訊飛星火:整體超越ChatGPT,醫療超越GPT4!一手實測在此_風聞
量子位-量子位官方账号-10-24 21:17
楊淨 發自 凹非寺
量子位 | 公眾號 QbitAI
整體超越ChatGPT,醫療全面超越GPT-4!
五個月之後,在科大訊飛全球1024開發者節現場,劉慶峯如約而至兑現諾言,並給出新的Flag:
2024年上半年對標GPT-4!

不光訊飛最強星火大模型來襲,七大維度全面升級,尤其是多模態、代碼生成以及複雜推理的能力,還能生成符合自己人設的AI助手。
除此之外,還有科技文獻大模型、醫療大模型以及同其他企業合作的12個行業大模型一併發佈。
以科技文獻大模型為例,它可以一分鐘就能整合18篇論文,生成一篇5頁的綜述報告。
還能直接生成論文中提到的代碼。
醫療大模型也正式公開,化身每個人的健康助手,進行自查、用藥指導以及檢查/體檢報告解讀,並首發**“訊飛曉醫”**APP及小程序。
在底層基礎設施上,訊飛華為再次聯手,發佈基於昇騰生態的“飛星一號”平台發佈。
正如劉慶峯所強調的那樣:唯有自主可控,才有生生不息的未來。

全面對標ChatGPT、醫療超越GPT-4
既然如此,當初的Flag都實現了嗎?
首先就星火大模型V3.0本身,我們自然進行了第一手的實測。
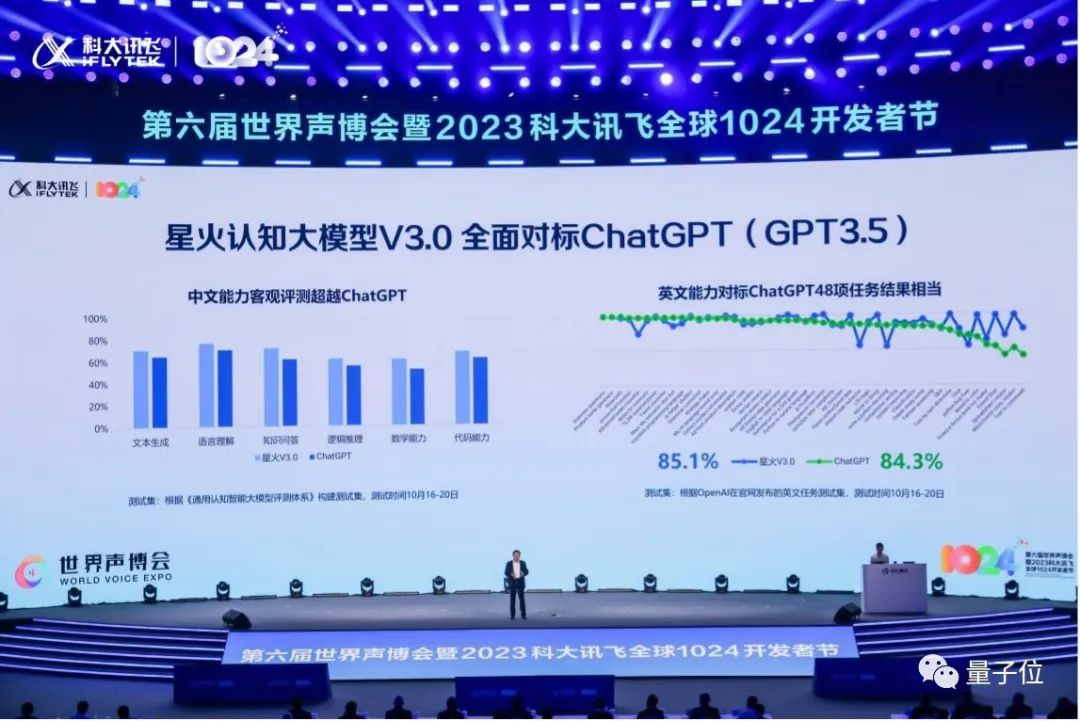
據介紹,此次七大能力持續提升,並且全面對標ChatGPT。尤其像中文能力客觀評測上超越ChatGPT,在醫療、法律、教育等專業表現也格外突出,還有在代碼項目級理解能力、小樣本學習、多模態指令跟隨與細節表達等能力有所提升。
並且此次還新增了虛擬人格功能,它可以根據性格模擬、情緒理解、表達風格來形成一個初始人設,再結合特定知識學習、對話記憶學習,形成一個更個性化的AI人設。
既然如此,那麼第一波就來考驗一下它的基本功。
理解能力。
比如一些只在中文語境下才能get到的網絡梗,沒想到星火與時俱進直接get。
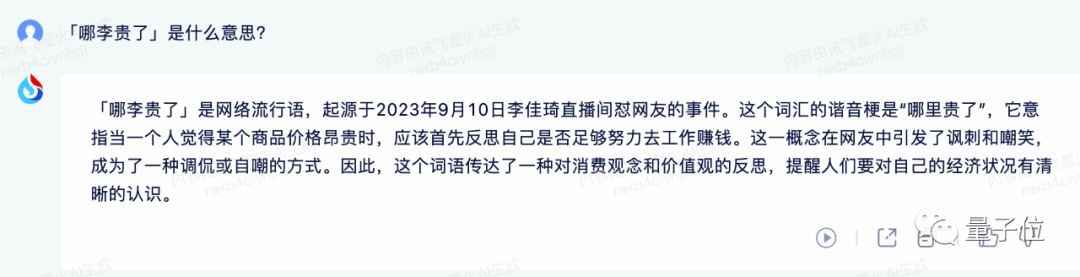
就連昨天的消息也都知道。

接下來第二波進階,也是最能考驗大模型真正實力的代碼生成能力。據介紹,目前訊飛星火代碼能力已經超過ChatGPT,但略遜於GPT-4。

既然如此,就來實際評測一下(提示詞故意有點語病):
你現在頂級程序員,請寫出Resnet神經網絡代碼,並給出每一段代碼的解釋。
首先兩者都正確識別了問題,給出的代碼表現基本一致。
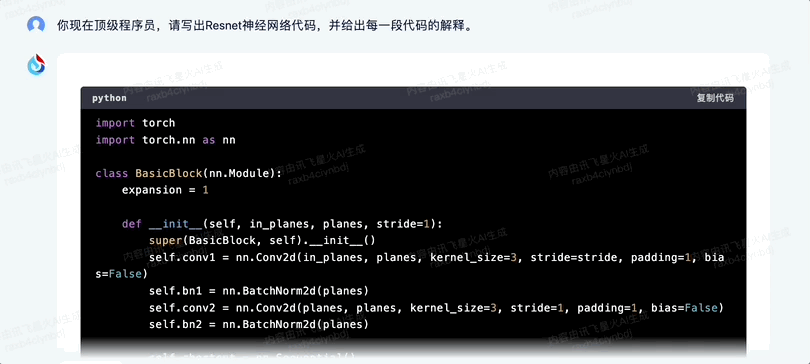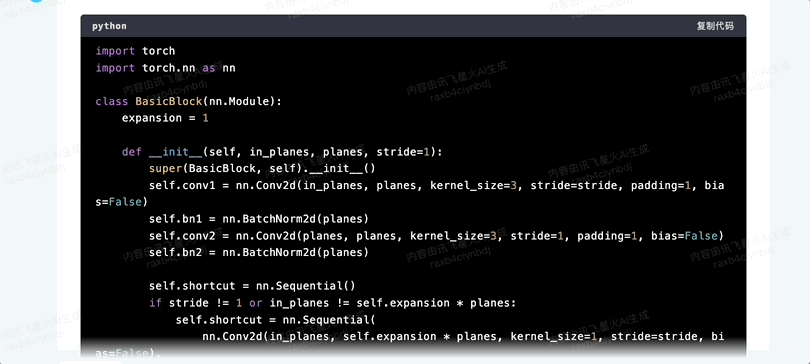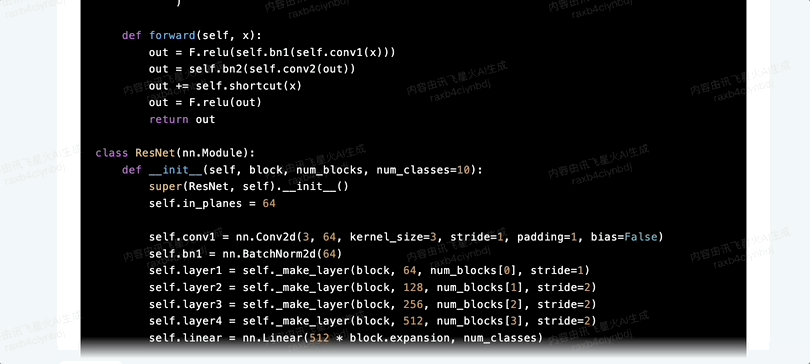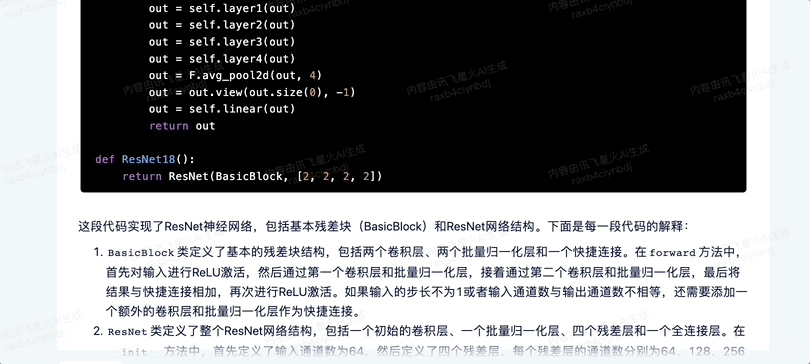
訊飛星火的回答直接分成了代碼部分和解讀部分。

而GPT-4的回答,直接將代碼部分拆分並解釋,這樣方便代碼修正和學習。
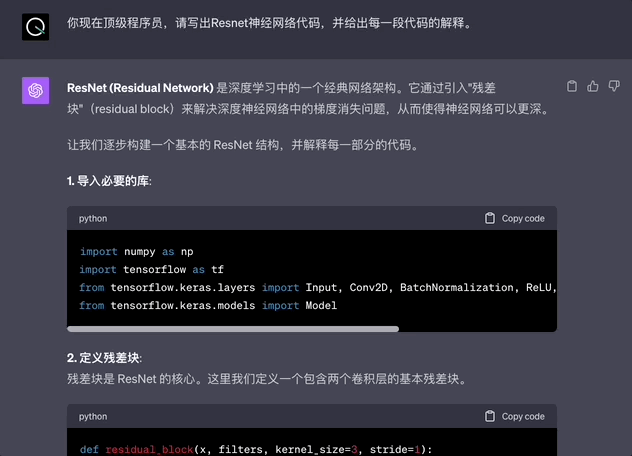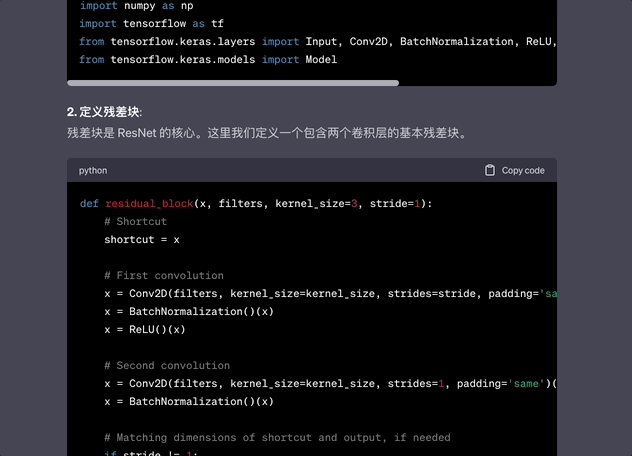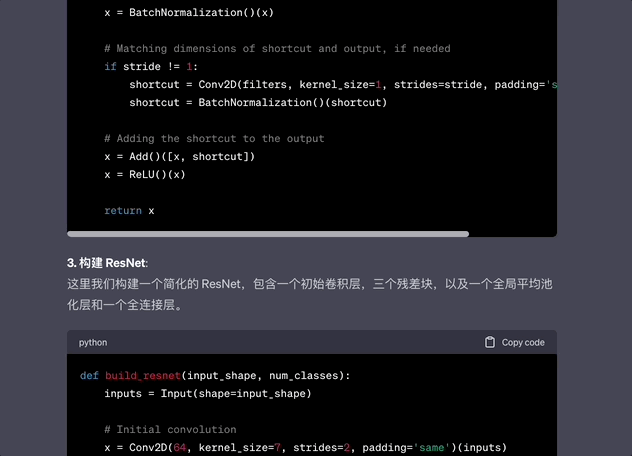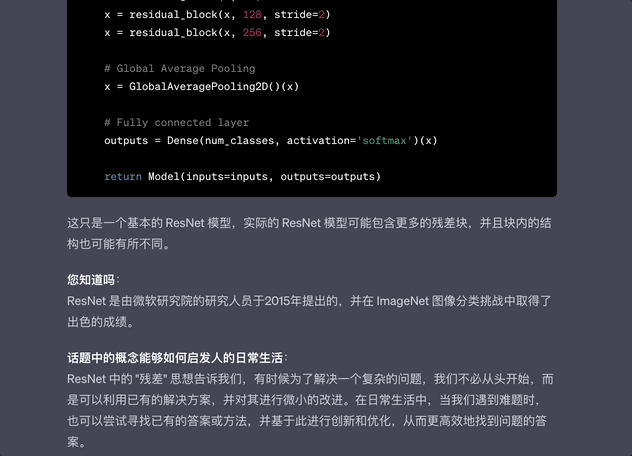
最後,再來看看新晉的看家本領——多模態生成能力。
請根據「黃河遠上白雲間,一片孤城萬仞山。」畫一幅畫。
這一來考驗對中文詩詞的理解能力,二來考究的是大模型對空間感知的能力。
 ****△訊飛星火回答截圖
****△訊飛星火回答截圖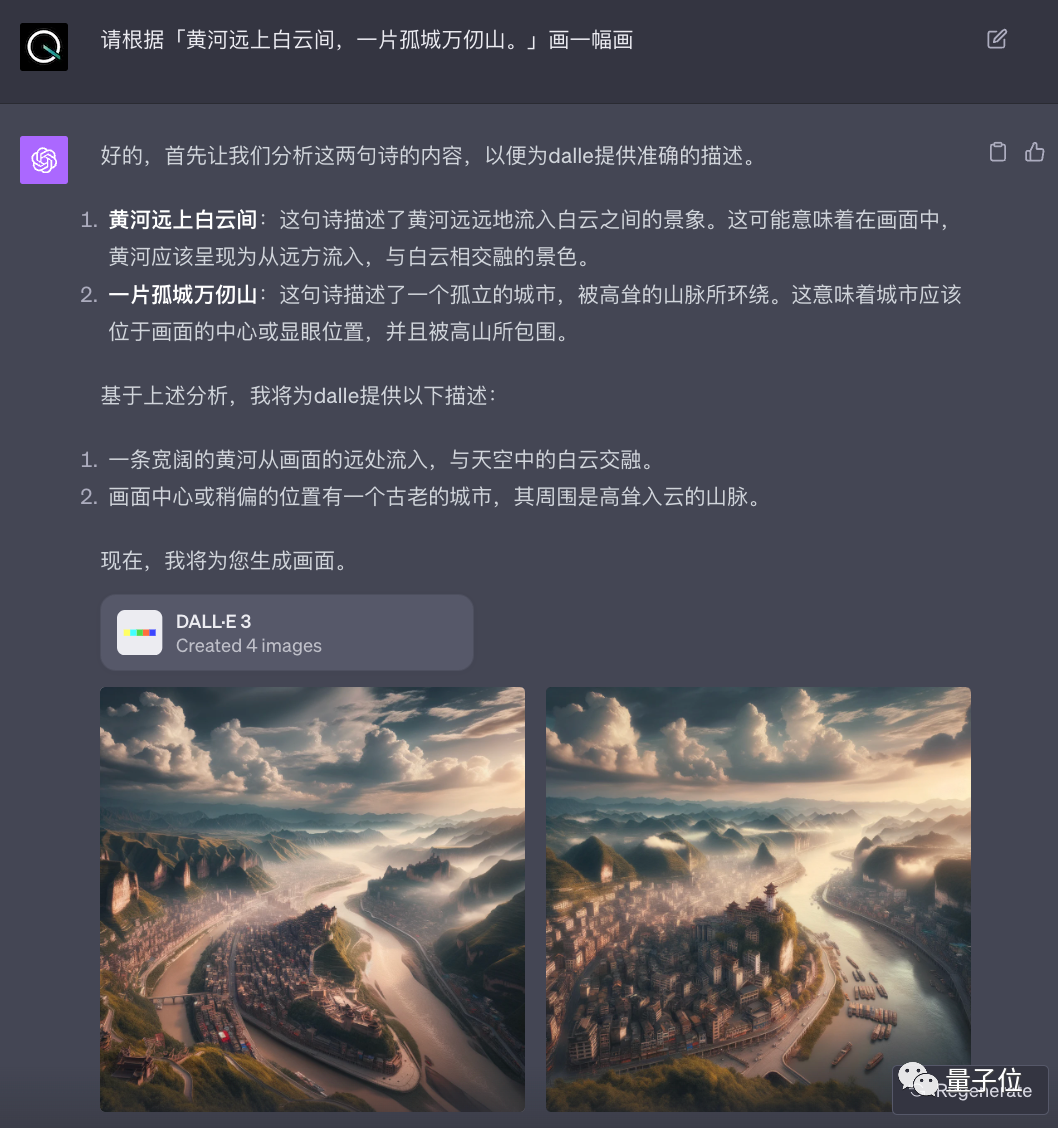
**△**GPT-4(部分回答截圖)
可以看到,訊飛星火繪製的畫不僅理解來中文古詩詞的內容,畫風也是更具有古色古韻,而且巧妙地將黃河、白雲和孤城在整個空間裏組合在一起。
而GPT-4則將孤城直接理解成了城市,畫面也是更為現代感……
大模型AI人設這塊,這也是此次發佈的重點更新。可以看到在「發現友伴」這一功能上有近20種AI人格可供選擇,包括像馬斯克、林黛玉、哪吒、於大爺、櫻花木道、秦始皇等等。
比如像這位硅谷鋼鐵俠,一上來腦子裏全都是地球保護、殖民火星那些事兒。

還有像林妹妹,説話語氣裏帶有些許婉轉詩意~

據劉慶峯介紹,這一功能上線12小時,已有3000+人設由開發者自創。
此次大模型的專業性上也有所提升,比如在醫療領域,問上這樣一個常識問題。
我24小時尿量<100毫升,我怎麼了

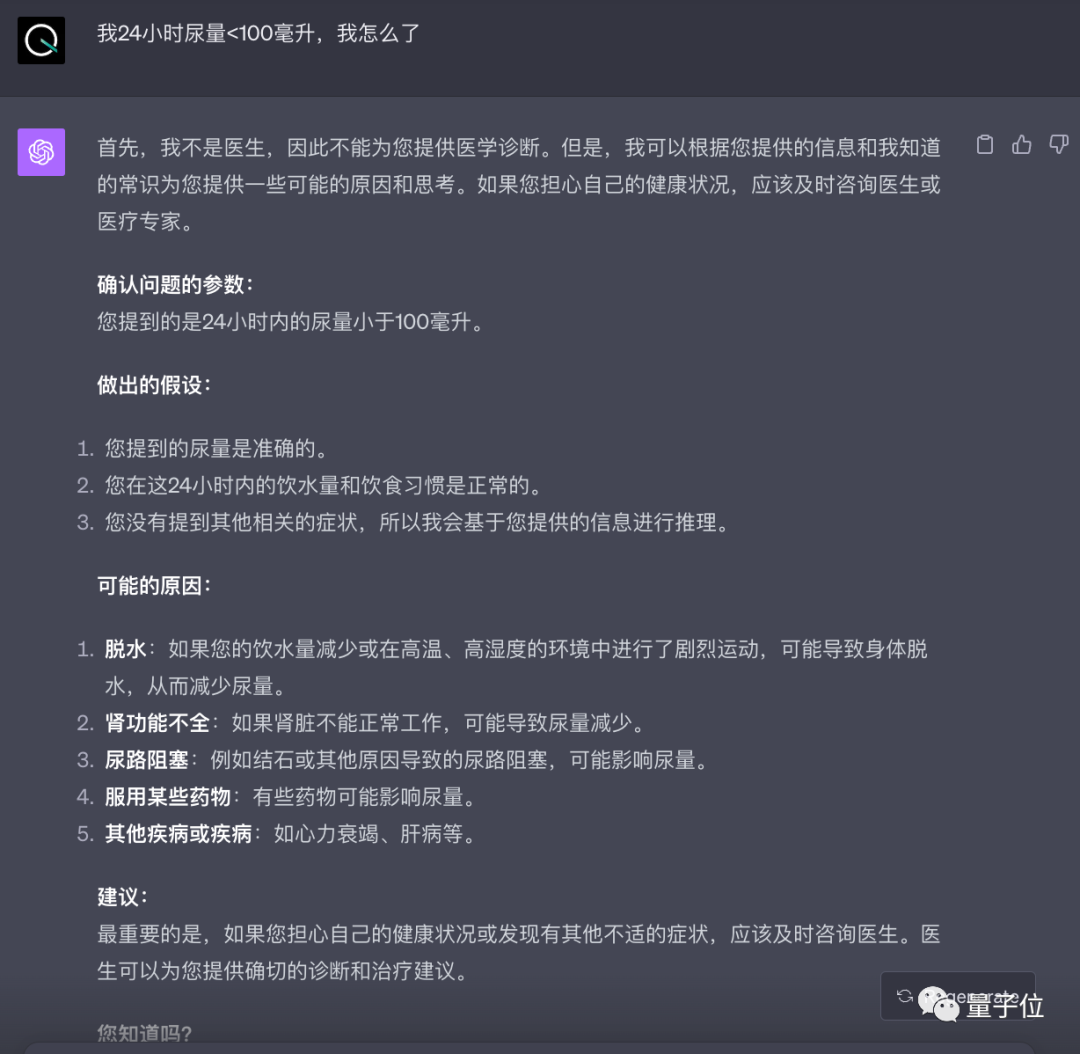
可以看到,在「可能的原因」上雙方的回答基本一致。訊飛星火風格則簡單直接,還給出了「嚴重性」提醒。而GPT-4更為完備一些。
最後再來簡單總結一下測評結果:
基礎能力:語義理解、時效把握以及代碼生成能力上都有很大的提升;
多模態生成表現不錯,尤其在空間感知能力的表現;
個性化上也有人格表現,但會出現原形的情況;
專業性表現也基本無事實性錯誤,尤其醫療能力水平,給出適時診療提醒。
每個人的AI助手時代正在到來
除了星火大模型本身,此次科大訊飛1024開發者節可謂是乾貨滿滿——
不光有編程產品iFlyCode、科技文獻大模型、醫療大模型等這些垂直領域大模型落地應用;還有同與行業龍頭共創12個行業大模型、10萬家企業用户,通用大模型產業生態初見雛形;另外,超腦計劃2030也在有序進行。
可以説是眼花繚亂了。

但細細梳理不難發現,這些進展其實圍繞着一個底層邏輯——
每個人的AI助手時代正在到來 。
正如劉慶峯在發佈會上所強調的那樣。這也是科大訊飛基於大模型技術發展的趨勢理解。
ChatGPT剛出現時,就曾探討過以ChatGPT為代表的大模型產品強大之處在於同時具備知識、推理和溝通能力。
一方面,這是實現認知智能必備的幾項能力;另一方面,也是個人AI助手場景相契合。
前者是科大訊飛一直以來的技術深耕,後者則是科大訊飛在工業、科研、醫療、教育、智能汽車,甚至超腦計劃的最終落地形態。
以教育為例,科大訊飛就認為目前教育「因材施教」進入到第三個層次:類人式對話輔導,進行逐層講解。
基於這樣的邏輯,從科大訊飛半年落地成果,也就能從中窺見大模型發展一二。
首先是應用和業務場景。
科大訊飛認為,大模型賦能首要就是工業和科研。而要賦能工業,則首先要賦能代碼。
iFlyCode**。**
8月15日iFlyCode發佈以來,已有62萬開發者應用、107家機構深度應用。
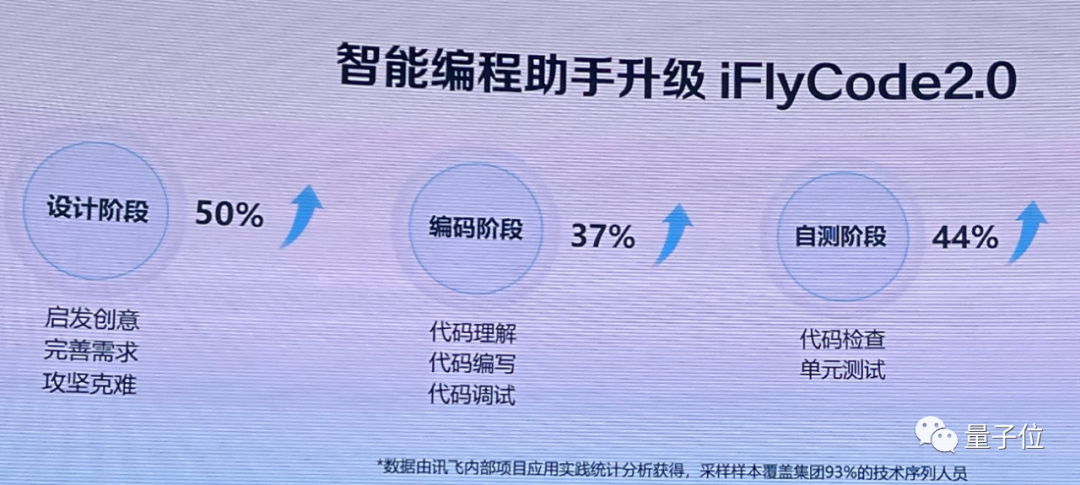
比如“智慧教育大屏”性能優化,傳統方案需要15天解決,在iFlyCode輔助下只需7天。
本次iFlyCode2.0在設計階段、編碼階段、自測階段都有一定的升級。
科技文獻大模****型。
同中科院知識文獻中心合作,有着包括成果調研、論文研讀、學術寫作、生成論文代碼、潤色、學術翻譯等功能,可以化身當下高校研究生的科研小助手。
給一篇中文文獻,結果一鍵就能生成英文版。

還能與時俱進、補充跨領域知識,比如一篇大模型文章,問到ChatGPT發展歷程,還補充了現下GPT-4的發展。
醫療大模型。
它能根據體檢報告、檢查報告進行解讀。
傳統體檢報告一般會有單項解讀,以及像複查這種比較粗放的結論。而訊飛曉醫不光給出具體指數指標,還會主動詢問最近身體情況,聯合各個單項結果並更新風險等級。

還可以根據藥品照片、自身情況,給出用藥建議,比如禁忌、推薦等。
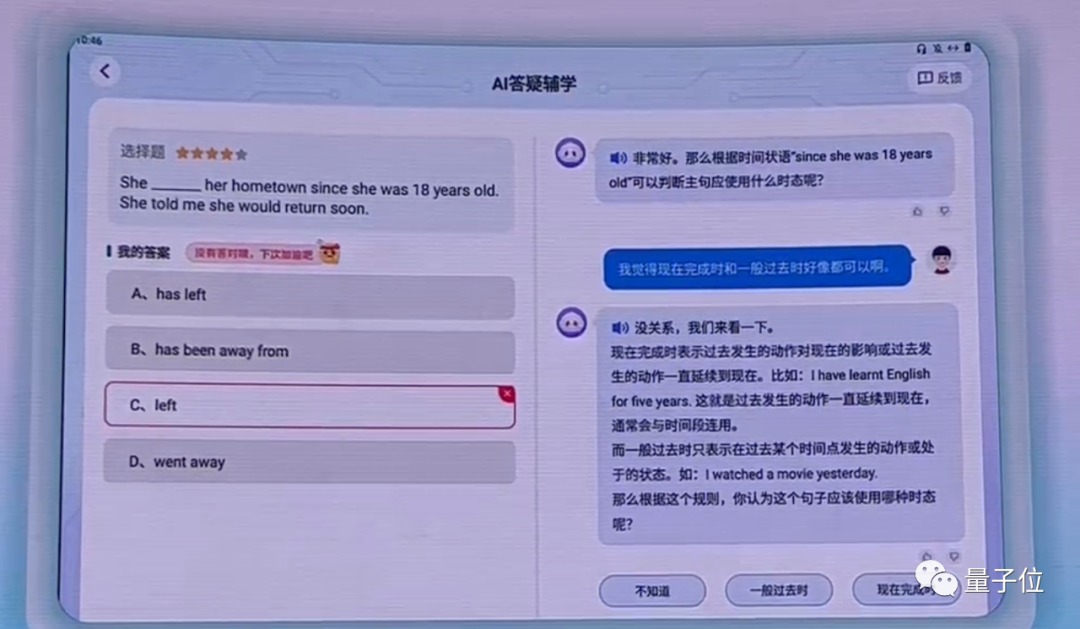
除此之外,還有科大訊飛歷來深耕的教育領域,訊飛AI學習機升級了英語AI答疑賦學;同科普中國一起合作發佈科普大模型;還打造了AI心理夥伴等等,因材施教已取得規模化應用成果,在全國50000+所學校深度應用。
當然,這些進展其實都是加速訊飛超腦2030計劃一部分——懂知識、善學習、能進化、讓機器人走進每個家庭。
AIBOT去年發佈以來,已為工業、教育、服務等領域372家企業提供服務。
中國玩家大模型加速度優勢明顯
不可否認的是,以星火大模型等為代表的國產大模型,在確定性方向上發展優勢明顯。
並且同樣保持着同樣明顯且持續的加速度。
已經形成全球共識的,當前大模型發展已經進入到第二階段——
大模型AI產品從炒作、演示Demo、到真正的價值導向,用户導向、場景導向。
像微軟谷歌亞馬遜在內的全球巨頭,卻面臨增長的煩惱:不僅不賺錢,還要倒貼。
以AI編程工具GitHub Copilot為例,微軟平均每個月在每個用户身上都要倒貼20美元,最高能達80美元。
箇中原因,用户找不到為大模型產品付費的理由。
更本質一點來説,大模型尚未發揮出最大的價值效能。
在這一方面上,中國玩家正在展現出自己的產業發展優勢,並且優勢明顯。
有場景。前一波技術浪潮,AI能落地到千行百業,大模型技術同樣也能落地千行百業。一方面,我國有着全球最完整的產業體系,為大模型的落地應用提供了廣闊的創新空間;另一方面,在一些場景中,我國還有着不同於其他的獨特優勢。像教育、醫療,要實現真正的全民普惠,對技術其實提出了更高的要求。
有數據。數據的價值,從未像今天這樣受到前所未有的關注。場景數據質量的好壞,直接決定了大模型的性能表現。
此前國內AI應用,已經有深厚的場景積累。如科大訊飛的認知智能技術已經在教育、醫療、金融、汽車、服務等多個領域落地,並構築起了深厚的行業壁壘。
根據IDC研究顯示,中國數據量規模將從2022的23.88ZB增長至2027年的76.6ZB,複合年均增長速度(CAGR)達到26.3%,為全球第一,為大模型的持續優化提供了海量的數據來源。
有市場。ChatGPT作為通用人工智能的代表,本身不是項好生意。OpenAI商業化只是少數,身處於國內市場大環境下的企業,通用路線往往不是一個最佳選擇。垂直場景應用路線更受國內市場青睞。
有場景有數據有市場,也再次印證中國玩家率先吃到ChatGPT紅利,如今發展加速度明顯。
從科大訊飛的迭代應用速度就可見一斑。

今年2月,科大訊飛首次回應:在搞類ChatGPT產品,並給出確定時間點;
5月,訊飛星火V1.0正式發佈,在語義理解,長文本生成以及數據能力三方面,據稱“已經超過了ChatGPT”,並直接展現五大應用成果。
6月,星火升級至V1.5;8月,訊飛星火V2.0發佈,多模態能力實現。
10月,科技文獻大模型、醫療大模型等12大行業大模型發佈,通用人工智能產業生態初具雛形。
……
當下大模型的發展進入到了冷靜期,每個企業都在思考如何能讓大模型充分發揮價值效能。即便如OpenAI的奧特曼,也在尋找自身第二增長點。
關於大模型的評測和判斷,不再看發佈效率、榜單分數,而是看實際應用、看產業應用生態。
這背後既需要國內底層軟硬生態更緊密的合作——華為昇騰生態“飛星一號”平台發佈。
也需要同行業龍頭、萬千開發者一起共建起通用大模型產業生態。目前關於星火大模型開發者已經有17.8萬,涵蓋各個領域。
大模型時代的序幕才剛剛到來。
好了,對於劉慶峯説的**「明年上半年對標GPT-4」**的Flag,你怎麼看?