微調真香,科技博主竟然在用國產大模型生成系列漫畫女主角_風聞
谭婧在充电-谭婧在充电官方账号-偏爱人工智能(数据、算法、算力、场景)。-08-28 17:40

有一説一,《微調真香,漫畫科技博主竟然在用國產大模型生成系列漫畫女主角》不是標題黨。
連我也不得不相信,作為“親愛的數據”創始人,我確實在用人工智能大模型生成自家特有風格的漫畫。
市面上,海內外,用Midjourney或者文心一格之類的文生圖的能力生成精美圖畫這件事似乎也沒有什麼稀奇。
日常聊天,有人動不動就説:“你讓人工智能給你畫。”
這話我接不住,並且很想回懟。
你能你上呀,你讓人工智能給你畫。
文生圖首先得會“咒語”。
這裏的“咒語”是指提示詞Prompt。
也許有人天生就會用“咒語”。
或者也許有人通過練習能將“咒語”用得出神入化。
很可惜,我沒有天賦。
很遺憾,Midjourney的咒語我練了很久,水平依然很菜。
完了,霍格沃茨四大學院,我今年鐵定考不上了。
不過,聊以自慰,在文生圖的時候,讓人工智能“陪你畫着玩”和“按職業要求畫” 完全是兩回事。
後者很難。
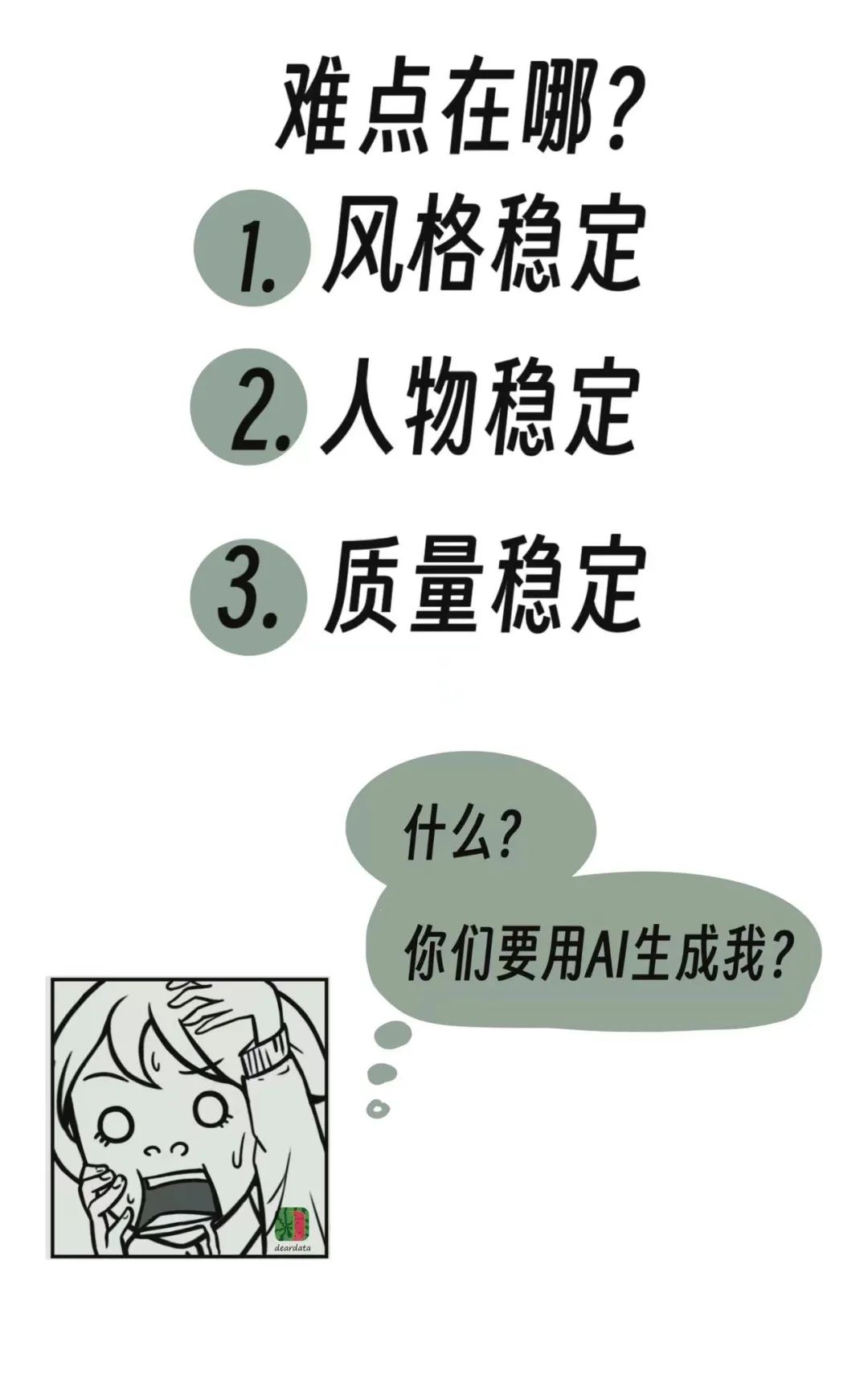
1.風格穩定,繼續畫出我們已有的漫畫風格;
上一張宮崎駿,下一張葫蘆娃,這樣不行。
2.人物穩定,主角是“同一個IP人物”。
做到這一點,意味着微調後的模型認識我們科技漫畫故事裏的“女主角”,這裏要隆重介紹一下,她叫做“小桔子”。
實際上,我們還有配角團隊,就是五仁。沒錯,就是五仁月餅的那個五仁。和世界上所有的配角一樣,我們希望五仁能夠豐富故事內容,完成特定任務,推動情節發展,以及搞笑擔當。
不過,我們決定要微調模型的時候,五仁的角色還沒有確定,或者説,沒有完全定型。

3.質量穩定,醜圖不行。
這只是三個重點,對於大部分漫畫團隊的來説,比較有共通性。
團隊肯定有自己的審美偏好,所以,次重點也有很多:
比如,筆觸力度一致,不能有的畫線條粗,有的畫,線條細。
比如,不要大面積使用豔麗色彩。
比如,少量着色
……
反正,有圖你自己看就行了,圖都在文章裏。
生成的科技漫畫,要把這些要求都滿足,可太難了。
好在,譚老師我對人工智能的理解有點深,高低能拿得出手的文章寫了二十來萬字。
藉機,插播一條硬廣:

這時候,我判斷:需要上微調模型了。
這裏説的微調模型,是指,在基礎大模型的基礎上,使用“親愛的數據”私有數據(漫畫圖片)訓練出來的微調模型。
雖然不知道結果如何,但是**“微調”這隻“螃蟹”,我先吃為敬**。
對微調後的模型效果有何期待呢?
我曾經聽到一些專業的畫家説,人工智能可以激發靈感。要我説,膽子再大一點。
微調模型能夠生成特定風格的漫畫,情況不外乎三種,
第一,能直接生成我們所需要的科技文章中的配圖。這是最好的情況,拿來就用。
第二,對圖畫少量改動後,就能用。
第三種最糟糕,對圖進行大量手工修改。
那種不能用的就直接刪了,省的佔用存儲空間。
為了保護商業秘密和知識產權,文章中均以“我們”來模糊處理團隊內部配合和分工的細節。

**1.基礎模型:**武漢人工智能研究院的“紫東太初”國產大模型;
2.原始數據:科技科普漫畫已經發布了二十多期。對“親愛的數據”老讀者而言,原始數據不需要介紹,全部來自原創漫畫系列。
4. AI for Science這事,到底“科學不科學”?
5. 想幫數學家,AI算老幾?
11. 強化學習:人工智能下象棋,走一步,能看幾步?
14. 雲計算Serverless:一支穿雲箭,千軍萬馬來相見
15. 數據中心網絡:數據還有5納秒抵達戰場
17. ChatGPT大火,如何成立一家AIGC公司,然後搞錢?
18. ChatGPT:絕不欺負文科生
不過,值得注意的是,我拿出來的私有數據都是黑白線稿.
從全部數據中挑了240張,並且都進行了標註。
標註方法就是給每個圖片都給出了一句描述性的句子,我有一部分數據是彩圖,但是沒有拿出來訓練。原因是,從實用的角度出發。黑白線稿更好修改。
風格上,追求簡約,如果線稿能夠把科技科普內容説清楚,就不費事複雜上色。
**3.訓練時間:**5小時;
**4.訓練資源:**華為昇騰910 ,2張 32G的NPU;
**5.訓練類型:**小樣本微調;
**6.應用界面:**開源的Gradio簡單搭建,不是十分穩定,有時候也會報錯;
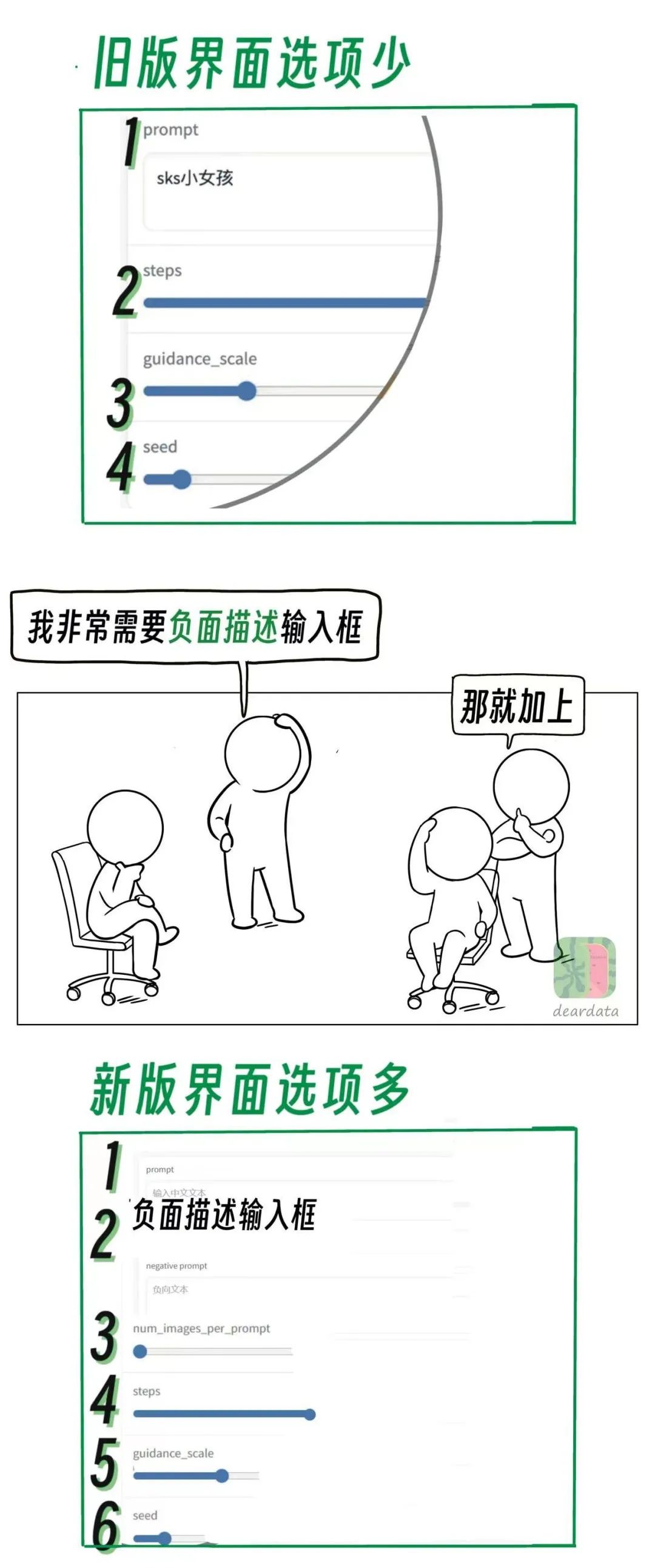
step是引導步數,越多生成的圖細節越多,會更豐富,但也可能會起到反效果;
scale是引導力度,scale越大圖像內容跟語義更相關,但過大會導致圖像質量下降;
seed是隨機種子,改變seed會在保證語義的前提下,調整圖像的構圖;
舊版應用界面有些不趁手的地方,我們經過反覆討論,幾輪對齊需求。(字少,事多。)
我們更新了一版應用界面,可以調的維度增多了,更能“探索”出大模型的能力。
俗稱,順手了。
**7.**提示詞長度:****55個字。
**8.每次可生成張數:**7張。
 這部分應該是最有趣的。
這部分應該是最有趣的。
借用此前的比喻,帶着私有數據上門訓練,好比提着自己最喜歡的獨門秘方餃子餡,直接到店,向餐廳要求定製化服務。
一般説來,模型微調屬於ToB服務。
但,凡事無絕對。
我們科技漫畫中的女主人公,也是我們漫畫的IP人物,在提示詞中使用“SKS小女孩”指代“小桔子”。
讓模型學習“認識”小桔子,再生成出她的相關漫畫。
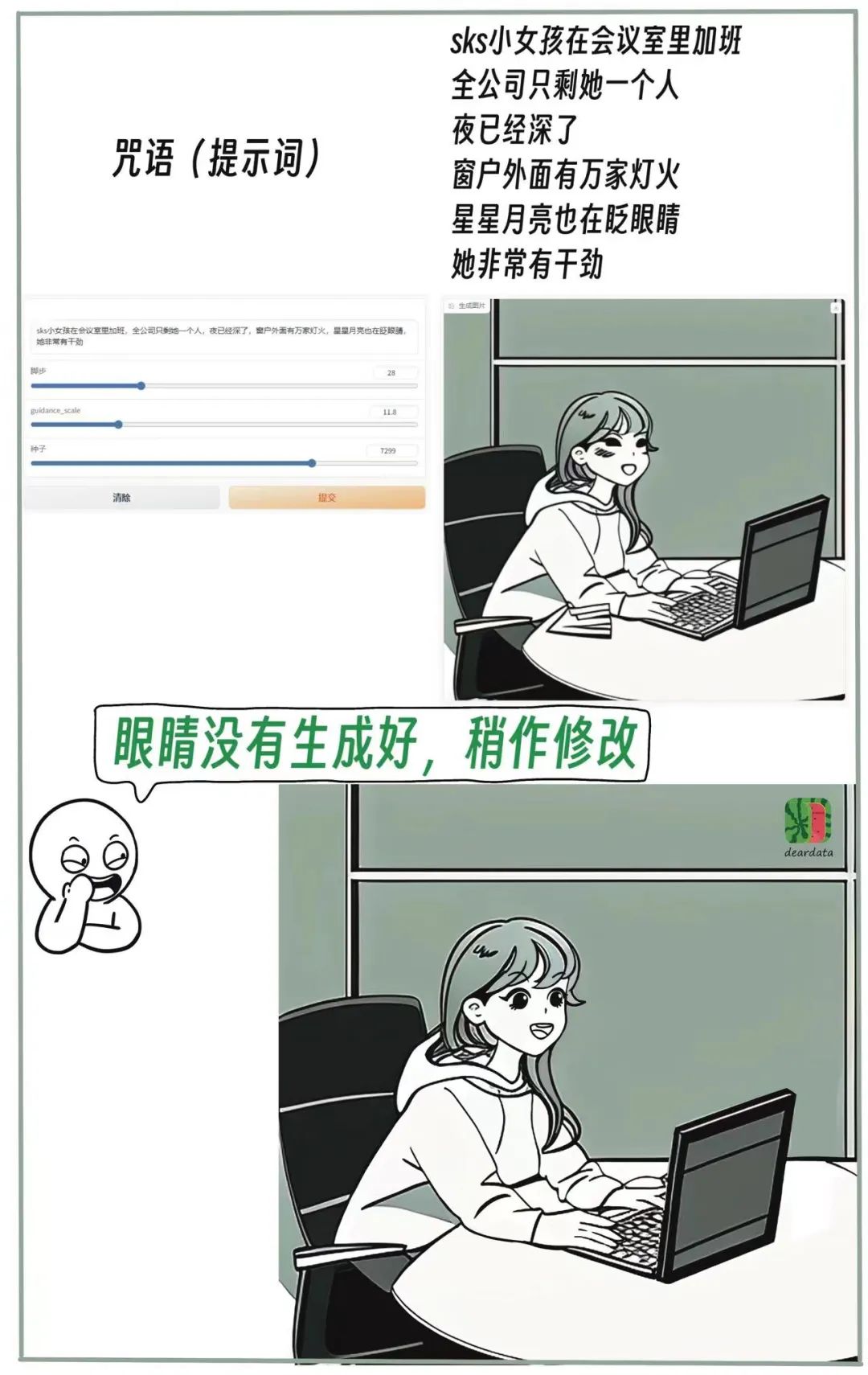
業務在發展,小桔子的形象也在迭代。
在訓練數據中,第二代和第三代小桔子的眼睛差距比較大,所以大模型生成的眼睛的失敗率非常高。可能大模型也很困惑到底學哪個。
造成這個糟糕問題的原因是,親愛的數據團隊的業務也在迅速迭代,我們需要調整小橘子的形象,迭代時期正好和訓練時間相撞。
但是,業務不可能停下來。
不得不承認,想用新技術,踩坑是避免不了的。
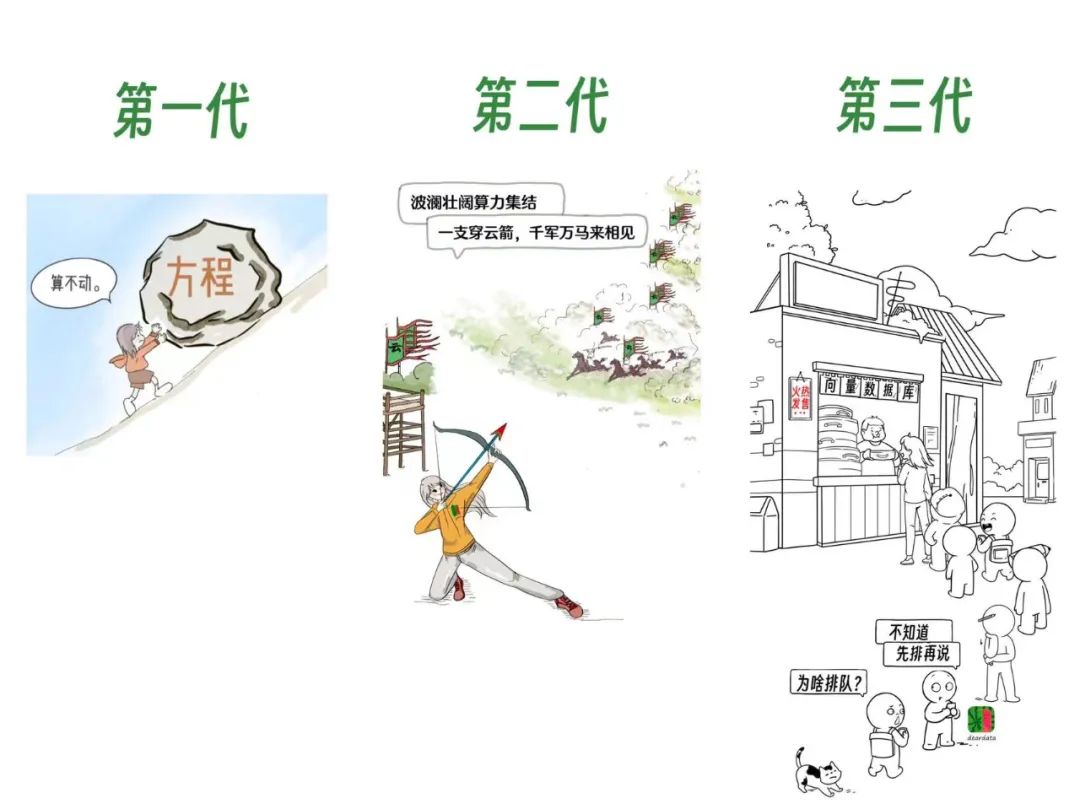
第一代:漫畫丨AI for Science這事,到底“科學不科學”?
第二代:漫畫雲計算Serverless:一支穿雲箭,千軍萬馬來相見
第三代:老店迎新客:向量數據庫選型與押注中,沒人告訴你的那些事
眾所周知,基礎模型非常重要。
因為是小樣本訓練,數據以小桔子的形象為主,樣本數據中沒有出現的大千世界的各種事物,比如企鵝,獨角獸,龍,贔屓,只能依靠基礎模型的能力。
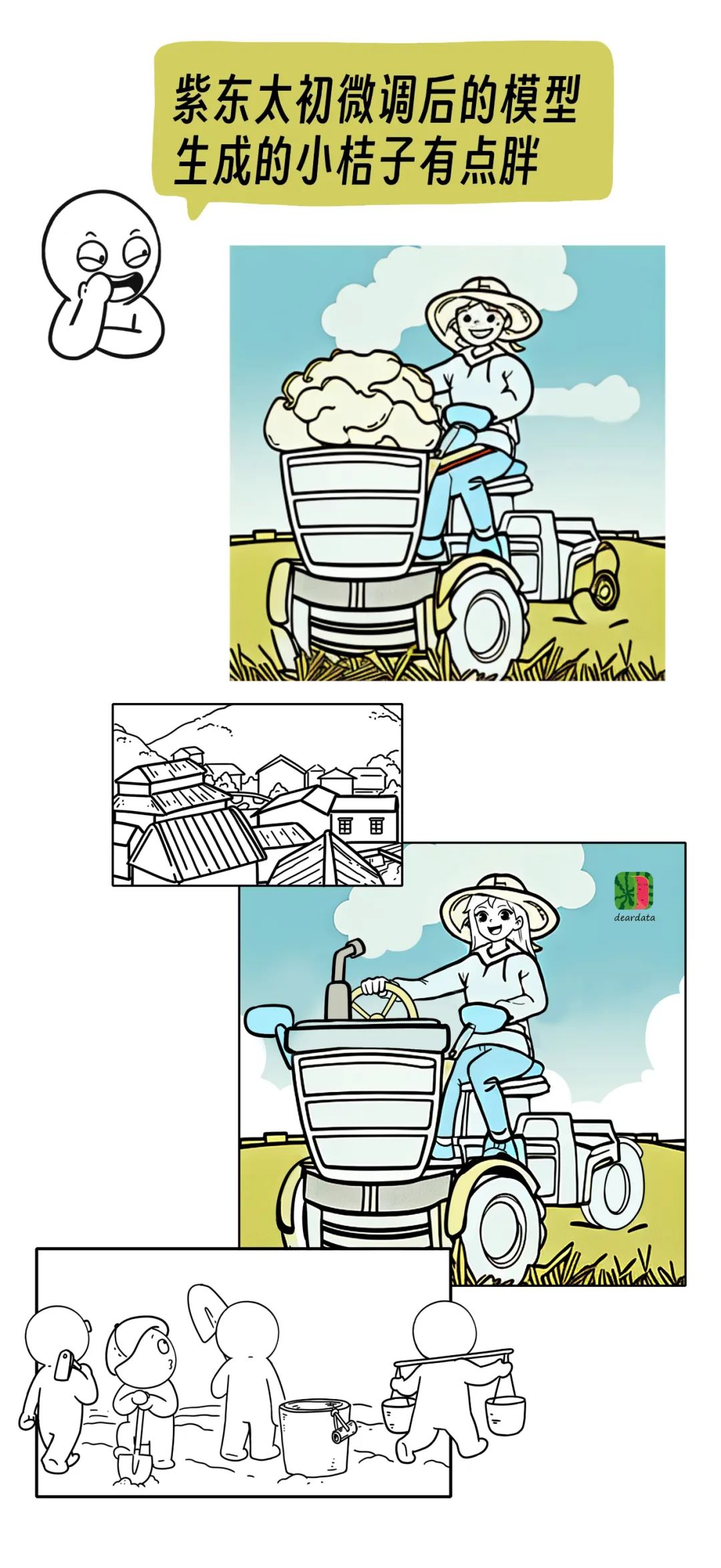
雖然眼睛總是失敗,但我們認為,小橘子的臉型和髮型生成得還不錯,對此,武漢人工智能研究院的專家給我的講解是:
學習小橘子的特徵既包括風格,也包括樣貌。比如,學習一個女生的樣貌,10張圖就能學到生神態特徵。
妙鴨APP生成優美藝術照片的原理也是如此,換妝的時候(場景),不需要學太多特徵。


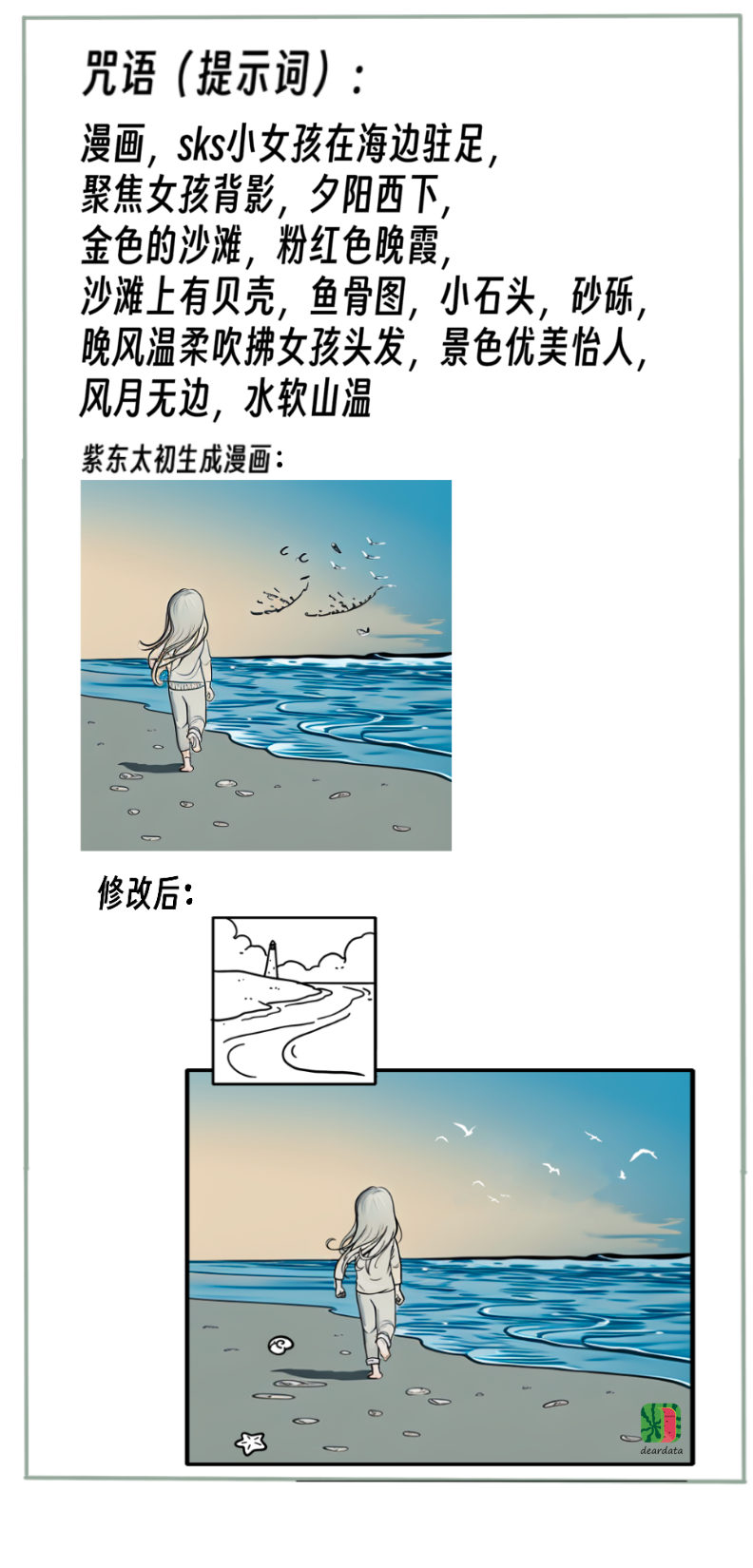

結合用文生圖模型的心路歷程,從經濟學的角度談談以下幾點:
1. 大模型不能代替主創思想。
如果你腦子裏什麼都沒有,大模型也沒辦法代替你思考。我們的方法是,你有了想法,再去引導大模型生成。
2.文生圖模型能讓主創團隊的工作成果變得更多。
對於創意團隊來説,好作品多,自然業界影響力大。同樣的團隊規模,能出更多的活,紫東太初大模型可以成為我們團隊勞動力的補充。
3.施咒能力是一種必備的,很值錢,很有技術含量的技能。
只要提示詞這個模式沒有被革命,有文生圖需求的人都應該儘快學。
圖文模型不像語言模型那樣情商高,就算你做得不好,它也會有禮貌的安撫你。
圖文模型一切用“結果”説話,圖不行,就是不行。
咒語水平不行會限制模型能力的施展。上手一個新模型,對“咒語”的使用會有個“適應期”。
對模型的熟悉程度,也影響咒語水平。
不同模型,咒語手法有所不同。比如,Midjouney上的部分經驗是可以用在“紫東太初”上,但不能完全照搬。
就算同一家公司的模型,不同版本(比如版本升級),也可能會讓“施咒者”從熟練變得生疏。
對紫東太初大模型的評價:
本質上講,這不是一個大模型測試。
我們甚至也無法做出橫向比較,用私有數據微調過的模型,只用了這一個。
我們幹這件事情的目的是希望用“紫東太初”大模型做幫手,增大產量,更快出品。
看它能從多大程度上,成為“新同事”。
以目的作為評價標準,我們認為紫東太初微調版本的模型有以下特點:
1. 和Midjourney有差距,但也有自己的特色。
2.配色水平不錯,微調模型的數據是黑白線稿,所以配色能力來自於基礎大模型。但是,顏色豔麗的高飽和色的配色水平容易翻車。
3.遠景背景的生成水平出乎意料,尤其對四字成語或者四字形容詞有一定的理解力,四字成語做提示詞效果不錯。比如萬家燈火,深邃廣袤。
4.特有的“留白”意境,給模型留下想象空間。
讓模型根據學到的知識,自動完善圖片。(比如,自動上色配色,比如,設計人物動作)
如有必要,我們會拿出更多的數據,進行下一次微調。
所以,這篇文章也許會出後續。
最後,還是那句話,人不會被AI取代,而是不會用AI的人才會被取代。
One More Thing
給AI工程師的悄悄話:
第一件事,整理數據。
雖然是提着“餃子餡(私有數據)”上門,但是標註好的數據,仍然需要再次清理,轉化成需要的格式,去掉圖片標註內容中不需要的數字。
第二件事,微調。
一般而言,小樣本的微調,模型學習幾遍就學會了。
過程是,手寫模型訓練工程代碼,調整學習率等參數,調整“凍結和放開”的參數,紫東太初是多模態大模型,需要激活模型不同區域。
微調過程中,需要“平衡”模型的融合性。
既不能讓模型過度訓練,從而導致原有信息喪失(遺忘舊知識),也不能因訓練不足夠而沒有學會。
多模態大模型涉及語言和視覺模型,為了保證模型均衡性,同時進行動態調整。
訓練過程中,根據樣本的數量,樣本學習的難易程度不同等因素,需要調整語言和視覺大模型學習時間。
比如,某一領域數據量較少,學習過程中出現語義偏移,模型總在重複學習一類東西,會把之前學習的內容給忘了。我們的這次微調,語義學習的時間短,信息量在圖裏,所以要多學圖片。語義學習的時間短,視覺學習長。
第三件事,測試。
第四件事,部署服務上線,Gradio快速生成應用。
然後,就沒有然後了。
