抖音跳舞不用真人出鏡,一張照片就能生成高質量視頻!_風聞
量子位-量子位官方账号-12-06 16:18
金磊 發自 凹非寺
量子位 | 公眾號 QbitAI
看!現在正有四位小姐姐在你面前大秀熱舞:

以為是某些主播在短視頻平台發佈的作品?
No,No,No。
真實答案是:假的,生成的,而且還是隻靠了一張圖的那種!

真實的打開方式是這樣的:

這就是來自新加坡國立大學和字節跳動最新的一項研究,名叫MagicAnimate。
它的作用簡單來説可以總結為一個公式:一張圖片 + 一組動作 = 毫無違和感的視頻。

然後啊,這項技術一經公佈,可謂是在科技圈裏掀起了不小的波瀾,眾多科技大佬和極客們紛紛下場耍了起來。
就連HuggingFace CTO都拿自己的頭像體驗了一把:
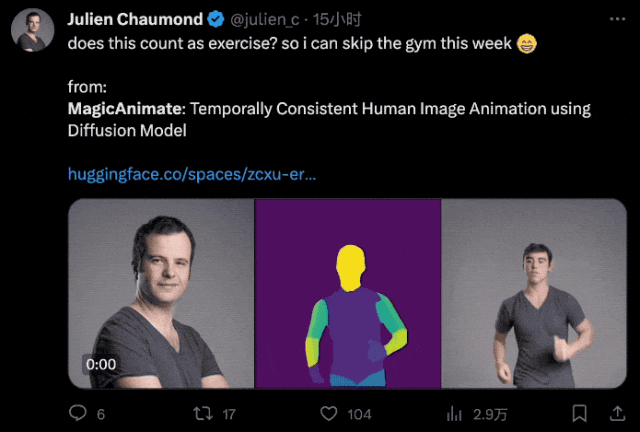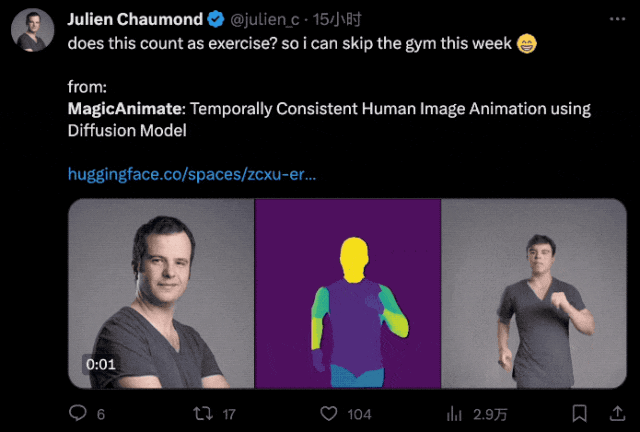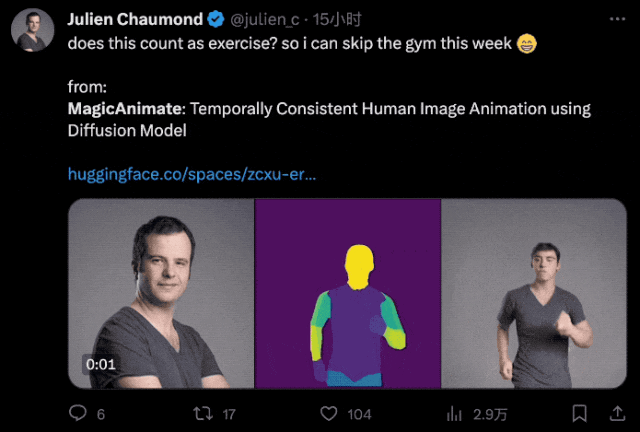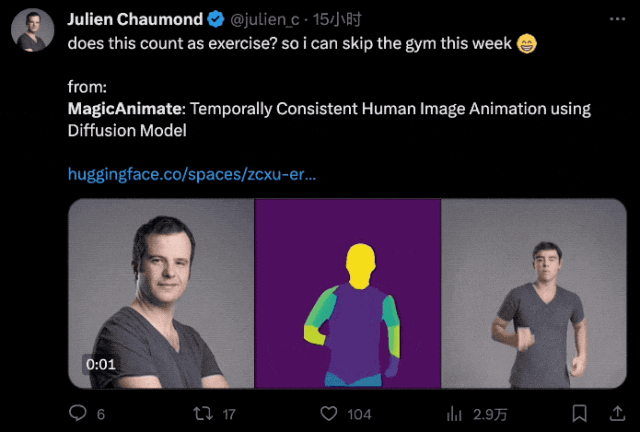
順便還風趣地開了句玩笑:
這算是健身了吧?我這周可以不去健身房了。
還有相當與時俱進的網友,拿着剛出爐的GTA6(俠盜獵車手6)預告片中的人物玩了一把:

甚至就連表情包們也成了網友們pick的對象……

MagicAnimate可以説是把科技圈的目光聚焦到了自己身上,因此也有網友調侃説:
OpenAI可以休息一下了。

火 ,着實是火。
,着實是火。
一張圖即可生成一段舞
那麼如此火爆的MagicAnimate,該如何“食用”?
話不多説,我們現在就來手把手地體驗一次。
目前項目團隊已經在HuggingFace中開放了在線體驗的頁面:
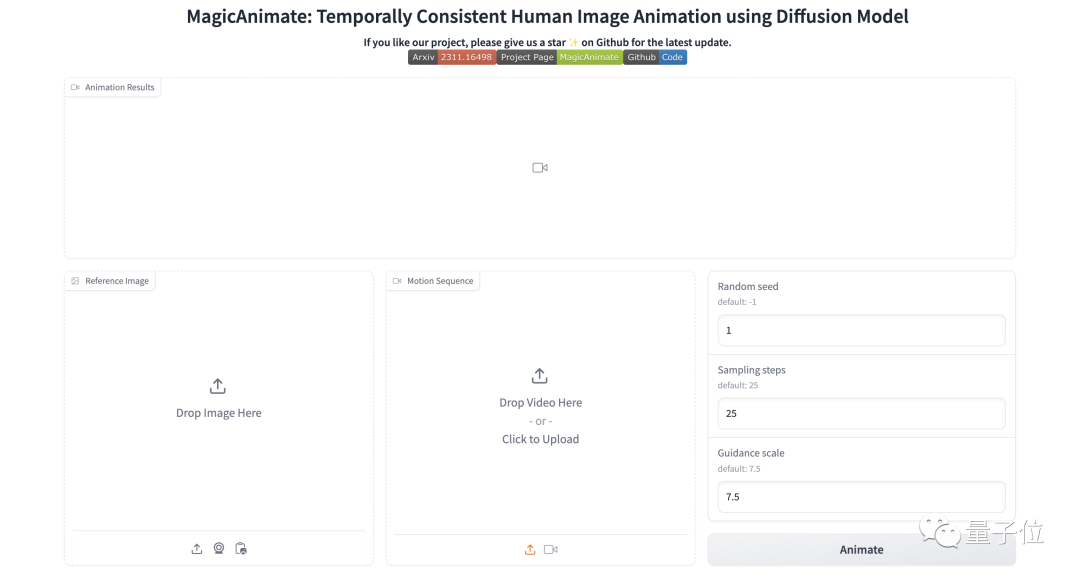
操作也是非常得簡單,只需三步即可:
上傳一張靜態人物照片
上傳想要生成的動作demo視頻
調整參數,點擊“Animate”即可
例如下面就是鄙人照片和一段近期席捲全球的《科目三》舞蹈片段:
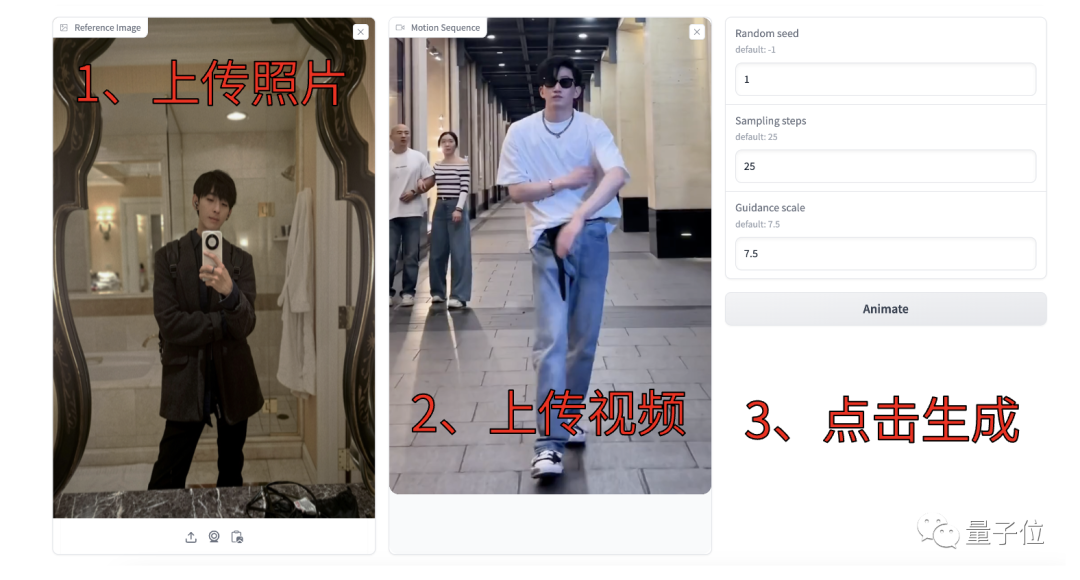
**△**視頻源:抖音(ID:QC0217)
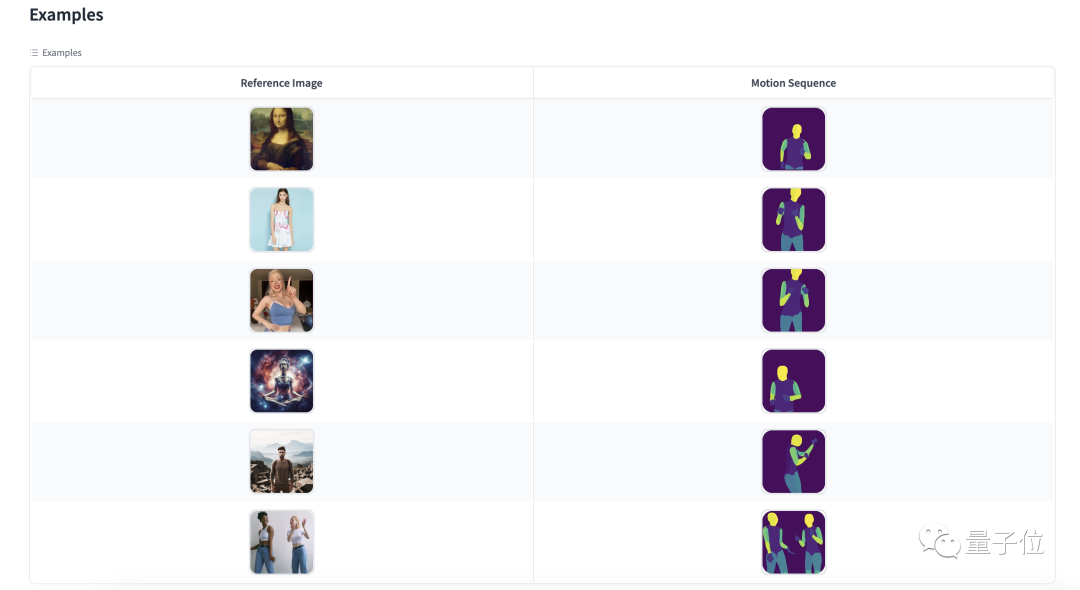
也可以選擇頁面下方提供的模版進行體驗:
不過需要注意的是,由於MagicAnimate目前過於火爆,在生成的過程中可能會出現“宕機”的情況:
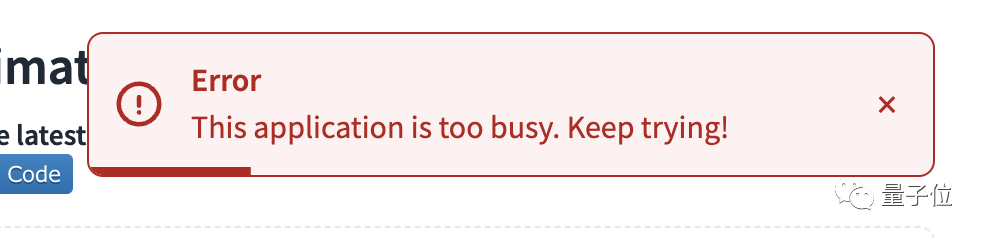
即便成功“食用”,可能也得排大隊 ……
……

(沒錯!截至發稿,還是沒有等到結果! )
)
除此之外,MagicAnimate在GitHub中也給出了本地體驗的方式,感興趣的小夥伴可以試試哦~
那麼接下來的一個問題便是:
怎麼做到的?
整體而言,MagicAnimate採用的是基於擴散模型(diffusion)的一個框架,目的就是增強時間一致性、保持參考圖像的真實性,並提高動畫保真度。
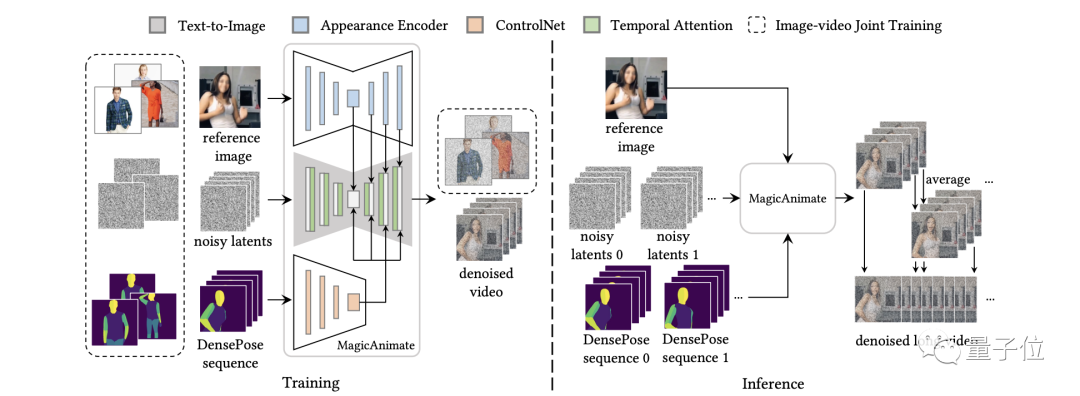
為此,團隊首先開發了一個視頻擴散模型(Temporal Consistency Modeling)來編碼時間信息。
這個模型通過在擴散網絡中加入時間注意力模塊,來編碼時間信息,從而確保動畫中各幀之間的時間一致性。
其次,為了保持幀間的外觀一致性,團隊引入了一種新的外觀編碼器(Appearance Encoder)來保留參考圖像的複雜細節。
這個編碼器與以往使用CLIP編碼的方法不同,能夠提取密集的視覺特徵來引導動畫,從而更好地保留身份、背景和服裝等信息。
在這兩項創新技術的基礎之上,團隊進一步採用了一種簡單的視頻融合技術(Video Fusion Technique)來促進長視頻動畫的平滑過渡。
最終,在兩個基準上的實驗表明,MagicAnimate的結果要遠優於以往的方法。
尤其是在具有挑戰性的TikTok舞蹈數據集上,MagicAnimate在視頻保真度方面比最強基線高出38%以上!
團隊所給出的定性比較如下:

以及與cross-ID的SOTA基線相比,結果如下:

One More Thing
不得不説,諸如MagicAnimate的項目最近着實是有點火爆。
這不,在它“出道”前不久,阿里團隊也發佈了一個名叫Animate Anyone的項目,同樣是只要“一張圖”和“想要的動作”:

由此,也有網友發出了疑問:
這似乎是MagicAnimate和AnimateAnyone之間的戰爭。誰更勝一籌?
你覺得呢?
論文地址:
https://arxiv.org/abs/2311.16498
參考鏈接:
[1]https://github.com/magic-research/magic-animate
[2]https://twitter.com/cocktailpeanut/status/1732052908227588263
[3]https://twitter.com/ProductHunt/status/1732116454647136449
[4]https://twitter.com/Gradio/status/1731992981715231162
[5]https://twitter.com/dylan_ebert_/status/1732152096621813954