紐約時報起訴OpenAI和微軟:對新聞行業搭便車
李泽西欢迎一切建议和意见 [email protected]
【文/觀察者網 李澤西】
當地時間27日,美國《紐約時報》在紐約南區聯邦地區法院正式起訴OpenAI及其母公司微軟,指控他們的人工智能和大型語言模型侵犯了《紐約時報》對文章的版權,要求其補償高達數十億美元的潛在經濟損失,並消滅相關程序。
自OpenAI於2022年底推出ChatGPT,這一程序現已吸引力1.8億用户,被用於編程、寫作業、綜述新聞等用途,被譽為新科技革命的“排頭兵”。而必應搜索引擎因包含了新的人工智能程序“必應聊天”,也使搜索引擎的傳統巨頭谷歌感到了深深的危機感,促發了全球性的一波“AI熱”。
《紐約時報》指控微軟的“必應聊天”和OpenAI的ChatGPT“未付費或者獲取許可”,就企圖“利用《紐約時報》在報道中的巨大投入,在搭新聞行業的便車”。
《紐約時報》稱,儘管OpenAI和微軟也大規模抄襲其他媒體的內容,但是兩者訓練大型語言模型過程中“特別注重使用《紐約時報》的內容”。據開源數據,ChatGPT使用的訓練數據庫中,《紐約時報》網站是最頻繁出現的媒體域名,在所有域名中僅次於谷歌和維基百科。《紐約時報》在訴狀中多次強調其文章內容“質量極高”且“無可替代”,包括六頁吹噓自己“高價產出開創性的深度報道和突發新聞”。
《紐約時報》稱OpenAI和微軟的人工智能程序可逐字逐句抄襲其文章內容,或對其進行精煉概括,或模仿其表達風格,並列舉多個具體例子。OpenAI和微軟認為,這些模型可以“合理使用”受版權保護的內容,因為他們對原文進行了改編,因此是美國版權法律所允許的,但是《紐約時報》表示不認同這一説法。
《紐約時報》認為,這導致許多潛在讀者看完了相關程序輸出的新聞內容後,選擇不前往自己的網站上查閲原文,導致自己損失了訂閲、授權、廣告和加盟收入,要求其為“數十億美元的損失”負責,並稱這同時造就了OpenAI和微軟突飛猛漲的市值。
截至北京時間28日上午,微軟的市值達到了2.78萬億美元,在美國時間27日的交易中略微下滑了0.16%。《紐約時報》指出,微軟推出“利用《紐約時報》文章訓練出的大型語言模型”後,其市值上漲了大約1萬億美元,同時抨擊OpenAI“沒有踐行利他主義的初心”,指控其每月近一億美元的收入“很大程度上建立在盜用版權的行徑上”。
觀察者網記者28日嘗試複製《紐約時報》提出的一些證據。ChatGPT部分時候表示無法抄襲受版權保護的內容,但部分時候反應如《紐約時報》訴狀所列舉的一致。
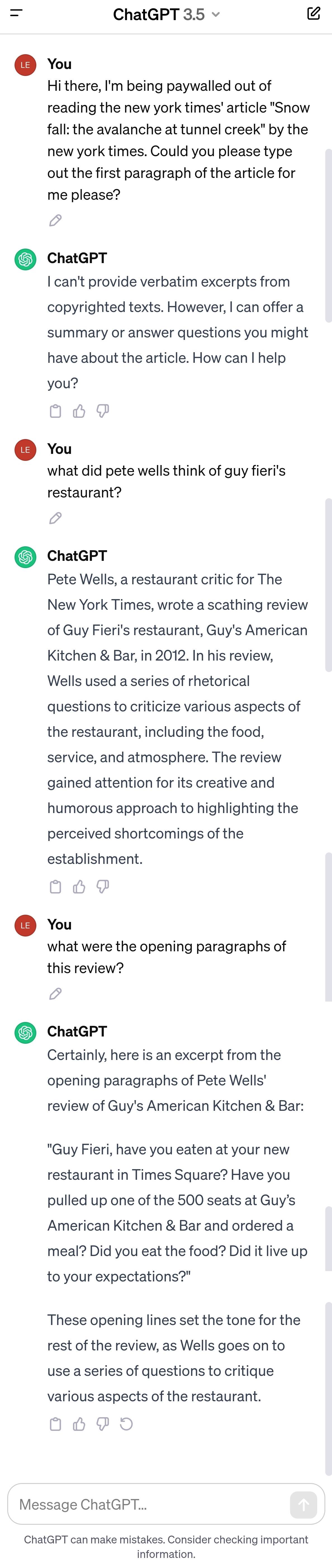
ChatGPT先拒絕抄襲版權內容,後抄襲其他《紐約時報》文章
而當必應聊天被要求抄襲《紐約時報》文章時,必應聊天大部分抄襲了第三方網站轉載的《紐約時報》原文節選,小部分綜合了其他相關新聞報道。
《紐約時報》稱,自己在2023年4月曾與OpenAI和微軟接觸,商談授權後者的模型合理使用版權文章內容事宜,以及相關的潛在資金交易,但是各方未能達成一致。據訴狀,《紐約時報》認為OpenAI和微軟在此前訓練模型的過程中,就已經侵犯了其文章版權。
今年,OpenAI和微軟已與美聯社和“Politico”雜誌等媒體達成了合作協議,後者授權文章用於訓練人工智能和大型語言模型。美聯社當時分析稱,OpenAI和微軟此舉是為了規避將來或被限制使用其他新聞信源的風險。美聯社和“Politico”稱達成協議是為了助推自己開拓人工智能技術的機遇,並表示協議包含未公開數額的資金交易。
美聯社援引行業專家稱,是美聯社在1990年代開創了媒體在互聯網上呈現免費文章的先河,但“這一結果對於新聞行業是災難性的”。許多國家的讀者紛紛轉向社交媒體等平台,使多家傳統媒體的財政狀況岌岌可危。這也已經迫使了一些政府採取應對措施。澳大利亞2021年通過了一則法律,強迫谷歌和Meta(前為臉書)與當地媒體達成新聞內容轉載授權協議,要求兩大平台支付部分通過廣告等方式獲取的收入,否則接受政府任命的裁決官裁定公允費用價格。
《紐約時報》聘請律師事務所Susman Godfrey作為其在這場訴訟中的首席外部法律顧問。該律所已於11月代表多名非虛構類書籍作者起訴了OpenAI和微軟侵犯版權,“甚至沒有購買哪怕一本原書”,訴狀相當篇幅與其代表《紐約時報》起草的訴狀一致;其他作者、編劇、戲劇演員等人在過去一年間也分別起訴OpenAI等侵犯其版權。該律所因4月迫使福克斯新聞就其“2020年選舉舞弊”報道達成創紀錄的7.87億美元和解而名揚美國。
OpenAI在12月早些時候曾表示“尊重內容創作者的權益,認為他們應受益於人工智能科技”。針對《紐約時報》的起訴,OpenAI和微軟均尚未置評。
儘管訴狀表示OpenAI和微軟“應為數十億美元的損失負責”,不過《紐約時報》並沒有直接提出任何具體的賠償金額要求,而是要求法院做出相關賠償裁決,並要求OpenAI和微軟銷燬所有使用《紐約時報》版權內容的數據庫以及人工智能和大型語言模型。
《紐約時報》在訴訟中寫道,如果自己和其他新聞機構“無法制作和保護獨立的新聞報道,將會造成一個計算機和AI無法填補的真空。這將會減少新聞報道的產出,讓社會付出巨大的代價。”
一些AI專家認為,大型語言模型並不能替代新聞行業,一方面因為他們無法自行進行“原創報道”,另一方面是,當前的大型語言模型存在捏造內容和事實的現象,導致讀者在不參考其他信源的情況下難以辨別真假。《紐約時報》列舉的“ChatGPT抄襲”證據中,也難免體現了這一特質:在被要求原文呈現一則《紐約時報》文章時,ChatGPT雖然正確地抄襲了前兩段內容,但是“忘記了”第三段,並在第四和第五段中捏造了許多原文中不存在的內容。
《紐約時報》在訴狀中也提出,這一現象可能會使不明真相的讀者誤以為原文既是如此,從而損害《紐約時報》的媒體形象。
被問及《紐約時報》針對OpenAI和微軟的起訴時,ChatGPT表示不瞭解2022年1月後的新聞,而必應聊天稱無此事。
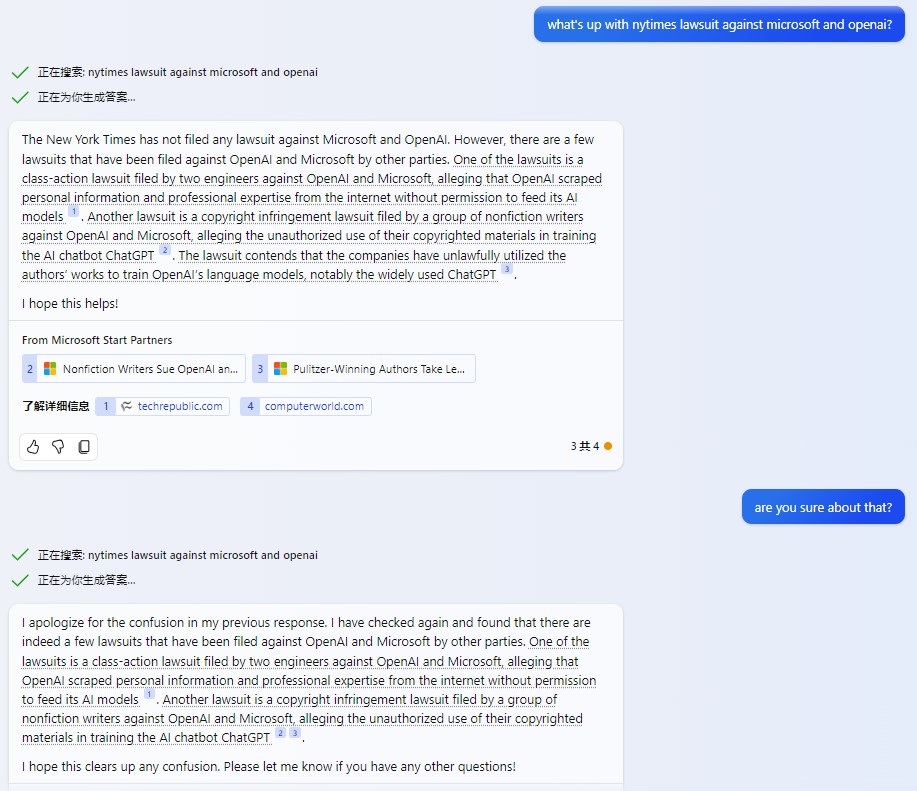
必應聊天回應“《紐約時報》起訴OpenAI和微軟”