漫畫丨為了大模型,如何榨乾每一滴算力?_風聞
谭婧在充电-谭婧在充电官方账号-偏爱人工智能(数据、算法、算力、场景)。-11-03 12:59
丨搞掂大模型,如何榨乾每一滴算力?原創 譚婧 親愛的數據 2023-11-02 12:05 發表於浙江收錄於合集#人工智能漫畫25個#人工智能大模型14個
原創:親愛的數據
失敗不可怕,可怕的是朋友成功了。
此話用到大模型這兒,就是:
失敗不可怕,可怕的是“朋友”有很多算力。
看出來了,大模型的訓練和推理需要很多很多GPU,
有些爆款算力產品居然躋身“電子黃金”。
外部那些不懷好意的人還在GPU上搗亂,氣煞我也。
不過,氣歸氣,預期之內。
(一)什麼是算力的發動機?
2023年9月,微軟官網曾有一篇報道,其原文為:
“美國愛荷華州有一台Azure的超級計算機(Supercomputer),是微軟為OpenAI團隊打造的一套系統,用於訓練突破性人工智能大模型。”

這個Supercomputer,可以翻譯成“超級計算機”。
但是,這不可能是超級計算機,泛指厲害的計算機。
陳左寧院士曾説過,傳統高性能計算機並不最合適用於AI對算力的需求。
我特意請教了權威專家,
他告訴我:“因為沒有詳細配置,不好判斷是不是超級計算機,也有可能是智能計算平台。”
他還強調:“目前主流超級計算機架構設計尚不能高效率地支持大模型訓練,需要專門設計,以GPU並行為主的智能計算平台。”
OpenAI大力出奇跡,高性能集羣始終是算力的發動機。
但凡需要訓練千億參數的AI大模型,背後必然是一個複雜系統。
算力發動機必然是這個複雜系統的一部分。
而模型已是科技生產力裏的重要生產元素。
即便現在盈利能力還不強,
但是在接觸AI這件事情上,國內客户的興趣和訴求非常強勁。
既然AI大模型必然廣泛應用,那麼算力要標準化,且性價比要高。
而這兩件事都不件容易。
阿里雲資深專家九豐告訴我:
“GPT-4出現,讓模型訓練的範式非常強地依賴高性能計算的硬件和高性能通信帶寬的網絡,此前完全不是這樣。”
高性能很難,挑戰還有兩個。
這就帶出了另外一個話題,如何衡量AI集羣算力性能?
而對於訓練大模型的算法同學來説,
他們不會僅僅關注性能數字,而是關注另一件具有同樣內涵的事情:
用AI集羣訓練大模型,到底要花多少時間?
(二)時間都去哪裏了?
大模型訓練對算力“飢渴”,對時間“焦慮”;
原因是它有個特點是“強同步”。
比如,一個人做一道大計算題,需要一百天。
那就找一百個人來一起做。
當幹活的人多,首先要分工,任務分配下去之後,需要同步工作。
然而,大模型解題需要好多步驟,中間步驟解出來,其計算結果需要同步傳遞給其他GPU。
那些還沒有拿到答案的GPU只有枯坐傻等。
有點搞笑的是,等到最後一個GPU拿到答案才能一起開始算。
那些數量不大,還遲到很久的任務,有一個名字叫“長尾時延”。
等待時間,計入模型計算的總時間。
就好比,等待吃飯的時間,計入吃飯總時間。
常聽專家們談論一個百分比:通信佔比。
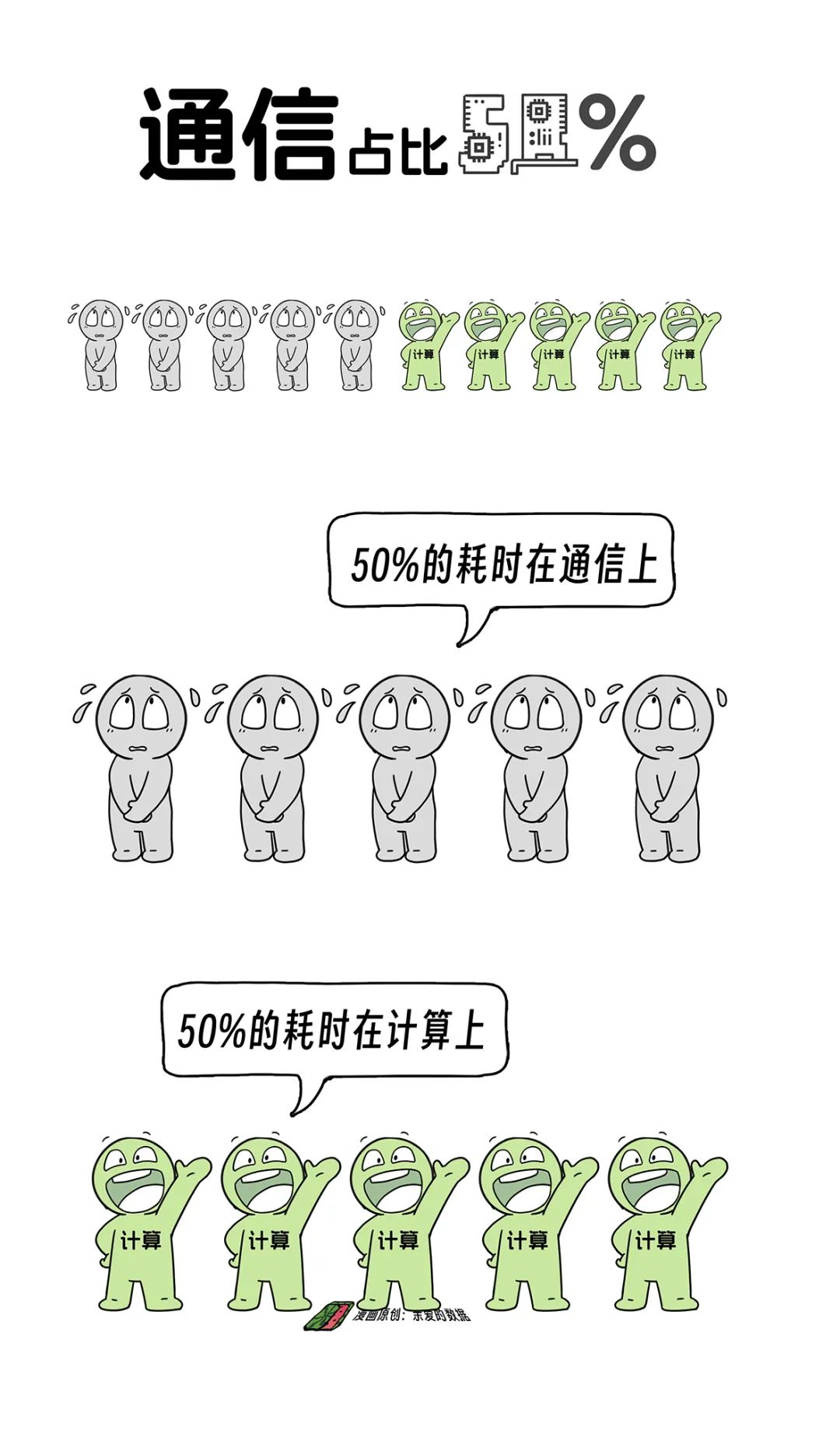
當通訊佔比是50%,整個訓練時間裏,計算和通信時間各佔50%。
計算佔一半時間,枯坐傻等也佔一半時間。
同樣的算力,別人的訓練時間是你的一半。
太可怕了。
這叫直道超車。
按我的理解,把計算這件事情分成三塊,
第一,“純”計算的時間。
芯片性能很重要,任何軟件優化的天花板,必然是硬件的上限。垃圾芯片再怎麼優化,不可能有“電子黃金”跑得快。
第二,取數據的時間。
計算服務器和存儲服務器之間打交道,相當於你先把原材料運過來。除了用高速存儲,下一步就是做緩存,數據從存儲那裏拉比較慢,就把它緩存到離計算近的地方,拉起來速度就快了。
第三,網絡的時間。
雖然是給計算打配合的,俗稱“服務於計算”。
但是,它佔用了大量的時間,是計算裏面的重要一環。
用網絡傳數據,就像説話溝通一樣。
機器多了,無法線性擴展,網絡速度自然就慢了。
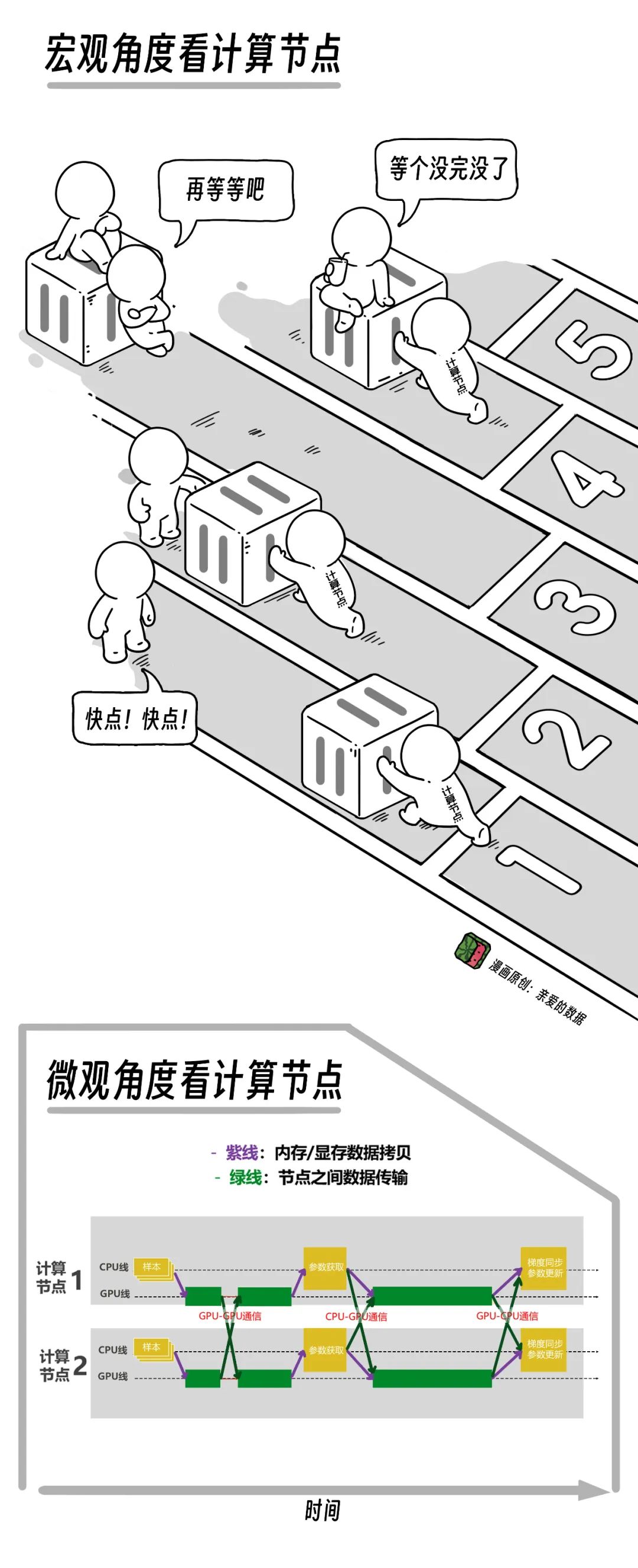
所以,想給計算集羣做一個完整的優化,不能只優化“純”計算部分,
這三塊都要考慮到。
**(三)**系統穩定,情緒穩定
如果計算集羣不穩定,那麼算法同學很可能情緒不穩定。
從某種角度來説,芯片一直處於較高頻率的計算狀態,
硬件的故障率肯定會比傳統玩法高很多。
機器規模越來越大,會不斷刷新故障率“成績單”。
並且,計算任務停止所付的代價也隨規模增大。
好比,全村停電和全國停電,經濟損失肯定不一樣。
訓練大模型的算法同學對故障非常痛恨。
講一個前幾天阿里雲異構計算產品負責人王超告訴我的段子:
當年,阿里算法同學曾內部吐槽早期的靈駿集羣不好用。
的確,那時候,在千卡穩定運行8小時這個段位上都努力了好一陣子。
8小時是什麼概念,你得讓算法同學安穩睡一覺。
算法同學得罪不起,他們拿靈駿的拼音開頭(LJ)開了個玩笑(垃圾集羣)。
聽到此,相信你很難不記住產品名字(蚌埠住了)。
模型訓練之時,GPU的狀態一路打滿,
都把設備累到這個份上了,故障多點實屬正常(雖然不可接受)。
於是,保障穩定性對於AI集羣的重要性不言而喻。
甚至説,現在比過去更應該重視怎麼通過軟件層面的優化,降低故障發生。
在龐大的複雜系統裏,
底層元氣滿滿支持上層軟件專注做事,
上層軟件如何能讓硬件的計算性能“精神抖擻”?
軟件層面的方法應該有很多,就看怎麼設計。
當某個硬件可能會出現故障或者降速的時候,能夠提前遷移訓練節點。
假如,帶寬由800G掉到400G,這是一個很嚴重的事情,訓練受到降速影響,算法同學完全無法接受。
找到問題,幹掉問題;
實際上,如果説不去做一些任務狀態的精細監控,沒有辦法發現故障。
AI大模型的訓練,已經是一個很大的複雜系統了,出現千里之堤毀於蟻穴的概率比以往大很多。
需要有人為此做出專門的設計。
合理的思路是,檢測到這一類降速故障,把任務遷移到正常節點。起把故障節點下線,自動維修,之後再自動上線。
我拿PAI靈駿(PAI的讀音為π)裏的功能AIMaster為例子來分析。
它是一種兜底的容錯方法。
這種方法又好像一種最低戰損法,
只要我的作戰單元足夠小,即使該單元全軍覆沒,我的戰損也會控制在很小範圍內。
因為沒有人能100%搞定高性能計算時候的故障,除了故障監控和故障修復,還有一種辦法也很重要,最小化故障損失法。
這種方法好像一種安全防禦理念,
只要我的作戰單元足夠小,即使這個作戰單元全部都被幹掉,我的損失也會控制在很小範圍內。
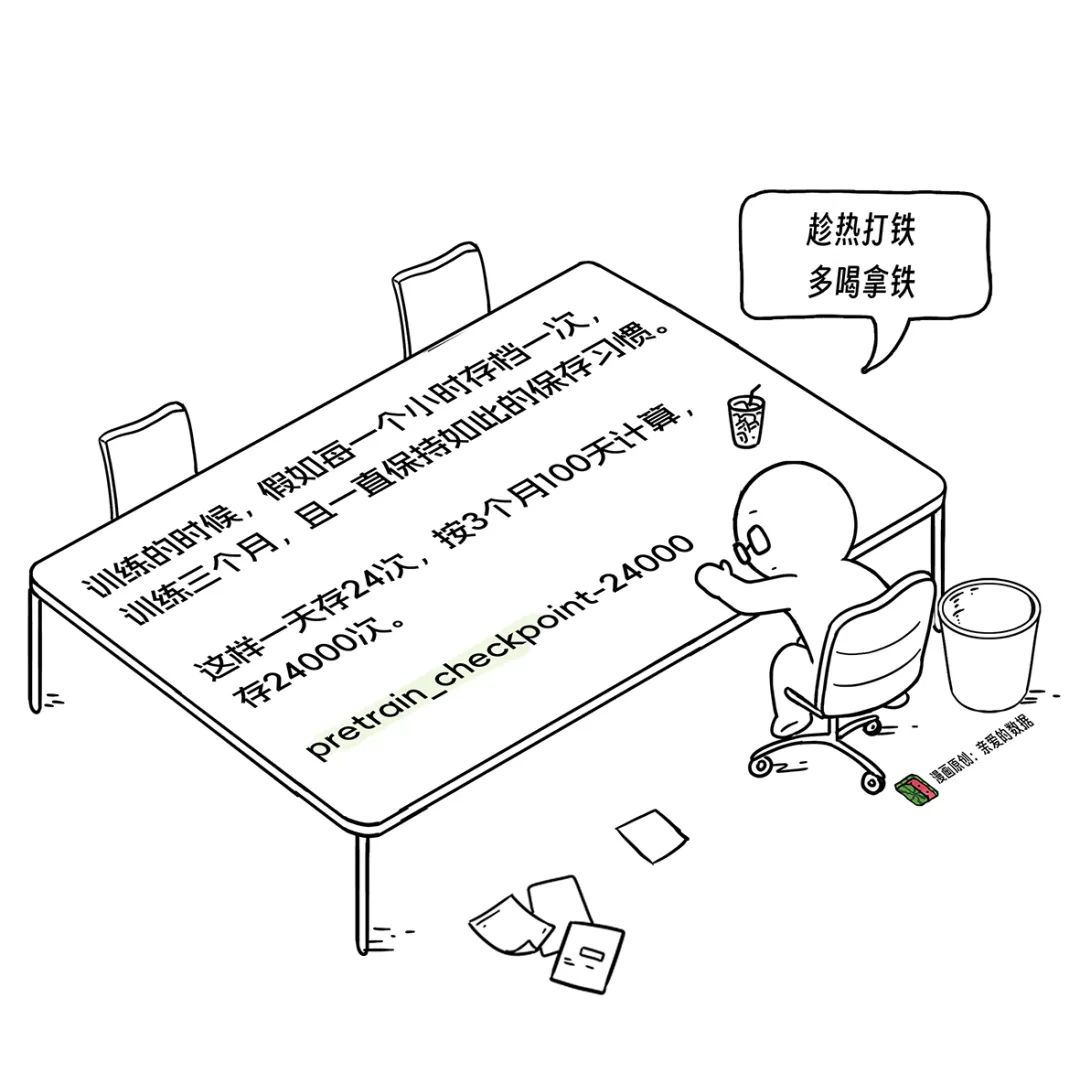
大語言模型的Checkpoint很大很大,千億規模模型的Checkpoint大小達到了數T級別大小。
這時候,我們發現Checkpoint是個好東西,Checkpoint是一組文件,不是一個單獨的文件。
一般來説,一組文件都會放在一個文件夾內。
雖然Checkpoint很珍貴,但是保存太花時間也很討厭。
我寫文章在Word裏打3個字,保存3秒。
那真是要説“栓Q了”,靈感早沒了。
從第一性原理上講,算法同學不是不想存儲,而是存儲耽誤時間,他們真正想要的是存儲的時候別耽誤計算。
為了不讓存儲耽誤計算,存儲和計算得做到異步。
現在保存Checkpoint,還對訓練自身不產生任何影響,已經是一個基本操作了。
我暗想以前是分鐘級,是不是有產品做到秒級那樣更厲害。
保存當然是越快越好,還要保存顆粒度更小的單位的Checkpoint。
比如:每一個小批次數據(Iteration)計算狀態。
如此這般頻繁的保存,會不會影響存儲性能,性價比降低,要知道“算力貴如油”的日子裏,人人都精打細算。
就這個問題,我請教了阿里雲專家肖文聰。
他給我的答案是,考慮性價比固然有理,但更重要的是無感知。
保存Iteration雖然次數多,但控制存儲總量能搞定。
他向我強調:“以前,把GPU上的任務停下來,從GPU寫到存儲,比如一千張卡,同時做這件事,存下來就需要幾分鐘,但是如果訓練時間不長,就顯得存儲時間很長。”
那真痛苦。

於是,我理解了PAI的EasyCKPT的設計思路,支持到Iteration級別的Checkpoint無感知,背後是更高頻次存儲,更少故障,減少計算步驟結果損失。
而且肖文聰告訴我:“EasyCKPT保存的時候無感知,是巧用了訓練任務多副本的模式和GPU服務器多級存儲架構。”
這確實是一種最小化故障損失的辦法。
以上方法科技含量挺高,我再介紹一種科技含量更高的方法,
算是一道學霸附加題:
PAI-TorchAcc(Acc是Accelerator的縮寫)是一種在編譯層面優化的方法。
Python原生深度學習任務的特點是會不斷給GPU很多小指令,在效率上,很多小指令不如讓GPU執行一個大指令。把這些小指令“按”成一條大指令,相當於把小運算轉換成連續運算,再給GPU執行。
這可以充分打開優化的空間,減少GPU算力損耗,降低訪存瓶頸,甚至可以更加智能地切分這個大指令到不同的GPU上做分佈式訓練優化。

PAI靈駿團隊內部有一個標準,叫做千卡。
當一千張卡在一定時間長度內不暫停,可視為複雜系統的穩定性跨過了一個門檻。
或者説,在行業裏拿得出手。
他們認為,一千卡的以內的能力沒有必要拿出來説。
目前,PAI靈駿一千卡任務可以穩定運行3周以上。
當一千卡的任務暫停了,報錯是某節點通訊超時。
值得問的問題很多:
1. 你通訊節點出了什麼問題?
2. 你有沒有備用的通訊節點給我?
3. 備用的計算節點和現有的節點組網的時候,網絡拓撲要不要重新優化?
客户不用管這些,先睡個美容覺。
第二日清晨,客户醒來,看到昨晚有一個日誌:
任務暫停又重跑了。
我們談到很多大模型算力裏的痛點,歸根結底都是時間。
那PAI靈駿給自己定的目標什麼呢?
我抄了阿里雲異構計算產品負責人王超的答案:讓不可用的時間越來越少。
(四)錘鍊“PAI靈駿****”****
對於大模型來説,計算可以彈性,計算不能聯合。
譚老師我所掌握的是,現在國內100%大模型創業團隊都採用線下集羣+公有云+租計算節點(服務器),三種模式組合來解決算力捉襟見肘的尷尬。
面對一個需要1000卡來訓練的大模型,有多個選項:
或用線下機房裏的1000卡跑任務,
或租1000卡的節點跑任務,
或跑在阿里雲上。
可惜,三個不同形態的1000卡AI集羣不能訓練同一個大模型。
當你遇見一個需要3000卡來訓練的大模型,怎麼辦?
國內公有云中,阿里雲規模最大。
公有云的本質是能夠資源共享,當訓練模型的時候,1000卡不夠了,可以“彈性擴容”到3000卡。訓練結束後,釋放資源給其他人用。
美國愛荷華州那台號稱“超級”的計算機可能是微軟雲Azure的智算平台。OpenAI團隊大約300號人,做出來一個令人震驚的東西,但不要忘了他們背靠微軟Azure。
我把PAI靈駿也理解為 “智算平台”,這個平台的底座是一個超大規模並行計算集羣。
或者説PAI靈駿是專門面向智算的軟硬一體的服務,就是名字有些複雜。
很多人第一次見PAI,不知道怎麼讀(包括譚老師我)。
在高端的英文名中混合了文縐縐,總之是既拗口,又難記。
全靠時間長才自然記住的。
(譚老師種草不行,拔草第一)

不過,PAI靈駿底層能力強,上層指揮調度也得力。
通義千問、通義萬相全部都跑在PAI靈駿上,它肯定不缺錘鍊。
一個大模型團隊,僅有一羣算法工程師不夠,還配備管控、計算節點、運維、網絡共4個團隊,一起服務計算集羣。
坦白講,市面上有不少線下產品的選擇,比如,線下版PAI靈駿,華為Atlas,英偉達Super POD,開箱即用。
這樣,“服務團隊”的人數能少些。
不過,沒有PaaS層和IaaS結合的能力,大量工作都得自己幹。
本質上,最好能使用一體化的設計,AI軟件棧裏的組件配合得越緊密,算力使用得越充分。
最後,譚老師我想説,模型訓練是一個離線過程,而模型推理服務是在線上的。
如果團隊有能力線下自建集羣,將大模型訓練於線下完成,這也是中國大模型團隊自身實力的體現。
在中國,有的是這樣有科技含量的團隊。
不過,當用户量大到一定規模的時候,他們一定會上雲。
有一天,中國本土一定會生長出一批千萬日活的大模型(我希望越多越好),
而現在看來,中國5000萬級別日活的APP有很多,每一個都生長在雲上。
One More Thing
2014年PAI團隊組建,
2017年,靈駿起步。
譚老師我在2021年因M6模型接觸到靈駿和PAI,並和多個主要研發負責人都有過深入交流,有些人已重新開始了另一段旅程,但我們至今仍在聯絡。
做公有云,要對技術趨勢有很強的判斷力。
跑錯了,糾錯成本高;
錯過了,抓不到新的增長點。
回頭看來,PAI和靈駿都是早期預判準確,且死死咬住需求變化的產物。
那時候的PAI和靈駿和現在很不一樣。
長坡滾雪球,我看到了一段PAI靈駿的由來和過往。
回憶起來,彷彿外面雨聲不斷,聽到短波收音機廣播裏另一個世界的聲音。
此後歷練打磨,又是幾多風雨。
時光如梭,在今天2023年的雲棲大會上,看到PAI靈駿的新面貌慨嘆萬千,背後是多少技術人的用心探索,精心打磨。
很高興能把我所知道的PAI靈駿寫下來。
我想這是中國大模型和雲的故事裏,重要一章。
(完)
《我看見了風暴:人工智能基建革命》,作者:譚婧

