中國大模型的實用性正在吊打OpenAI_風聞
零态LT-零态LT官方账号-最独到的商业洞察2小时前

**作者|**吳狄
**編輯|**張文
**運營|**陳佳慧
**出品|**零態LT(ID:LingTai_LT)
近日,獵户星空突然連着出了兩件“大”事。
首先是在國內,曾經勢不兩立的傅盛和周鴻禕,居然在1月21日獵户星空大模型發佈會上共坐一堂,甚至聊的歡聲笑語。
要知道,自從2008年徹底鬧掰後,兩人十幾年勢同水火,矛盾逐漸升級到了對簿公堂的地步。而這次,被稱為“紅衣教主”“紅衣大炮”的周鴻禕,卻表示“不是來懟的…而是抱着學習的態度”,場面和諧到讓不少人紛紛表示“品出了世紀大和解的味道”。
隨着1月21日獵户星空大模型Orion-14B系列正式發佈,雙方更是針對大模型再次“唇槍舌劍”,據瞭解,該模型具備140億參數規模,涵蓋了中文、英語、日語、韓語等多種語言,效果炸裂。憑藉在多語言環境下一系列任務中所展現出的卓越性能,模型一經發布便在海外迅速引發了熱議。
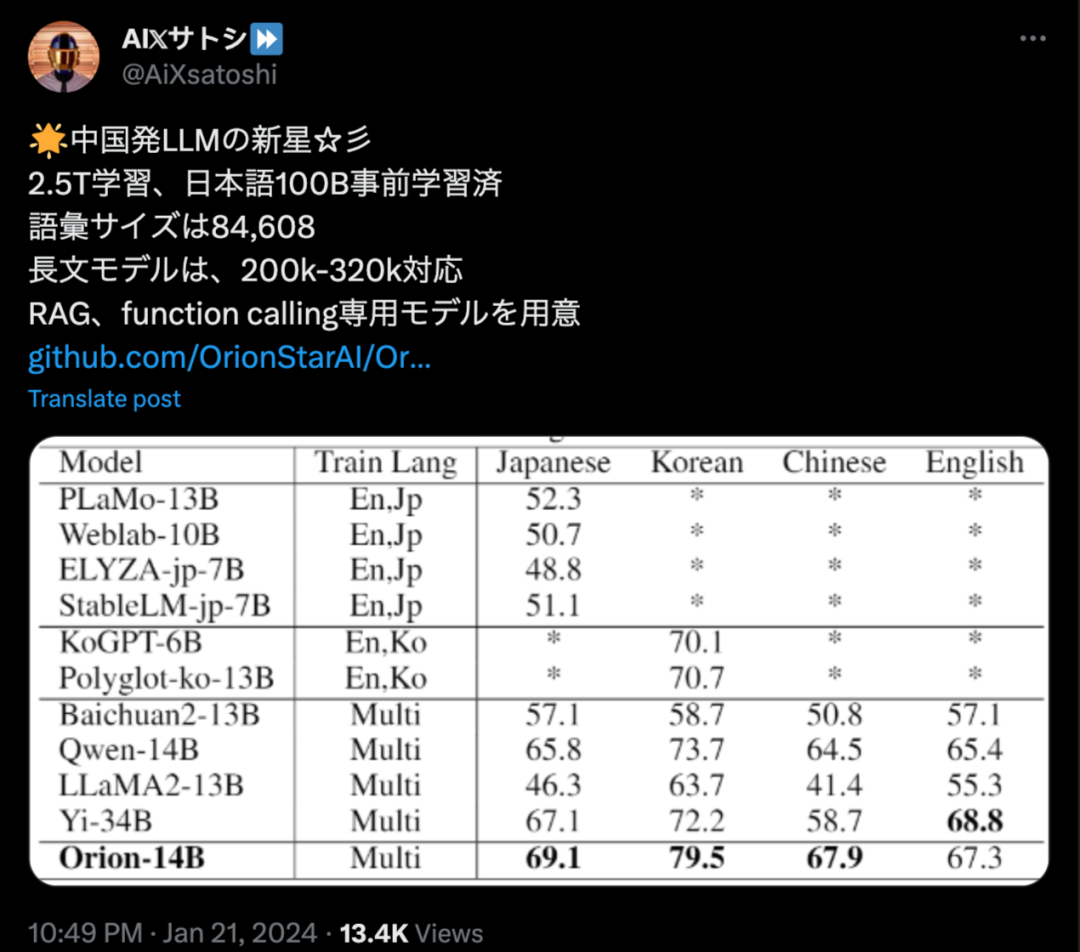
▲圖:日本網友熱議Orion-14B
▲圖:HuggingFace員工介紹Orion-14B
有日本網友表示,看演示感覺日語似乎相當流利。

▲圖:日本網友評論Orion-14B
有開發者表示“這是我見過的最全面的基準模型之一!為獵户星空團隊的全面工作點贊”。
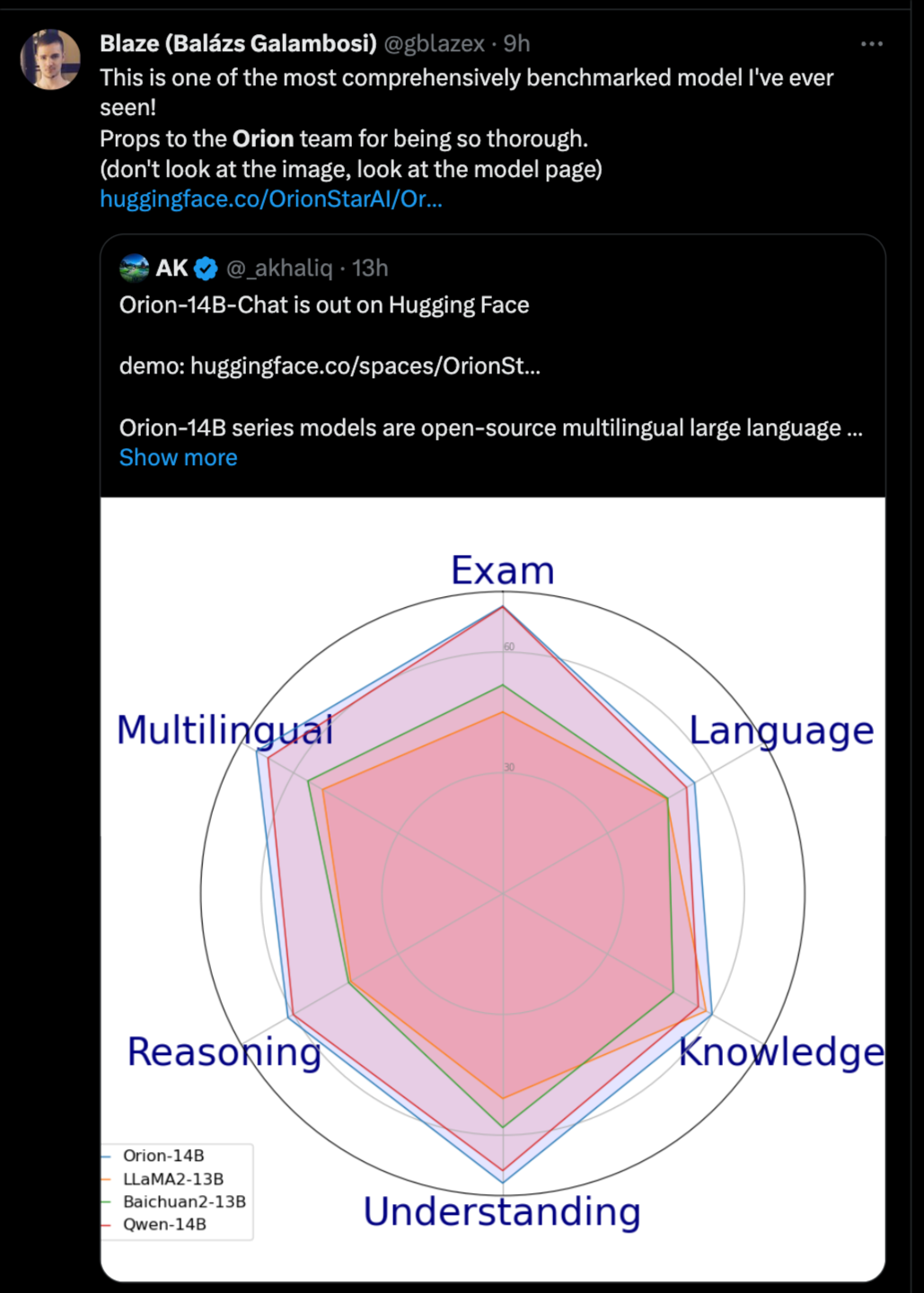
▲圖:海外網友評論Orion-14B
有網友表示“模型看起來非常強大。我喜歡他們列出的所有基準分數,真的能給人很好的整體感覺”。

▲圖:海外網友評論Orion-14B
還有網友表示“希望他們能用RAG(檢索增強生成)測試更多數據提取任務模型”。

▲圖:海外網友評論Orion-14B
YouTube上網友表示,獵户星空團隊的研究工作很philosophical
▲圖:海外更多網友熱議
海外網友更多熱議:
https://www.reddit.com/r/LocalLLaMA/comments/19ce7kw/a_new_base_model_orion_14b_trained_on_25t_tokens/?rdt=42728
同樣都是大模型,獵户星空Orion-14B有什麼不一樣?

獵户星空大模型“Think Different”
本次發佈的Orion-14B,實際上是由7個版本組成的系列,分別是基座模型、對話模型、長上下文模型、 RAG 模型、插件模型,以及兩個量化模型。
其中基座模型是在一個龐大且多樣化的數據集上進行訓練的,數據集規模達到了2.5萬億token,為了確保模型能夠理解和生成多種語境下的文本,該數據集不僅覆蓋了常見的語言,還涵蓋了專業術語和特定領域知識。
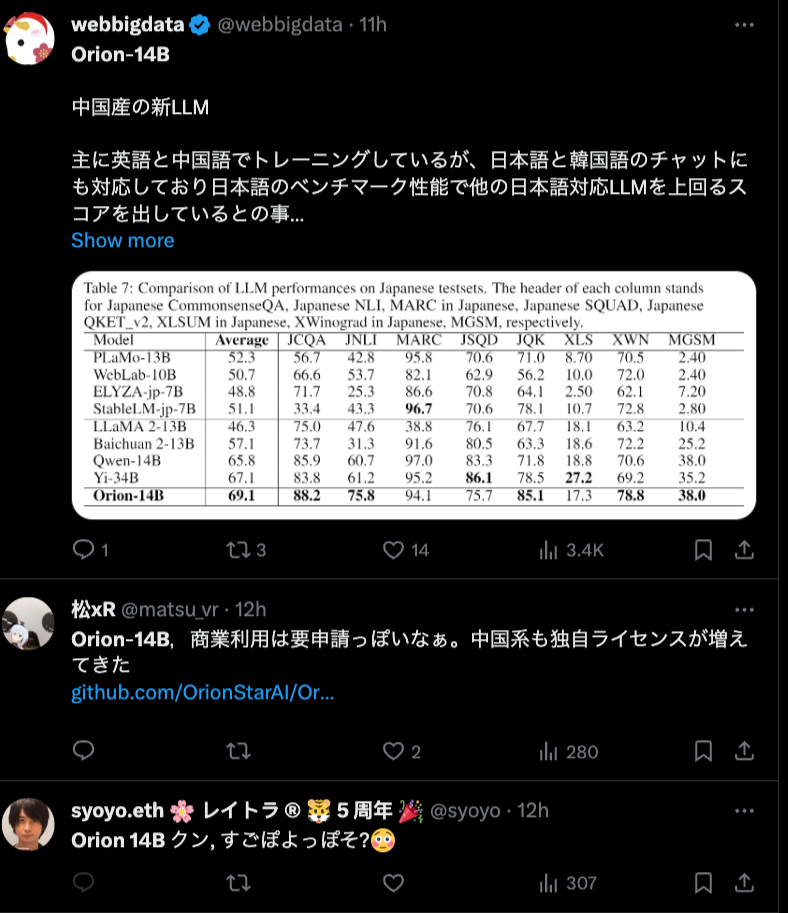
Orion-14B基座版在20B參數級別大模型綜合評測效果表現優異,並且在MMLU、C-Eval、CMMLU、GAOKAO、BBH等第三方測試集上都達到了SOTA(State-of-the-Art,指在該項研究任務中,目前最好/最先進的模型)水平。
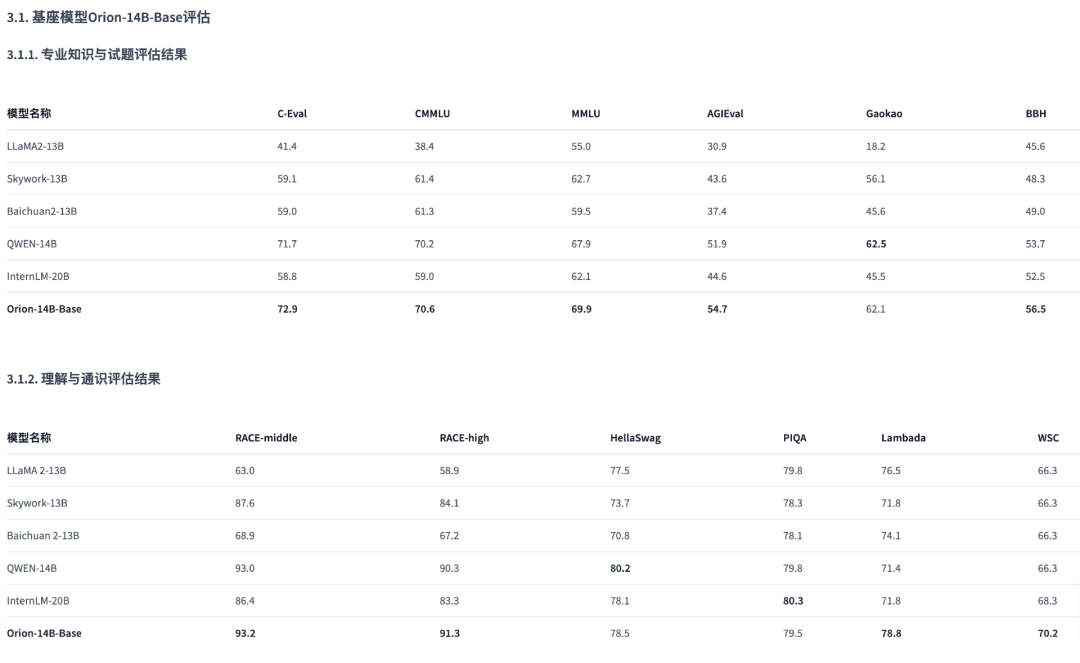
▲圖:基座版綜合評估結果
長上下文模型可支持320k的超長文本,並在200k token長度上效果優異,在長文本評估集上,性能甚至能比肩專有模型。也就是説,我們一次性錄入一本三十萬字的小説後,將其中任意位置的關鍵信息隱藏掉,再對模型進行提問,大模型給出的結果依然能夠做到100%正確。
而量化版更是在性能上實現了大幅優化。模型大小縮小70%,推理速度提升30%,性能損失小於1%,極大降低了硬件運行的門檻。即便是千元級別的顯卡,運行量化版模型也能做到流暢運行。在NVIDIA RTX 3060顯卡實測,推理速度可達31 token/s (約每秒50漢字),但性能幾乎無損。

在多語言能力方面Orion-14B也表現優異,尤其是在日語、韓語測試集上,評測結果全球第一。
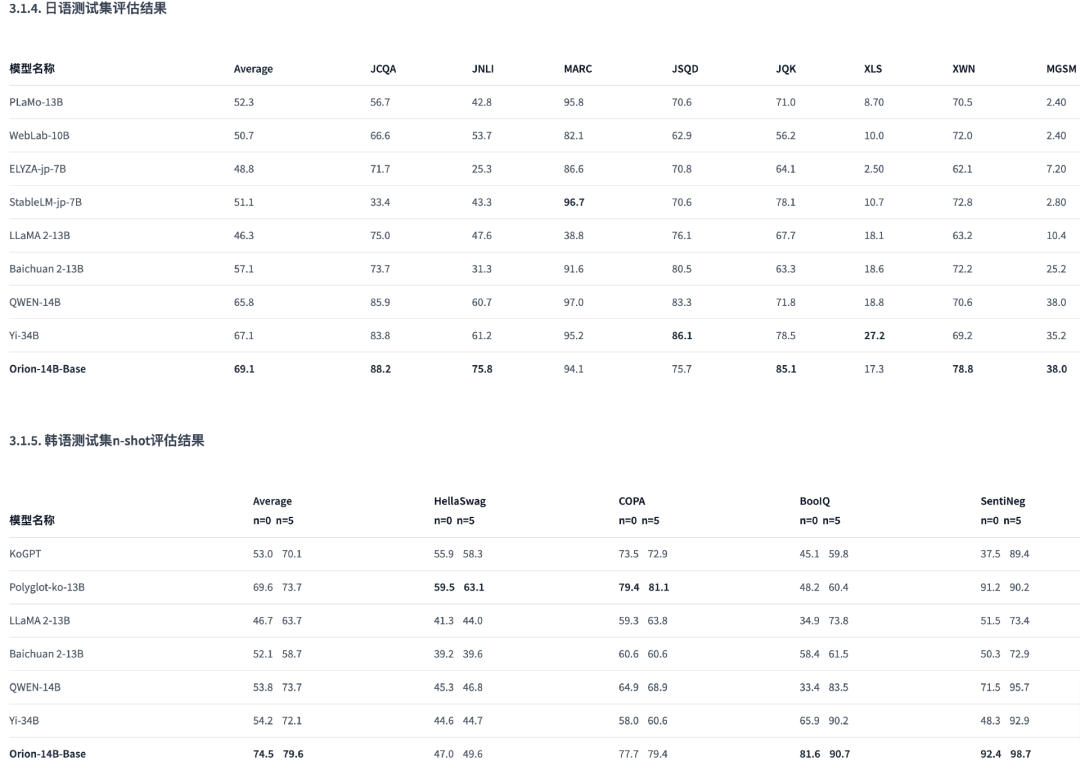
▲圖:基座版日韓語評估結果
但最讓人印象深刻的,是Orion-14B極度反差的小體量和大成就。

百億參數做出千億效果
大模型,顧名思義,重點在一個“大”字。
隨着硬件性能和算法的提升,大模型的門檻也在不斷提高。**以前,10億參數即可稱為大模型,現在都是百億起步。**但隨着模型越來越大,兩個隱患也逐漸顯露出來。
一方面,大模型的發展受制於芯片產能。近年來,缺芯問題一直都沒有得到過很好的緩解,就連OpenAI都要開始自研芯片,以備未來的不時之需。
另一方面,模型越大越燒錢,這對企業發展的可持續性提出了嚴峻的挑戰。同樣是OpenAI,一天70萬美元的燒錢速度,即便是獲得了微軟鉅額投資,也無法完全打消投資者的“OpenAI破產焦慮”。
周鴻禕認為,當下的大模型市場,正在進入一個兩極分化的勢態。一方面,大廠在追求模型體量方面將會越來越放肆,我們有望看到千億、萬億級別的大模型的出現;而另一方面,也會有越來越多的企業嘗試將大模型做小。
在傅盛看來,這兩個陣營卷向了不同的方向:一個在卷“誰能造出愛因斯坦”,另一個則是追求“誰能造出平民化大模型”。
獵户星空顯然屬於後者。
站在早期大模型的角度,140億的確可以算是非常大的模型了,但在當下動輒數百億參數的大模型面前,140億就成了“輕量級選手”。但重量輕,並不代表力道不如重量級。
Orion-14B是一個“精打細算”過的大模型,這一點,從“700億以下參數基座模型中文數據集的綜合測評結果”中就能看出來。在第三方評測機構OpenCompass中,Orion-14B在700億以下這個量級排名第一,甚至超過了某些超700億數據的大模型。
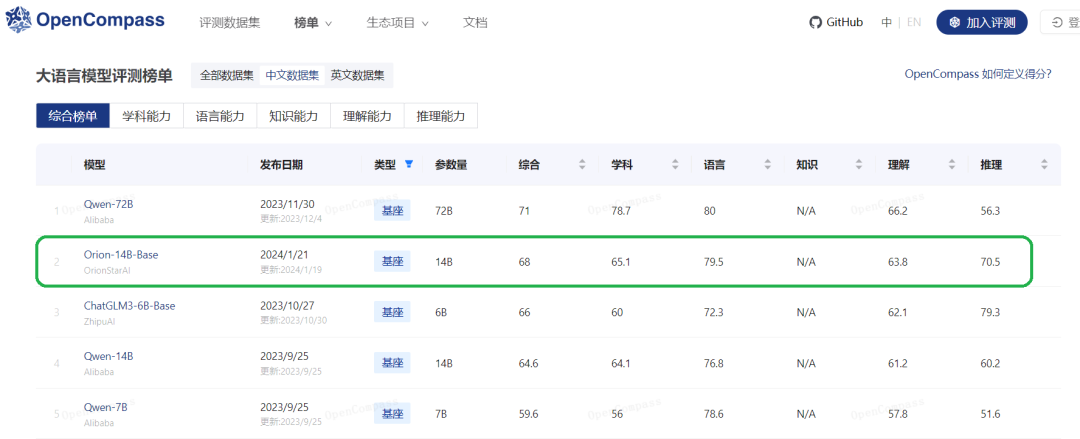
▲圖:OpenCompass測試結果
不僅如此,獵户星空還針對不同應用場景,將模型做了拆分,這就不得不提到Orion-14B的RAG模型和微調模型。
構建並維護企業私域知識庫,可以有效的提高企業內部管理效率。目前普遍採用的檢索增強生成(RAG)技術,可以實現無代碼形式,構建定製化的企業私域知識庫應用。
為此,獵户星空通過針對知識邊界控制、問答對生成、幻覺控制、結構化數據提取等能力進行專項微調後,推出的RAG能力微調模型 (Orion-14B-RAG),在檢索增強生成任務中表現卓越。相比普通RAG套件,獵户星空的RAG套件在專業度上有非常顯著的提升。
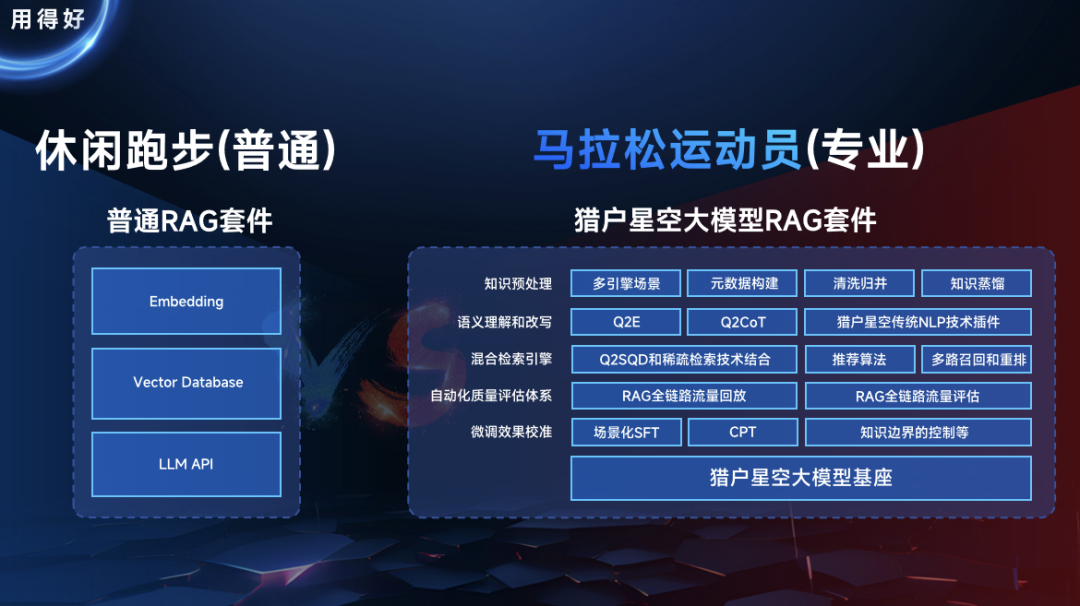
▲圖:獵户星空RAG對比
而被認為將應用開發帶入“3D 打印”時代的AI Agent,更是在企業應用中有着極其重要的作用。
1月10日,OpenAI正式推出可定製化AI Agent應用市場GPT Store,為大模型接下來卷向何方指明瞭道路。當全世界都在為GPT Store上線而興奮的時候,傅盛卻表示這其實是OpenAI的一個“陽謀”。
由於隱私限制,ChatGPT只能從公開出版物來獲取數據,拿不到企業內部核心數據,就無法為企業定製大模型應用。因此,OpenAI需要一個能夠讓企業心甘情願共享出私有數據的方式,傅盛認為GPT Store的作用正在於此。
企業想要通過GPT Store賦能提升效率,就不得不共享核心私有數據。從積極意義來看,這是一個雙贏的格局;但從消極意義來看,企業正在用自己的私有數據去餵養GPT,未來存在不小的隱患。
因此傅盛提出,大模型應該私有化,讓經營數據內循環生長。然而,這又帶來了另一個問題——成本。
通常來説,千億參數大模型被認為是商業化應用的最佳方案,但很少有企業能夠支付的起一年數千萬美元的費用。要把成本降下來,就要把模型做小。到底多小呢?傅盛認為百億參數就夠了。因此,獵户星空大模型的數據只有140億。
但讓人意外的是,百億參數的獵户星空大模型,仍然能在企業級應用中媲美千億級大模型。通過獵户星空的插件能力微調模型(Orion-14B-Plugin)開發的Agent,在意圖識別、首輪抽參、多輪抽參、缺槽反問、插件調用這五項關鍵指標上,已經接近了GPT-4的水平。
看到這裏我們不禁好奇,獵户星空是如何做到“以小博大”,在“小小的花園裏”開出“大大的花”呢?
關鍵在於“應用”二字。

大模型的應用“大”年來了
其實獵户星空大模型能以百億參數達到千億參數模型的效果,和獵户星空本身的路徑走向有着密切的關係。
相比大模型開發商的身份,獵户星空更為人熟知的是智能機器人供應商。在日韓市場,獵户星空更是被認為只是一家送餐機器人供應商。這個角色,在很大程度上決定了獵户星空的做大模型的業務邏輯。
通常情況,平台都是先開發出大模型後,再開始尋找落地點。為了儘可能的覆蓋到更廣泛的應用場景,模型就要做的足夠大,成本自然居高不下,千億級參數的大模型一年授權費就能高達數千萬。
但大模型本身並不是即開即用的產品,企業需要的事能夠結合業務流並解決自身痛點的大模型應用。
在傅盛看來,脱離市場的技術投入就是浪費資源。所以獵户星空剛好反着,先有了落地應用,然後通過AI賦能該產品,在此基礎上再推出大模型,典型的先找痛點再針對性突破的思維模式。
這樣的好處是可以通過更少資源、更專業性能、更靈活配置,在具體應用場景中獲得足以媲美更高參數、更全面性能、更大算力模型的效果。同時,在這個過程中,成本被大幅降低了。一個技術在落地場景中能夠實現爆發,成本就是臨門那一腳。
以前只有大企業才用得起的大模型,現在每個企業都用得起了。以前大公司需要依賴專業人員來構建和維護私域知識庫,如今每個公司都可以自己利用Agent來構建定製化的私域知識庫。
根據傅盛的構想,距離我們實現這樣的場景並不遙遠。
傅盛將剛剛過去的2023年稱為奇蹟年。這一年因為ChatGPT的出現,刷新了人類科技探索的高度,甚至l會對人類底層生活產生重大影響。2023年作為導火索,點燃了大模型之火,而這把火將在接下來的一年徹底燎原。
2024年,將會是大模型的應用“大”年。
—END—
本文為零態 LT 原創,未經允許,請勿轉載
原文鏈接:https://mp.weixin.qq.com/s/9sOsW9xCdZ7qmE_sR2m_gA