2023WAIC世界人工智能大會見聞:大模型安全到底在哪?_風聞
谭婧在充电-谭婧在充电官方账号-偏爱人工智能(数据、算法、算力、场景)。-07-10 20:21

親愛的數據:出品
2023年7月不能錯過的人工智能大會當屬在上海舉辦的2023世界人工智能大會(WAIC)。
8日下午,以“智聯世界·生成未來”為主題的WAIC在世博中心閉幕。
本次大會上,“親愛的數據”見到了瑞萊智慧RealAI聯合創始人、算法科學家蕭子豪。
瑞萊智慧是依託清華大學人工智能研究院發起設立的人工智能公司,對人工智能安全技術頗為擅長。清華大學計算機系長聘教授、清華大學人工智能研究院副院長、瑞萊智慧/生數科技首席科學家朱軍在業界享有勝譽,公司於2022年9月入選國家級專精特新“小巨人”企業。
他們這次在WAIC上發佈的產品是,RealSafe3.0。
RealSafe是產品名稱,3.0是產品版本號。
該公司旗下硬核技術產品還包括;第一,RealSafe:針對大模型自身安全性檢測。第二,DeepReal:針對生成式模型所生成內容的檢測。第三,RealSecure:針對數據安全,以及隱私保護。
對此,”親愛的數據“的評價是:因為模型的生產訓練以及部署,甚至更早的數據準備,各個環節和傳統軟件有較大區別,以往的安全技術和方案難以囊括或者包含在人工智能安全問題中。
這三款產品“親愛的數據”的理解是:第一,RealSafe產品圍繞模型本身的安全,也就是模型安全(評測+優化)。第二,DeepReal更針對深偽技術,類似深度偽造內容檢測平台。第三,RealSecure是保護數據安全的隱私保護技術平台
安全是一個重要,全面,且細項諸多,掛一漏萬的技術領域。有IT,就有IT安全問題。有AI,就有AI安全問題。

其中一個原因就是人工智能安全技術較為前沿,在學術領域沒有領先性的科技成果,如何遏制“洪水猛獸“肯定是要比猛獸更猛,也有網友戲稱”用魔法打敗魔法“。
常見的安全問題有:打擊網絡詐騙和聲譽侵害檢測網絡內容合法合規性檢測音視頻物證真實性濫用生成式人工智能技術行為
上海WAIC大會上,蕭子豪對”親愛的數據“表示:“評測只是手段,幫助通用大模型提升其自身安全性才是核心目的。”
他強調:“不能因為對於被技術反噬的擔憂就止步不前,創造新技術和控制技術危害應該同步進行。”

很多人都擔憂人工智能安全,然而,有些問題表現在表面,有些問題潰爛在機理。
我們來看看瑞萊科技產品大圖上的變化:
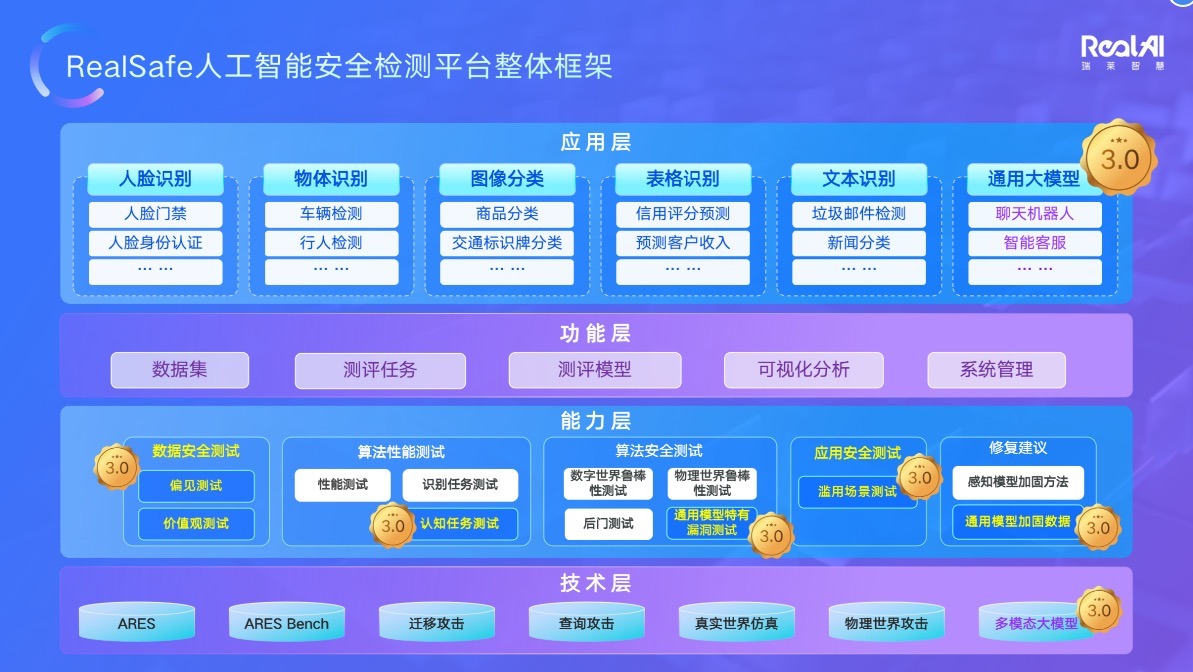
大模型風險都會出現在這些大模型應用上線前的最後這一道關卡上面。
所以現在大模型上線會有兩大類痛點,一類是它的安全測試成本會很高,另外一個大痛點就是安全整改成本會很高,測試成本高體現在因為這些聊天數據的數量跟種類都是非常多的,很難讓一個很難窮舉所有可能出現的用户使用情況。而且這些即使去窮舉,這些問題往往都需要算法專家或者人文社科的專家去設計,這會引入非常高的成本。
另外整改成本也很高。因為整改就意味着你需要算法專家去對這個模型。進行一個優化,但這些優化背後都需要懂大模型原理的算法科學家。但這些科學家的非常短缺,成本也是非常高的。
他介紹:”RealSafe3.0內部集成了多個自研模型和專家論證高質量數據集,來幫助用户修復模型中的問題。
對黑盒不可解釋的通用大模型,自研紅隊對抗模型取代人工設計問題,顯著提升攻擊成功率和樣本多樣性。也就是説,該模型數據集中,不僅包含了自有數據集,還包含了模型自生成的數據,無論是從數據質量還是數據規模上都可圈可點,因此它能夠自動化地挖掘出更多的漏洞,真正從源頭上緩解安全問題。“
在”親愛的數據“看來,夯實的數據基礎讓教練模型理想的模型效果非同凡響。

在業界中頗為罕見的是:他們團隊自有數據集,經過數十位價值觀領域的專家論證,以確保輸入的數據無誤,質量高且領域多元,未來也將持續更新補充。
瑞萊科技對這次產品的核心提煉語是:可提升生成式大模型安全性的RealSafe3.0。
在”三大“產品中,並不是只有圍繞模型本身安全的RealSafe有進展,
DeepReal此前名為深度偽造內容檢測平台,現已正式更名為生成式人工智能內容檢測平台,因為它除了能夠檢測Deepfake內容,還新增兩個功能模塊,可以檢測Diffusion、LLM這兩類新方法生成的數據,支持對圖像、視頻、音頻、文本進行是否偽造的檢測。

(完)
親愛的數據,出品

