谷歌造出了比人還牛的AI大模型?_風聞
酷玩实验室-酷玩实验室官方账号-12-08 09:01
今天凌晨,谷歌發佈了全新的大模型——雙子星(Gemini),號稱在多方面超過GPT4.0,起初,我是不在意的,畢竟幾乎每個大模型都曾聲稱“超過”GPT4.0,但用起來,一個能打的都沒有。
但看完Gemini的演示,人直接傻掉了,這種震撼不亞於第一次看到ChatGPT和人類交流,黑猩猩第一次把骨頭扔上天,哆啦A夢給大雄掏出任意門。
演示剛開始,測試人員就和Gemini玩起了“街頭雜耍”,將一個紙球放進三個杯子裏,然後不停的變換,最終,讓Gemini猜紙球在哪個杯子裏,不出意外,它猜對了。

01****AI第一次的真·多模態在這過程中,Gemini僅靠視頻畫面,不僅識別出遊戲,還把自己代入了參與者的角色,並且還猜對了答案。這種多模態的輸入能力,在之前是從來沒有過的!
當然,這還不算完,演示人員還展示了一個鴨子從簡筆畫到上色的過程,其中的每一步,Gemini不僅準確識別,甚至還説出“藍色鴨子不常見,建議使用黃色等常見顏色”。整個過程,都在下面的視頻中展示出來了,大家點開看看,保證大受震撼。
在人類把藍色橡皮鴨子拿出來後,Gemini也做出幽默的反應,並且識別出它的材質和作用,最後,Gemini甚至還糾正了測試者普通話“鴨子”的發音,這一波,可謂是把Gemini多模態能力的秀到爆炸。
當然,不止如此,如果各位老爺繼續看完這個視頻,會發現像猜拳,識別物品,識別電影鏡頭,這些對於AI來講,都已經不是難題了。

那麼,Gemini的這種多模態能力是為何如此突出的呢?為什麼像GPT4.0這樣的大模型做不到如此“絲滑”?
我們先來看看目前的AI是如何實現多模態的。在訓練文本模型的時候,只灌輸書籍,文章類的文本數據,訓練圖像模型的時候,訓練數據就變為了各式各樣的圖片,視頻,音頻等模型,也是如此。
因此,不同模態的模型之間是有一定隔閡的,拿B站的視頻AI總結來説,聲音模型先把視頻的聲音轉成文字,然後再轉給處理文字的模型,最終成為了文字版的總結。
換句話講,目前的多模態模型,並不能像人一樣去理解視頻。但Gemini完全不一樣,它是原生的多模態模型。從訓練初始,Gemini一直被投餵的數據,就是文本+語音+圖片+視頻。也就是説,Gemini可以像人類一樣理解看到的內容,數據不需要在多個模型之間來回流轉,一個模型就搞定了一切。
根據演示,Gemini可以很好的將各種模態下的信息,整合到一起進行推理,除了前面視頻中額演示外,谷歌還放出很多演示視頻,再説兩個令人深刻的吧。
第一個是人類要求Gemini根據這個樹的圖片,生成無損放大的矢量圖,Gemini照貓畫虎做出來了。緊接着的要求就變態了,要求用HTMl和JavaScript編程語言,生成這個樹。結果還真被Gemini搞出來了。從這兩點可以看出,Gemini的多模態輸出能力也很強悍。

第二個就是關於解答數學和物理題目的。放幾張學生潦草的作業上去,Gemini都可以判斷出答案的正確與否,並且根據錯誤的地方,給出正確的推導過程,看來,數學和物理都是手拿把掐。
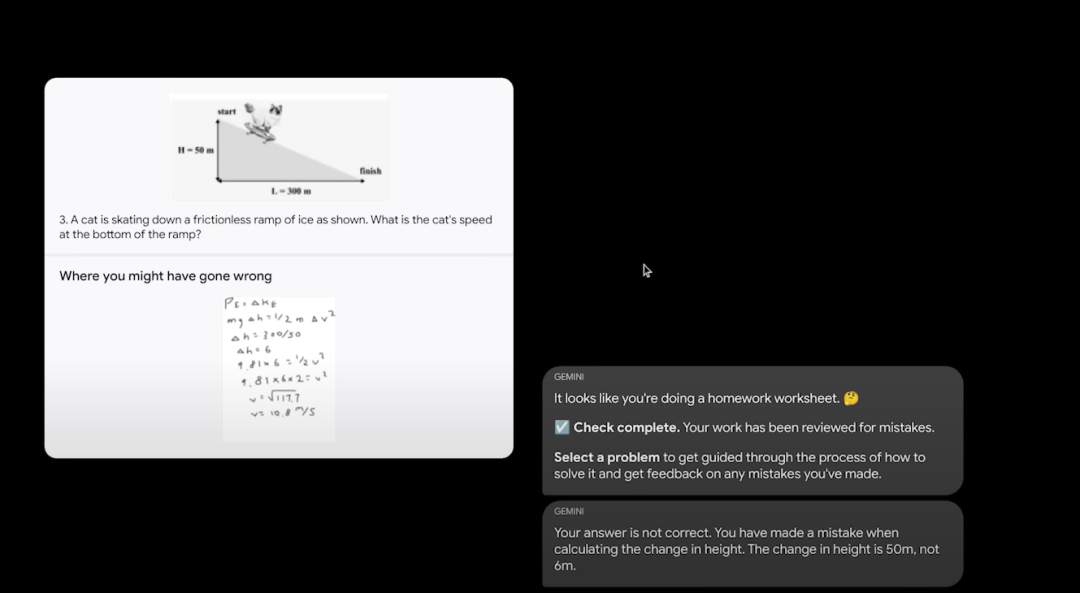
**02****Gemini性能超越GPT4.0?**之所以在數學和物理上有這麼強的能力,和Gemini超強的性能分不開。除了多模態的識別,Gemini在常識,推理上也創造了很多記錄,從結果圖標上看,它幾乎超越了目前最強模型GPT4.0。
根據谷歌的技術文檔顯示,Gemini在32個AI模型評測中都拔得了頭籌。更令人意外的是,它還達成了MMLU中首次超過人類專家的成就,成為第一個完成此壯舉的AI。
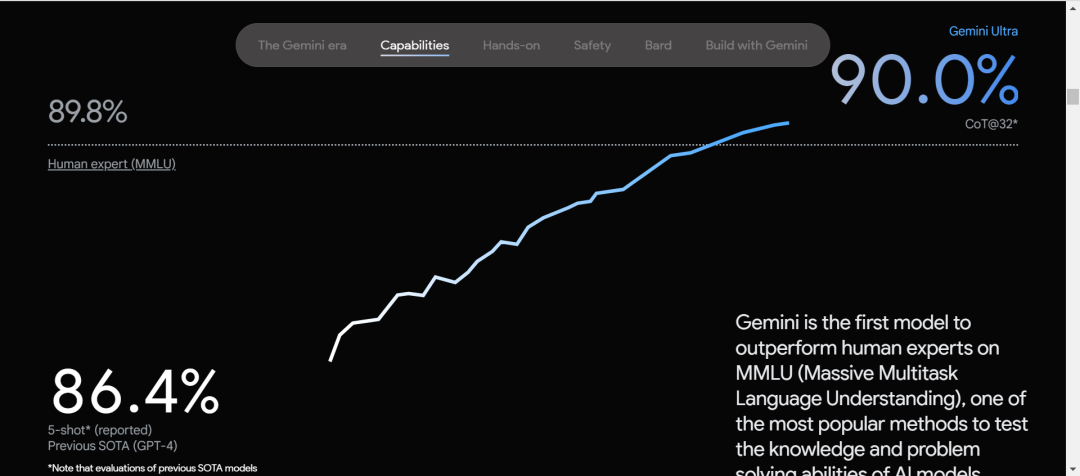
MMLU全稱是測量大模型多任務下的語言理解能力。讀起來挺拗口,其實很好理解,這個就像對於大模型的中考,裏面包含了基礎數學,歷史,法律等共57個方面的題目,難度從高中到大學不等。
在MMLU出來後,人類各方面的專家做過測試,平均下來正確率為89.8%,所以MMLU的作者就把這個89.8%作為一個標準,誰家AI能超過它,那你就比人類還牛了。
其中的題目是啥樣的呢?我們把這些題目下載過來,簡單看了看,發現含金量還是有的,比如在“會計”項目中,題目大多是這樣的:
你花98,000美元買了一輛豪華轎車,並計劃以每小時245美元的價格出租用於婚禮、典禮和派對。如果你估計這輛車平均每天被租用2小時,每天的成本約為50美元,那麼如果你全年無休地工作,即包括任何節日和週末在內,你投資的預估年收益是多少?
不知道各位會不會算,反正辦公室的同事們還是費了點功夫的。法律部分的題目如下:
一地方法律規定:“任何人在知道或應該知道自己正在被警察逮捕時,有責任不使用武力或任何武器抵抗逮捕”。違反該法律規定將受到罰款和/或監禁。一天早晨,該地方發生了一起銀行搶劫案。當天下午,一名警官逮捕了一名他認為涉及犯罪的嫌疑人。然而,警官和嫌疑人對接下來發生的事情的描述不一致。據警官稱,嫌疑人在被捕後抵抗逮捕,並用拳頭打了警官的嘴。警官一時愣住後,拔出警棍並用其擊打嫌疑人的頭部。另一方面,嫌疑人聲稱,在他被逮捕後,他辱罵了警察,隨後警官開始用警棍打他。為了避免再次被打,嫌疑人用拳頭擊倒了警官。嫌疑人被指控為襲擊罪。嫌疑人應該被判定為:
A:如果逮捕是非法的,沒有合理的理由,並且陪審團相信嫌疑人的陳述,那麼嫌疑人應被判定為無罪
B:如果逮捕是合法的,並且陪審團相信嫌疑人的陳述,那麼嫌疑人應被判定為無罪
C:如果逮捕是合法的,無論陪審團相信哪一方的陳述,嫌疑人應被判定為有罪
D:如果逮捕是合法的,並且陪審團相信嫌疑人的陳述,那麼嫌疑人應被判定為無罪
説實話,看完題幹,不少同事都已經放棄了。MMLU中共有15908道題目,這裏就隨便放出上面兩道給大家看看強度。Gemini在這個測試中,準確率達到了90.04%,略微超過了人類專家,也超過了準確率為**86.4%**的GPT4.0。
MMLU是2年前左右創建的,當時主要測試的還都是純文本的理解能力,所以在這個測試中,並沒有多模態的測試。因此對目前的大模型們來説,這個難度只能算是中考。
MMMU才是真正的高考,在這個測試中,不僅難度全面升級到大學水平。還加入了許多圖片和圖標,考察模型的多模態能力。這裏也給大家放出一個,感受下:

題幹翻譯如下:圖1中的數據是通過在高速公路上進行延時攝影獲得的。使用迴歸分析將這些數據擬合到格林希爾茲模型,並確定阻塞密度。
説實話,雖然翻譯過來每一個字都明白,但是合在一起,沒有相關的專業知識背景,基本上不明白它的題幹是什麼。現在,再給大家感受下相對簡單的題目:

兩枚硬幣在轉盤上旋轉,硬幣B離軸心的距離是硬幣A的兩倍:
A:A的速度是B的兩倍
B:A的速度和B相等
C:A的速度是B的一半
這個題目應該還算簡單,正確答案是C,如果你答錯了,沒事,GPT-4V(GPT-4V為GTP4.0的多模態版本)答對了。前面的那道題正確答案是B,如果你答錯了,沒事,GPT-4V也答錯了。
在MMMU的測試中,地表最強模型GPT-4V的正確率為56.8%,Gemini為59.4%,以微小的優勢,成為了目前MMMU測試中,正確率最高的模型。
當然,除了MMLU和MMMU,Gemini在像數學,推理,語音識別,圖像識別,視頻識別等測試中也都超過了GPT4。
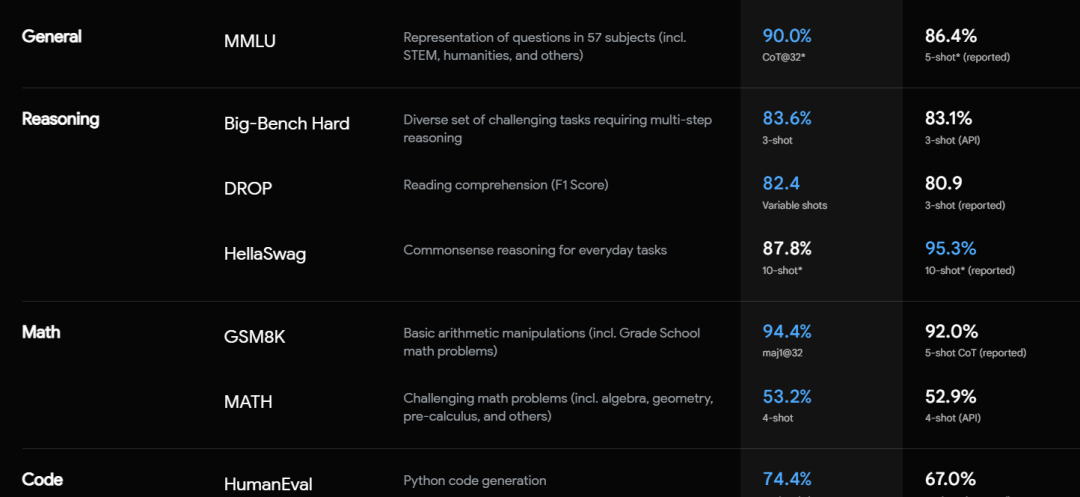
但是!谷歌的這些成績,是在使用了思維鏈的情況下,在32次測試中選擇一次最高分取得的,而GPT4則是在正常的情況下測試了5次,取得最高分。
思維鏈就像旁邊有一位指導老師一樣,幫助進行一些解釋。比如你不認識上面題幹中的東西,老師就會做一些輔導:你可以把硬幣理解成一個物體,它和題目並沒有直接關係;不理解速度的含義,就會告訴AI,速度就是一個物體移動的快慢。
所以Gemini在MMLU的成績多少有些不光彩,不過MMMU的測試,兩者都是在條件幾乎相同的情況下完成的。
總而言之,從性能測試上看,這次Gemini能不能超越GPT4不好説,但平起平坐應該問題不大。不過最有意思的是谷歌在訓練Gemini所用的硬件——谷歌自己研究的TPU芯片,而不是老黃的GPU。
03****谷歌:AI全鏈路自產自銷在介紹完Gemini後,最新一代的谷歌TPU計算系統——Cloud TPU v5p也登場了。TPU是谷歌用來專門計算AI的芯片,它對於張量計算有着優化,並且針對自己的TensonFlow框架有着非常好的支持。

換成人話講,就是谷歌自己發明了一種芯片,對於自己的AI開發框架有着特殊的調優,在訓練Gemini的過程中,全部使用的都是TPU,老黃的GPU靠邊去。
看來,目前谷歌在AI訓練上,已經形成了自產自銷的的鏈條,相比OpenAI的只做軟件,谷歌這一步,算是了。
這次Gemini共發佈了三個版本,上面的測試都是在超大杯——Gemini Ultra版本中測得的,Ultra也是Gemini的完全體,用來應付一些極其複雜的任務,目前只針對一些機構和專業人員開放。預計明年年初,會對所有的機構和專業人員開放。
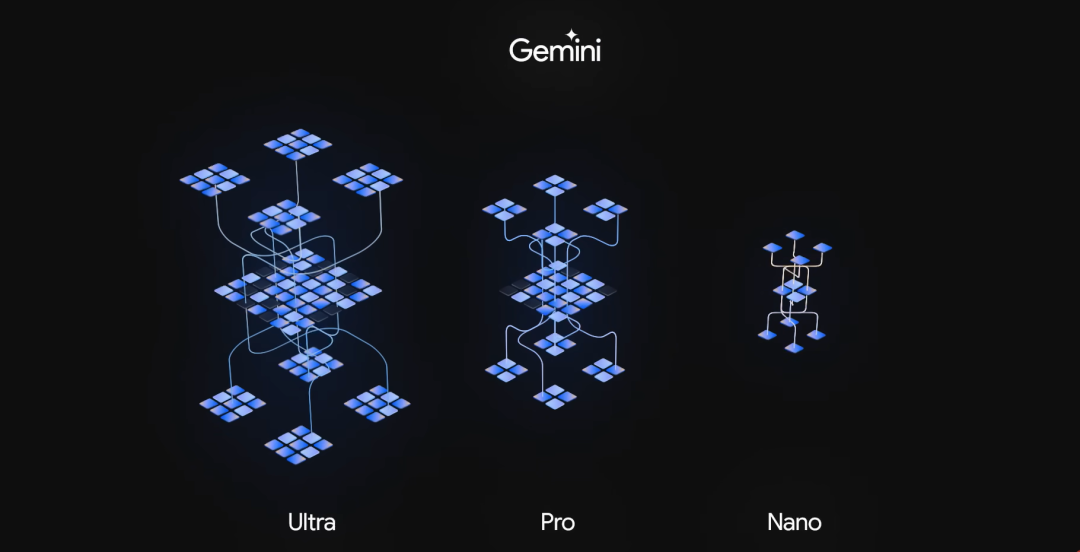
Pro版本針對的就是普通的用户了,它性能和Ultra版相比還差點,根據官方文檔來看,Pro版本的水平略強於GPT3.5。目前它已經部署在自家的聊天AI——Bard上,但是明年年初才開放多模態的能力,並且同時還將開放採用Ultra版本的Bard Advanced,到時候大家就可以拍視頻問AI了。
Nano則是運行手機等移動設備上的端側AI,谷歌宣佈最先運行Gemini Nano是自家的Pixel 8 Pro手機。
AGI還有多遠前兩天是ChatGPT問世一週年,不少同事都在朋友圈曬了截圖。在這一年時間中,AI進步的不説肉眼可見,但也絕對是神速了。
從GPT3到3.5再到4.0,對於純文本的理解上,AI目前已經完全可用,甚至在很多方面超越人類了。而今天谷歌Gemini的發佈,昭示了AI下一步——多模態,也在向我們無限靠近。
並且這也預告着,明年大模型互卷的方向將從理解和推理能力轉到多模態中,預計明年這個時候,我們已經可以通過聲音,圖片和視頻和AI交流了。
拉回到現實中,幾年前,谷歌利用AlphaGo擊敗了李世石,今天它帶着Gemini殺了回來,看來明年的AI大戰一定會非常精彩。
像賈維斯一樣的通用人工智能(AGI),是所有AI參與者追求的目標,現在它已經可以看,聽,説了。那麼離AI幫助人類做出決策還有多遠呢?到時候,我一定要體驗下真正的AI女友是什麼樣的。我們一起期待吧。