城市5000高速3000落地NOH,中國智駕方案成本新低!_風聞
量子位-量子位官方账号-10-11 19:36
賈浩楠 發自 副駕寺
智能車參考 | 公眾號 AI4Auto
自動駕駛圈,竟也捲成這樣!
3000元,比一次高檔汽車貼膜服務,或一個洗車店年卡更便宜…
但它是現在最新量產L2+智能駕駛底層套件的成本價——

3000元,帶1個前視相機、4個魚眼相機、2個后角雷達、12個超聲波雷達,算力5TOPS。能實現的卻是高階行泊一體智駕功能。
包括高速、城市快速路上的無圖NOH (領航輔助) ,短距離記憶泊車。
系列產品還有5000、8000元版本,分別搭載不同價位車型,實現城市NOH功能。但同樣突出超高功能體驗下相對的超輕傳感器方案、超低算力需求。

不是期貨,而是明年就量產上車的現貨。
L2++體驗的入門門檻被捲到3000元成本,行業前所未見。
智駕落地新“卷王”,不是新面孔,而是之前業內一直有“最懂量產自動駕駛”之名的毫末智行。
智駕新卷王,高階智駕極致性價比
量產智駕系統市場上很多,但在2023年這個時間點,明確區分“高階”的,是是否具備領航輔助功能,也就是常説的NOA能力。
在領航輔助功能開啓下,ADAS自主識別車道線、路上的其他目標,包括紅綠燈在內的交通標誌,實時制定駕駛策略。
最重要的,是根據導航信息自助規劃路線,包括什麼時候進出匝道、何時離開環島,什麼時候準備變道轉彎等等。

簡單的理解,就是用户不用直接承擔駕駛任務,只作為安全員,負擔大大減輕。
根據落地場景的複雜程度,NOA又分成高速和城市兩種,對應着不同的方案和成本。
毫末智行的相關產品,叫做NOH。毫末智行董事長張凱,剛剛在AI Day上發佈了支持量產NOH功能的最新智駕硬件方案產品。

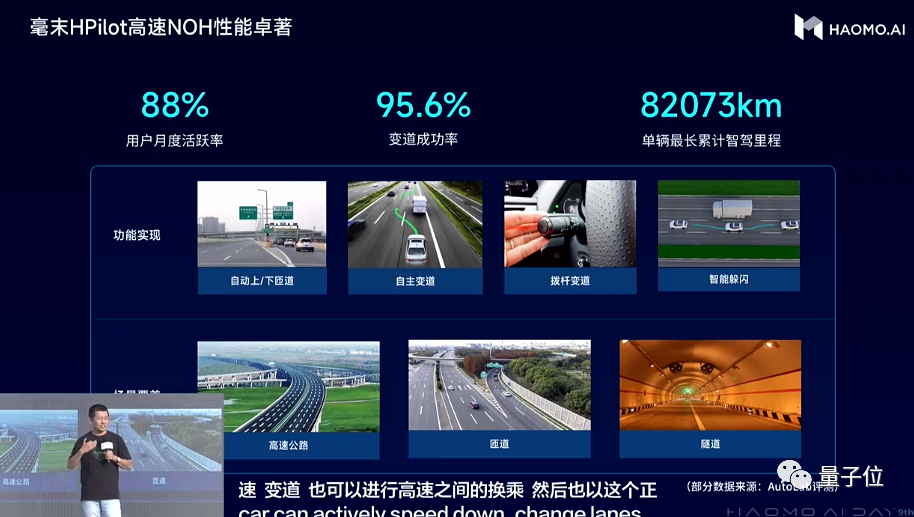
最大的特徵,總結成一句話:高速NOH起步標配,極致性價比前所未有。
HP170,成本3000元級“極致性價比”智駕硬件方案,但其實在行業平均水平中已經實現了高階的功能能體驗。實現高速上和城市快速路上的NOH功能,以及自主泊車能力,而且比常見的量產方案更近一步。
高速或城市快速路NOH,不依賴高精地圖;而自主泊車能力,支持短距離記憶功能。
不依賴高精地圖意味着更廣泛更快速的城市能夠解鎖NOH;記憶泊車,則大大方便了有固定車位的用户。
硬件配置上,算力5TOPS,傳感器方案標配1個前視相機、4個魚眼相機、2個后角雷達、12個超聲波雷達,靈活選裝1個前視雷達和2個前角雷達。
毫末HP370,5000元級,實現的功能同樣是“極致性價比”。除了高速、城市快速路的NOH,還支持城市內的記憶行車功能。泊車層面也有升級,實現免教學記憶泊車、智能繞障。

城市內記憶行車,就是今年流行的“通勤NOA”功能:系統可以通過訓練,記住你常走的上下班路線,實現這一特定路段上的高階領航輔助。這也是在成本和法規限制下,瞄準最高頻需求推出的高階智駕落地方案。
HP370底層算力32TOPS,傳感器方案標配2個前視相機、2個側視相機、1個後視相機、4魚眼相機、1個前雷達、2個后角雷達、12個超聲波雷達,靈活選裝2個前角雷達。
最後還有一個HP570,可實現全場景城市無圖NOH、全場景輔助泊車、全場景智能繞障、跨層免教學記憶泊車等功能。
功能拉滿,體驗最強,實現了“從P檔到P檔”的智能駕駛能力。這樣的量產智駕天花板方案,之前在業界至少是數萬元成本,毫末的“極致性價比”體現在官宣成本為8000元。

算力可選72TOPS和100TOPS兩款芯片,傳感器方案標配2個前視相機、4個側視相機、1個後視相機、4個魚眼相機、1個前雷達、12個超聲波雷達,還支持選配1顆激光雷達。
簡單科普一下智能駕駛量產落地目前的普遍情況:實現高速NOH,一般供應商方案至少需要20TOPS起步,平均數十TOPS的算力支持,傳感器方案,也都在視覺和毫米波之外標配至少1個激光雷達。
而上升到城市NOH功能,則至少是254TOPS算力的英偉達Orin芯片起步,有的還要數顆,傳感器一般是前向及補盲激光雷達至少3顆。
毫末智行董事長張凱這樣評價這些方案:
毫末第二代HPilot的三款智駕產品把價格打到了3000元級、5000元級、8000元級的極致低位,同時性能都打了上去,讓輔助駕駛產品成為最平民化的日用級消費品.
中低階智駕便宜更好用,讓高階智駕好用更便宜
所以毫末量產智駕硬件方案的最大特徵,也是行業“卷王”級成本的直接原因,就是擺脱了重傳感器依賴,也自然用不到過大的算力支持。
但這種方案能保證可靠,並且達到量產條件的根本原因,還是要從毫末CEO顧維灝一季一度的AI Day“自動駕駛前沿技術分享”中找答案。
毫末為什麼捲成這樣?
毫末智行量產智駕硬件方案的最大不同,是無論3000、5000、8000元級的產品,激光雷達都是“非必要不增加”,突出以視覺為主的智能駕駛能力。
而激光雷達省下來的,不光是傳感器採購的直接成本。
激光雷達除了貴(一個幾千元),另一個不理想之處是其產生的點雲圖數據量大,回波噪聲不好抑制,需要佔用系統大量的計算資源。

想要低算力實現高功能,又不增加額外成本,就必須要在視覺能力上取得突破。
毫末給出了這樣的直觀數據。
截止目前,共計篩選出超過100億幀互聯網圖片數據集,和480萬段包含人駕行為的自動駕駛4D Clips數據(帶有時間特徵的連續視頻片段),總學習時長超過103萬小時。
乘用車用户輔助駕駛行駛里程已經接近9000萬公里。注意這不是模擬仿真訓練里程,而是毫末智行已經量產上車的產品,由用户實際使用產生的高價值數據。

上一次毫末公佈相關數據是在200多天以前,學習時長和用户實際使用里程還分別是56萬小時和4000萬公里。
毫末在量產智駕方案上的快速降本捲到極致,本質是視覺自動駕駛能力的迭代進步。而迅速從行業內卷中脱穎而出,拿出史無前例的性價比方案,説明毫末AI能力進步的“加速度”已經今非昔比。
“大模型”引入自動駕駛,是核心原因,當然毫末依然是行業第一家。
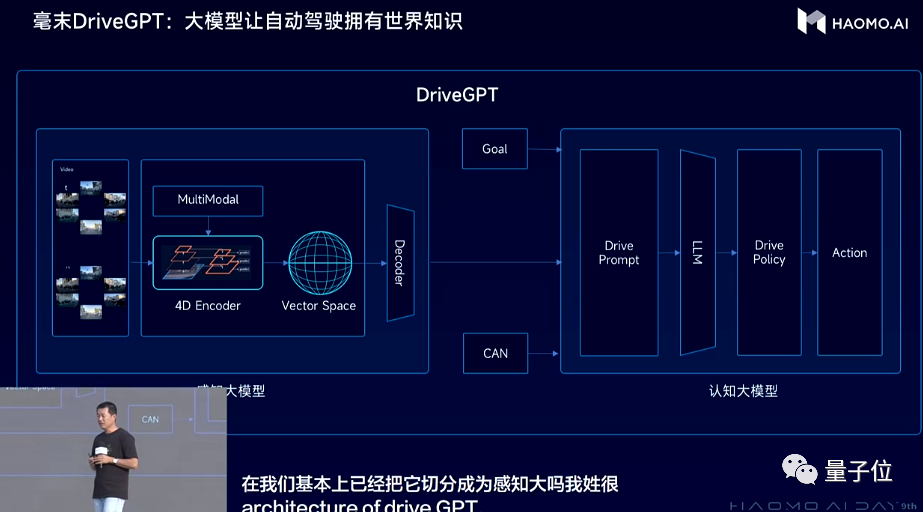
DriveGPT,中文名雪湖·海若,是毫末的自動駕駛大模型技術體系。
DriveGPT在今年初提出來,是首先應用於自動駕駛認知決策模塊,採用的是生成式預訓練思路,只不過訓練的數據從語言文本,變成了圖片、視頻等等自動駕駛數據。
實現過程分為3步:
首先在預訓練階段引入量產智能駕駛數據,訓練出一個初始模型,相當於一個具備基本駕駛技能的AI司機。
然後再引入量產數據中高價值的用户接管片段(Clips形式),訓練反饋模型。而不同Corner Case的依次迭代,相當於針對不同駕駛任務挑戰分別強化AI司機的技能。
接下來就是通過強化學習的方法,使用反饋模型不斷優化迭代初始模型。
所謂“生成”,反饋模型能夠實時根據當前交通流情況,生成不同的針對性場景,訓練初始模型。而完成迭代後,模型也能對同一任務目標生成不同的策略方案。

DriveGPT參數1200億。DriveGPT模型本身始終部署在雲端,直接“上車”還需要時間。但大模型本身可以對自動駕駛數據挖掘和訓練起到加速作用,同時也能通過駕駛決策模型參數、效果的擬合學習,直接對車端用户,價值卻是能夠快速兑現。比如生成式模型能夠做到智能捷徑推薦、困難場景自主脱困、智能陪練等等。
公佈200多天,DriveGPT又有了新的技術層面進展,這也是理解毫末“卷王”的核心。
視覺感知網絡架構,從之前ViT(Vision Transformer)為代表的大模型,升級到性能更強大的Swin Transformer大模型。從訓練範式上,毫末率先採用基於大規模數據的自監督學習訓練範式,採用Transformer大模型輕鬆“吃下”上百億的圖片,模型變得見多識廣,泛化能力極強,逐漸可以識別萬物。
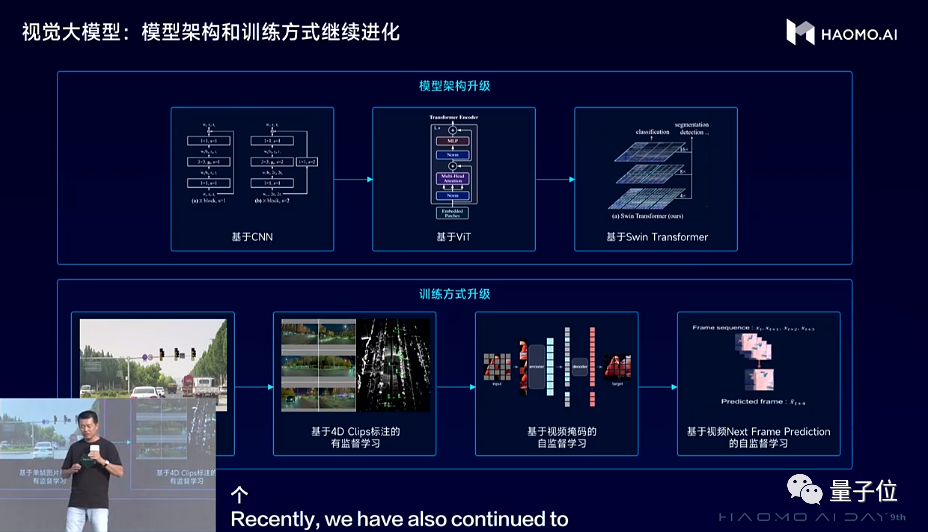
現在,最新的大模型是採用視頻生成的方式來訓練,通過預測生成視頻下一幀的方式,來構建4D表徵空間,使得CV Backbone能夠學到三維的幾何結構、圖片紋理、時序信息等全面的物理世界信息,相當於把整個世界裝入到神經網絡當中。
在視覺感知模型的架構、訓練流程更新之外,毫末還做了一件事,就是引入外部的大模型,使得自動駕駛在感知和認知層面,具備通用能力,可以識別萬物,具有世界知識,能力媲美人類老司機。
感知模型方面,引入NeRF技術,通過預測視頻下一幀的自監督方式來構建4D編碼空間,即將一個Clips序列的前K幀的部分輸入模型,用NeRF(神經輻射場)渲染出後續H幀。
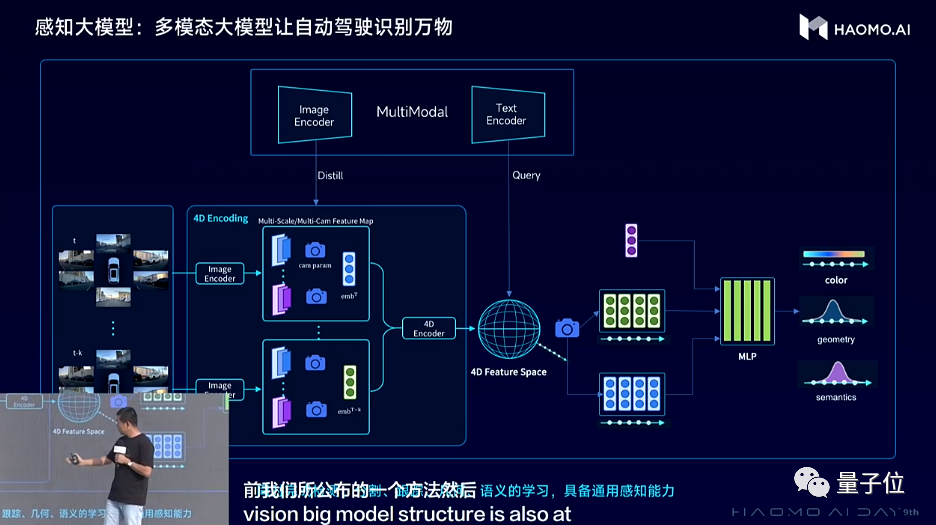
這樣通用感知大模型就可以分為3個關鍵的模塊:4D編碼器、多模態教師、NeRF渲染器。其中,4D編碼器將視頻中的時空特徵編碼到一個4D特徵空間裏;多模態教師模型是一個預訓練好的多模態大模型,可以將視覺特徵對齊到文本語義特徵。
NeRF渲染器則通過預測未來視頻的方式,用來監督4D 特徵空間中對世界的感知能力。通過這種方法,毫末DriveGPT構建起更有效、更見多識廣的自動駕駛通用感知大模型,實現在一個模型中同時學習到空間的三維幾何結構、語義分割和紋理信息,具備識別萬物的能力,也由此更好地完成目標檢測、目標跟蹤、深度預測等各類感知任務。
認知層面,一個老司機不僅僅只會操控汽車,還必須具備人類社會的常識,懂得這個世界的普遍規律,或者説世界知識。但這種世界知識僅僅通過自動駕駛數據是難以學到的,而大語言模型LLM已經學習並壓縮了人類社會的全部知識,所以引入大語言模型來輔助駕駛決策是一個非常有效的途徑。
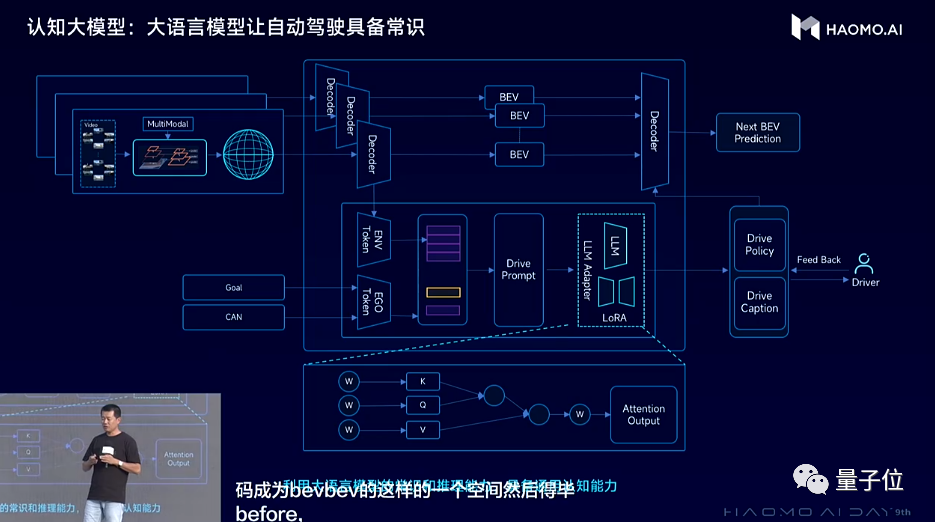
為了讓LLM更好地適配自動駕駛任務,毫末採用自動駕駛行業數據,對LLM進行了微調,使得LLM能看懂駕駛環境、能解釋駕駛行為,做出更優的駕駛決策。
這樣,認知大模型除了獲得感知大模型看到的物理世界信息之外,也能像老司機一樣具備社會常識、知道這個世界各種現象背後的物理知識,從而像老司機一樣駕駛。
這些技術層面的創新,讓毫末的模型結構、訓練方式,以及對世界理解認知層面能力提升,而服務的主要對象,是視覺感知能力,也實實在在的反應在量產方案的降本增效上。
比如將視覺感知能力引入到泊車場景中,並結合視覺BEV的感知框架,使毫末視覺感知模型使用魚眼相機可以識別牆、柱子、車輛等各類型的邊界輪廓,形成360度的全視野動態感知,可以做到在15米範圍內達到30cm的測量精度,2米內精度可以高於10cm。這樣的精度可實現用視覺取代USS,從而進一步降低整體智駕方案成本。

再比如,毫末城市NOH可以在城市道路場景中,在時速最高70公里的50米距離外,就能檢測到大概高度為35cm的小目標障礙物,可以做到100%的成功繞障或剎停。這就是擺脱激光雷達依賴的一個體現。
為什麼毫末能在量產商業化上捲到如此程度?
毫末智行CEO顧維灝給出的解答是:
大模型、大數據、大算力,成為自動駕駛公司邁入3.0時代的關鍵標誌。在感知階段,通過海量的數據訓練感知基礎模型,學習並認識客觀世界的各種物體;在認知階段,則通過海量司機的駕駛行為數據,來學習駕駛常識,通過數據驅動的方式不斷迭代並提升整個系統的能力水平。
很慶幸,毫末從一開始就在為自動駕駛3.0時代作準備。在感知、認知、智算中心的建設上,毫末都是按照數據驅動的方式建設的
與主機廠緊密的聯繫讓毫末對工程化、成本控制理解深刻,敏鋭的捕捉自動駕駛最先進最前沿技術,並率先落地應用。
如何評價?
毫末智行如今要加上一個新的標籤:落地最卷的自動駕駛公司。
之前它有“量產自動駕駛第一名”的評價,現在也正在代表着量產自動駕駛產品方案、落地趨勢的benchmark:
Transformer的引入和計算基礎設施建設的成熟,使高階智能駕駛落地競爭,由獨特價值提供,轉向增量價值的競爭。
毫末迅速適應了這樣的變化拿出3000元成本的產品,意味着用户端可以在20萬以下甚至10萬級的乘用車上標配高階智能駕駛,真正享受黑科技的紅利。所以是高階自動駕駛開始普及的信號和里程碑。
毫末智行本身,成為量產自動駕新卷王,核心原因是它代表了自動駕駛最先進前沿技術的應用方向。從最早引入Transfomer、到大模型率先應用,以及現在在訓練端引入類似LoRA圖片生成模型之類的技術……這些技術在毫末這裏,還能快速產生價值,反應在落地量產的產品迭代中。
這也讓毫末一季一度的AI DAY,成為了自動駕駛技術方向上風行標性質的活動。

不誇張地説,如果想要保持對自動駕駛技術最核心的關注,最高效的方式就是關注好毫末每個季度的AI DAY。
之前還有特斯拉AI DAY、自動駕駛日,但因為今年的跳票,業內響亮的“學習機會”就只剩毫末了。而在背後更加值得注意的,是毫末智行代表的自動駕駛技術體系的變革,正越來越深刻的理解並應用大語言模型的範式和具體思路。
自動駕駛的GPT時刻、iPhone時刻正在隱隱轟鳴。
這樣的轉折,可能並不是在實驗室中實現然後再向用户推廣。更有可能是毫末、特斯拉這樣的漸進式量產自動駕駛玩家,在持續的交付和迭代的商業運營過程中率先突破。