馬上雙11,別被AI坑了_風聞
酷玩实验室-酷玩实验室官方账号-11-03 22:57
AI,AI,AI從年初喊到年尾,説實話,除了用AI辦工工具來摸魚外,這兩個字母似乎並沒有掀起什麼波瀾。
不過就在這個雙11期間,估計會有不少人穿上AI設計的衣服。
 先看幾張圖。
先看幾張圖。

對於上面兩張圖,大家有沒有發現什麼端倪?
第一眼看上去,是兩個漂亮的模特在T台上展示國風毛衣。但如果仔細看,就會發現一些不同,比如多出來的一雙手和台下觀眾極度扭曲的面部,非常嚇人。

圖片來自網絡

圖片來自網絡
別怕,這並不是時空扭曲的科幻片,只是AI在作祟。
目前在電商平台上,利用AI技術來生成模特已經不是個例,只要隨便一搜國風毛衣的關鍵詞,就會出現一堆類似的唯美的模特上身圖。
電商平台搜索截圖
當然,不只是模特,附着在這些模特上的衣服也是由AI生成的。話又説回來,這些衣服實際上身好看嗎?
AI國風毛衣,翻車潛力巨大在AI模特的助攻下,不少買家都被國風毛衣吸引,不少店家的月銷量都在百****件以上。
 但在收到毛衣後,台上古風古韻的郡主,儼然變成了被人使喚的宮女。不僅色差大,在材質和配飾上,現實版和AI展示的衣服都有着巨大的差異。
但在收到毛衣後,台上古風古韻的郡主,儼然變成了被人使喚的宮女。不僅色差大,在材質和配飾上,現實版和AI展示的衣服都有着巨大的差異。

圖片來自網絡
隨着吐槽越來越多,這些買家已經被網友戲稱為“第一批國風毛衣裙受害者”,雖説買家和AI模特有差別,但色差過大和版型上的不同,才是讓國風毛衣不接地氣的原因。
所以,AI模特為什麼能騙過這麼多的買家?
**接近真人的AI是怎樣練成的?**為了探究現在AI作圖到底進化到什麼地步了,看來只有親自上陣了。
目前流行的AI作圖模式有兩種,第一種是部署在雲算力上的Mid journey,它雖然易用,但擴展性比較差,無法畫出定製化的圖片。就像大家在飯店吃飯一樣,直接點菜,就會做好端上桌,但口味無法進行很大的調整。
所以測試的時候就採用了第二種——Stable Diffusion,這是一種可以運行在自己電腦上的AI,因為一切計算都在本地完成,所以就可以用它繪製一些定製的圖片。這就跟自己做菜一個道理,只要願意,你甚至可以做出宮保雞丁味兒的西紅柿雞蛋。
在Stable Diffusion中,AI模型會根據用户給出的關鍵字,進行繪製。關鍵字分為兩類,一類是你想讓畫面出現的內容,另一類則是你想避免出現在畫面中的內容。所以即使對於AI不熟悉的朋友來講,作圖也不是件難事。
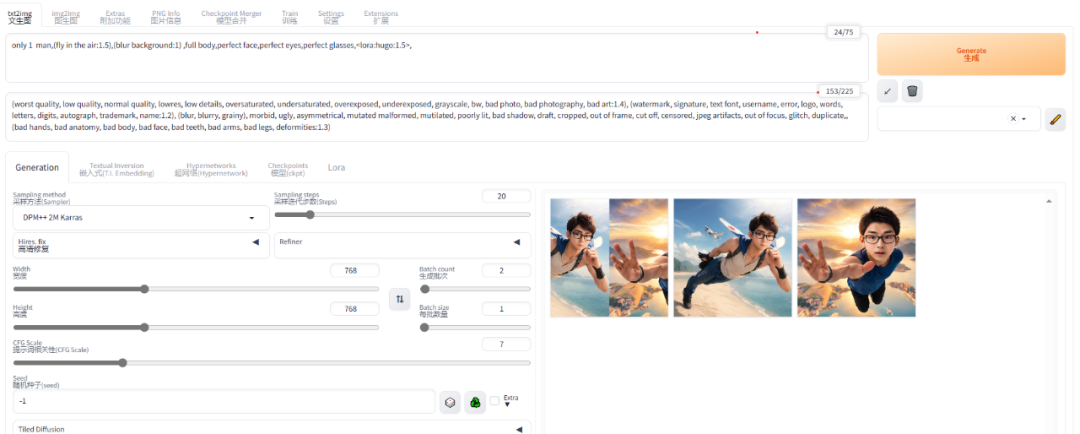
Stable Diffusion WebUI 界面
所以只需輸入:小姐姐,時尚走秀,虛化背景,全身照,漢服,毛衣,國風等一系列提示詞,然後在避免出現處,寫上像6個手指手部等詞語,就可以畫出第一批模特了——噹噹噹!請大家欣賞!

等下,怎麼和電商平台上的不一樣啊?難道是提示詞的問題?在進行多次嘗試後,發現多少還是和賣家圖片有差距。
潛心研究後,發現是我們用的模型的問題,默認的模型就像什麼都會,但又做不好的廚師。我們現在先要吃漢堡,這個廚師能做,但想要好吃,那就難為他了。所以我們現在需要去找一個經過兩年半漢堡訓練的廚師(模型)。
 這下,在輸入關鍵詞,我們就可以得到和國風毛衣差不多的圖片了!
這下,在輸入關鍵詞,我們就可以得到和國風毛衣差不多的圖片了!

之前我們説過,Stable Diffusion運行在本地電腦上的好處就是可以自己訓練,讓它做出任何口味的菜(圖片),所以到這裏,一個大膽的想法出現了——我能訓練我自己麼?
答案是:當然可以。我從手機上隨意找了20張自拍,雖然説各個角度都有照片最佳,但是鋼鐵直男的自拍也不是不能用。經過訓練,AI版的我,就這麼出來了,這個時候給些關鍵字或者跟其他模型結合,就可以繪製好多有意思的圖片。

來自鋼鐵直男的自拍
比如,小鮮肉版本的我,二次元版本的我等等,此時限制我的只有想象力和顯卡了(AI計算需要顯卡)!

小鮮肉

二次元和飛機結合
**AI給賣家帶來了什麼?**其實目前本地訓練的模型不只能做這些,在眾多強大的功能下,還可以控制圖片里人物的姿勢,只要你想,它完全可以做出你想要的動作。
那麼如此全能的AI給賣家帶來了什麼呢?這裏假設我是一個無良商家。
首先,可以肯定的是,免去了請真人模特和拍攝等一系列的費用。其次,也省去了設計,打板,選布料,成衣等一系列步驟。現在我開店,靠着AI生成的圖,坐等空手套白狼就可以了。

圖片來自電商平台
等有顧客下單,照AI畫虎做出成品就可以了。但其中省略的打板和選布料兩個環節,就造成了前面的色差和版型問題。
在傳統的製衣過程中,打板是把初步設計好的樣品,放在在一個裝有假模特上(業內稱為人台),確保樣品可以符合大部分人的體型。選料則是選出符合設計稿的衣料,比如這次的國風毛衣,用普通的針織衣料肯定會達不到這種飄逸的效果。
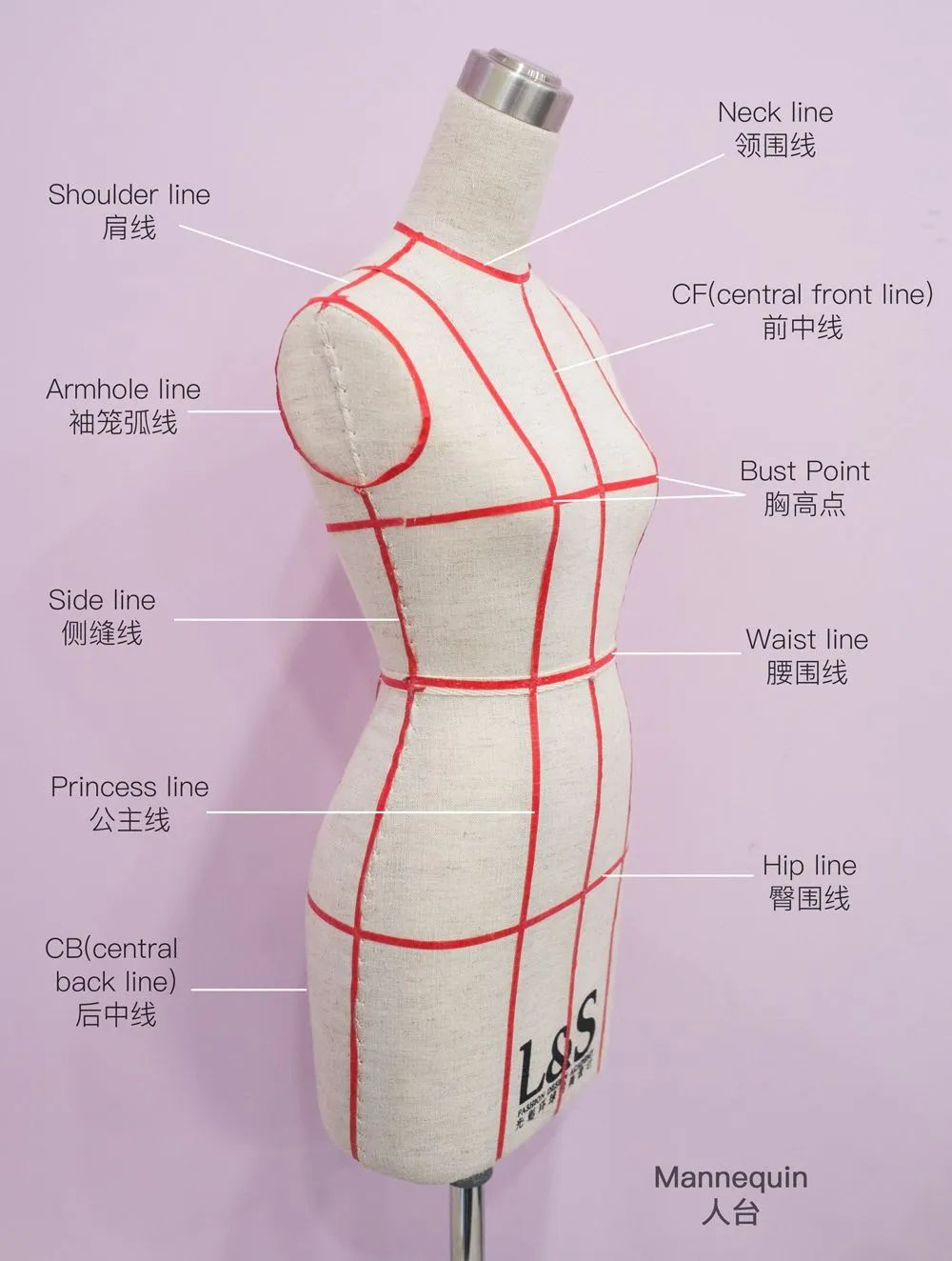
因為普通的毛線太重,並且還有產生靜電,會讓裙襬裹在身上,所以想要達到這種效果需要特殊的馬海毛才行。也正是因為缺少這兩個步驟,才造成了開頭的買家秀和賣家秀。
作為消費者,該怎麼面對AI在AI海洋裏遨遊了幾天後,我發現其實目前大部分賣家使用的還都是比較基礎的模型。所以對於消費者來講,現階段想要分清AI還是實拍不是件難事。
因為AI作圖在文字,觀眾臉部等細節上還不夠精準,所以AI生成的圖片在這三個地方會有很大的瑕疵,大家可以多注意注意。

仔細看觀眾的臉部,幾乎一致
再就是基礎模型的油畫感很重,多看幾張,就會覺得和實拍有很大的不同,另外AI生成高分辨率圖片需要高端顯卡才可以,所以也可以看下店家的照片是否清晰。
最後——記得買運費險!
人間一天,AI一年還記得3月份第一次接觸Stable Diffusion的時候,可供下載的模型沒有幾個,大家還都是以基礎模型為主,沒想剛剛進入11月份,目前網上的模型已經挑花眼****了。
有的用户使用各種二次元漫畫來訓練出漫畫風的模型,有的用户則會訓練出科幻的模型,因此,現在的模型數量基本上可以覆蓋到絕大部分的畫圖領域了。
既然如此,那肯定也有用真人的照片來訓練模型吧?答案是肯定的,大家可以猜猜下面這六張圖片中,哪幾張是AI生成的,哪些是實際拍攝的?(前10名猜中的朋友將獲得酷玩贈出的小禮品)


相信大家很難辨認出這些圖片的真假,這也是為什麼上面提到的賣家只是使用了基礎的模型,並沒有使用定製的模型。
因為現在的AI製圖確實已經可以達到以假亂真的地步了,如果有人採集大量的模特實拍圖用來訓練模型,那麼賣家秀的區分難度將再上一個量級。
這主要是AI學東西太快了,以前人類學習一種風格可能需要幾周的時間,而現在只要你有一張足夠強力的顯卡,AI一天就可以學習完幾百張圖片。然後把它應用到繪製圖片中。
這種快,不僅體現在作圖上,今天Gen2宣佈,它們已經可以生成4K清晰度的視頻了,這兩天各種郭德綱説外語,黴黴説中文也是最好的作證。
真可謂,人間一天,AI一年。就在現在,幾萬張顯卡組成的集羣就在地球上很多個角落瘋狂的學習,這將帶來怎麼樣的改變,真是讓人類又害怕又期待。