對話聯匯科技趙天成:被動智能正走向主動智能,一切都將被顛覆_風聞
极客公园-极客公园官方账号-12-12 13:29

智能體將成為全新物種,廣泛而深刻地影響人類。
作者 | 北方
編輯| 靖宇****
歷史上從來沒有哪一個時刻,比 2023 年更緊密地將 AI 與人類未來聯繫在一起。
僅僅剛剛過去的幾個月,AI 行業就上演了 OpenAI 開發者大會、Humane 推出 AI Pin、微軟 Ignite 大會、xAI 發佈 Grok、OpenAI「宮鬥劇」等行業大事件,不僅一次次引發 AI 圈密集討論,也讓更多人開始密切關注 AI 商業化與自身的未來發展。
作為「大模型元年」,AI 大模型的落地也出現不同走向。面向 C 端,以 OpenAI 為代表,將 GPT Store、人人可定製的 GPT 等切入人類生活變成新的主題;而在 B 端,「技術如何落地」「應用的可能性」這類更實際的問題,從沒有如此頻繁地出現在創業者的話語中。
卡耐基梅隆大學(CMU)「學霸」、聯匯科技首席科學家趙天成,現在還記得當年在大學攻讀博士時,看到谷歌的 AlphaGO 戰勝人類頂尖圍棋選手帶給自己的震撼。當時已經看清傳統「列規則」式的 AI 開發方式的弊端,轉而研究「AI 智能體」的他,選擇了一條「前 GPT 模式」的 AI 之路,早在幾年之前,已經預判大模型才是 AI 快速進化的正確路徑。
回國加盟聯匯科技後,趙天成和團隊就開始打磨基礎模型,將重心放在了多模態大模型領域,並在 2021 年就推出了首個自研的多模態大模型,與當下創業者仍在疲於「卷」文字大模型形成鮮明對比。
技術上的創新和務實的產品開發,讓聯匯科技利用多模態大模型的超強能力,先後獲得廣電、運營商、國家電網等多個領域的 B 端客户,成為大模型創業者中少見的功落地者。
在商業路徑上,趙天成看到當年「AI 四小龍」當下的窘境,認識到「小模型定製死路一條」的真理,堅持聯匯科技在大模型領域的不斷研發和創新。
對於當下的「百模大戰」,趙天成認為單純的「卷參數」,嘗試復現 ChatGPT 的能力,對很多創業公司來説,可能並不是唯一正確的打法。而已經在 B 端積累了相當經驗的他,認為大模型並不止 LLM 一種形式,相比而言,多模態大模型能落地的場景更多。
「GPT 只是大模型的一個路徑,但 OpenAI 的方法論可以在更多場景中做嘗試。」趙天成告訴極客公園。在他看來,在 AI 的 B 端落地上,競爭並非是「百團大戰」,而更像「叢林狩獵」,最終能獲得獵物的,並非一定是大公司。
以下為聯匯科技首席科學家趙天成採訪實錄,由極客公園整理:
01
傳統 AI 研究有上限,要做沒人敢做的事情
極客公園:你之前在加州大學攻讀計算機專業,為什麼後來又去了 CMU 進行語言技術方面的研究?
**趙天成:**我在 UCLA 電子工程系加計算機雙修,差不多三年時間就修完本科專業課程,第四年主要攻讀了一系列研究生課程,並且在 UCLA 語音技術實驗室做語音處理相關研究,開始接觸到人工智能和機器學習等前沿課題,激發了我很大的興趣。
選擇去 CMU 攻讀計算機博士學位,是因為 CMU 在 AI 領域全球排名第一,去那裏是所有 AI 研究人員的夢想。而去 CMU 計算機學院的 LTI(語言技術研究所)是因為接觸到語音處理技術之後,我感覺到這項技術,已經開始慢慢從學術界往工業界轉移了,它本身的技術部分相對來説已經比較成熟了,我想去做更前沿的基礎人工智能理論研究工業工程化相關的研究。
我當時判斷既然語音識別作為語音感知層已經相對成熟,那後續的行業趨勢肯定會做更深度的認知智能,比如理解語義,智能對話,甚至具有超出語言本身之外的推理與決策能力。CMU 的 LTI 是這個領域全球最好的研究機構,那裏的科學家研發了全球最早的語音識別引擎、機器翻譯系統、人機對話系統等等,我相信在那裏可以誕生出未來新一代的突破性人工智能技術。
極客公園:2014 年你選擇去做語音和語言研究的時候,當時的學術界是什麼狀態?
**趙天成:**NLP(自然語言處理)領域那時屬於一個交接期。當時有一批人在做偏規則型研究,也有人在做偏機器學習型的研究,或者把機器學習和規則進行結合。
在 2016 年,我發表了業內最早的一篇端到端人機對話論文,講如何用神經網絡解決整個對話系統的問題。當時通常的做法是多個規則模塊的拼接,而用一個神經網絡來完成全部的對話還是很前沿的想法,和現在的 ChatGPT 很像。這個工作也提名了當年 SIGDIAL 最佳論文獎。
我當時提出的就是,應該用一個神經網絡進行端到端的學習來實現智能對話,而不是用很多 AI 規則模塊來做人機交互系統。
極客公園:這種靈感來源是什麼?
趙天成:當時我分析了傳統的對話系統,發現通過人工建立規則或者人工建立專家系統,雖然能在短期內對系統的能力會有一些提升,但這個提升是不可持續的,因為我們不可能窮舉所有的對話場景,因此從長遠看,要實現大的 AI 飛躍,正確的路線應該是減少人工干預,依靠更強的算力,讓機器能更好地進行自學習來達到智能的提升。而不能陷入有多少「人工」,才有多少「智能」的怪圈,那樣做只能讓「人工智能」變成「人工智障」。
但是要實現機器自我學習,這個過程中有很多挑戰,因為一個人機交互系統會有很多複雜模塊,需要做自然語言理解,把它解釋成實體,在對話層面又要去做很多邏輯以及規劃,這些都要通過一個神經網絡去解決。

機器人小歐對畫面深度理解 | 小程序搜索「機器人小歐」體驗
但當時業界沒有現在這麼多的工具,在做的過程中,我們考慮的是從怎樣的點入手,把最基本的閉環走通,然後以它為基礎再去做擴展。這是我當時覺得比較容易實現、成為真正智能的 AI 的方向和路徑。
極客公園:你在 CMU 讀博期間,業內還沒有大模型這個概念出現?
**趙天成:**當時還沒有大模型這個概念,甚至連生成式模型都是少見的概念。
在碩博期間,我做了兩件事情。我在碩士期間承接了一個美國科研自然基金 NSF 的項目,當時還沒有智能音箱,我提出做一個智能體,其智能大腦可以融合各種各樣的單任務智能體能力,可能是訂餐,也可能是推薦地圖,通過一個統一的智能體和用户交流。這在當時還是很前沿的課題,類似於現在 ChatGPT 的插件系統。我和團隊在 2014 -2016 年從 0 到 1 把整個平台做出來,作為基礎科研平台,支撐了後續超過 100 多篇科研論文的發表。這個成果得到了亞馬遜、谷歌等多位人工智能專家的充分肯定。
做這個智能體的過程中,我發現靠傳統的方式去做智能體其實能力上限很低。這啓發我在博士課題中去做端到端的生成式模型,我認為只有這樣才能真正從根本上解決這個問題。所以從 2016 年之後,我基本上所有的論文都是圍繞怎樣去做更好的生成式模型,把數據「注入」進去之後,它就可以完成更復雜的任務。
極客公園:當時做的就已經是大模型,只是沒有像現在這種幾百億參數這麼大?
**趙天成:**對,只是在規模上不一樣,在核心算法這一塊非常接近,幾乎沒有差別。比如當時我訓練的是 1 億參數的模型,現在可能是 100 億參數或者 1000 億參數的模型。
極客公園:2016 年 AlphaGo 出現了,當時也引起了非常大的反響,你當時有什麼感受?
**趙天成:**當時觸動很大。因為我當時做的就是生成式模型過程中最大的兩個技術棧:偏神經網絡的設計、訓練和強化學習。
當時 AlphaGo 是強化學習一個很好的應用場景和成果。所以我們也考慮怎樣讓這種能力應用在現實場景中,因為 AlphaGo 本身的規則是固定的。但實際上我們在跟人機交互、自然語言、圖像打交道的時候有無限的可能性,難度遠遠超出下圍棋這個任務。所以我們花了很多精力去研究,怎樣將 AlphaGo 級別的端到端的機器學習應用在更廣領域,在 2018 年我們就提出了通過基於隱變量的強化學習,讓智能體學會從人類反饋中獲得更好的人機交互策略,大幅度提高任務完成的成功率,達到了當時的 SOTA 性能。
極客公園:在 2019 年和 2020 年左右,國內 AI 行業尚處於波谷期,為什麼會選擇回國創業做 AI?
**趙天成:**因為我發現不管什麼模型、什麼技術,都需要有一些匹配的應用場景,去實現它的迭代和本身價值的體現。當時我們和國內有很多交流,發現其實國內不管是視頻還是多媒體,有很多應用場景在美國可能很少見,國內反而機會更多。
一方面,國內做 AI 會有更大的應用空間,有更多的機會。另一方面,回國也是我的個人選擇,我個人還是比較有家國情懷的一個人,在美國留學這麼多年,我希望能把時間與精力放在建設自己的國家,綜合決定之後,我選擇回國實現我的理想。
02
做小模型定製,是死路一條
極客公園:當時國內 AI 行業處於什麼狀態,聯匯科技如何選擇切入市場的角度?
**趙天成:**當時國內大模型幾乎是未開啓狀態。很多大廠,包括華為、百度等也訓練過一些模型,但當時大家還沒有發現什麼實際的價值。
我回來後分析了國內 AI 行業的痛點。當時很多行業都在做 AI,比如零售 AI、客服 AI 等,這些基本上都是用傳統的小模型方式在做的,定製化程度極高,而對小模型定製來説,他的瓶頸在於每個模型不能泛用,每個場景都要從頭做起,無法沉澱積累,使得定製成本很高。這就導致了當時做 AI 商業化落地成為一件很累、很虧錢的事情。
經過研究分析,我們發現雖然市場有很多中長尾應用場景,但功能要求非常分散,這種情況和我們之前做智能體平台差不多。如果用小模型方式去做的話,很難走遠**。**所以我覺得我們既然要做,就要去做有「未來」的東西,摒棄小模型的思路,專心於大模型。而且我們根據學術界的研究成果,判斷大模型的行業爆發不會太遠。
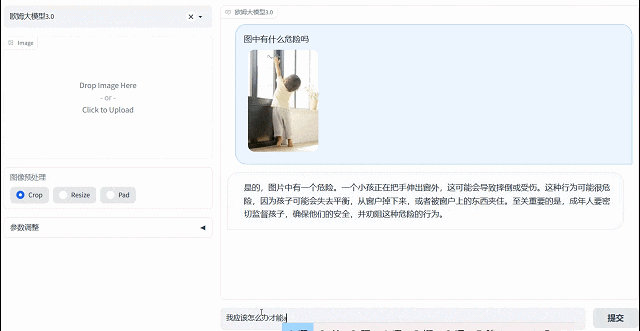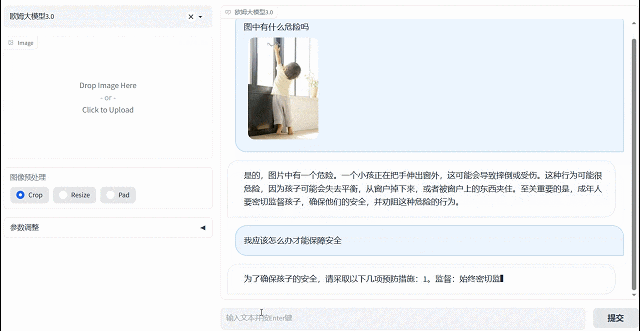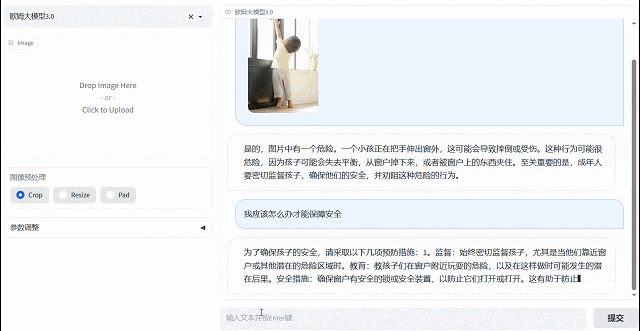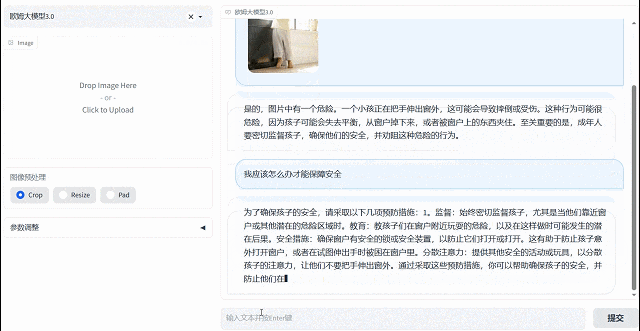
歐姆視覺語言大模型擁有主動思考分析能力
極客公園:當時你怎樣讓客户認識到這種技術案例的先進性?説服對方在這個方向投入?
**趙天成:**非常困難。當時還沒有大模型的概念,我們嘗試了很多方法去做科普,但幾乎沒人聽得懂。我們就嘗試通過和其他產品 PK 來説明我們的路線優勢,因為大模型和小模型一對比就能看到效果。比如在介紹跨模態搜索能力時,我們就和對方説以前的搜索都是需要打標籤的,但我們的搜索只要通過自然語言説一句話,就能把東西搜出來,我們不用標籤,或者説我們是「無限標籤」。
這種概念其實很多客户也還是不理解,我們只能用更具象的方式去介紹。比如**雖然我們是無限標籤,但有時候不得不説我們有幾萬個標籤,因為這樣能給他們一個具象的概念。**這些都是我們在嘗試落地時碰到的困難。
極客公園:有沒有給你印象很深的客户,你展示前他並不相信這些,展示後他被震驚到了?
**趙天成:**比如某廣電集團,他們也是我們比較大的一個客户。他們有很多視頻媒體資料,比如新聞播報類節目等,以前一年要花幾百萬進行人工編目、打標籤,來實現資產管理和檢索。當時我們説可以通過機器學習,自動生成無限標籤,可以實現任意檢索,對方不太相信,我們就給他們做測試系統,讓客户自己去驗證。然後我們再從技術底層去講解這個原理。經過幾次使用和講解之後,他們內部一些專業的技術專家也認識到這個技術路線的先進性,後續合作就比較順暢了。
極客公園:這樣的一個商業化方向是團隊經過很長時間碰出來的嗎?還是説你早就已經想到了場景和方向,只是根據客户不同來去提供支持?
**趙天成:**雖然我們當時認為大模型一定是一個方向,而且我們也一直在致力於提高大模型的基礎能力,但在商業化方向上,還是通過不斷的市場探索,慢慢摸出來的。在尋找具體應用場景時,我們當時嘗試了很多行業,也碰過很多壁。最終發現,最終我們聚焦在媒體視覺和 IoT 視覺這兩大應用場景。
極客公園:從回國到成功落地這樣的大客户,大概花了多長時間?
**趙天成:**差不多一年多時間。雖然在技術方面,我們之前在美國已經有了一些積澱,並不是回來之後從零開始做起。但在真正落地應用時,還是有很多需要改進。實際上要真正做到應用落地,需要大模型能力提升、工具鏈開發、應用場景確定、應用閉環開發以及商業模式確定等一系列因素結合起來才能實現,並不僅僅是技術問題。
極客公園:你回國的時候,國內「AI 四小龍」很受關注,經過這些年,從這些公司的起伏中能學到什麼經驗?
**趙天成:**我認為這些公司都很優秀,他們在小模型應用落地方面,做了很多嘗試,在高頻領域也有很多成功案例,但在中長尾領域都不太順利。這也反過來驗證了我的判斷——如果用小模型方式去服務中長尾場景,貌似是死路一條。
這樣的判斷,更加堅定了我們做大模型的決心。我們看到只要把大模型的商業道路走通的話,將具有巨大的市場價值。
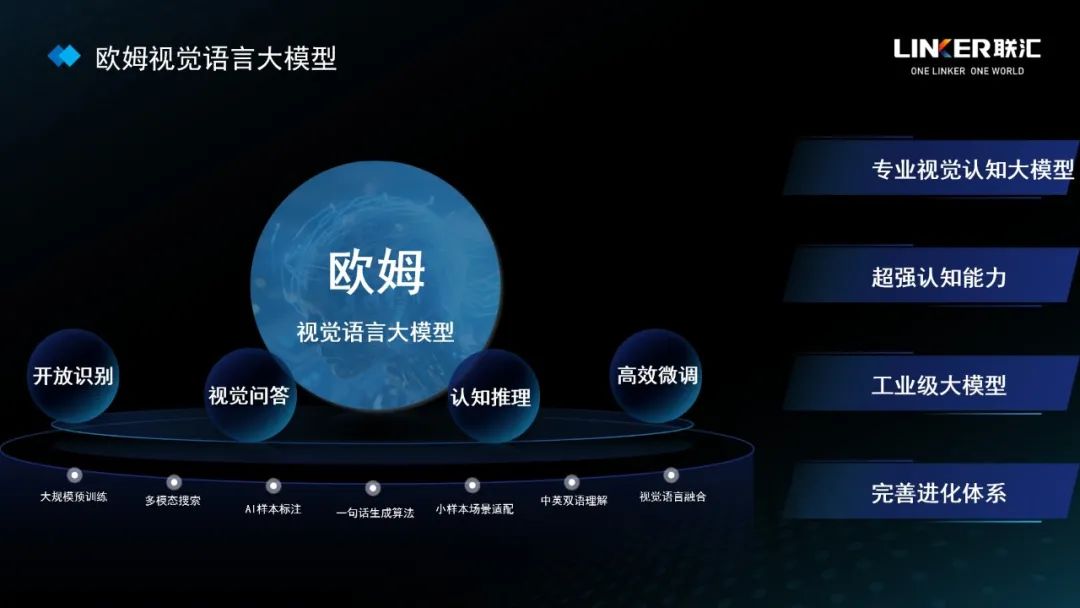
歐姆視覺語言大模型擁有四大核心能力
03
被動智能正走向主動智能,一切都將被顛覆
極客公園:在 ChatGPT 出來之前,你已經預判到大模型技術的行業趨勢,在這些年裏,你對大模型的理解有什麼變化?
**趙天成:**我是從 2016 年左右開始專注於端到端的生成式模型訓練,其核心思想和如今的大模型訓練如出一轍,也就是首先構建一個上限極高的神經網絡模型,然後通過對大量的無監督數據進行自迴歸學習,實現原本需要 N 個專家系統模塊組合而成的複合能力。在這些年裏,對於大模型學習的最大變化在於對於這種學習方式能達到的上限與發展速度一次次地刷新了我的預期,也讓我更加堅定這種方法論的正確性。
早年的時候,端到端模型能夠實現 AI 對於自然語言的流暢生成,到後面能夠根據用户的問題給出流暢的答覆就已經是非常了不起的成果了。然而現在 GPT-4 可以不但進行流暢的語言生成與問題回覆,還可以主動地選擇不同的工具,並且產生思維與推理鏈條,這個在當時是不太敢想的。當時這個過程只能靠人工去定義,不可能靠 AI 自己做出來。
現在不管多模態大模型還是大語言模型,已經逐步具備自己去產生整個推理鏈路或者決策鏈路的能力,我覺得這個是顛覆性的變化,也讓現在的 AI Agent 開始具備了主動思考與決策的能力。

聯匯科技智能管家機器人看護老人
極客公園:所以這些年的改變,讓 AI 有可能實現大範圍的商業化?
**趙天成:**對,這些年最大的變化是從以前的被動智能——用户問一個問題,AI 回答一個問題,到現在的主動智能——用户問一個問題,AI 除了回答他的直接問題,還會主動聯想到其他問題。甚至用户不用提問,AI 自己根據它的觀察,就能主動發現問題並給出解決問題的建議。
比如在零售場景下面,AI 通過視頻分析發現超市裏的咖啡打翻了,它會自己聯想到需要做清理,或者通知誰去打掃衞生。這樣從觀察到行動的決策方案,以前只有通過人工設置才可能實現,但現在就可以自動實現,這是一個比較顛覆性的變化,從被動智能進化到主動智能。

聯匯科技巡店機器人進行店面管理
當 AI 從被動智能發展到主動智能後,就有了更多的商業應用價值,就有可能實現大規模的商業化。
極客公園:聯匯科技團隊在 AI 落地場景很早就開始嘗試,現在還有哪些落地場景可以透露?
**趙天成:**現在很多 AI 應用主要還是基於純語言模型,我們的特點是專注在多模態大模型上,特別是視覺和語言兩個模態。把視覺和語言結合起來的應用場景很多。
比如在媒體領域有很多內容創作需求。我們正在用基於視覺語言大模型的智能體框架做一個產品,實現編導層面的自動化和主動智能,以解決編導們最頭痛的內容創意問題,這個產品可以根據內容主題要求,自動分析內容主體是什麼、需要什麼素材、鏡頭怎麼拆,最後要用怎樣的敍事線表達,讓 AI 去做一步步推理的過程。

視頻小歐文生視頻
另外比如國內做的比較多的智慧家居、智慧零售等場景。以前家庭或者小店裏安裝的攝像頭只是一個觀察者,只會識別預定目標,比如有人闖入,然後通知你看視頻回放,**但一旦這些攝像頭加上了主動智能後,每個設備都能主動思考,它就成了一個虛擬店長、虛擬保姆,**這些都很有想象空間。

OmBot 自主智能體:面向行業的多模態智能體系列
04
大模型 B 端市場是叢林,而不是大決戰
極客公園:聯匯科技在 AI 商業化,尤其是 B 端是很成功的,這其中有哪些經驗值得分享?
**趙天成:**B 端場景不像 C 端。B 端必然會有個性化的需求。因此怎樣用更低成本去滿足這些個性化需求是非常重要的。這幾年,我們一直致力於加強我們大模型的能力,同時開發相應的微調工具鏈,在此基礎上,用户通過 Prompt(提示詞)的方式就可以完成用户的個性化微調訓練,這就讓定製成本變得很低,創造出一種全新的用户個性化 AI 服務的方法。
我們的經驗在做 B 端服務時,一定要考慮取捨,不能走上定製小模型的路,要學會剋制,有舍有得。
極客公園:在 AI 大模型商業化落地這件事上,真正難的地方是什麼?
**趙天成:**把 AI 技術產品化,讓它滿足客户的需求有很多因素需要考慮。國內和國外市場有個很不一樣的地方,美國在很多技術方面都有更明晰的分層,生態鏈中每一個環節,都能發展出很優秀的公司。
比如説有些公司就做一箇中間件,也可以活得很好。但**是國內並不存在這樣成熟的生態體系,只做中間件很難存活。因此在國內市場,一家 AI 公司要實現商業化落地,他產品得有「厚度」才行,意味着你必然要對客户有更深的理解,要做成產品閉環。**單純把某個模塊做到極致,是遠遠不夠的。
極客公園:前不久剛剛召開 OpenAI 開發者大會,很多開發者看完覺得自己做的半年甚至一年努力都歸零了,怎麼看這種趨勢?
**趙天成:**我覺得 OpenAI 做這些商業化嘗試和我預期的差不多,他們肯定會做這些事情。Sam Altman 是很有野心的人,他肯定不會放棄這麼大的潛在市場。
OpenAI 的商業化模式,對國外的開發者衝擊確實很大,但我認為他們很快就會在這樣的生態中,找到新的機會。
前面我講到,國內和國外的 AI 生態有很大的不同,特別是 2B 市場,OpenAI 的模式很難在中國複製。國內用户的私有化部署、數據壁壘、個性化需求等特點,都會影響到商業落地模式。
因此我們還是堅持把自己的模型做好,把我們的工具鏈做好,提升自己原生的長期競爭力。同時,我們也在根據國內的商業環境,探索更多的應用形態,其中也會借鑑國內外的很多模式,它山之石可以攻玉,總的來看,OpenAI 的發展對我們的成長還是非常有利的。
極客公園:國內目前卷大模型的這個現狀,聯匯科技是怎樣看待或者應對的?
**趙天成:**我們主要從幾個方面來應對,第一,走差異化路線。回頭看「百模大戰」,其實大部分公司都是在想辦法復現 ChatGPT,到現在為止,基本上還停留在 OpenAI 早期的大語言模型階段,各家的產品很難看出差異化。而我們一開始就是走多模態路線,很多時候客户會説,文本 AI 我見過,但是能看懂圖像的好像沒見過。圖像+文本的場景應用非常豐富。因此,我們通過差異化,能夠更好滿足客户需求,並提供市場想要的產品。
另外,相較於很多公司,聯匯有不同的定位,因為我們主要服務在 B 端,就和目前市面上大部分企業面向 C 端的打法也不一樣。

聯匯科技擁有豐富完整的產品體系
還有,相較於有些公司一味地卷模型參數的大小。我們更關注的是模型的實際落地能力。大家也都知道微軟透露 GPT 3.5-Turbo 用的大模型參數也就在 200 億左右。因此模型參數多少合適,要有一個綜合的判斷,不是越大越好。
極客公園:如果現在才回國創業,大模型領域當前的紅海狀態下,你還會考慮做基礎模型嗎?
**趙天成:**假如目前從 0 去做基礎模型,相比三年前會難很多。很多團隊已經入場。但我並不認為現在大模型領域已經進入紅海階段,因為大模型本身證明了對於海量數據的學習和壓縮可以產生智能,但是 ChatGPT 也只是大模型的其中一種形式。
通過大量的預訓練,把知識融入到一個模型裏面,讓它產生通用能力,湧現出一些智能,這件事是不是隻能做語言模型?我覺得肯定不是,別的場景下面還可以有,比如圖像、3D 或者分子結構等等,因此,切準某一個領域去做,還是有很多機會的。
比如我可以專門做 3D 大模型,或者做物理世界大模型,像 World Model 這種類型。其實三年前,做語言類大模型也是有很多不確定性的,因此我覺得做基礎大模型還是有很多機會的,關鍵是要對大模型的方法論有真正的理解,以及切入點的正確選擇。
極客公園:怎樣看待和大廠在 AI 領域的關係?是完全的競爭還是説有其他可能?
**趙天成:**首先,在 AI 領域,任何時候小公司都有機會,就像美國,很多 AI 創新都是谷歌提出的,但是 OpenAI 就比谷歌做得更好。
2017 年的時候我一些朋友也在 OpenAI 實習,那時候這家公司還不到 100 人。所以在 AI 領域,創業公司並不是沒有機會,但是競爭肯定不可避免。每家公司要找準自己的定位。
對於 C 端場景,競爭肯定會比較激烈,大廠本身有較強的用户平台,小公司可能要真正有一些比較創新的應用場景,同時又有比較好的市場策略才能勝出。
不過在 B 端,我覺得不管大廠還是小廠,都不存在贏家通吃的局面,因為 B 端的行業邏輯和 C 端是不一樣的。有一個比喻説的很好,C 端可能是一種規模戰,大家是在比拼火力,我有 100 輛坦克,你有 1 輛坦克,我就能贏你。但是 B 端場景下面,大家都是叢林裏的獵人,你可能拿了一個火箭筒,我拿了一把狙擊步槍,我的火力沒有你強,但這頭鹿到底誰能打下來不一定。
*頭圖來源:聯匯科技
本文為極客公園原創文章,轉載請聯繫極客君微信 geekparkGO