對話小冰CEO李笛:聽到要卷AI應用,我挺擔心「重蹈覆轍」_風聞
极客公园-极客公园官方账号-1小时前

AI 針對 2C 和 2B 的滲透,這一次會衝鋒成功嗎?
作者 | 連冉
編輯| 鄭玄****
因為去年幾次給行業「降温」的言論,最近小冰公司 CEO 李笛被人打上了「看衰大模型」和「AI 舊世代」的標籤。
李笛有點無奈,「去年火了以後這個行業就是這樣。一開始是誇大模型厲害,後面光誇不夠你得説自己信仰大模型;更後面説信仰都不行,你還得用若干辭藻堆砌來表達你對大模型的熱情,才是個現代人。」
2 個小時的訪談裏,他幾次提出希望我們不要用「大模型時代」來形容這股浪潮。他認為技術的發展趨勢不會是一條一直向上的斜線,而會是經歷一波又一波的週期。2013 年就開始做 AI 的李笛和小冰,已經經歷過 AI 的幾個週期。在他看來,大模型給 AI 帶來了一個新的波峯,而不是開啓了一條新的曲線。
近日,小冰公司宣佈已經成功獲得「小冰大模型」國內備案,包括小冰克隆人、歌手克隆人分支等在內的一系列測試產品靜默期結束,轉為正式發佈。這些產品在過去半年的測試中積累了數十萬的創作者用户,但都不是所謂的大模型原生應用,而是在原有的產品上利用大模型的技術能力對一些關鍵環節升級,從而提升了用户的使用體驗。
對行業週期的認識一定程度上成為了過去一年小冰的大模型「行動綱領」。比如在產品上,小冰不會一味追求所謂的「大模型原生」;比如在經營上,小冰不會為了提升短期關注度而去卷熱點,甚至會在市場教育還沒完成的時候就先考慮「自限」,規避 AI 可能造成的倫理風險;當然在言論上,李笛也更加保守。
過去一年,這給小冰似乎帶來的更多是一些「壞處」。不卷熱點和參數,讓小冰少了一些爆點,也成了部分人質疑他們是舊派的依據,一定程度上也讓他們沒那麼容易拿到以熱錢為代表的行業紅利資源。
但李笛依然認為這種冷靜是必要的,他説小冰不去追熱點,不去為了流量做一些事情,其實是早年已經踩過或者看人踩過同樣的坑。**「流量會帶來關注和熱錢,但這個行業其實不缺少這些,真正需要解決的問題是找到長期可持續的商業模式。」**而一味追求流量、熱點和熱錢,比如去卷榜單、做開源或者追熱點,只會讓商業模式變形。
所以當我們提到最近行業談論比較多的「卷應用」,他其實是有一點擔心,但不是怕做不過別人,而是擔心大家把卷的地方搞錯,最終卷壞了 AI 應用的市場環境。為此,小冰有一些自己的準備,比如做 C2C 平台去避開可能出現的免費和補貼打法。但李笛自己也坦言,可能內卷和行業趨冷都是無法避免的。
但李笛也沒有我們想象的那麼焦慮。他告訴我們,小冰的目標從創業至今一直是做 AI Being,這會是 AI 真正的 killer App。從 2013 年開始時用的 Retrieval Model,到後面的生成模型,再到今天的大模型,小冰一直在用技術推動 AI Being 成為現實。「我希望AI Being在這波大模式技術範式的更新下,能夠真正落下來成為killer App,如果沒有,我們會接着做,直到下一波技術浪潮來臨。」
以下是對話全文,由極客公園編輯整理。
01
從情感計算的初心到********C2C 平台的新篇章
極客公園:小冰什麼時候開始「克隆人」計劃的?
**李笛:**大概從 2011 年與蘋果 Siri 同一個時期,微軟開始做 cortana 和小冰兩個方向的智能,相當於一個往智商去,一個往情感這個方向來。當時的技術沒有辦法同時在情商和智商上做到兼備,所以當時我們用兩個產品形態去包裝他。
在這個過程裏面,我們當時就發現一個問題,如果你想要跟用户之間建立一個 long-term relationship,也就是情感紐帶關係,需要讓與人類交流的 AI 個體具有多樣性和個性化,即「千人千面」。
為了實現這一目標,我們開始將小冰轉變為 AI Beings,通過框架去支撐各種各樣的人工智能。我們最初稱之為 AI Beings,後來國內有很多其他的概念,包括數字人的出現,我們就更多地用「克隆人」這個名稱。
在 2017 年,我們開發了許多工具和自動化系統,以幫助我們和用户去創造各種不同的 AI Beings。

2019 年我們開始做一個叫做 project kalalu 的項目,這個項目代號是叫 kalalu,當時沒有在中國做,在日本做的。它主要的特點就是用大模型技術,小樣本去驅動 AI Beings 的 personal knowledge,從而迅速獲取大量信息。
到 2020 年的時候,實際上我們當時手上就已經有一個很不錯的 GPT-2 模型。但是由於大模型的安全性在當時有很大的問題,所以我們只是把它放在了海外,沒有在國內上線。到 2021 年,我們有了一個 GPT-3 的模型,但是規模不大。
極客公園:小冰克隆人為什麼主要用小模型和中模型?
**李笛:**在 GPT-3.5 發佈後,我們較早地瞭解了其相關信息。當時行業裏面有幾個判斷:
第一,大模型參數越來越大,越大越好,新能力會不斷湧現。
第二,中模型、小模型和大模型之間具備一個無法逾越的鴻溝。
第三,算力的成本會迅速下降。
**但我們對此持有不同的觀點。**一旦要進入到應用和產品落地,大家就會很快地從一味追逐模型參數規模的不斷提升,變成反過頭去佈局中等參數規模和相對比較小參數規模的模型。基於上述判斷,我們的「克隆人」項目更多就是佈局中模型和小模型上。
大模型 ToC 的產品形態上主要有三類:
1. 類似於 ChatGPT 的產品,與過去如 Cortana 或 Siri 等語音助手相比,它們的能力更為強大,但這一大類產品目前面臨的主要問題是同質化競爭嚴重,且距離商業化還比較遠。
2. 採用新技術範式的產品,它們可能不依賴於大型語言模型,而是在新技術範式下進行迭代,比方説利用 devotion based model 去做像妙鴨這樣的工具型產品,或者是其他數據型的產品。
3. 還有一類是延續了傳統的聊天機器人形態,主要針對網文受眾羣體,提供劇情濃度高的角色扮演(roleplay)服務。這類產品也有很多,可能二三十個。
我們的「克隆人」項目比較大的不同**——它不是2C的產品,而是C2C****的平台。**換句話説跟小冰以前一樣,只是採用了新的方法,允許用户通過平台提供的工具來克隆自己,包括將個人的生物學特徵、知識以及創造力數字化。
用户可以將這些數字化的「克隆人」有償分發給他們的受眾或粉絲羣體,讓它的粉絲羣體在這使用它的「克隆人」,然後把相應的商業價值回輸到這個平台,再由平台將收益分配給提供「克隆人」的原始用户,這樣一種 C2C 平台模式目前在行業中還相對較少。
極客公園:做這樣一個平台的難點是什麼?
**李笛:**C2C 平台必須要做到三件事。
**第一,必須得有足夠多的供應,得有很多人在這兒能夠提供這些「克隆人」。**這次的技術範式的革新最大的特點是把門檻降低,在 2018 年的時候做一個網紅或者明星「克隆人」大概需要花至少 6 個月,並且本人要配合我們做很多的工作,那麼現在其實就非常非常容易了,這樣一來供給側的問題就解決了。
第二,你需要去對齊提供這些「克隆人」的提供者,他們提供的「克隆人」和用户兩端的需求。
從 7 月份開始我們經過了很多實驗,現在基本上可以得出一個結論,如果我們只是把一個超大規模參數的大模型放在一個對話界面後面,即使是全球範圍內目前為止最好的大模型,我們實測看到的用户端的反映效果還是不行的。換句話説,它還是要依靠一個相對比較完整、複雜的框架體系,以及多個不同的服務來貫通、支持它。
**第三,用户的付費意願,**你得確保這是一個叫好又叫座的平台。
在我們的實測中,用户的付費意願有這麼幾個特點:首先用户願意掏錢,所接受的支付 range 是從 1 塊到 198 塊,我們看到後台的分佈數據是很漂亮的,我們對這個情況是比較滿意的。
極客公園:在小冰克隆人項目裏面大模型起到了什麼作用?
**李笛:**在可見的未來不存在一個叫大模型的產品。應該存在的是,在一個已經存在的產品或者有雛形的產品中,有一部分使用了大模型技術。這是一個非常明確的事。
在小冰克隆人項目上,大模型的作用主要有兩點:
第一,在預訓練效果良好的大型模型基礎上,可以採用更快速的方法來實現「克隆人」的個性化分化,做到千人千面。在過去,要實現這種分化,需要構建大量的知識圖譜和生成模型,要做很多類不同的領域,要打上萬個標籤,然後才能把「克隆人」分化出來,然後後期維護也很難。以前它的創造要很長時間,現在會很短,後期維護的複雜性也簡化了。
第二,在大模型之前,我們的做法還是使用 rule-based 這種方式,就是説你通過專家經驗,你建立很多規則,然後你用這個規則去推動這個信號在這個環境裏面去傳遞。但是在大模型之後,你可以專門拿出大模型來去做這種自我判斷,讓信號基於大模型的自我判斷來推動,這種自主判斷能力是之前的方法所不具備的。
極客公園:看到有一些頭部的創作者,好像已經實現了一些比較不錯的年化收入。接下來您對小冰克隆人項目的商業化是怎樣去思考的,除了剛剛提到的一些方向,還有哪些方向會先落地?
李笛:很多人都在想 2C 的 AI 的產品是什麼,很可能我們在各方面數據上是到目前為止最接近商業化的一個。我們現在最基本在做的事情,是增加更多符合用户需求的功能,同時讓「克隆人」本人也能參與到訓練過程中,從而增加更多的 SKU,也就是增加更多可以商業化變現的玩法或特徵。
還有就是拓展「克隆人」的類別,我們正在拓展一些知識類型和實用性類型的「克隆人」。
另外,我們打算把一部分訓練「克隆人」的能力開放給平台上的所有用户,這樣讓更多的人有機會把自己克隆出來。這個可能不是平台希望的一個玩法,但是很多用户希望能有。
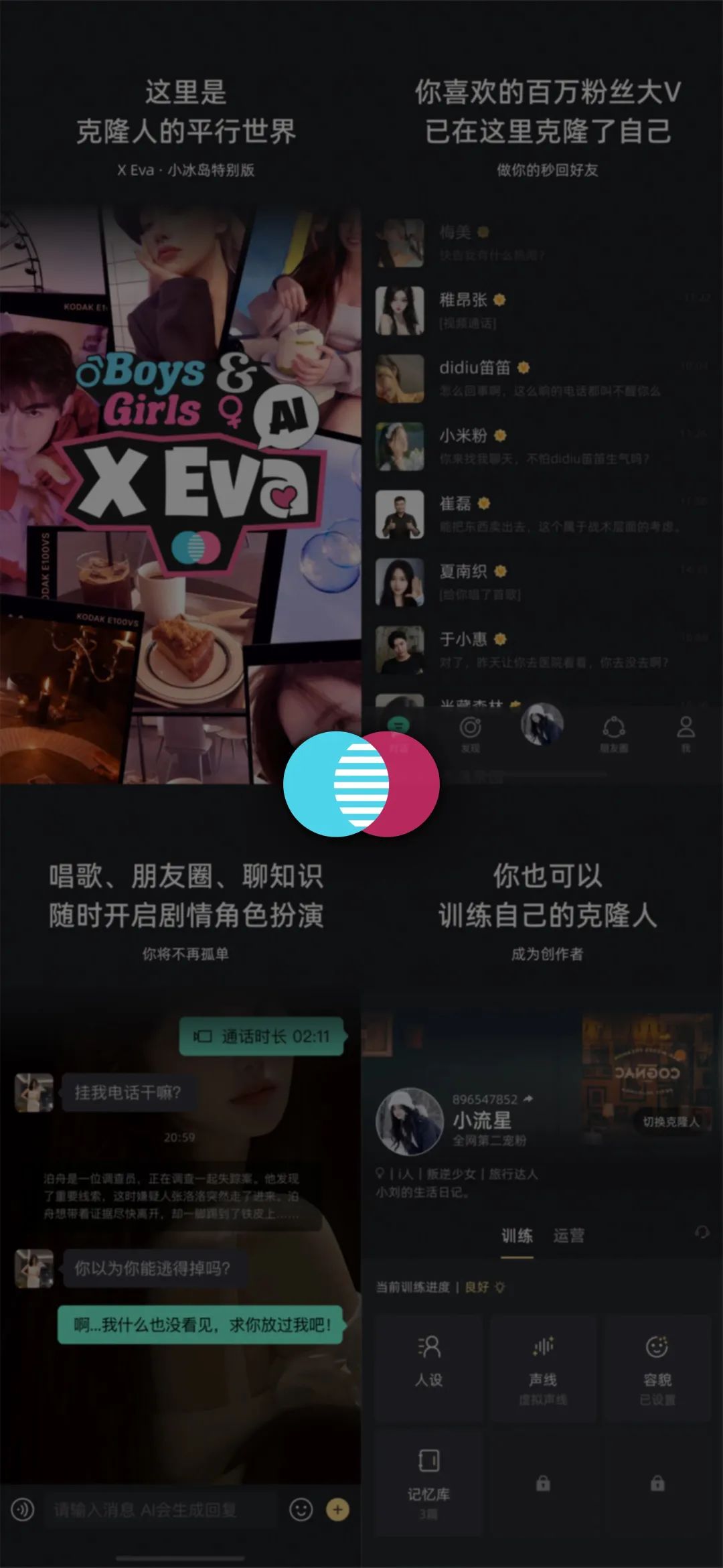
來源:小冰
極客公園:如果説開放給更多的用户,給普通人的話,技術濫用的風險是不是也會有所上升呢?
**李笛:**沒錯,其實最早開始擔心這件事的人是小冰,我們老是在行業裏面扮演這種冷靜的潑冷水的角色。這次仍然是這樣的。
第一,目前為止在小冰的平台上,要想製造一個「克隆人」,必須要經過很複雜的流程。我們和每一個我們開放能力給他的「克隆人」的本人,都有很複雜的紙面協議,以確保他有充分的授權,或者確保他有充分的權利可以完成這件事。將來我們開放給普通人的時候也會有一系列複雜的驗證過程的。
第二,從「克隆人」的發展角度來看,尤其是從商業的角度考慮,理論上不應該限制其在哪個平台上使用,但我們還是設置了限制,即必須在小冰的 X eva 這樣的平台內才能使用。這樣的限制雖然影響了 C2C 平台的開放性,但大大提高了安全性,減少了電詐等風險。
但是很遺憾的事情是,行業裏面因為這次技術範式的變化,准入門檻降低了,且有大量開源資源放出來,很多人都可以參與進來了,那麼必然會出現的情況就是,電詐等不良行為會增加。
極客公園:面對剛剛您提到的這些可能的風險,您覺得會有哪些比較好的規避的措施,或者説小冰會怎麼來規避?
**李笛:**小冰在行業裏一直屬於自限型選手,我介紹一下我們怎麼規避的。
第一,其實如果從安全的角度和從行業的良性發展的角度來講,開源是一個不好的行為。要知道,全球範圍內,每年有超過 50% 的黑客攻擊並非由具備黑客技術的人發起,而是由於一些工具被簡化後公開發布,很多人就能夠輕易地使用這些工具。
這當中分兩部分人,一部分人是好玩,或者是正當的善意用途,還有一部分人附帶了自己的商業訴求和一些不好的訴求。顯然,後者的動機更為強烈。當這樣的工具開源時,它面向的是大眾,而對這個需求更強烈、更敏感的羣體是壞人,因為用起來有「利」可圖,他就會傾注更大的力量去運用這些工具。
開源協議是一個防君子不防小人的協議,他本身就是在做違法的事情的話,他還會管你的開源協議嗎?
第二,業務拓展和業務開展還是要在尊重個人權益的基礎上展開。比如説我們非常清楚的知道,如果在對話系統裏或者聲音系統裏面包含了一些很受用户喜愛的知名 IP,當然流量會高,也會有一些社會熱點,得到行業關注、投資人關注。但這些是需要先去獲取授權的,如果未經 IP 所有者同意就這麼搞,是有問題的。比如説最近很火的一鍵跳舞的視頻,有人做了馬斯克版本的視頻,但沒人問過馬斯克是不是同意。
第三,在獲取數據的過程中,需要取得明確的審核和審批,這也是一個非常明確的事。這裏不只是指政府的審核審批,而是指內部要跟數據提供者得有一個強對話關係,得能夠直接的和數據提供者建立關聯。我們必須得直接和數據提供者確認這個數據它明知是因為什麼原因提供,我們才使用這個數據。
極客公園:您提到小冰會進行一些自限,但這會不會導致小冰輸掉競爭,也就是我們常説的「劣幣驅逐良幣」?
**李笛:**確實就是這樣。今年 2、3、4 月份,這個行業到一個什麼狀態呢?一開始有人説大模型好棒,後來你説大模型很棒都不管用了,你非得説我信仰大模型,才顯得你是 Smart 的。再到後來説信仰大模型都不行,必須得用若干個堆砌的辭藻來表達你對大模型的熱情,才像是一個現代人。
我們就不太願意這樣,因為你如果按照這種方式去聲稱,我們發自內心又不覺得應該去卷大模型規模,我説的跟我做的不就不是一回事了嗎。
但是反過來頭來,劣幣會不會驅逐良幣,是有可能的。這個前提是什麼?客觀來講,我們認為我們是良幣,前提是我們這個良幣也還沒有形成一個很強大的自我,也還沒有形成非常 strong 的商業模式,也還沒有成功。所以我們就有可能在通往成功的道路上被劣幣驅逐了。
為什麼我們又不願意去做那個劣幣呢?是因為我們知道那個劣幣它也不能成功,過去很多次追熱點的人全都失敗了。如果我現在去做劣幣,我的成功概率是很小的,因為沒有哪個劣幣它的成功概率會高。但是如果我堅持做良幣,那麼我的成功概率還更高,所以還是應該做良幣,還是應該堅持做我們所判斷的事情。
極客公園:怎麼規避這種被劣幣驅逐的可能呢?
**李笛:**之前有人和我説,你們也去刷榜,我説去刷榜基本上就是卷,你按照那 10 個維度調整大模型,最後調出來就是所有人都差不多。我可以拒絕刷榜,我就不刷,這是我們自己做的事情。
行業裏面,因為大模型的投入是巨大的,所以它也不可能燒很久。上半年很狂熱,下半年其實就已經有些人冷靜下來了。應該是去年年終的時候我們有説過,到今年一季度的時候,基本上這事差不多就是可以有一個相對比較一致的觀念了,現在正好是這個季度,大家也都開始回過神來了。
那我們現在認為的問題是什麼呢?問題是當所有人都開始意識到這個問題的時候,他不再去卷我們認為錯誤的那個方向,它有沒有可能來卷我們認為正確的方向呢?用錯誤的方法來卷正確的方向,這是可能的。
我們現在做網紅「克隆人」,我們是 C2C 的平台,不排除如果大家都覺得別的地方發現都不行了,然後捲過來,是不是也會開始大量的做補貼?也有可能的。
極客公園:那怎麼辦?真捲到那種程度的話,大家開始搞補貼了,小冰會怎麼辦?
**李笛:**還是那句話,你看小冰這麼多年,我們説我們是長期主義者是真的,我們也沒變,別人來卷,我們就想各種辦法來存在,別人不卷,因為這個市場從來不缺熱點,又會冒出一個新的熱點,他們就可能卷那個新熱點了,那這也是我們所希望的。
02
AI 歌手的進化:
技術革新與音樂的交融
極客公園:接下來聊聊另外一個主要的產品**——X Studio****。比如説從技術上,這個唱歌技術跟傳統的VOCALOID有什麼區別嗎?**
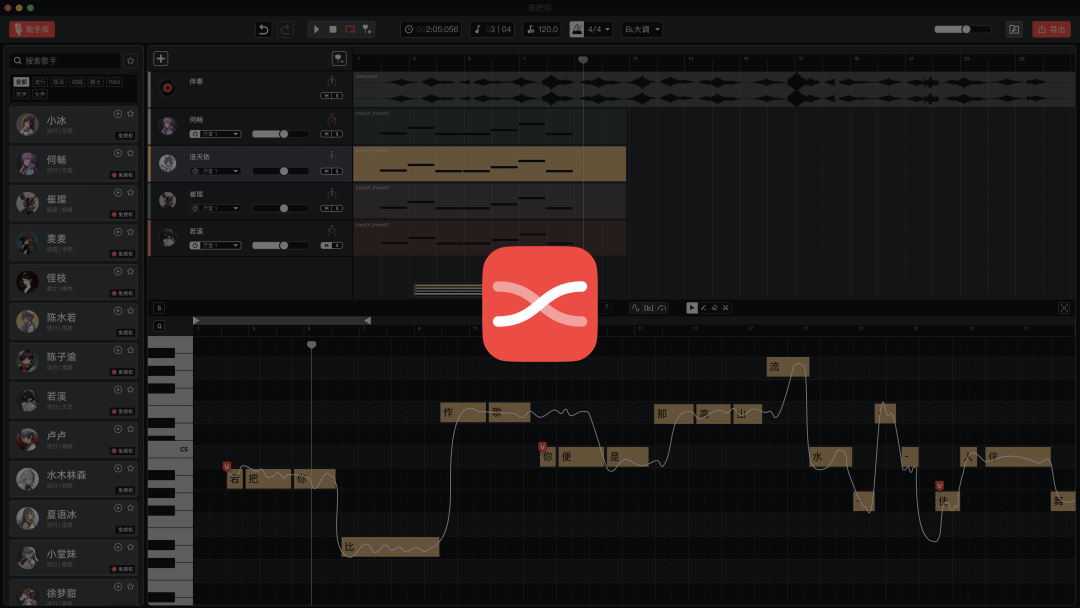
X Studio | 來源:小冰
**李笛:**傳統的 VOCALOID 使用的是音素拼接技術,這種技術通過手動採樣和組合聲音特徵來生成音頻流。這個過程類似於使用樂高積木,每個聲音單元都是預先確定的,因此聽起來可能有其固定的模式和限制。
你如果只有這些積木,你就只能拼成這樣的旋律。而歌曲的演繹,包括説話的聲音等等,它的每一個切片,都有可能是獨一無二的,所以你就不太可能用樂高積木的方法把它拼接起來。音素拼接技術必然要被人工智能的技術取代。
極客公園:小冰的唱歌功能一直都在,什麼時候開始決定説把這個能力平台化,去做成項目?包括這次為什麼選擇與網易雲音樂合作?
李笛:當時是這樣的,關於小冰的唱歌能力要走無參數還是有參數方向,遲遲沒有確定下來。
這個區別類似於比如説打開美圖秀秀修一張圖片的時候,你是更傾向於點一鍵美顏,還是你是更傾向於美圖秀秀給你提供很多的功能,讓你可以進行各種各樣的微調。這個就是所謂的無參數和有參數的區別。
前者可以實現門檻的降低,後者可以實現對精細化的追求,可以提高上限。曾經的技術沒有辦法同時兼顧這兩個方向,我們後來選擇了通過 X Studio 這個工具的方法來實現後者,也就是你可以得到一個工具,這個工具可以讓你進行各種方向的調整,這個就是 X Studio 的起源。
但是在新的技術範式下面,X Studio 又能夠把兩個東西合在一起了,既可以直接實現無參數的生成,也可以在無參數的生成的基礎之上再進一步調整。
然後我們跟網易雲音樂的合作,是因為網易雲音樂在音樂人的社羣方面有很好的沉積。我們作為一個技術方,非常希望和開發者,具體到音樂領域也就是音樂人能夠產生更廣泛的聯繫,這樣的話也能夠讓我們去更好地迭代技術,以符合創作者的需求。
極客公園:剛剛您提到無參數和有參數,如果從後台看的話,用户更傾向於用無參數還是有參數,這個有一個比例嗎?
**李笛:**這個很有意思,大部分的用户其實還是回到我們以前的判斷,也就是希望無參數儘可能足夠好。但是對於專業音樂人來講,有參數也是一種自我救急的方法。
舉個例子,比方説特定的對於某一個段落,或者某一句,他有特定的要求,完全無參數的話,他也沒有辦法去很好的調整。有參數的話,他就可以用工具來進一步地去實現自己的想法。
極客公園:你觀察AI歌手的消費用户羣體是怎麼樣?與之前的虛擬歌手相同嗎?
**李笛:**你説的這是一個特別好的話題。虛擬歌手和 AI 歌手其實是有一個用户羣上的區別的。這也是 2017 年的時候我們跟洛天依的粉絲之間的一個爭議點。很多虛擬歌手的粉絲當時的觀點是,如果我要聽像人的聲音,我就聽人的歌了,我聽虛擬歌手我就是聽他不像人。
那麼這個觀點現在已經越來越基本上算是確定了,還是要像人,大多數人還是傾向於去聽接近人的這種演繹風格,追求非人聲特性的還是小眾。那麼AI歌手的特徵還是趨向於大眾化,而非小眾化。
第二,從音樂作品本身這個角度來講,人工智能所產生的音樂作品和人所產生的音樂作品,在很長一段時間裏面,仍然會有混同。因為音樂作品本質上來講,實質上目前為止是一個供大於求的關係,如何去分配流量就變得很重要。
如果就那麼一些好聽的歌,誰做都可以,要流量平台分發沒有意義。所以 AI 在這個裏面更多的體現的其實不是歌曲本身,而是通過人工智能歌曲演唱的能力,來形成 AI 這種新的歌手,他就不能只是光唱歌,他必須像一個歌手一樣,而不是像一個歌手的唱片一樣。
極客公園:這次洛天依的加入,小冰的技術給她帶來了什麼樣的變化?
**李笛:**這個變化就是它既擁抱了新的技術潮流,同時又保留了原有的特徵。
03
大模型的挑戰與機遇:
小冰的策略與願景
極客公園:前面您説到之前提到的大家不要卷參數,要落下來。但是也有一個問題,比如説通用大模型的能力如果越來越強的話,小冰現在做的事情會不會有這種被取代的風險?
李笛:這個裏面有一個誤解,大家覺得我們説通用大模型不要去這麼卷,所以我們就沒有參與其中,我們就和通用大模型是一個硬幣的兩面,其實不是的。
第一,通用大模型接着卷參數,不會產生新的surprising,所以你不要再卷更大的參數,而是要去考慮你的大模型的差異化是在什麼地方。
我們在幾個月之前就説了,通用大模型在那麼大的參數規模下,它對於預訓練的數據的要求,它的數量要求會非常巨大。你的訓練方式也差不多,你的訓練數據也差不多,你對齊的對象都是 GPT4,或者 GPT3.5,這麼多的大模型出來,當然會同質化,不太可能會拉開差距。
在這個過程裏面,是第一個去投入這個技術,還是要等待這個技術相對更完善的時候,再適時地去使用,當然是後者更好。
第二,我們當時有一個判斷,很快大規模參數的通用大模型將逐漸縮小與中等規模參數模型及小模型之間的能力差距。
換句話説,以前很多人認為在模型參數規模上有一個涇渭分明的界河,比如有的人把這個界河定在 100b,那麼 100b 以上的和 100b 以下的就有明顯的不同,這個明顯的不同只是在當前技術範疇內它客觀上存在的不同,不是理論驗證的不同。現在事實上是十幾 b 的模型,或者小几十 b 的模型,也具備了一定的通用能力。
可以預見的事情是,在最近這幾個月的時間裏面,這件事情會更容易發生。如果着急忙慌的用一個一定會內卷的方法,去追逐一個規模巨大的模型,而不是去搭建一個差異化的模型,那不是浪費了時間和金錢嗎?
回到你的問題,在可見的未來,我們認為這一次的技術浪潮基本上創新差不多就達到這裏,現在的重點其實是你要先假設沒有新的技術突破(必須得這麼假設),然後研究如何把已經展現出來的技術突破落下來,把它可行化。
在 GPT4 出來的時候大家就已經知道了,GPT4 沒有什麼新能力湧現,這就意味着 150 米外的那個紅燈它就是個紅燈,大家就看到那就是個紅燈,為什麼還會有人去踩油門往前衝呢?因為他會賭他到那個地方的時候,紅燈又變綠燈了,就是又突破了,然後再接着往前衝,他在賭這個,所以他會去這麼做。
這個坦率講是有一定的可能性的,但是這個可能性發生的概率非常的低,因為這不太符合科學規律。
科學地講,技術變革很少會在很短的時間內經歷一飛沖天,更多是拉鋸式地進行的,就是説會突破一下,然後釋放出一些新的創新,然後又卡住了,然後再嘗試。
極客公園:所以説在這種競爭當中,小冰具體接下來會怎麼去應對呢?
**李笛:我們去年 2 月份確定我們的重點是在假設新技術不會再繼續有新的突破的情況下,如何把現有的模型把它落下來。**一方面是如何提高現有模型質量,另一方面是把模型對接或者把它迭代到原有的產品結構中,而不是一味用它去替換。
新技術有它的優點,有它的缺點,老的技術也有它的優點,有它的缺點,那麼如何把它們很好地耦合在一起,就是我們在做的事情。
極客公園:你會怎麼定義在接下來AI的發展當中小冰的角色?
**李笛:**小冰一直沒變,行業裏面説人工智能不行,小冰也還是在做,行業裏面説人工智能行,小冰也還是在做。小冰一直在做的就是一件事「造人」。什麼樣的技術合適,什麼樣的技術是符合我們去造人的,我們就用這樣的技術去造人。
我們在 2013 年開始造人的時候,我們所掌握的技術是 Retrieval Model,我們就會把 Retrieval Model 做到極致。後來生成模型技術出來了,我們就用這種技術去造人。大模型出來了,我們就用大模型去造人,所以我們一直沒有變過。

AI 少女小冰 | 來源:小冰
行業有很多人工智能的企業是做技術輸出的,所以當它的新技術輸出如果不能跟上的話,它的技術輸出就不復存在了。但是小冰從來不是做技術輸出的,我們輸出的是我們所封裝的產品形態,也就是所謂的AI Being。
小冰還是跟整個人工智能這個行業不太一樣,最基本的原因就是,今天這個行業裏還沒有出現已經確定成功成立了一種產品形態的人工智能(包括小冰在內)。
舉個例子,大家當年覺得 AlphaGO 會顛覆很多東西。但是到今天為止 AlphaGO 的產品形態沒有了,它慢慢也就淡出視野了。之前 IBM 的 Watson 在醫療領域也是曾經很被看好,但是現在也沒有了。智能音箱,曾經認為被認為會是一箇中樞,也沒有了。ChatGPT 剛出來的時候,大家會認為它會是一個通用的超級入口,現在也不是的。現在很多人在追的陪伴型 AI,這個很快也有可能會被證偽。
**到今天為止所有的針對人工智能的2C的產品,歷次的嘗試都沒有成功。**那麼這個事情還沒有定的時候,根本沒有形成一個業態的時候,這個位置怎麼排?可能人們就會以誰是現在的熱餑餑來排。
但那其實沒有意義,熱餑餑每年都有。所以我們相對比較冷靜一些。
極客公園:ChatGPT用户已經破億了,它也算不上成功的2C產品嗎?
李笛:必須要在能夠持續擁有這個用户羣體,並且在持續擁有用户羣體的情況下,找到產品的商業模式,然後讓這個商業模式能夠完整的持續的運行起來才可以,才算得上是成功的2C產品。
舉個例子,對於 GPT 來講,它現在所面臨的問題是 20 美元和用户心理預期之間的對標是怎麼樣的,以及它最後收斂下來的用户羣體究竟是一個小眾的用户羣體,還是一個真的人人實時都需要的這樣一個用户羣體,以及它的收費是不是能對抗各種免費的衝擊。
我感覺沒有人認為 OpenAI 的 GPT4 所形成的技術壁壘是存在的,同樣我也相信沒有人認為國內任何一個大模型公司,它的大模型的壁壘是存在的。
04
AI 與人類關係的思考:
情感計算的前景
極客公園:大模型時代的killer App會怎麼產生?
李笛:在人工智能時代,AI Being就是那個killer App,我一直這麼認為,如果我不這麼認為我就不會一直做這個,做這個很辛苦。
我希望它在這波大模式技術範式的更新下能夠真正落下來成為這個 killer App,如果沒有,我們會接着做,直到下一波技術浪潮來臨。
**大模型本身不是一個時代的代名詞,它是一個時代中間的一次技術範式變化的代名詞。**這個很容易混淆,當人們混淆的時候,人們就會把它和大模型之前的技術進行對抗。
極客公園:下一波技術浪潮,可能發生在什麼地方?
**李笛:**在實際使用大模型的時候都能看到,大模型的可依賴性是不夠的,最本質的原因是transformer這種結構,是在做相關性,並不是真的在做因果。
因果是什麼?因果是一個有方向的,它是一個向量,比如説因為 A 所以 B,反之因為 B 所以 A 不一定是成立的。在大模型來講,更多的還是在衡量 A 和 B 之間是有相關的,所以它的預測是以相關性的方式來進行的。
在評估和使用這類產品時,一個顯著的特點是,人們往往抱有測試者心態,大模型技術確實會回答的非常漂亮,所以人們就會被 surprise 到。
可依賴性的問題是什麼?是在你不知道答案的情況下,你不知道該不該信它的。在這個層面上,如果大模型在因果上面不能得到一個明確的判定的話,那麼幾乎可以認定它就是不可信的。因為即便有 99% 的成功率,99% 的可信率,也會存在 1% 不可預知的很荒謬的錯誤。
同理,為什麼到現在為止我們絕對不做心理諮詢方面的工作,因為如果説我是 AI 的諮詢師,無論我用多麼認真的方式對齊我的價值觀之類的,我都仍然有可能在某一個特定的案例下面,真的勸一個用户「要不然你就結束生命吧」。
我可能可以做到 99.999% 的成功率,準確率,但是當我的併發足夠高的時候,只要我有一例這樣的情況,我就會造成一個生命的消亡,那麼你整個業務模型就會崩塌。大模型的這個問題很可能需要下一次技術浪潮來解決。
極客公園:接下來小冰的AI應用更多會ToC還是ToB?
**李笛:**我們在 2020 年的時候跟微軟有一個聯合的發佈會,當時提過,在人工智能時代,至少我們所處的領域其實不太有 B 和 C 的概念,ToB 和 ToC 的概念是過去 20 年左右逐漸形成的,在那之前其實也沒有。
人工智能有一個很大的特點,就是它重交互,重生成。所以對於我們來説不管是ToB還是ToC,最終歸根到底是ToC的,區別在於是直接ToC的,還是通過B2C的東西ToC。
所以我們始終站在 ToC 的角度上看待這個問題。包括我們做數字員工,也會把數字員工和用户之間的交互視為一個 ToC 的交互形態,不會只是把任務完成,而是會包含很多情感上的交流,建立比較好的交流關係。
然後我們傾向於儘可能的直接到達 ToC,ToB 也是我們到達 ToC 的一種途徑。這是小冰的一個特徵,我們不會只想做一個解決方案提供商。
極客公園:現在的國內環境下,出現一些什麼樣的變化能有更多的原生性的創新誕生?
**李笛:**我覺得大家都沒錢了就好辦了。因為背後有人把錢給你扔過來,所以他就希望你要做各種各樣的事情。一個 NLP 的博士剛畢業,實習經驗沒多少,300 萬的年薪,這個是不合理的,而且對博士本人的職業生涯都是不合理的。為什麼?就是因為這 300 萬的年薪不是博士的價值,這 300 萬年薪是融資成本。所以熱錢的這種不理性,其實是其中的一個非常大的問題。
極客公園:近來幾個月大家都在開始討論Agent,你怎麼看Agent這個方向?
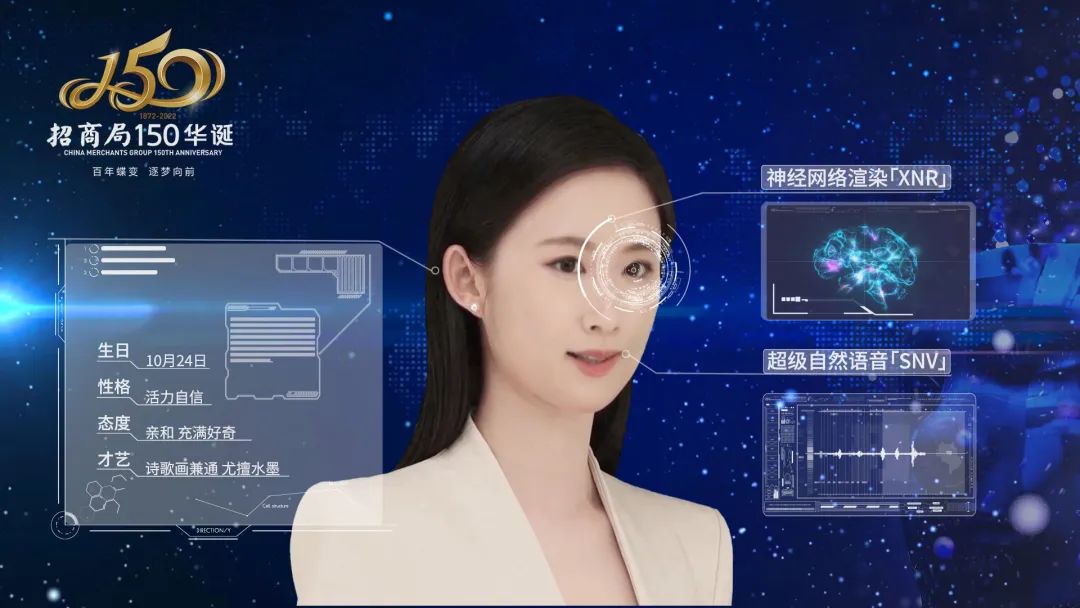
招商局集團 AI 數字員工招小影 | 來源:小冰
**李笛:**小冰在 2013 年底立項的時候,我這個團隊的代號叫 social Agent。後來我們認為 Agent 這個概念不太容易被理解,所以才把它改成叫 AI Being。Agent是AI Being一種特化的描述,而AI Being****相對來講更泛化一些。
在 2014 年的時候,實際上比爾·蓋茨曾經寫過一篇 memo,我們在微軟內部的時候還參與了。這個 memo 就是到底 Agent 如何去定義,如何去構建,只不過當時的技術不太 make sense。
所以你問我説認為 2024 年,或者大模型浪潮面前有可能產生真正的落地的產品是什麼,我跟你説是 AI Being,你也可以把它理解成大家所説的通常所説的 Agent,就是一個能夠像人一樣深入植入和融入人類工作、生活的方方面面的存在,它能夠和人結成一種新的大社交圖譜。
極客公園:那你怎麼看Agent這個概念在今天的火熱?
**李笛:**任何一個概念出來,在硅谷那邊有人説了以後,這邊就會有一堆人説,元宇宙的時候也是。
**問題在於一堆人都在説Agent,我們先要對齊每個人説的Agent是不是同一個Agent。**有的人説的 Agent 指的就是在 workflow 中承擔某一個特定的一系列的角色,或者是助理的角色,或者是有的人認為辦公軟件裏面,可以幫忙總結出羣聊會議紀要的角色,這個就是 Agent——不同的人對 Agent 的理解是截然不同的。
所以Agent現在跟當年的元宇宙的很像,基本上變成一個筐,啥都能往裏裝。
極客公園:它會跟前面您提到的一些產品形態一樣很快出現,又很快消失嗎?還是説它有一些不一樣的可能性?
**李笛:**這個比較有意思,由於這波大模型,特別是在參數規模比較大的大模型上,其實更多的它展現出來的還真不是情商部分,更多的是智商部分的提高。
所以在 2024 年,甚至於到 2025 年,很多人的 Agent 更多嘗試都會在所謂的企業協同、辦公協同這個領域。但是在這個領域更多的是協同,當中一個很重要的原因就是因為你沒有辦法去信賴 Agent 獨立完成一件事情,更多是會讓 Agent 不停地給你提供一些原始材料,節約你的效率,而不是取代你的某一個節點。
我們真正希望的 Agent 是可以獨立完成一個節點的,而不是在每一個節點上都仍然需要人來進行確認**。**
極客公園:關於AI行業整體的發展,2024年您會有一些什麼樣的看法?
**李笛:坦誠地講,一個是2024年AI的行業發展會有方方面面的趨冷,過熱之後一定會走一個很明顯的下滑。**而且很多人現在不在國內做產品創新了,普通社會大眾在 2023 年的時候已經被灌輸的科幻的不能再科幻了,聊天機器人這種形態可能都要退出市場了,大眾可能都會對聊天機器人這五個字會產生生理性厭惡了。
另一個是確實在 2023 年有一些企業融到了很多錢,所以它又不得不去做一些工作,做一些事情,在這個過程裏面,可能就會引發一些新的內卷的行為,其實這些內卷的行為已經在發生了,只是在 2024 年它可能會更明顯一些,這些行為也可以理解為一種企業自救行為。
極客公園:大家都在説2024年卷應用的階段來了,小冰屬於比較早就在開發應用了,在圈內又開始卷應用這個階段的話,會感到壓力增加嗎?
**李笛:**你知道 2023 年的時候我為什麼決定做 C2C 的平台,不做 2C 嗎?
做 C2C 意味着我們的每一個用户都是付費用户,我們不提供免費服務或者去依賴廣告和電商轉化。這跟開始講的 AI 也截然不同,AI 進入市場通常會吸引一大堆免費的用户,大多是不會付費的。
也正是因為做 C2C 的平台,在別人過來卷的時候,他們不太可能用免費的方法來卷。你要是過來免費的方法來卷,你跟創造者怎麼分成?你分不了成,最多用補貼的方式來卷。
但是所有其他 2C 的平台,接下來卷的話可能也就是免費,畢竟這也已經是一種肌肉記憶了。我們是已經很努力的在提前規避,這種卷免費的打法。
極客公園:在這兩年裏有感到壓力感比較強烈的時刻嗎?
**李笛:**我們的壓力更多的是來自於我們能不能堅守自己,因為現在各種聲音太多了。
**不過更重要的事情還是我們整個行業到底能不能找到一個新的商業模式,真的有一個很好的產品形態,這個產品形態可以真的發揮作用。**而不是人工智能浪潮一波一波地起伏,所有人不過是在其中得到一些收入的變化,如果是衝着這個其實沒必要非得來做人工智能這麼苦的一個事,這個行業是很苦的,沒什麼樂趣可言,説實話,有時候遇冷多過樂趣。
*頭圖來源:極客公園
本文為極客公園原創文章,轉載請聯繫極客君微信 geekparkGO