天璣9300拿下生成式AI最強移動芯,支持330億大模型,全新全大核架構做底座_風聞
量子位-量子位官方账号-11-09 13:23
明敏 發自 凹非寺
量子位 | 公眾號 QbitAI
最強生成式AI終端芯片,現已易主!
天璣9300一舉支持運行最大330億參數大模型,短短几周時間內刷新業界紀錄。

它是業界首款搭載硬件生成式AI引擎,首次實現端側LoRA融合,讓大模型技能可在本地擴展,基於個人照片生成專屬表情包。

打開攝像頭,即可實時生成一個虛擬數字分身。

同樣支持1秒內文生圖、20 Tokens/秒生成文本(70億參數)。
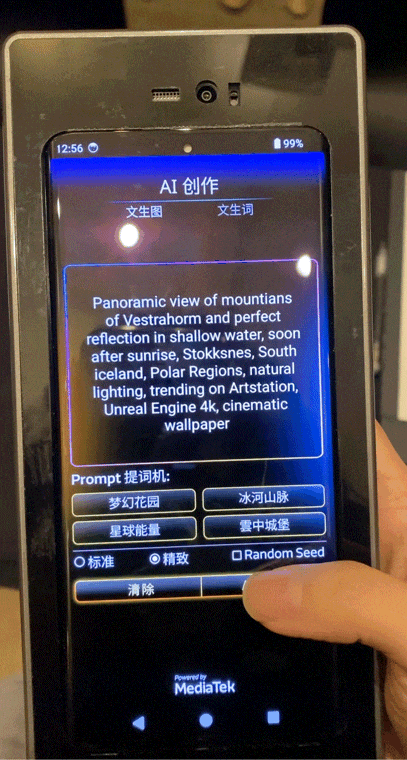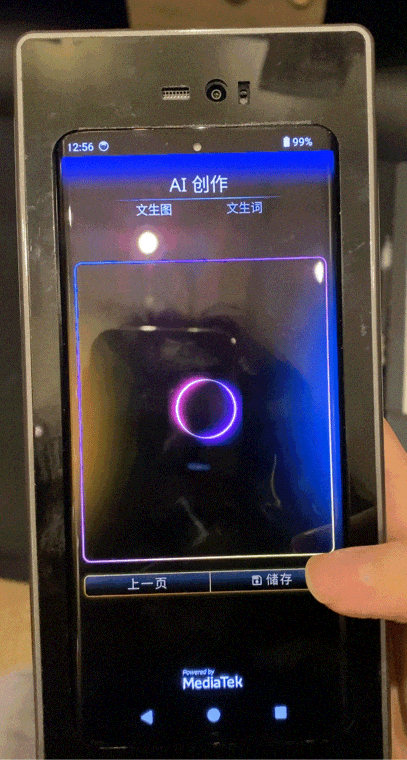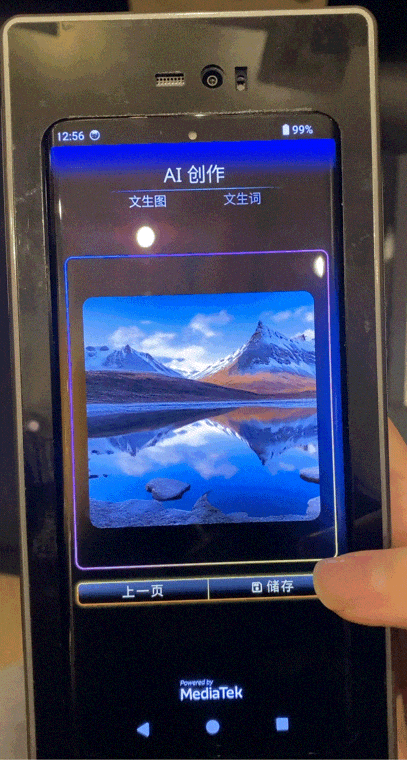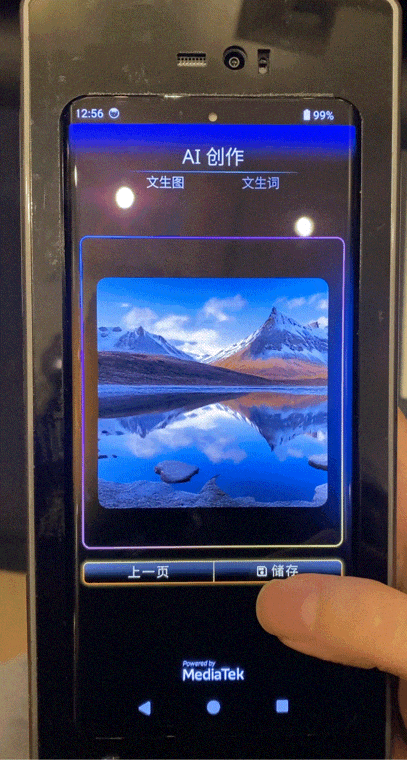
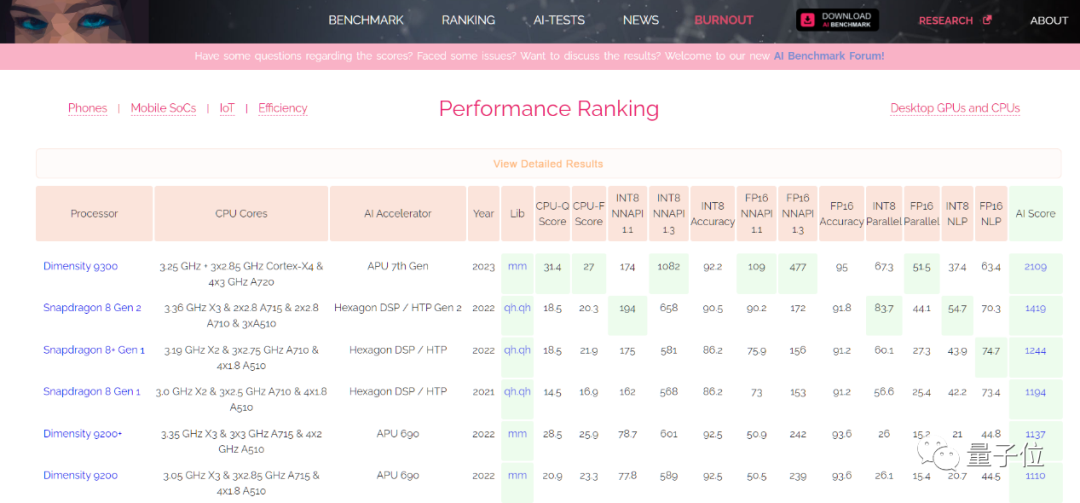
並且拿下“業內第一移動AI性能”,設備AI 跑分達到恐怖的3173(目前業內公開最好成績為2000+).
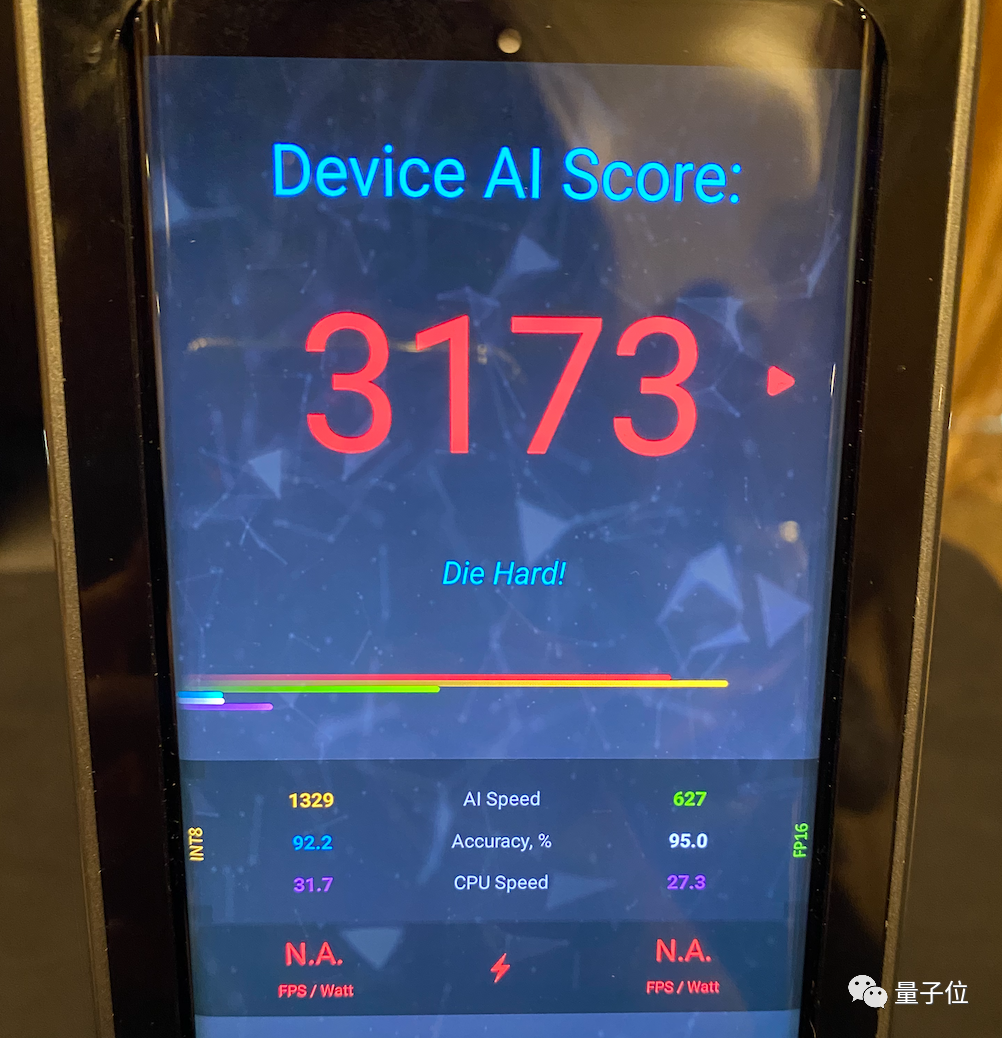
沒想到,聯發科首顆生成式AI移動芯片,性能就如此強悍。
加上首次採用的全大核CPU架構,天璣9300屬實是把牙膏踩爆了,峯值性能較上一代提升40%,功耗節省33%。
網友們看了都直呼:發哥,穩了!

搭載天璣9300的旗艦智能機vivo X100系列,馬上就會和大家見面。
如果你想嚐鮮,確實值得期待一把。

因為這是一張從底層開始、完全為生成式AI而來的旗艦級移動芯片。
透過它,不僅能先人一步體驗在端側玩大模型有多絲滑;更能提前窺見與感受,AI浪潮和移動終端將會碰撞出哪些激烈火花,。
手機實時生成虛擬分身
作為一張生成式AI移動芯片,能帶來哪些創新體驗?
天璣9300先來打個樣,帶來如下幾方面能力:
支持運行大模型
快速文本、圖像生成
端側能力擴展、個人專屬GIF表情包
視頻實時個人分身
生成式超分、夜景防眩光
語意搜索

最基本的,生成式AI芯片要具備端側支持大模型的能力。
天璣9300支持終端運行10億、70億、130億、最高330億參數AI大模型。
通過和vivo的深度合作,基於天璣9300率先實現了在vivo旗艦手機上端側落地70億參數大語言模型,系行業首家。
同時也突破行業上限,和vivo一起將端側運行大模型規模提高到130億參數。
在可以運行的基礎上,更進一步,需要做到快速處理。
天璣9300具備快速文字、圖片生成能力。
70億參數模型下可實現每秒20 Tokens輸出,支持文本創作、摘要生成等文本任務。
每張圖片生成時間控制在1秒以內。
這意味着幾乎無需等待,就能馬上從手機上獲得最新AI生成結果。
這也是為什麼天璣9300能拿下業界移動AI性能第一名號,ETHZ AI Benchmark v5.1 Mobile SoC >2000 分。
更創新的體驗來自端側技能擴展,它支持在本地生成多樣個性化內容。
這也是移動芯片首次實現端側LoRA。
基於此,拍下一張照片,在手機本地即可進行各種風格處理,生成個人專屬表情包。

要知道,基座大模型的知識與能力相對有限,想要讓大模型有更強生產力,往往需要對大模型進行SFT、LoRA等方式微調。今年AI繪畫能憑藉不同畫風、多次掀起熱潮,很多程度上正是得益於LoRA方法。
天璣9300的端側支持,可以讓LoRA變得更加便捷,可以推動大模型在手機上實現更多豐富玩法。
除此之外,生成式AI的應用還能導入到視頻中,實時生成個人虛擬化分身,進行視頻通話。
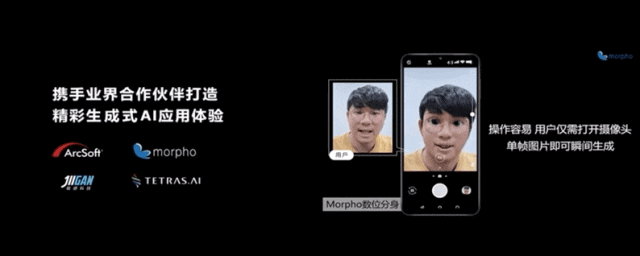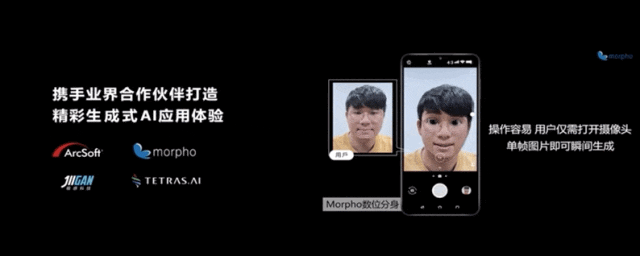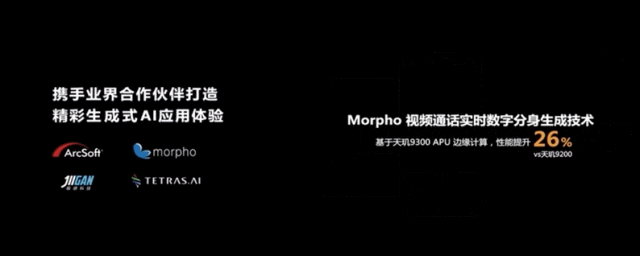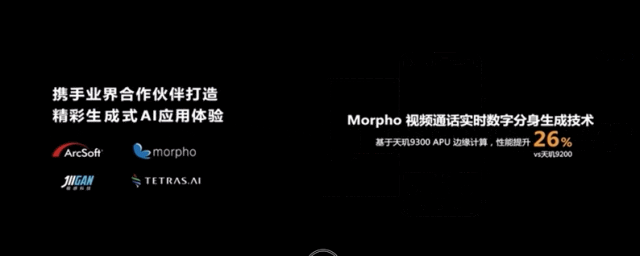
一些已有的AI應用,也基於生成式AI實現了更多創新。
比如用在提升遊戲畫質、圖像方面的超分算法,使用生成式能力後可以帶來更好畫質提升;

夜景拍攝可以防眩光產生;

以及生成式AI語意搜索,能不聯網智能檢索相冊圖片,在端側完成計算更好保護隱私。

總之,透過天璣9300的能力可以感受到,聯發科認為一張合格的生成式AI移動芯片,應該能把大模型能力儘可能帶到端側。
不只是要裝下更大模型,還要讓大模型能在端側拓展能力,以此帶來更豐富的應用。
那麼,聯發科是如何做到?
第七代APU+全大核打底
作為一張為生成式AI而來的移動芯片,天璣9300的能力提升邏輯簡單粗暴:
AI性能拉滿,底層能力夯實。
具體可以從APU和整體架構兩個方面來看。
APU主要負責實現大模型的端側快速運行。
天璣9300集成MedieTek第七代AI處理器APU 790,整數運算和浮點運算性能均是上一代的2倍,同時功耗降低45%。

為了能讓端側支持更大規模大模型,它帶來了特有的內存硬件壓縮技術(NeuroPilot Compression)。
要知道,大模型的海量數據在帶來極致性能同時,也帶來了巨大內存佔用。所以這也是為什麼大模型進端側難。
聯發科先採用INT4量化,將130億參數大模型壓縮至13GB。
然後基於內存硬件壓縮,進一步把13GB內存壓縮到只有5GB,內存佔用直降61%。
這樣一來,內存為16GB的內存即可運行130億參數大模型,24GB內存手機可運行330億參數大模型。

但裝下大模型還不夠,聯發科認為還要讓大模型具備更豐富能力。
由此提出了生成式AI端側“技能擴充”技術(NeuroPilot Fusion)。
它直接解決了終端無法裝下過多大模型的問題,實現一個大模型為底座,N個技能作為擴展。
這樣既解決了大模型的內存瓶頸,還儘可能拓展手機上生成式AI的應用邊界。

而為了能讓大模型更絲滑地在終端運行,天璣9300在更底層還做了進一步優化。
一方面,天璣9300是業界首款硬件生成式AI引擎。
它深度適配Transformer模型,特別在Softmax+LayerNorm算子上,處理速度較上一代提升8倍。
Softmax+LayerNorm算子正是當下大語言模型(Transformer網絡)的核心部分。
另一方面,天璣9300開創性採用了全大核CPU架構,從底層大幅提升芯片算力。
它包含4 個 Cortex-X4超大核,最高頻率可達 3.25GHz,以及4個主頻為2.0GHz的Cortex-A720大核,其峯值性能相較上一代提升40%,功耗節省33%。

其單個E大核的能效比完全超越傳統架構B核和L核。
全大核架構全面使用亂序執行(out-of-order)內核。
和傳統小核必須順序執行的邏輯不同,大核運算允許只要任務進來且可以處理,它就會開始執行。
這樣能大幅減少任務的總消耗時間,提升應用執行效率、減少卡頓。同時也能降低功耗,對比如下兩圖,大核運算“做得快、休息快”,運行曲線的積分更小,即功耗更低。
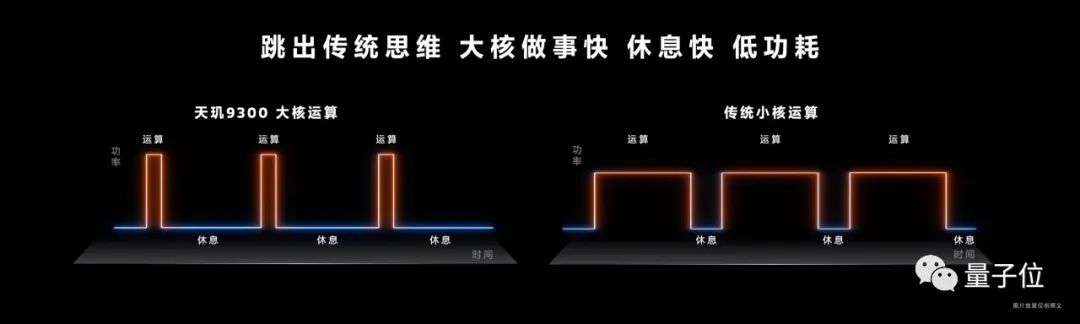
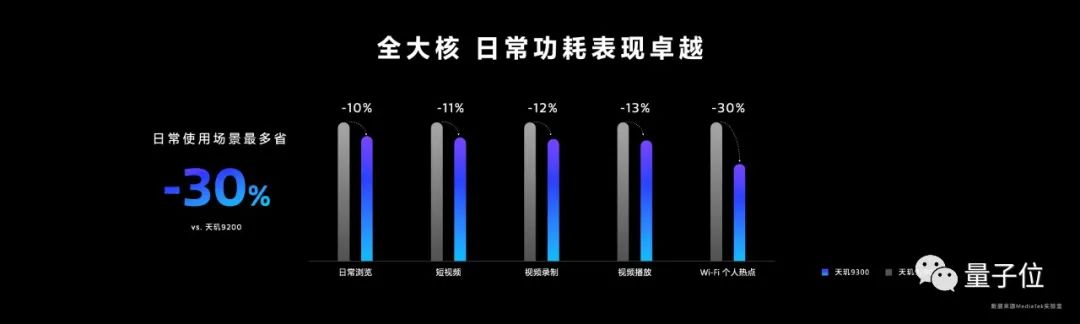
這些能力都能為芯片執行生成式AI任務,提供紮實的基礎計算底座。
最後,生成式AI在端側運行,還有很多細節需要考量。
比如在交互方面,目前大模型更多以智能助手形象出現,語音是重要的交互方式之一,所以天璣9300專門提升了音頻降噪能力,支持對3個麥克風動態錄音降噪,可以有效過濾風噪等環境音,不僅能讓視頻拍攝、錄音效果更好,也能輔助提升大模型語音識別的正確率。

另外在用户格外關注的數據安全方面,天璣9300集成雙安全芯片,從開機源頭保護個人隱私,同時具有物理隔離計算環境,進一步保障個人數據加密、解密的安全。以及內存標記擴展(MTE)技術,可以打造更安全的開發環境。

如上諸多方面的優化、革新與考量,都讓天璣9300成為一塊名副其實為生成式AI而來的移動芯片。
而除了對自身硬件性能提升,聯發科還進一步打通大模型生態。
支持Meta LLaMA 2、百度文心一言****大模型、百川大模型等前沿主流AI大模型,以及多模態大模型。
應用方面和抖音、快手、虎牙、愛奇藝、美圖秀秀等展開合作,提供相關SDK和model hub。

開發者生態方面,天璣開發者中心將提供端側生成式AI落地的一站式資源,提供端側部署案例分享。目前已有20+生成式AI合作伙伴。
一言以蔽之,聯發科要用天璣9300這塊旗艦芯,正式叩開生成式AI大門。
由此帶來的影響,將從聯發科由內至外,給全行業帶來新氣息,更進一步影響到每一位智能手機用户。
生成式AI打開移動芯片新象限
在近幾年裏,手機行業始終在思考一個大命題,下一代旗艦機該怎麼做?
這個命題需要芯片、手機、應用等廠商共同思考,如摺疊屏、旗艦影像等都是摸索出來的方向。
而生成式AI浪潮的到來,讓這個大命題迴歸本源,即下一代智能手機,就是要更智能、更強大。
大模型是實現這一切的根本。
所以過去一段時間裏,手機廠商們紛紛開始推出端側大模型、發佈接入大模型的OS系統,掀起大模型浪潮的OpenAI被曝要做新一代智能手機。
但落地到實際,怎麼讓手機用户能更好用上大模型。這個核心問題,還是要拋給芯片廠商。

因為大模型落地,必須要解決計算瓶頸、功耗瓶頸,而且只依靠雲端運行不能長久,也不能從根本上打開大模型的手機場景。
從當下來看,聯發科等頭部手機芯片廠商已經邁出了關鍵性的第一步——將大模型實現端側運行。
那麼接下來該怎麼走?如何思考生成式AI芯片的未來?以及大模型在手機端的應用?
現在似乎很難有非常明確的答案。
畢竟業內都非常清楚,大模型浪潮如今才只是最早期階段,無論是技術層面還是應用落地,都仍需長期探索。
但聯發科用天璣9300給出了一個關鍵參考:
面向生成式AI的移動芯片,要從底層為大模型做準備,“天生”更適合大模型,同時硬件層面要做到能力溢出。
為什麼?
用聯發科的話來説,就是“生成式AI旗艦芯片未來一定會有更多應用模式產生、完成更復雜的任務。”

作為一個硬件級的底座,要足夠強大,上層系統、應用才能有更多創新空間,更多生成式AI端側應用才能誕生。
在強大的同時,還要動作夠快。
天璣9300不僅和vivo一同實現業內首個70億大模型端側落地,還實現了130億參數大模型端側運行。
搭載天璣9300的vivo X100系列也將馬上上市。屆時就能真正上手實測大模型跑在端側是什麼感覺了。
對於大模型上手機,你有哪些期待?對於今年生成式AI給手機行業帶來的新氣息,你又有哪些感受?
歡迎評論區留言討論~