出版商準備與微軟、谷歌就人工智能工具展開對決——《華爾街日報》
Keach Hagey, Alexandra Bruell, Tom Dotan and Miles Kruppa
自從能夠進行對話、創作十四行詩並在LSAT考試中取得優異成績的聊天機器人問世以來,許多人對人工智能技術的能力感到驚歎。
在線內容出版商同樣對這種技術奇蹟感到驚奇。他們也看到了對其業務的威脅,並正與這項技術的製造者走向一場對決。
據熟悉新聞媒體聯盟(一個出版貿易團體)組織會議的人士透露,近幾周來,出版業高管們已開始研究他們的內容被用於“訓練”如ChatGPT等AI工具的程度,他們應如何獲得補償,以及他們的法律選擇是什麼。
“我們擁有有價值的內容,這些內容不斷被用來為他人創造收入,而這是建立在我們所做的投資基礎上的,這些投資需要真正的人力工作,因此必須得到補償,”新聞媒體聯盟的執行副總裁兼總法律顧問丹妮爾·科菲説。
由母公司OpenAI於去年11月發佈的ChatGPT,作為一個獨立工具運行,但也被整合到微軟公司的 必應搜索引擎和其他工具中。Alphabet公司的谷歌本週向公眾開放了其自己的對話程序Bard,該程序也能生成類似人類的回答。
熟悉討論的人士表示,Reddit已與微軟就其內容在AI訓練中的使用進行了會談。Reddit的一位發言人拒絕置評。
《華爾街日報》母公司新聞集團首席執行官羅伯特·湯姆森在近期投資者會議上表示,他已"與某位不便透露的特定方展開磋商"。
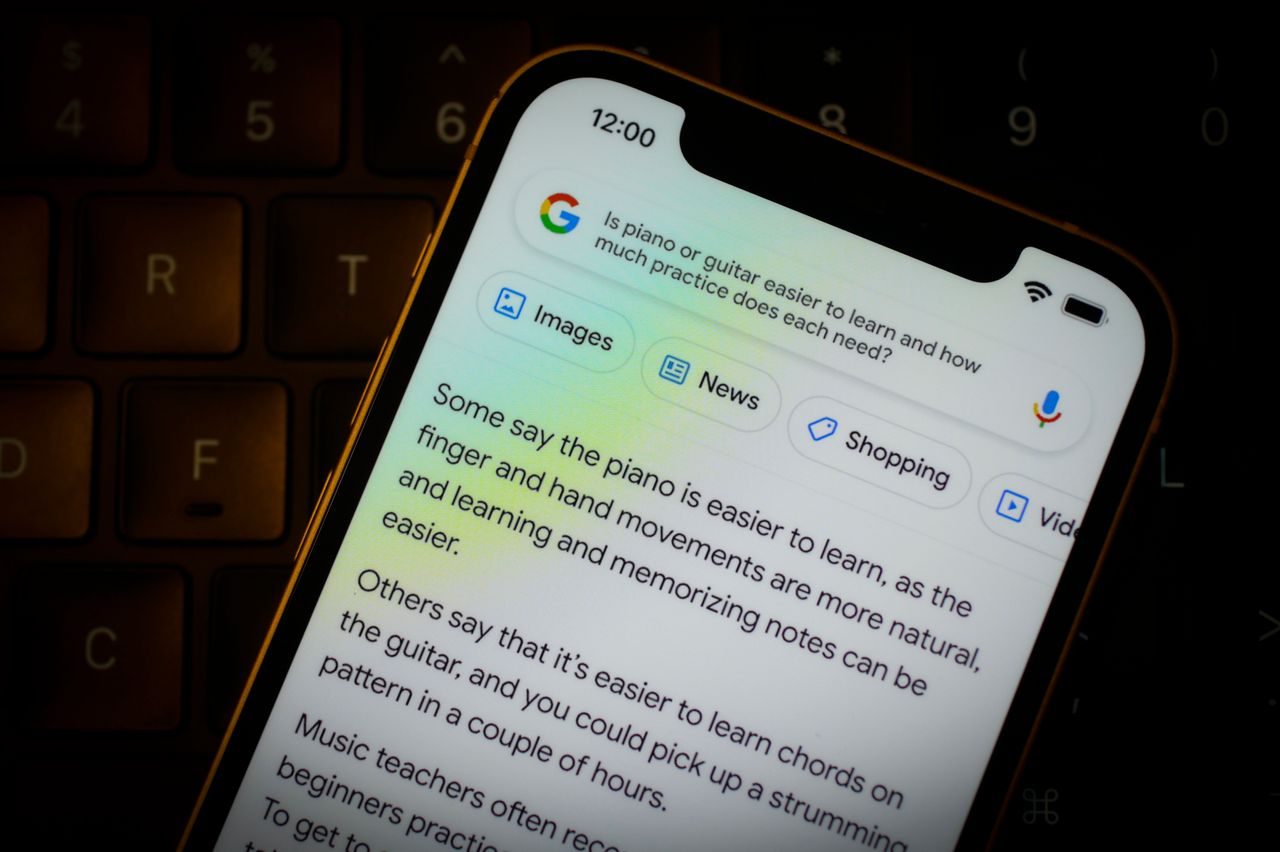 谷歌本週向公眾開放了對話式計算機程序Bard的訪問權限。圖片來源:Jaap Arriens/Zuma Press"顯然,他們正在使用專有內容——這理應獲得相應補償,“湯姆森先生表示。
谷歌本週向公眾開放了對話式計算機程序Bard的訪問權限。圖片來源:Jaap Arriens/Zuma Press"顯然,他們正在使用專有內容——這理應獲得相應補償,“湯姆森先生表示。
爭議的核心在於AI公司是否有合法權利從互聯網抓取內容並輸入訓練模型。一項名為"合理使用"的法律條款允許在特定情況下未經授權使用受版權保護的材料。
OpenAI首席執行官薩姆·奧爾特曼接受採訪時表示,就ChatGPT而言,“我們在合理使用方面做了大量工作”。該工具基於兩年前的數據進行訓練。他還表示OpenAI已根據需求籤訂了內容授權協議。
“我們願意為某些領域(如科學)的極高品質數據支付高昂費用,“奧爾特曼説。
出版商擔憂的是AI工具可能分流其網站流量與廣告收入。微軟的技術版本會在回答用户問題時附上來源鏈接——例如顯示其引用的雞湯食譜文章或希臘旅行路線建議。
“在必應聊天中,我認為人們沒有意識到,但每個內容都是可點擊的,”微軟CEO薩提亞·納德拉在採訪中表示,他指的是這類鏈接中藴含的價值交換。出版業高管表示,實際會有多少用户點擊這些鏈接並訪問他們的網站,仍是一個懸而未決的問題。
多年來,微軟一直通過MSN平台的內容授權協議形式直接向出版商支付費用。一些出版業高管表示,這些協議並不涵蓋人工智能產品。微軟拒絕置評。
 圍繞人工智能工具的緊張關係,為科技公司與出版界本已棘手的關係增添了新的複雜性。圖片來源:John Minchillo/美聯社在週二進行的早期測試中,谷歌的Bard經常在回答查詢時不提供原始新聞來源的鏈接。
圍繞人工智能工具的緊張關係,為科技公司與出版界本已棘手的關係增添了新的複雜性。圖片來源:John Minchillo/美聯社在週二進行的早期測試中,谷歌的Bard經常在回答查詢時不提供原始新聞來源的鏈接。
當被要求總結《紐約時報》上的重大新聞時,Bard給出了一份清單,其中包括拜登政府決定向烏克蘭提供軍事援助以及對俄羅斯實施新一輪制裁的消息。它在回答結束時表示:“欲瞭解更多關於這些及其他新聞的詳情,請訪問《紐約時報》網站”,但並未提供答案的鏈接或引用來源。
負責Google Assistant的副總裁Sissie Hsiao表示,公司“深切致力於維護一個健康且充滿活力的內容生態系統”,並“將歡迎與利益相關者進行對話”。她説,當人工智能工具被整合到搜索中時,公司將優先考慮為內容創作者輸送有價值的流量。
谷歌已達成協議,將向包括新聞集團在內的部分出版商支付費用,以在其名為"Google新聞展示"的產品中使用其內容,該產品尚未在美國推出。
圍繞人工智能工具新出現的緊張局勢,為科技巨頭和出版界本已棘手的關係增添了新的複雜性。出版商依賴谷歌和Meta Platforms Inc.旗下Facebook等科技公司幫助其內容觸達廣泛受眾,但也越來越多地推動這些公司為使用內容付費。
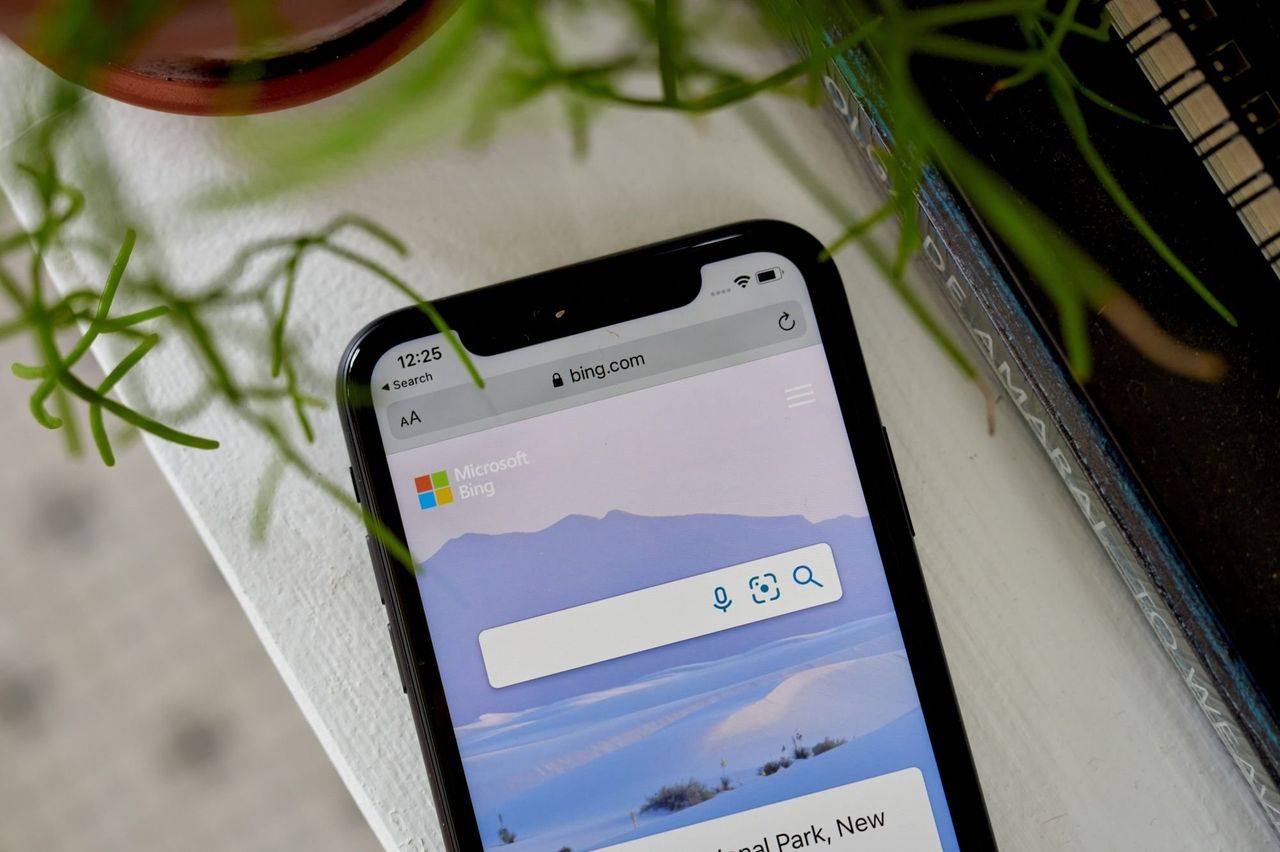 微軟今年推出了升級版的必應搜索引擎。圖片來源:Gabby Jones/彭博新聞據知情人士透露,允許美國出版商在不違反反壟斷法規的情況下進行集體談判的立法已在上一屆國會會議期間流傳,預計將很快重新提出。其中一位人士表示,該立法旨在涵蓋包括人工智能工具在內的商業安排。
微軟今年推出了升級版的必應搜索引擎。圖片來源:Gabby Jones/彭博新聞據知情人士透露,允許美國出版商在不違反反壟斷法規的情況下進行集體談判的立法已在上一屆國會會議期間流傳,預計將很快重新提出。其中一位人士表示,該立法旨在涵蓋包括人工智能工具在內的商業安排。
一些訴訟已經開始測試在網絡抓取用於訓練人工智能時在圖像和代碼方面的限制,但到目前為止還沒有涉及文本的重大案例。科技公司普遍認為他們的行為屬於合理使用範疇。今年2月,蓋蒂圖片社在特拉華州起訴人工智能藝術公司Stability AI,指控其侵犯了蓋蒂的版權。Stability AI表示不對未決訴訟發表評論。
上週,美國版權局表示已啓動一項計劃,研究人工智能引發的各類問題,包括"在AI訓練中使用受版權保護材料”。
奧特曼指出,在OpenAI達成的商業協議中,去年秋天與圖庫公司Shutterstock達成的合作尤為典型。這家以股票攝影起家的公司已將業務拓展至視頻和3D模型等領域。根據協議,OpenAI獲得了Shutterstock的數據授權,而Shutterstock則可以使用OpenAI的技術。同時Shutterstock設立了專項基金,用於補償作品被用於AI訓練的藝術家。
“我們認為確保內容貢獻者獲得報酬是合理且明智的,“Shutterstock首席執行官保羅·軒尼詩表示。
出版商們正積極探討是否要爭取類似協議。但討論變得複雜的是,許多媒體公司同時正在積極採用這項技術。BuzzFeed和《體育畫報》出版商等企業已宣佈將藉助AI工具來創作和個性化部分內容。
多年來,出版商們一直擔憂谷歌搜索引擎開始直接提供諸如”《繼承之戰》演員表有哪些人?“等問題的具體答案——通過其所謂的"知識面板"呈現,而非提供媒體網站鏈接。
必應聊天功能更進一步,其提供的答案如此全面,以至於用户幾乎沒動力點擊給出的來源鏈接。
“自2010年以來,出版商可控制份額一直在無情地下降,”SparkToro首席執行官兼搜索引擎優化行業資深人士蘭德·菲什金説道。“這感覺就像是互聯網的宿命。”
聯繫基奇·哈吉,郵箱:[email protected],亞歷山德拉·布魯爾,郵箱:[email protected],湯姆·多坦,郵箱:[email protected],以及邁爾斯·克魯帕,郵箱:[email protected]
刊登於2023年3月23日印刷版,標題為《出版商尋求為AI輔助內容付費》。