小扎今天搞了個大新聞,想把大模型變成下一個“安卓”_風聞
差评-差评官方账号-07-20 07:52
本文原創於微信公眾號:差評 作者:差評君
距離 OpenAI 上次説考慮開源 GPT-3,已經過去兩個多月了。
 結果,GPT-3 開源的影子一點兒沒瞅着,反倒是一直熱衷於開源的 Meta 又帶着他們家的羊駝模型來上大分了,發佈了一個進階版的 Llama 2。
結果,GPT-3 開源的影子一點兒沒瞅着,反倒是一直熱衷於開源的 Meta 又帶着他們家的羊駝模型來上大分了,發佈了一個進階版的 Llama 2。

説起這 Llama 羊駝模型,估計大夥兒之前也見識過了,一經問世,就在開源社區的各大榜單中刷屏。
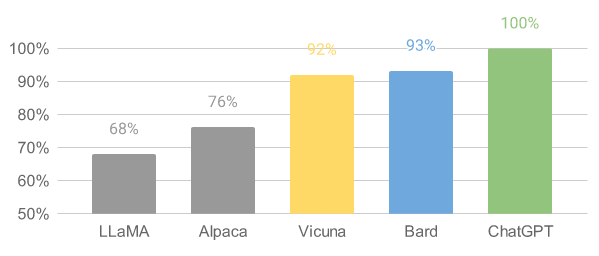
也是從 LLaMA 開始,什麼斯坦福的 Alpaca、UCB 的 Vicuna。。。各種基於 LLaMA 的小模型一個接着一個地蹦出來。
別看這些二創的模型參數量小,和千億參數的 GPT 模型比起來,效果其實也還不錯。
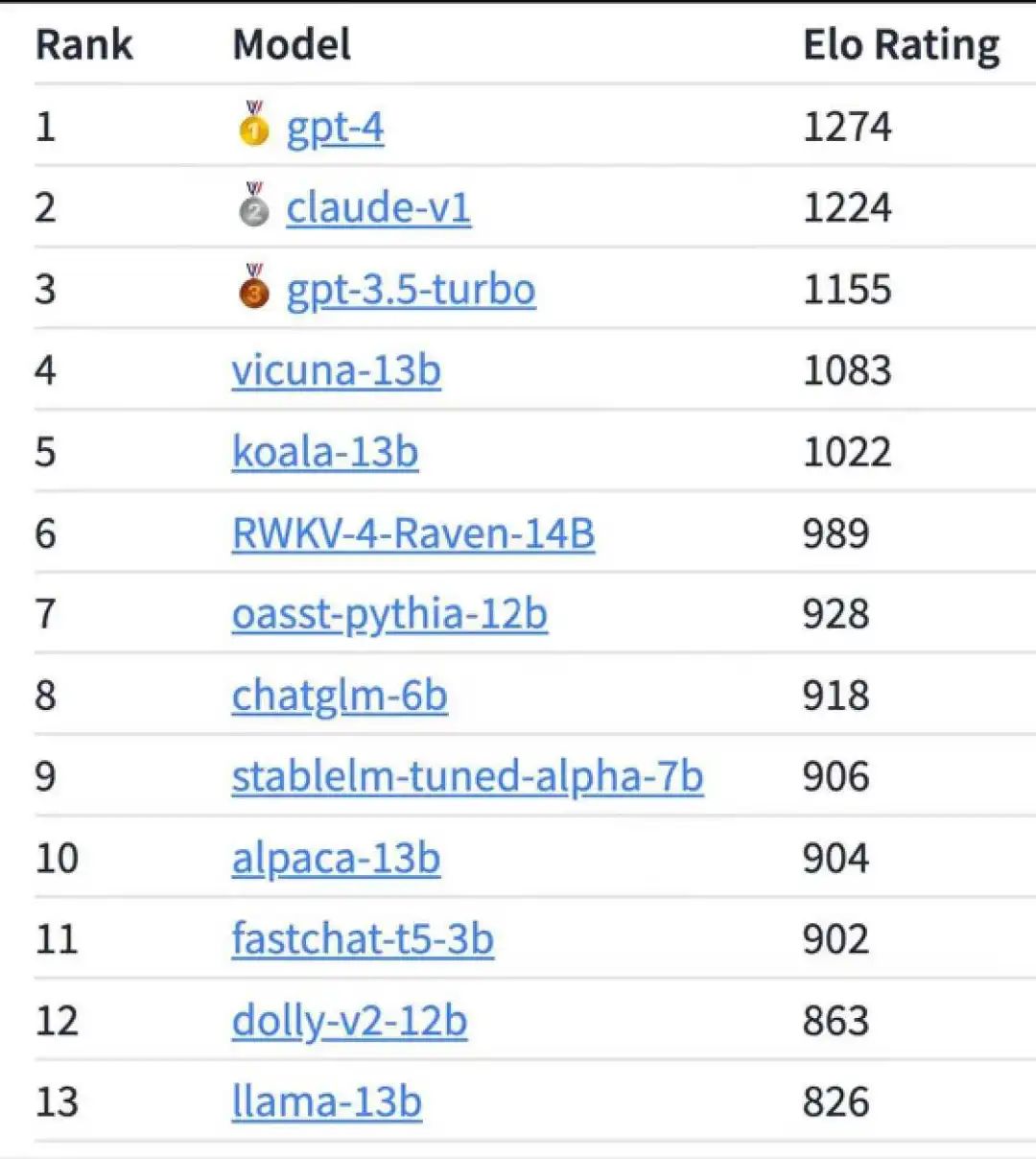
前段時間網上不是發了一個大模型的排名嘛,第四名的 Vicuna 可沒比 GPT-3.5 遜色多少。
而這次的 Llama 2,又來了波升級。
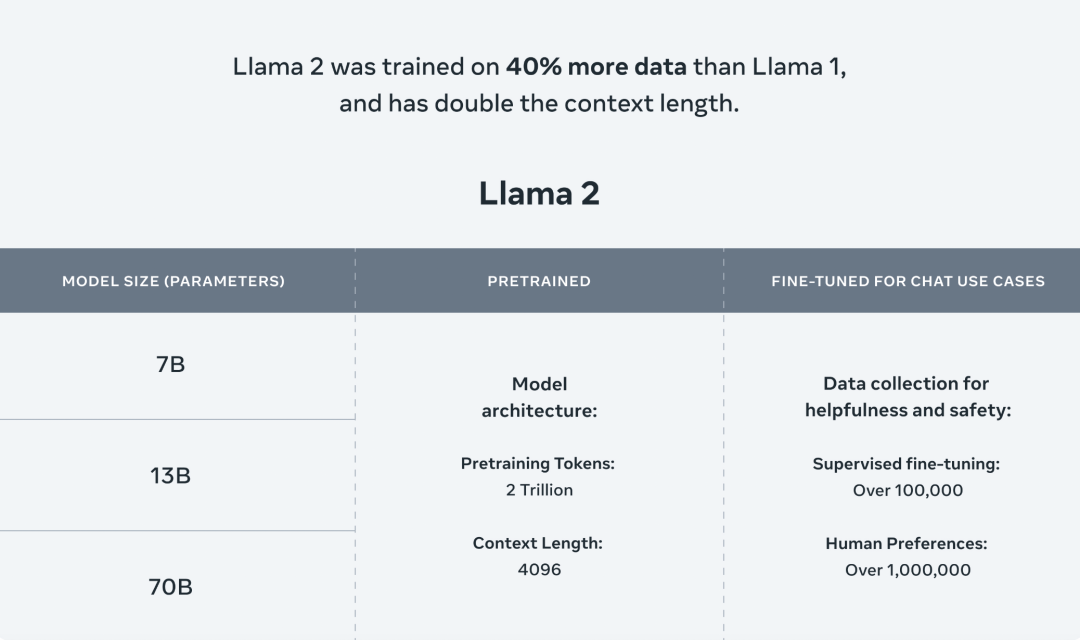
相比上一代 Llama,Llama 2 增加了 40% 預訓練數據,Token 數翻了差不多一倍到2T,模型的參數量也擴展到了 700 億。
 在長文本的支持能力上,訓練文本的窗口也從之前的 2048 擴展到 4096 。而且還發布了一個微調之後的 Llama 2-Chat 模型,專門針對應用場景的優化。
在長文本的支持能力上,訓練文本的窗口也從之前的 2048 擴展到 4096 。而且還發布了一個微調之後的 Llama 2-Chat 模型,專門針對應用場景的優化。
也可以這麼理解,升級過後的 Llama 2 初始屬性更強了,升級更快了,等級上限也更高了。
不過,這些還都只是小菜。
 Llama 2 最大的亮點,就是開源、免費、可商用,而且還支持在高通的芯片上運行。
Llama 2 最大的亮點,就是開源、免費、可商用,而且還支持在高通的芯片上運行。
這跟上一代 Llama 源代碼泄露的“被開源”可不太一樣,之前即使允許二創,也只是停留在研究領域。
可以免費商用,就相當於拿到了 Meta 準用許可的“免死金牌”,你拿去幹啥都不用擔心回頭被告侵權。
當然了,這許可也是有點限制的,要是產品的日活超過 7 億,那就還得去申請一下。
 而在高通的芯片上運行,也一反過去大模型受制於英偉達芯片的常態。
而在高通的芯片上運行,也一反過去大模型受制於英偉達芯片的常態。

看來,Llama 2 這次,大有要一舉打破 OpenAI 和英偉達封鎖的意思啊。
所以消息一出,很快就在網上引起了一波轟動。
 有不明覺厲的吃瓜羣眾跟風誇讚的,還有人馬上用 Llama 2 做了個應用程序出來。
有不明覺厲的吃瓜羣眾跟風誇讚的,還有人馬上用 Llama 2 做了個應用程序出來。
甚至於,Meta 的首席 AI 科學家 Yann LeCun 楊立昆也在推特上為 Llama 2 站台,説它將會“徹底改變大語言模型的行業格局”。

Llama 2 這次的升級當真就有這麼厲害嗎?
本着求證的態度,差評君聯繫到了在學術圈和開源社區,都頗具影響力的智源 AI 研究院,得到的答案是:這次 Llama 2 的升級,其實並不是重點,開源可商用才是。
 而與開源的羊駝模型形成對比的 GPT,就因為閉源( 不開放源代碼 )而備受吐槽。
而與開源的羊駝模型形成對比的 GPT,就因為閉源( 不開放源代碼 )而備受吐槽。

當然,關於這開源和閉源的爭論,其實從 PC 時代就已經開始了。
當年的開放源碼運動裏,就誕生出了大家熟知的 Linux 系統。
因為開源之後,大夥們都能上手魔改代碼、移植應用等等,基於 Linux 的開源生態也扎着根長出了枝葉。
而如今的路由器、交換機、智能洗衣機、智能電飯煲、交換機、服務器等等設備上,幾乎搭載了各類 Linux 系統。
 包括幾年前的美國火星車登錄成功,還把 Linux 帶上了火星。
包括幾年前的美國火星車登錄成功,還把 Linux 帶上了火星。

而開源,也逐漸演變成為了一種“開放共享”的精神。
如果沒有開源,紅帽、ubuntu 等桌面操作系統很大概率就不會出現,安卓也不會拿下如今智能手機近三分之二的市場份額。
 歷史總是驚人的相似,現在開源與閉源的戰火很明顯已經蔓延到AI領域。
歷史總是驚人的相似,現在開源與閉源的戰火很明顯已經蔓延到AI領域。
有意思的是,一直被詬病不太“ Open ”的 Open AI,其實在 GPT-3 之前,一直都是開源的,GPT-2 的代碼、框架還有論文都開放得很徹底。
但到了 GPT-3,就只能看論文了。

也難怪馬斯克當年執意要退出 OpenAI,因為它們完全違背了當初要成立一家開源非營利組織的初衷。
但即使頂着外部輿論壓力,GPT-3 和 GPT-4 仍然雷打不動的堅持閉源。
 至於原因,根據 OpenAI 官方的説法,是出於“安全”的考慮。
至於原因,根據 OpenAI 官方的説法,是出於“安全”的考慮。
這也合理,作為目前最牛叉的大模型,GPT-4 要是真落入了壞人的手裏,的確很麻煩。
但差評君覺着,還有一個原因是,OpenAI 不想放棄現有的技術優勢。
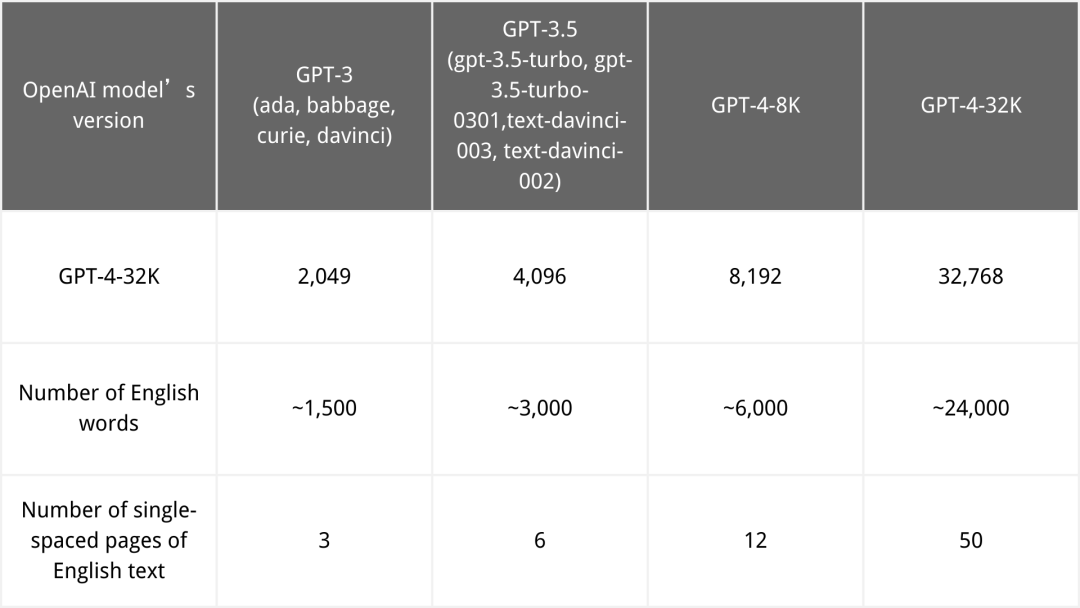
畢竟 GPT-4 跟前輩們相比,無論是在參數量還是性能上都有了大規模的提升,Open AI 不想讓自己的心血白給也可以理解。
説白了,閉源更像是一種商業行為。
但有一説一,閉源的王座並不會一直牢固。
 因為從第一代 Llama 開始,大模型開源的這把火就已經被點燃了。開源模型的隊伍日漸壯大,AMD 也宣佈要在明年開源 OLMo 大語言模型。
因為從第一代 Llama 開始,大模型開源的這把火就已經被點燃了。開源模型的隊伍日漸壯大,AMD 也宣佈要在明年開源 OLMo 大語言模型。
隨着更多模型源代碼的開放,將會有越來越多的人蔘與到模型的迭代升級當中,為開源的生態添磚加瓦。而技術壁壘在這個過程中,也會被慢慢拉平。
而作為打響了羊駝模型開源第一槍的 Meta,也一直在暗戳戳地往裏添柴。
 當初,為了請 AI 大拿楊立昆出山,扎克伯格可謂是煞費苦心,不僅答應了他諸多苛刻的要求,而且還立下了研究成果必須開源的規矩。
當初,為了請 AI 大拿楊立昆出山,扎克伯格可謂是煞費苦心,不僅答應了他諸多苛刻的要求,而且還立下了研究成果必須開源的規矩。

從 2015 年把 CNN 卷積神級網絡用到 GAN 上,提出了 DCGAN,到開源基於 Python 的深度學習框架 PyTorch,再到如今全網刷屏的 Llama。
這麼多年了,小扎承諾過的“開放”似乎從來就沒變過。
 包括 Llama 之後,Meta 又陸續推出了一系列多模態大模型,像什麼Imagebind、MusicGen,都是開源的。
包括 Llama 之後,Meta 又陸續推出了一系列多模態大模型,像什麼Imagebind、MusicGen,都是開源的。
而且,對於 OpenAI 口中,出於安全考慮的閉源理由,楊立昆也是不太認同的。
在他看來,使人工智能平台安全、良善、實用的唯一方法就是開源。
換句話説,技術掌握在少數人的手裏是危險的,只有讓監管 AI 的力量也同時進化,才能儘可能地管住 AI。
 這在目前看來,暫時只有開源能辦到。
這在目前看來,暫時只有開源能辦到。

而小扎這步棋,又或者説,當年楊立昆堅持開源埋下的種子,或許很快就能看到收穫。
比如在定製化的大模型****上,開源會跑得比閉源更快。

不可否認的是,OpenAI 大模型的能力的確很能打,但 OpenAI 的團隊到底能不能根據具體的行業和應用場景去做適配,還需要打個問號。
 打個比方,一家服裝廠要用 GPT-4 來優化貨物的調度流程,廠裏原材料的運送、存儲,成品的質量檢測,裏邊兒涉及到太多的行業 Know-How,如果不是由企業自家的開發者來操作,OpenAI 最終交付出來的效果不一定能滿足企業的業務需求。
打個比方,一家服裝廠要用 GPT-4 來優化貨物的調度流程,廠裏原材料的運送、存儲,成品的質量檢測,裏邊兒涉及到太多的行業 Know-How,如果不是由企業自家的開發者來操作,OpenAI 最終交付出來的效果不一定能滿足企業的業務需求。
畢竟,咱也不能指望一個搞 AI 的公司,突然就懂服裝了。。。

就算咱拋開質量不談,算力成本一攤下來,中小企業也很難吃得消。更何況,有些企業的數據涉及商業機密,全都交由 OpenAI ,老闆估計也不放心。
 但開源的優勢就在於,開發者可以在源代碼的基礎上,根據業務需求對模型進行微調。
但開源的優勢就在於,開發者可以在源代碼的基礎上,根據業務需求對模型進行微調。
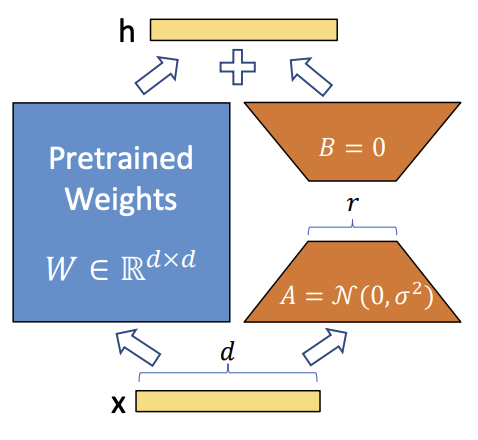
和從頭訓練大模型相比,在開源的基礎上,運用 LORA 這類低成本的微調方法去構建一個適配下游任務的模型,顯然後者的性價比更高。
當開源大模型滲透到越來越多的行業以後,開發者反饋的業務需求越多,模型迭代的速度也會越快。
 先佔領市場,再用量變來催化質變。
先佔領市場,再用量變來催化質變。
當然了,無論是開源,還是閉源,其實都沒有絕對的對錯之分。
OpenAI、谷歌之流堅持閉源也無可厚非。
畢竟幾十億美元砸出來的優勢擺在那,在模型層級、Token 長度、推理等等能力上,還是領先現在的開源模型不少。
但開源大模型現在勢頭正猛,搶先一步實現商業化也不無可能。
就像不久前 Altman 説的那樣,AI 之後會分化,開源負責商業化落地,而閉源則負責研究超級智能。
所以差評君大膽猜測,AI 大模型的行業格局,或許會是一兩家頭部閉源,其他開源模型建立起社區生態的局面。
 而在開源推動下的商業化落地,也可能會很快地重塑生活的方方面面,説不定哪天你家的掃地機器人就能幫你遛狗了。
而在開源推動下的商業化落地,也可能會很快地重塑生活的方方面面,説不定哪天你家的掃地機器人就能幫你遛狗了。
差評君還是很期待,在開源的加持下,AI 究竟能給我們的生活帶來什麼樣的變化。
圖片、資料來源:
Meta AI、推特、WAIC
智源社區,當今開源大語言模型一覽,每個AI 實踐者都應該瞭解
We have no moat,and neither does OpenAI
遠川科技評論,差一步稱霸AI:歷史進程中的扎克伯格