通義千問開源:大模型時代“虹吸效應”的開始_風聞
子弹财经-子弹财经官方账号-子弹财经(zidancaijing)12-04 18:46
出品 | 子彈財經
作者 | 張樵
編輯 | 閃電
美編 | 倩倩
審核 | 頌文
12月1日,阿里雲舉辦發佈會,正式發佈並開源“業界最強開源大模型”通義千問720億參數模型Qwen-72B。同時,通義千問開源了18億參數模型Qwen-1.8B和音頻大模型Qwen-Audio。
至此,通義千問共開源18億、70億、140億、720億參數的4款大語言模型,以及視覺理解、音頻理解兩款多模態大模型,實現了“全尺寸、全模態”開源。
這是一場可以用“不同尋常”來形容的發佈會,不僅僅因為它廣受外界關注,更重要的原因在於,從這場發佈會釋放出的信息來看,今年以來眾説紛紜,莫衷一是的“百模大戰”的勝負和大模型路徑之爭,已經有了初步的答案——在阿里雲“無開放,不生態”策略的驅動下,作為國內落地最深、應用最廣的大模型,通義千問希望延續阿里雲在“前AI時代”就信奉的創新底座角色,以AI底座的開放培育上層生態的繁榮。
1、阿里雲的開放邏輯這並非阿里雲在大模型開源方面的首次動作。作為國內最早開源自研大模型的“大廠”,阿里雲希望通過開源,讓海量中小企業和AI開發者更早、更快地用上通義千問。
今年8月,阿里雲就已開源通義千問70億參數模型Qwen-7B,今年9月,通義千問140億參數模型Qwen-14B及其對話模型Qwen-14B-Chat也實現了免費商用。
此次發佈會上,阿里雲CTO周靖人表示,開源生態對促進中國大模型的技術進步與應用落地至關重要,通義千問將持續投入開源,希望成為“AI時代最開放的大模型”,與夥伴們共同促進大模型生態建設。
大模型的前景無須贅言。但是,與基礎軟件產業的變革和發展歷程相同,大模型有着開源和閉源兩條發展思路,同樣有着相當於智能手機的“iOS”與“Android”之爭。
在國外,OpenAI選擇的就是閉源路線,除了ChatGPT,沒有具體的產品應用,對外則通過提供接口和投資的方式繁榮生態。Meta旗下的大模型Llama2則選擇了開源,用開源生態加速Llama的迭代和升級。在國內,例如BAT三巨頭,騰訊雲和百度雲的大模型採用的是閉源路線,阿里雲則選擇了開源路線。
業界由此分成了兩派。在支持閉源的人士看來,大模型閉源的好處是能夠提供更加成熟、穩定的產品,客户只要付費購買,即可直接使用。同時,還能夠提供更加專業的技術支持和服務。
大模型開源的擁躉則認為,開源能夠幫助用户簡化模型訓練和部署的過程,使得用户不必從頭訓練模型,只需下載預訓練好的模型並進行微調,就可快速構建高質量的模型或進行相應的應用開發。
“大模型究竟是開源更好還是閉源更好,實際上與‘先生態,後商業’還是‘先商業,後生態’的這個問題有關”,大模型行業人士告訴「界面新聞·子彈財經」,按照以往科技發展的規律來看,頭部的技術服務商,一般都會先建立生態、落地應用,然後再講商業模式,現在大模型仍然遵循着這個規律。
如近期周靖人就曾説過,“大模型這部分應該先注重生態,然後再注重商業化,而不是説一開始就過度圍繞商業化。”而建立生態的前提就是開放。
在今年的雲棲大會上,阿里巴巴集團董事會主席蔡崇信反覆強調的一個關鍵詞就是“開放”:“我們堅信,不開放就沒有生態,沒有生態就沒有未來。同時,我們要始終攀登技術高峯,只有站在更先進、更穩定的技術能力之上,才有更大的開放底氣。”

(圖 / 雲棲大會)
**與其他頭部廠商不同,阿里一直就有技術開放的基因,**例如,操作系統、雲原生、數據庫、大數據等等,在這些領域,阿里都有自主開源的項目。
此外,阿里在去年11月推出了AI開源社區“魔搭”。阿里的數據顯示,中國幾乎所有的大模型頭部研發機構都已將“魔搭”作為模型開源的首發平台。經過一年的發展,“魔搭”現已匯聚了280萬開發者、2300多個優質模型,模型下載量超過1億。
不僅如此,阿里雲充足的算力資源,也是其選擇開源的重要原因。雲和AI都離不開算力,特別是大模型,對於算力有着更高的要求。阿里的優勢本就在雲計算,數據、算力和存儲這些關鍵的底層資源。

從阿里雲今年以來的發佈和展示來看,阿里雲已具有全棧化AI能力,還有更加完整的通義大模型系列,這樣的能力體系背後,還是離不開算力。這也是大模型時代,MaaS層會成為頭部雲服務商最重要的業務環節的原因。
在國外,如微軟這樣的雲服務巨頭,也已擴大了開源模型的MaaS服務,他們也是依靠連接產業鏈的上、中、下游,才形成了規模化和平台化的生態。
阿里雲未來的角色同樣如此,以雲平台為基礎,將大模型的構建和應用讓給行業,用以連接眾多的企業和個人開發者,從而構建新的生態。
自此,阿里雲大模型的開源邏輯更加清晰,即通過開源的方式提供技術產品,降低門檻,推動技術普惠,為企業客户到個人開發者提供多元化、全方位的技術服務。在通義千問的基礎上創建的大模型、小模型越豐富,AI生態就越繁榮,阿里雲的前景也會越廣闊。
**2、“站在巨人肩上”**據介紹,此次最新開源的通義千問Qwen-72B有高性能、高可控、高性價比等特點,可為業界提供不亞於商業閉源大模型的選擇。
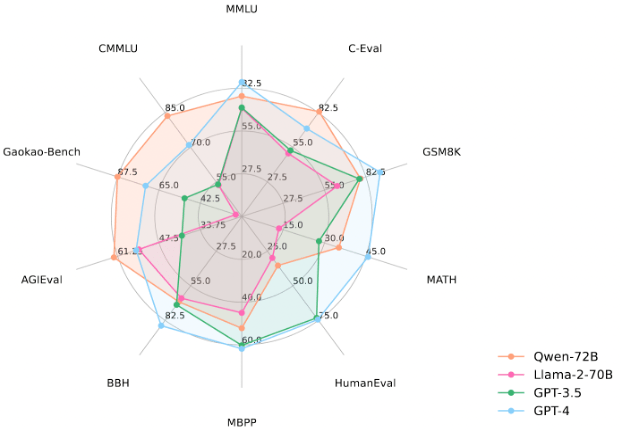
從性能數據來看,Qwen-72B在MMLU、AGIEval等10個權威基準測評中,都拿到了開源模型的最優成績,成為性能最強的開源模型,甚至超越了開源標杆Llama 2-70B和大部分商用閉源模型(部分成績超越GPT-3.5和GPT-4)。
基於Qwen-72B,大中型企業足以開發各類商業應用,高校、科研院所則能夠開展AI for Science等科研工作。
從18億、70億、140億到720億參數規模,通義千問不僅成為業界首個“全尺寸開源”的大模型,而且廣受外界歡迎。
據介紹,此前開源的通義千問系列模型先後登上HuggingFace、Github大模型榜單,得到了很多企業客户和個人開發者的青睞,累計下載量已超過150萬,催生出150多款新模型、新應用。用户可在“魔搭”社區直接體驗Qwen系列模型效果,也可通過阿里雲靈積平台調用模型API,或基於阿里雲百鍊平台定製大模型應用。
據瞭解,目前,從企業/高校到創業公司,再到個人開發者,基於通義千問開發強大的AI平台和應用,實現了業務的迅速成長的例子比比皆是。
華東理工大學的X-D Lab(心動實驗室),專注於社會計算和心理情感領域的AI應用開發。基於開源的通義千問,團隊開發出了心理健康大模型MindChat(漫談),主要提供心理撫慰、心理測評等服務、醫療健康大模型Sunsimiao(孫思邈),主要提供一些用藥和養生建議、教育/考試大模型GradChat(錦鯉),主要為學生提供就業、升學、出國留學等方面的指導。
X-D Lab團隊成員表示,從可持續性、生態和場景適配這三個維度判斷和比較,通義千問是最合適的選擇。“此前有一家企業找我們合作,我們只用20萬tokens的數據微調了Qwen基座模型,就得到了比另一家用百萬級數據微調的模型更好的效果。這證明了通義千問基座模型的能力,也證明了我們有很好的行業know-how。”
“我對72B的模型抱有非常大的期待,好奇72B在我們領域中的能力極限值。高校計算資源有限,我們可能不會用這麼大參數的模型直接做推理服務,但可能基於Qwen-72B做些學術探索,包括利用聯邦學習算法處理數據,也希望72B的推理成本能得到很好的控制。”
對於初創企業有鹿機器人而言,大模型的開源十分關鍵。該公司專注於大模型+具身智能領域,致力於讓每一台專業設備都擁有智能性。目前,有鹿機器人在路面清潔機器人中集成了Qwen-7B,使機器人能以自然語言與用户進行實時交互,理解用户提出的需求,完成用户佈置的任務。
有鹿機器人創始人、CEO陳俊波表示:“市面上能找到的大模型,我們都做過實驗,最後選了通義千問,原因在於,第一,它是目前至少在中文領域能找到的智能性表現最好的開源大模型之一;第二,它提供了非常方便的工具鏈,可以在我們自己的數據上快速地去做finetune和各種各樣的實驗;第三,它提供了量化模型,量化前和量化後基本上沒有掉點,這對我們非常有吸引力,因為我們需要把大模型部署在嵌入式設備上;最後,通義千問的服務非常好,我們有任何需求都能快速響應。”

(圖 / 有鹿機器人創始人、CEO陳俊波)
**在眾多個人開發者的眼中,通義千問代表着各種可能性。**在電力行業就職的土土,主要負責新型電力系統、綜合能源的宏觀分析、規劃研究和前期優化工作。他利用通義千問開源模型搭建文檔問答相關應用,想要探索大模型應用於電力領域的各種可能性。
“我用Qwen做基於私有知識庫的檢索問答類應用,場景很特殊,經常需要從幾十萬甚至上百萬字的文檔中查找內容,給定一個英文文檔,告訴大模型需要查找的內容,請大模型根據文檔目錄回答,在哪個目錄項下可以找到答案。”土土介紹道。
專業領域的文檔檢索和文檔解讀任務,對內容準確性和邏輯嚴謹性有很高要求。在試過的幾款開源模型中,通義千問是最好的,不僅回答準確,而且沒有那些稀奇古怪的bug。“通義千問14B的開源模型表現已經非常好,72B就更讓人期待了,希望72B能在邏輯推理方面再往前走一步。那樣的話,再加點程序手段,基本就能擺平文檔檢索和解讀任務。做好了基礎的,再把難度逐步提升,比如按照這個行業的國家級標準來要求大模型。”
目前,基於Qwen的行業模型如今涉及各行各業,包括醫療、教育、自動假設、計算機等等。
有開發者興奮地表示,除了開源大模型,最新舉辦的“通義千問AI挑戰賽”也有着很大的吸引力,既可以嘗試通義千問大模型的微調訓練,探索開源模型的代碼能力上限,也能夠基於通義千問大模型和魔搭社區的Agent-Builder框架開發新一代AI應用,“有一種站在巨人肩上,不懼挑戰、收穫成長的感覺。”
**3、大模型“起風了”**在今年11月舉辦的世界互聯網大會烏鎮峯會上,阿里巴巴集團CEO吳泳銘的一番話,讓「界面新聞·子彈財經」印象深刻:
“AI技術將從根本上改變知識迭代和社會協同的方式,由此驅動的發展加速度將遠遠超越我們的想象。”
“AI與雲計算的深度融合,將成為雲計算迭代的重要動力。‘AI+雲計算’的雙輪驅動,是阿里雲面向未來、支撐AI基礎設施的底層能力。”
“阿里巴巴將立足‘科技平台企業’定位,打造更加紮實的基礎設施底座,不斷加大開放和開源力度,和廣大開發者一起營造繁榮的AI生態。”

這些話很好地向外界闡釋了阿里的過去、現在和未來:此前,阿里的業務涵蓋物流、支付、交易、生產等多個環節,為這些環節提供數字化商業服務。在AI已成為中國數字經濟和產業創新最重要驅動力的背景下,阿里變成了一家“科技平台企業”,將為各行各業提供基礎設施服務。
他們的完整技術體系和基礎設施構建能力,正在以開源和平台服務的方式向外界全面開放,不僅提供穩定、高效的AI基礎服務體系,還將創建開放、繁榮的AI生態,藉此希望為全社會打造堅實的AI底座,實現自身的升級,也順應時代的大趨勢。
阿里雲也已經實實在在地獲得了大模型帶來的巨大收益。國內超過50%的頭部大模型企業都跑在阿里雲上。隨着智能化時代的到來,AI將成為新的生產力,阿里的不同業務、不同場景都在試水大模型,用以提升產品體驗與經營效率,打造新的增長引擎。
反過來説,大模型也在驅動着阿里雲。周靖人就曾表示,“基於通義千問大模型,我們對雲上產品也進行了AI化改造,超過30款雲產品具備了大模型的能力,帶來了開發效率的大幅提升。”這些信息也充分説明了,阿里雲要打造AI時代最開放的雲的原因。
如今,從底層算力到AI平台再到模型服務,阿里雲正在持續加大研發投入,形成了三種新的打法,即基礎設施、開源路線、開放平台,再加上IaaS層和PaaS層的迭代,這些都有利於聚攏客户、開發者和ISV,也有利於樹立典型的標杆案例。
這些優勢正在建造阿里雲乃至阿里全新的增長飛輪。當國內的開源大模型“起風了”的時候,阿里雲就是那個“風向標”。
AI算力底座、豐富且開源的產品、多元的應用場景、通過社區不斷擴大的開發者規模、工具鏈及智能化平台、開放的創新生態……阿里雲通過大模型開源,正在形成一條具有競爭力的“高質量開源基礎大模型-大模型優化-AI應用創新”的商業化落地發展路徑,這對於國內大模型產業應用的落地、創新有着非常重大的影響,勢必推動國內大模型成熟應用的規模化出現。
就像中國工程院院士、阿里雲創始人王堅所説,AI和雲計算的結合,將帶來雲計算的第三次浪潮,大模型的開源和普惠,也將改變雲計算的技術、產品和服務模式,雲服務商未來的角色和定位,也會因大模型而產生變化。