馬斯克、Grok與“數據封建主”_風聞
阿尔法工场-阿尔法工场研究院官方账号-中国上市公司研究平台昨天 15:33
“下一代基礎模型會摧毀任何數據護城河”。
下週,馬斯克躊躇已久的Grok就要上線了。
在OpenAI接連甩出炸街新聞的這段時間,這事似乎沒掀起太大波瀾。
然而,越低調的狙擊,往往傷害越高。
具體來説,Grok的這次年末突襲,隱藏了老馬背刺OpenAI的一件“秘術”。
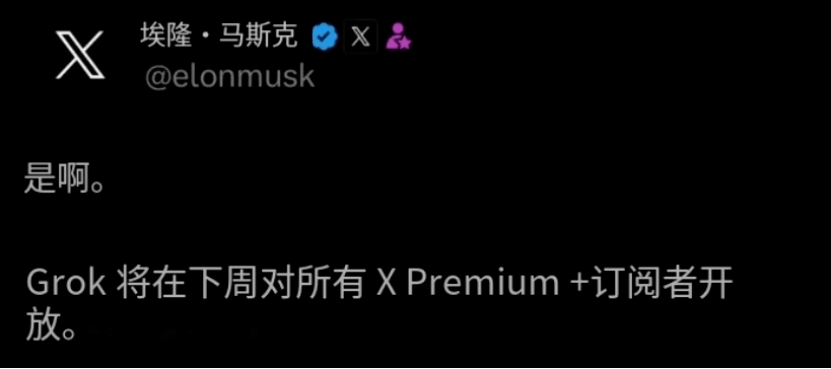
所謂的“秘術”,其實也很簡單,就是X平台上不斷湧現的,真實的人類數據。
在大模型數據愈發吃緊的今天,連OpenAI自己,也開始直接拿用户數據訓練了。
在此情況下,掌握了X這樣一個源源不斷的“數據噴泉”,無疑就有了一張將來翻盤的“底牌”。
但話雖如此,但Grok畢竟是一個社交平台,上面的大部分信息,都是未經核驗,且質量參差不齊的,直接拿來訓練大模型,不怕幻覺迭出嗎?

瞭解大模型的老馬,一定知道這點。
但即便如此,Grok的上線,對特斯拉,對老馬也仍是利大於弊。
因為倘若不走這一步棋,將來的AI賽道上,馬斯克最多隻能做割據一方的“數據封建主”,並且終將面臨“護城河”被攻破的命運。
這樣的未來,很可能也是日後眾多國內企業的命運。
01 數據封建主
何謂“數據封建主”?
簡單來説,就是以獨有數據為壘,在某些垂直的行業、領域內“圈地為王”的大小企業。
這樣的概念,最初由希臘前財政部長雅尼斯·瓦魯法克斯提出,是其在歐洲各國在美國科技企業壓榨、盤剝之下發出的感慨。
而自從11月初的OpenAI開發者大會後,這種爭當“數據封建主”的聲音,就開始在業內不絕於耳。
希臘前財長雅尼斯·瓦魯法克斯

畢竟,在應用層的路被GPTs堵死的情況下,獨有數據就成了很多企業唯一的優勢。
那麼,老馬推出Grok,是想以X平台的數據為基礎,成為新一代的“數據封建主”嗎?
答案是否定的。因為在未來,這類“數據封建主”的命運,就是其壁壘會隨着技術發展不斷被削弱,以至於被更強的通用模型步步蠶食。
在這方面,老馬的Grok,已經展示出了兩種攻破這類“護城河”的方式。

其中一種,就是通過將模型置於“數據樞紐”的位置,使模型的觸手伸向原來鞭長莫及的行業、領域。
很多人都知道,美國並沒有中國的微信這樣集社交、支付、娛樂、資訊於一身的綜合平台。這並不是因為美國人能力不行,而是美國的各大金融機構,與科技巨頭之間是一種互為競爭的關係。
馬斯克對於X的收購,不僅在某種程度上結束了這樣的“割據”,也為其打造成一個類似微信的超級APP提供了基礎。

倘若X平台真的能成為一個以音頻、視頻、消息、支付/銀行為中心,同時鏈接商品、服務和機會的全球市場。那麼到了那時,Grok就會成為這個數據樞紐的中心,從而獲得來自不同行業、地區或模態的海量數據。
如此一來,Grok的定位就不再是一個侷限於社交平台的整蠱大模型,而是成為了連接各領域的綜合性交互入口。
隨着時間的推移,這種綜合性入口+大模型的協同效應,將會使那些不用Grok,或不上X的用户,與經常使用的用户之間差距越來越大。

這種情況下,各個垂類行業的數據壁壘儘管依然存在,但若脱離了Grok,卻很難被用户接受。
於是,這些被拿捏的“數據封建主”們為了求存,只得向Grok效忠。
02 協同效應
除了以佔據數據樞紐的方式,對各個“數字封地”進行蠶食外,Grok這類大模型攻破數據護城河的另一大方式,就是端雲協同的形態,編織一張巨大的包圍網。
具體來説,在將來的端側大模型這條賽道上,由特斯拉提供算力(Dojo),X和特斯拉提供訓練數據,xAI進行模型研發,最終將產出模型反哺給X平台和特斯拉的產品(汽車、人形機器人),將構成極為堅固的三角陣營。
那麼,在大模型逐漸走向端側的未來,這樣的三角陣營,將怎樣攻破一個個“數據護城河”?

在這裏,我們可以用一個電商行業的例子進行推演。
假設,有一個企業,基於某個局部的電商賽道,用行業獨有數據訓練出了個專有大模型,而馬斯克的Grok打算入侵這個領域,那麼在數據收集階段,其很有可能會採取一種“領域交叉”的戰術。
具體來説,特斯拉汽車在行駛過程中收集到的交通、地理和用户行為數據;機器人在家庭、工廠等場景中收集到的環境和操作數據;以及X平台上的社交信息,都為馬斯克的團隊提供了豐富的信息來源。

當馬斯克的團隊將這些數據整合在一起時,他們就可能會發現一些新的模式和關聯,從而在某種程度上削弱這個專有大模型的獨特優勢。
這種戰術的核心理念就在於:這個世界上沒有任何一個行業、領域,是完全孤立存在的。
除了外圍攻勢外,這樣的三角陣營,還能通過“合縱連橫”的方式,瓦解掉一個個孤立的“數據護城河”。
簡單來説,面對大模型逐漸端側化的趨勢,馬斯克的三角陣營提供了一種端到端的解決方案。
其涵蓋了從不同來源進行數據採集、處理、訓練到部署的整個流程。這意味着企業無需在各個環節尋找不同的技術和服務提供商,從而降低了實施難度和成本。

簡化的流程有助於企業更快地應用AI技術,提高數據處理和分析能力。
在此情況下,就可能會有相當一部分企業,決定犧牲數據的獨有性,加入三角陣營的生態,從而換來更高的AI部署效率。
這種邏輯,本質上就和移動互聯網時代,很多商家即使忍受高抽成,也要入駐平台,換取更低的獲客成本一樣。
在這樣圍困之下,一座座孤立的“數據城堡”,終將難以抵擋日漸壯大的Grok。
03 通向AGI之路
面對Grok潛在的,咄咄逼人的攻勢,各個想以數據為壘的AI企業,將何去何從?
在回答這個問題之前,有一個更重要的問題,那就是:
這種對“數據護城河”的堅守,真的是一種正確的方向嗎?
此前,在紅杉資本總結報告《生成式AI的第二幕》中,曾有那麼一段話:
“‘數據護城河是站不住腳的’:應用公司生成的數據並沒有創造出無法逾越的護城河,而且下一代基礎模型很可能會摧毀創業公司構建的任何數據護城河。相反,工作流程和用户網絡似乎正在創造更持久的競爭優勢。”

那麼,未來真的會如紅杉所説:“下一代基礎模型會摧毀任何數據護城河”嗎?
至少從技術層面上看,這種可能性是存在的。
此前,在討論OpenAI泄露的Q*項目時,NVIDIA的高級AI科學家Jim Fan,就在推特上和馬斯克、LeCun討論了合成數據的問題。
Jim Fan認為使用計算機生成(合成)數據可以提供下一次幾十萬億高質量數據集。唯一的問題,就是需要想辦法確保數據的持續高質量和多樣性。
而AI三大教父之一的LeCun則表示:“動物和人類只需少量的訓練數據,就能很快變得非常聰明。我認為新的架構可以像動物和人類一樣高效地學習。”
OpenAI首席科學家Ilya也表示,數據問題可以解決

總體來説,對於數據問題,Jim Fan和LeCun代表了兩種不同的解決思路。
一種是通過合成數據的方式解決;另一種則是研發新的架構(如世界模型),讓模型僅用很少的數據,就能“舉一反三”。
但無論方案優劣如何,這些技術構想,都代表了學術界渴望打破“數據限制”的一種集體意志。
同樣地,站在用户的角度來説,人們也更樂於看到一個通用性更強,能精通更多任務的大模型,而不是每換一種場景,就要切換不同的模型。
而當一種技術方向,成為上至科學家,下至百姓的共同意志時,它的實現就只是時間問題了。

從這個角度上説,所謂的“數據壁壘”,都是終將要消失的。
現在的很多互聯網公司,都是根據用户的行為數據,結合模型在做一些業務,而如果用户遇到了整合能力更強的大模型,那之前的很多業務、功能(例如聽歌),也許就會變成一個個插件,這樣就沒有數據壁壘了。
而在這個向AGI過渡的階段中,真正有潛力的團隊,應該是那些能夠摸索出“數據壁壘”之外的核心競爭優勢的團隊。
誠如月之暗面的CEO楊植麟所説:不同組織衍生不同的文化,文化又衍生不同的系統,而系統又了衍生不同的結果。
在技術、數據方面發展趨於平緩的情況下,開發範式,制度和觀念,這些軟性的、抽象的因素,就成為了決勝的關鍵。
而這種“數據”之外的因素,這也是AI時代,人之為人最偉大的源泉所在。