字節OpenAI賬號被封禁,這事兒到底誰錯了?_風聞
差评-差评官方账号-15小时前
本文原創於微信公眾號:差評 作者:世超
 不知道各位差友聽説沒,字節的 OpenAI 賬號,被封了。。。
不知道各位差友聽説沒,字節的 OpenAI 賬號,被封了。。。
根據 OpenAI 的説法,就在上週五,他們暫停了字節的賬號,具體發生了啥,現在也還在進一步調查中。
世超也去查了查,發現事情,是由外媒 The Verge 的一則報道引起的。
據報道,字節跳動正在悄咪咪地用 OpenAI 的 API ,做一些 “ 不太光彩 ” 的事兒。

和大夥們用 AI 水週報,糊弄領導不一樣,按照 The Verge 的説法,字節直接在用 OpenAI 訓練自家的大模型。
一般遇到類似傳言,世超不會太在意,畢竟套殼大模型、用別家大模型訓練自家大模型等等,相關的消息隔三岔五就會來那麼一次。
而且都是一些風言風語,沒啥實錘,也沒啥後續。
 但這次不一樣了,報道里的內部消息,至少看起來都賊真。
但這次不一樣了,報道里的內部消息,至少看起來都賊真。
他們説是弄到了字節內部泄露的一份文件。
裏面主要講了字節的大模型項目—— “ 種子計劃 ” 的開發過程,幾乎在每個階段,包括訓練還有評估,字節的大模型都用了 OpenAI 的 API 。
另外,像是怎麼 “ 通過數據脱敏,不被人抓到小尾巴 ” 這類的內部飛書聊天記錄,也都給曝出了。

再加上 OpenAI 的直接封號,還真有點坐實了報道里內容的味道。
反正一時間,網友們都紛紛出來吃瓜,各種陰陽國產大模型的言論都出來了——
“ 怪不得國產大模型們一個個都開發得這麼快,原來是在偷師 GPT 啊? ” “ 國內的大模型都一股 GPT 味兒,原來問題出在這兒。 ”
國內媒體們都一股腦兒地轉載報道,話題還一度飆上了知乎熱榜。

而大夥們也應該發現了,爭議的中心在於,字節可能調用 OpenAI API 給自家大模型生成訓練數據。
説實話,相較與簡單粗暴,甚至有些無底線的套殼,這手段,其實文明瞭不少了。。。
 在大模型領域裏,我們一般叫它大模型的知識蒸餾。
在大模型領域裏,我們一般叫它大模型的知識蒸餾。
從名字來看,估計各位差友也能猜出來個一二三,就是用已經訓練得差不多的先進大模型,生成一些優質語料,然後再把生成的這些語料餵給更小模型。
説好聽點,大模型的知識蒸餾,是幫大家省了前期標註數據、提取優質語料庫的功夫,説難聽點,這就是在吃別人已經嚼爛的食物,好偷懶省力。
看到這兒,肯定有人會説了,大模型做出來,不就是讓人用的麼,用户愛咋用咋用,這波字節沒做錯啥啊?
話是這麼説,但是 OpenAI 早就料到了這一手,為了防止自己的數據被薅、被蒸餾, OpenAI 在自家的服務協議早就埋伏上了。
不只有企業,包括個人開發者在內, OpenAI 都禁止他們用 OpenAI 的大模型,去開發競品。

在普通用户那兒, OpenAI 也沒放過。
它給 ChatGPT 和 DALL·E 都套上了枷鎖,同樣也不讓用輸出的內容,訓練與 OpenAI 競爭的模型。

 只要你違反上面那些規定了,按照官方的説法,就只是提前知會一聲,隨時終止服務。
只要你違反上面那些規定了,按照官方的説法,就只是提前知會一聲,隨時終止服務。
這些條例就跟唐僧念符之下的緊箍咒一樣,越來越緊。。。咱明眼人也都能看出 OpenAI 在自家 “ 數據安全 ” 這塊是下狠招了。
雖説字節用的 API 不是從 OpenAI 這邊直接買的,而是買的微軟 Azure 上的雲服務 Azure OpenAI 。
但從微軟那邊買,同樣也是受這個協議約束。
或許是因為這些原因,才有了開頭先封號處理,再進一步調查字節的局面。
看着這一盆盆 “ 髒水 ” 潑過來,字節也沒乾坐着,在週末加班一一給出了回應。

 首先,他們稱在開發大模型的時候,只是在初期探索階段用了 GPT 的 API 服務,並且探索階段的模型還只是測試,沒有上線對外使用。
首先,他們稱在開發大模型的時候,只是在初期探索階段用了 GPT 的 API 服務,並且探索階段的模型還只是測試,沒有上線對外使用。
並且根據字節的説法,今年四月份他們內部就明確規定,不能用 GPT 生成的數據訓練自己的大模型。
更重要的是,他們説九月份內部還搞了個檢查,主要的任務就是看他們的訓練數據和 GPT 的相似程度。
未來幾天裏,他們還準備再來一次全面檢查,以確保嚴格遵守相關服務的使用條款。

到現在為止,反正各方的回應是一籮筐,至於字節到底有沒有違反 OpenAI 的服務協議,從現在的信息來看我們也做不出啥判斷,只能等後續雙方溝通的結果。
不過,在訓練大語言模型這塊,數據來源的爭議其實一直都蠻大。
OpenAI 訓練大模型的時候,也曾在數據上栽了不少跟頭。
就比如 ChatGPT ,它主要就是爬取一些社交媒體網站、或者論壇、貼吧上的數據。
剛開始,這些數據他們都是免費爬的,但後來 OpenAI 的 ChatGPT 還有 DALL·E 慢慢出圈,一些問題就連帶着浮出水面了。
 這兩個大模型爆火的那段時間, OpenAI 吃的官司是一個接一個。
這兩個大模型爆火的那段時間, OpenAI 吃的官司是一個接一個。
文生圖大模型被各種圖片網站、藝術家們起訴,大語言模型被社交平台上的博主索賠。。。
與此同時,各大平台也都開始注重數據價值,像是美版貼吧 Reddit ,還有程序員問答網站 StackOverflow 等等這種優質語料多的網站,都開始設置付費門檻,交錢才能爬取數據。
但在此時 OpenAI 的大模型已經發育起來了,過去網絡上的數據該爬的也都爬了。
這下就苦了那些後來者,前期還不僅要做一些標註語料庫的重複勞動,還得付費再爬一遍數據。

 不過世超覺得,這次真如 The Verge 報道中説的,那這個 “ 鍋 ” 鐵定還是要字節來背,畢竟相關的條例,早就寫在協議裏了,拿人家的手短,人家還真有理。
不過世超覺得,這次真如 The Verge 報道中説的,那這個 “ 鍋 ” 鐵定還是要字節來背,畢竟相關的條例,早就寫在協議裏了,拿人家的手短,人家還真有理。
最後,世超想説的是,自從大模型流行以來,業內類似的爭議也好、醜聞也好,其實基本就沒斷過。
就比如前不久,李開復的大模型 Yi 被扒出是 “ 套殼 ” Meta 的 LLaMA ,雖説後者也是開源的,但要用也得註明。
但李開復還是在網上輿論發酵之後,才不痛不癢地回應了句命名疏忽。。。

更離譜的是,大模型內部還和機圈兒一樣,流行起了跑分熱。
有的企業為了讓自己的模型分數更好看一點,直接搞起了小動作。
前段時間谷歌的 Gemini ,為了讓自家模型的分數比 GPT-4 好看,在測試方法上就動了些手腳。

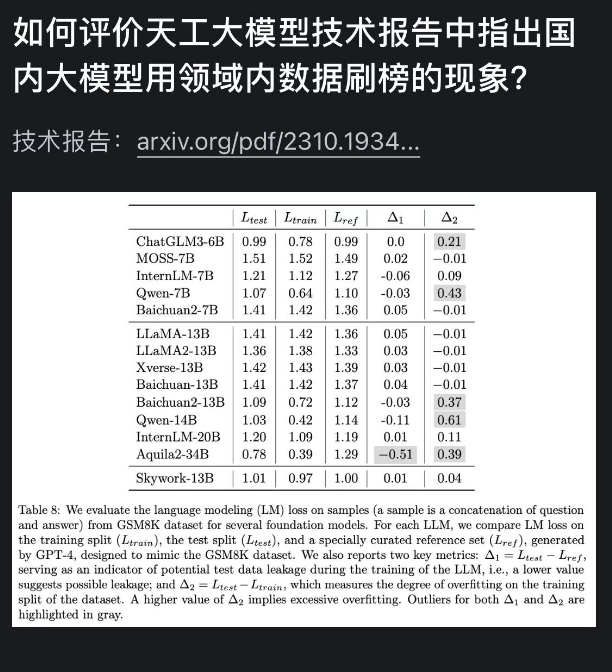
 國內某團隊也曾發佈過技術報告,裏面明晃晃地指出了大模型刷榜的亂象。
國內某團隊也曾發佈過技術報告,裏面明晃晃地指出了大模型刷榜的亂象。
他們直接把測評的題目,先餵給了自家大模型。
相當於是開卷刷榜,讓自家的大模型在一羣**“ 做題家 ”**中脱穎而出。
當然,新興領域一開始都是亂象叢生,有這些醜聞也不是啥新鮮事兒。
世超也希望,未來,大模型廠商們能主打一個誠實,別今天暴打 GPT-4 ,明天又暴打 OpenAI 的了。
還有用了誰誰誰的數據,用了哪些開源資源,也大大方方承認,作為一個追趕者、學習者,其實沒啥丟臉的。。
 再回到字節和 OpenAI 這檔子事兒,要是真相水落石出,字節確實是被冤枉,世超也希望 OpenAI 和媒體們能立馬化身牆頭草,還字節一個清白。
再回到字節和 OpenAI 這檔子事兒,要是真相水落石出,字節確實是被冤枉,世超也希望 OpenAI 和媒體們能立馬化身牆頭草,還字節一個清白。
少一些套路,多一些真誠,大模型可以有幻覺,人嘛,還是實誠點好。
圖片、資料來源:
網絡
TheVerge,ByteDance is secretly using OpenAI’s tech to build a competitor
