中美是AI領域的第一梯隊,各有千秋,不存在美國技術碾壓_風聞
岩王帝菌-2小时前
來源:微博@格竹熊
簡直受不了那些傻缺了,中美是AI領域的第一梯隊,各有千秋,不存在什麼美國技術碾壓的情況。
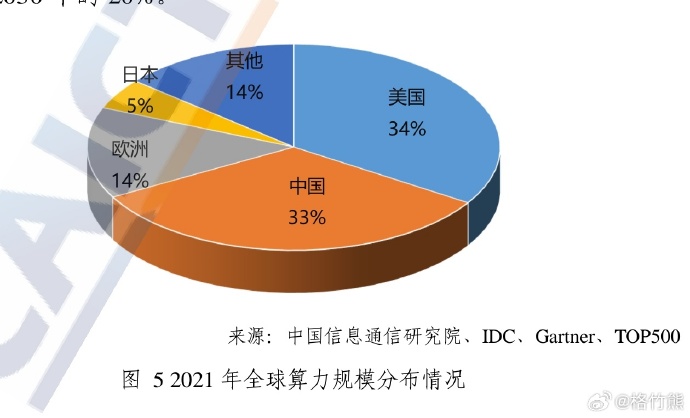
一、中美AI算力基礎設施比較。
在總算力上,美國佔全球的34%,中國佔33%,差距很小,兩者構成絕對的第一梯隊。在智能算力上,中國佔全球的45%,美國佔28%,中國在規模上絕對領先,目前智算中心20個,在建智算中心20個,是美國的一倍多。
中國總算力略低的主要原因就是芯片有差距,單位算力低於美國。隨着今年芯片陸續突破,中國有望在算力和規模上均大幅超過美國。
英偉達老黃之所以着急,千方百計要繞過制裁,主要是因為:一是中國規模實在太大了,二是華為昇騰和寒武紀為代表的AISC芯片有望取代英偉達的強項GPU實現彎道超車。
二、中美AIGC大模型比較。
AIGC就是生成式人工智能,包括現在很熱門的NLP模型(神經語言)和CV模型(圖像視覺模型)。這類大模型很多,但各有側重,應用場景也不同,撿幾個典型的來比較。
1.ChatGPT——百度文心。
這兩都屬於典型的LLM語言大模型。LLM是NLP的重要一環,主要是針對自然語言的理解、貫通、補齊。ChatGPT領先百度文心一個半身位。GPT3.0是1750億參數量,最新的文心參數量是2600億,大概處於GPT4.0的水平。
不過百度文心能同時滿足C端和B端且更偏向B端。ChatGPT目前來看更偏向C端。
2.華為盤古大模型——無
盤古大模型主要面向B端行業端。谷歌和微軟也有做同類的,但與盤古比基本屬於打醬油的。舉個例子:你問AI識別一列火車的型號,GPT會給你個教科書的標準答案,但你要問它通過圖片視頻來預測和判斷火車的故障類別,它能提供的回答就很有限,因為美國的鐵路已經無法提供足夠的參數和樣本訓練了。同樣,你要是問它高鐵在時速350公里下輪軌的磨損檢測,它根本無法回答,因為它連高鐵什麼樣都沒見過。
3.阿里通義千問大模型——微軟
通義千問也與ChatGPT類似可以對話生產內容,但更側重辦公和助手。大概是因為阿里自己有搞釘釘吧。但是與微軟的大模型相比就差得比較遠。前者參數量是1500億,而後者參數量達到5000億。這主要是微軟有GPT加持,自己又是長期搞辦公助手的。不過阿里開源,也很符合阿里的風格——自己搭台,吆喝大家一起幹。
4.騰訊混元大模型——Open AI Text和谷歌Switch
混元大模型也與ChatGPT類似可以對話生產內容,但更側重創新創意。這是因為騰訊獨一無二的生態,微信社交媒體屬性下交易、公眾號、小程序、遊戲等等商業應用,讓騰訊極為重視龐大客户羣體AI應用的可擴展性。其參數設置達到萬億級別。相比下,GPT4只有兩千多億,能與之匹敵的是谷歌Switch大模型,後者參數量1.6萬億。
所以,雖然大家都是AIGC模型,但是每家的側重點和應用場景是不同的,中國的模型更偏向B端的行業應用。而美國因為產業空心化,更偏向C端(個人)方面的虛擬應用。這就導致普通公眾對中國的AI比較陌生,而容易被美國的喧鬧所吸引。
現在很多人把AI簡單理解為問答、寫作、做點圖片視頻。然後做一些簡單比較就忙着瞎吹神吹。
普通公眾跟風就算了,你們那些號稱搞投資、財經的“專家”也是人云亦云,跟風炒作,甚至生些莫名其妙感嘆反思,連行業應用都不知道,你們平時都在忙着研究什麼呢?研究給哪個老闆提褲子?研究怎麼忽悠散户買你們的理財產品?