks的特點。在DGX A100 SuperPOD中,每個DGX節點的8個GPU通過NVLink3互聯,而32個節點則需要通過HDR InfiniBand 200G網卡和Quantum QM8790交換機互聯。在DGX H100 SuperPOD中,節點內部採用NVLink4互聯8個GPU,節點之間通過NVLink4 Network互聯,各節點接入了稱為NVLink Switch的設備。

DGX A100 和 DGX H100 256 SuperPOD 架構
根據NVIDIA提供的架構信息NVLink Network支持OSFP(Octal Small Form Factor Pluggable)光口,這也符合NVIDIA聲稱的線纜長度從5米增加到20米的説法。DGX H100 SuperPOD使用的NVLink Switch規格為:端口數量為128個,有32個OSFP籠(cage),總帶寬為6.4TB/s。
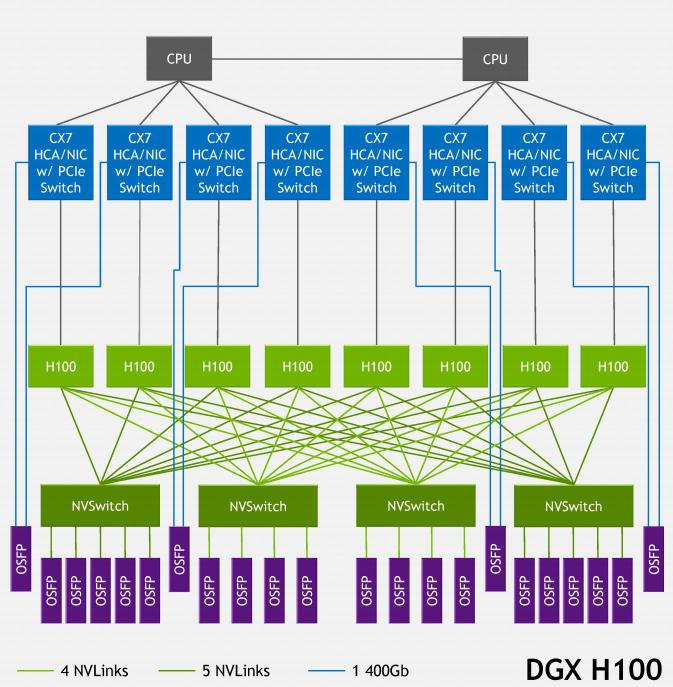
DGX H100 SuperPOD 節點內部的網絡架構
每個8-GPU節點內部有4個NVSwitch,對於DGX H100 SuperPOD每個NVSwitch都通過4或5條NVLink對外連接。每條NVLink的帶寬為50GB/s,對應一個OSFP口相當於400Gb/s,非常成熟。每個節點總共需要連接18個OSFP接口,32個節點共需要576個連接,對應18台NVLink Switch。
DGX H100也可以(僅)通過InfiniBand互聯,參考DGX H100 BasePOD的配置,其中的DGX H100系統配置了8個H100、雙路56核第四代英特爾至強可擴展處理器、2TB DDR5內存,搭配了4塊ConnectX-7網卡——其中3塊雙端口卡用於管理和存儲服務,還有一塊4個OSFP口的用於計算網絡。
回到Grace Hopper超級芯片,NVIDIA提供了一個簡化的示意圖其中的Hopper GPU上的18條NVLink4與NVLink Switch相連。NVLink Switch連接了"兩組"Grace Hopper超級芯片。任何GPU都可以通過NVLink-C2C和NVLink Switch訪問網絡內其他CPU、GPU的內存。
NVLink4 Networks的規模是256個GPU,注意是GPU而不是超級芯片,因為NVLink4連接是通過H100 GPU提供的。對於Grace Hopper超級芯片,這個集羣的內存上限就是:(480GB內存+96GB顯存)×256節點=147456GB,即144TB的規模。假如NVIDIA推出了GTC2022中提到的Grace + 2Hopper,那麼按照NVLink Switch的接入能力,那就是128個Grace和256個Hopper,整個集羣的內存容量將下降至約80TB的量級。
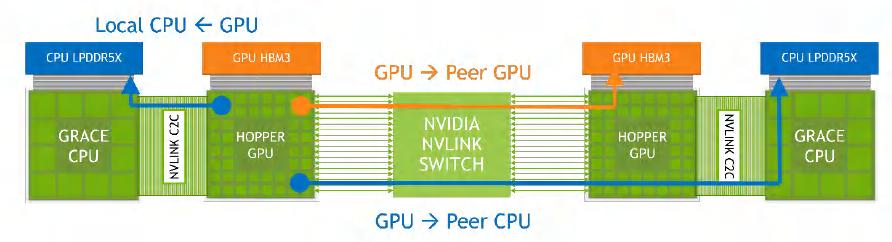
Grace Hooper 超級芯片之間的互聯
在COMPUTEX 2023期間,NVIDIA宣佈Grace Hopper超級芯片已經量產,併發布了基於此的DGX GH200超級計算機。NVIDIA DGX GH200使用了256組Grace Hopper超級芯片,以及NVLink互聯,整個集羣提供高達144TB的可共享的"顯存”,以滿足超大模型的需求。以下是一些數字,讓我們感受一下NVIDIA打造的E級超算系統的規模:
算力:1 exa Flops (FP8)
光纖總長度:150英里
風扇數量:2112個(60mm)
風量:7萬立方英尺/分鐘(CFM)
重量:4萬磅
顯存:144TB NVLink
帶寬:230TB/s
從150英里的光纖長度,我們可以感受到其網絡的複雜性。這個集羣的整體網絡資源如下:

由於Grace Hopper芯片上只有一個CPU和一個GPU,與DGX H100相比GPU的數量要少得多。要達到256個GPU所需的節點數大大增加,這導致NVLink Network的架構變得更加複雜。
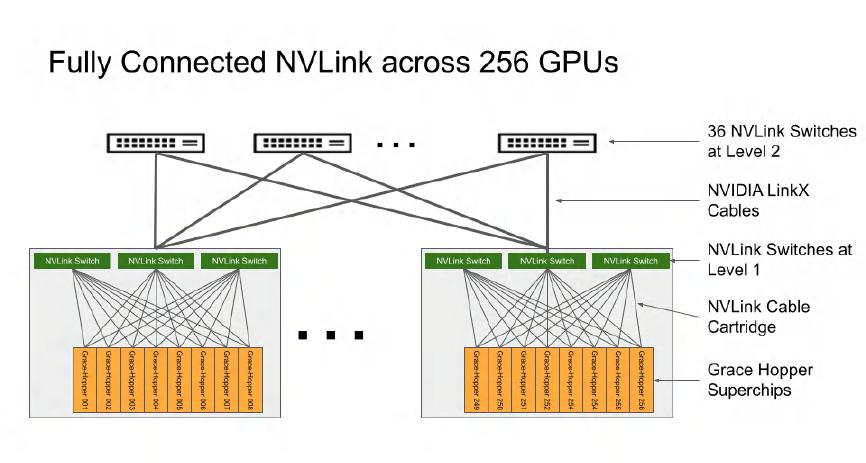
NVIDIA DGX GH200 集羣內的 NVLink 網絡架構
DGX GH200的每個節點有3組NVLink對外連接,每個NVLink Switch連接8個節點。256個節點總共分為32組,每組8個節點搭配3台L1 NVLink Switch,共需要使用96台交換機。這32組網絡還要通過36台L2 NVLink Switch組織在一起。
與DGX H100 SuperPOD相比GH200的節點數量大幅增加,NVLink Network的複雜度明顯提高了。以下是二者的對比:
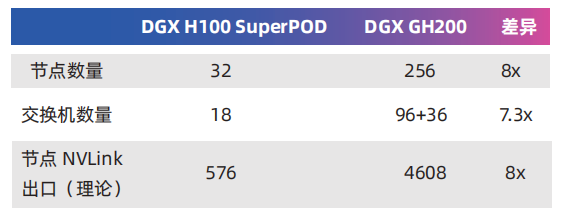
三、InfiniBand 擴大規模
如果需要更大規模(超過256個GPU)的集羣就需要引入InfiniBand交換機。對於Grace Hopper超級芯片的大規模集羣NVIDIA建議採用Quantum-2交換機組網提供NDR 400 Gb/s端口。每個節點配置BlueField-3 DPU(已集成ConnectX-7),每個DPU提供2個400Gb/s端口,總帶寬達到100GB/s。理論上使用以太網連接也可以達到類似的帶寬水平,但考慮到NVIDIA收購Mellanox,傾向於使用InfiniBand是可以理解的。

NVIDIA BlueField-3 DPU
基於InfiniBand NDR400組織的Grace Hopper超級芯片集羣有兩種架構。一種是完全採用InfiniBand連接,另一種是混合配置NVLink Switch和InfiniBand連接。這兩種架構的共同點是每個節點都通過雙端口(總共800Gbps)連接InfiniBand交換機,DPU佔用x32的PCIe 5.0並由Grace CPU提供PCIe連接。它們的區別在於後者每個節點還通過GPU接入NVLink Switch連接,形成若干NVLink子集羣。
很顯然混合配置InfiniBand和NVLink Switch的方案性能更好,因為部分GPU之間具有更大的帶寬以及對內存的原子操作。例如,NVIDIA計劃打造超級計算機Helios,它將由4個DGX GH200系統組成,並通過Quantum-2 InfiniBand 400 Gb/s網絡組織起來。

四、從 H100 NVL 的角度再看 NVLink
在GTC 2023上,NVIDIA發佈了專為大型語言模型部署的NVIDIA H100 NVL。與H100家族的其他兩個版本(SXM和PCIe)相比,它具有兩個特點:首先,H100 NVL相當於將兩張H100 PCIe通過3塊NVLink橋接連接在一起;其次,每張卡都具有接近完整的94GB顯存,甚至比H100 SXM5還要多。
根據NVIDIA官方文檔的介紹H100 PCIe的雙插槽NVLink橋接延續了上一代的A100 PCIe,因此H100 NVL的NVLink互連帶寬為600GB/s仍然比通過PCIe 5.0互連(128GB/s)高出4倍以上。H100 NVL由兩張H100 PCIe卡組合而成,適用於推理應用高速NVLink連接使得顯存容量高達188GB以滿足大型語言模型的(推理)需求。如果將H100 NVL的NVLink互連視為縮水版的NVLink-C2C,這有助於理解NVLink通過算力單元加速內存訪問的原理。
藍海大腦高性能大模型訓練平台利用工作流體作為中間熱量傳輸的媒介,將熱量由熱區傳遞到遠處再進行冷卻。支持多種硬件加速器,包括CPU、GPU、FPGA和AI等,能夠滿足大規模數據處理和複雜計算任務的需求。採用分佈式計算架構,高效地處理大規模數據和複雜計算任務,為深度學習、高性能計算、大模型訓練、大型語言模型(LLM)算法的研究和開發提供強大的算力支持。具有高度的靈活性和可擴展性,能夠根據不同的應用場景和需求進行定製化配置。可以快速部署和管理各種計算任務,提高了計算資源的利用率和效率。

總結
在計算領域,CPU和GPU是兩個關鍵的組件其在處理數據和執行任務時具有不同的特點和複雜性。隨着計算需求的增加,單一的CPU或GPU已經無法滿足高性能計算的要求。因此,多元算力的結合和算存互連、算力互連的重要性日益凸顯。
作為計算機系統的核心,CPU具有高度靈活性和通用性,適用於廣泛的計算任務。它通過複雜的指令集和優化的單線程性能,執行各種指令和處理複雜的邏輯運算。然而隨着計算需求的增加,單一的CPU在並行計算方面的能力有限,無法滿足高性能計算的要求。
GPU最初設計用於圖形渲染和圖像處理,但隨着時間的推移,其計算能力得到了極大的提升,成為了高性能計算的重要組成部分。GPU具有大規模的並行處理單元和高帶寬的內存,能夠同時執行大量的計算任務。然而,GPU的複雜性主要體現在其並行計算架構和專業化的指令集,這使得編程和優化GPU應用程序更具挑戰性。
為了充分利用CPU和GPU的優勢,多元算力的結合變得至關重要。通過將CPU和GPU結合在一起,可以實現任務的並行處理和分工協作。CPU負責處理串行任務和控制流,而GPU則專注於大規模的並行計算。這種多元算力的結合可以提高整體的計算性能和效率,並滿足不同應用場景的需求。
算存互連是指計算單元和存儲單元之間的高速互聯,而算力互連是指計算單元之間的高速互聯。在高性能計算中,數據的傳輸和訪問速度對整體性能至關重要。通過優化算存互連和算力互連,可以減少數據傳輸的延遲和瓶頸,提高計算效率和吞吐量。高效的算存互連和算力互連可以確保數據的快速傳輸和協同計算,從而提高系統的整體性能。
CPU和GPU在計算領域扮演着重要的角色,但單一的CPU或GPU已經無法滿足高性能計算的需求。多元算力的結合、算存互連和算力互連成為了提高計算性能和效率的關鍵。通過充分利用CPU和GPU的優勢,並優化算存互連和算力互連,可以實現更高水平的計算能力和應用性能,推動計算技術的發展和創新。