Sora未成曲調先有聲?_風聞
何鲸洛-文字可以流氓,初心不敢或忘;公众号:一笔封禅1小时前

出品©一筆封禪
作者@何鯨洛
如果説2022年末。
OpenAI聊天機器人ChatGPT的面世是為AI技術張開了“嘴巴”。
那麼2024年2月16日。
OpenAI宣佈推出全新的生成式人工智能模型“Sora”,則是為AI技術打開了“眼睛”。
①Sora一出誰與爭鋒?▽
2月16日。
OpenAI宣佈推出全新的生成式人工智能模型“Sora”。
據瞭解。
通過文本指令。
Sora可以直接輸出長達60秒的視頻,並且包含高度細緻的背景、複雜的多角度鏡頭,以及富有情感的多個角色。
例如一個Prompt(大語言模型中的提示詞)的描述是:
在東京街頭。
一位時髦的女士穿梭在充滿温暖霓虹燈光和動感城市標誌的街道上。

在Sora生成的視頻裏。
黑衣紅裙女子走在霓虹街頭。
不僅動作連貫、鏡頭的移動,周遭,以及水面的反射效果都相當自然。
一眼看去。
甚至有種電影的質感。
也難怪有網友表示Sora要顛覆電影業。
更早之前。
2023年8月。
Runway將Gen-2生成視頻的最大長度從4秒提升到了18秒。
9月。
Runway又官宣Gen-2新增了導演模式,可以控制“鏡頭”的位置和移動速度。
11月。
Runway家標誌性的AI視頻生成工具Gen-2,迎來了“iPhone時刻”般的史詩級更新。
依舊是簡單一句話輸入。
但視頻效果卻可以拉到4K超逼真的高度!
此後不久。
Gen-2又新增了“Motion Slider”的功能,可以調節視頻中的動作幅度。
與此同時。
2023年11月。
美國AI初創公司Pika labs發佈了第一個產品Pika 1.0。
Pika 1.0的新功能主要有以下幾個方面:
一是用文本和圖像生成視頻,只需要輸入幾行文本或上傳圖像,就可以創建簡短、高質量的視頻;
二是編輯更改視頻,輸入相關文本,實現對背景環境、衣着道具等元素的增減或者更改;
三是切換視頻風格,例如在黑白、動畫等不同風格中轉化;
四是更改視頻的寬高比。

專注於開發人工智能AI產品的初創公司Stability AI發佈了其最新的 AI 模型 ——Stable Video Diffusion。
這款模型能夠通過現有圖片生成視頻,是基於之前發佈的 Stable Diffusion 文本轉圖片模型的延伸,也是目前為止市面上少有的能夠生成視頻的 AI 模型之一。
2024年1月。
字節跳動發佈文生視頻大模型MagicVideo-V2。
MagicVideo-V2是一個視頻生成流水線,通過集成多個模塊,包括文本到圖像模型、視頻運動生成器、參考圖像嵌入模塊和插值模塊,實現從文字到視頻的自動化生成。
首先,T2I模塊將文本轉化為1024×1024的圖像;
然後,I2V模塊將其轉化為動畫,生成600×600×32的幀序列。
接着,V2V模塊增強並完善視頻內容,最後通過插值模塊將幀數擴展到94個,從而在保證高保真度的同時,也保證了時間上的連續性。
②Sora的星辰大海?▽
此前。
Sora其實OpenAI研發GPT深度學習模型中的一種“副產物”。
GPT(Generative Pre-trained Transformer)是一系列由OpenAI提出的非常強大的預訓練語言模型,這一系列的模型基於Transformer算法,可以在非常複雜的NLP任務中取得非常驚豔的效果,例如文章生成,代碼生成,機器翻譯,Q&A等,而完成這些任務並不需要有監督學習進行模型微調。
2018年6月。
初代GPT上線。
2019年2月。
GPT-2上線。
2020年5月。
在訓練約2000億個單詞、燒掉幾千萬美元后,史上最強大AI模型GPT-3一炮而紅。
從初代GPT到GPT-3。
從技術的角度。
算法模型基本沒有變化,但通過堆人、堆算力來進行訓練後的結果就是GPT-3已經初步能夠“理解”人類語言。
2021年1月。
OpenAI發佈DALL·E模型,人工智能根據一段話就可直接生成圖像。
2022年4月。
OpenAI發佈DALL·E 2.0版,允許對圖像輸出進行簡單修改。
9月。
OpenAI發佈自動語音識別ASR系統Whisper。

11月底。
基於GPT-3.5模型的ChatGPT上線之後迅速火爆全網。
2023年3月。
GPT-4上線。
2024年2月14日。
OpenAI官宣ChatGPT新增記憶功能。
2月16日。
Sora上線。
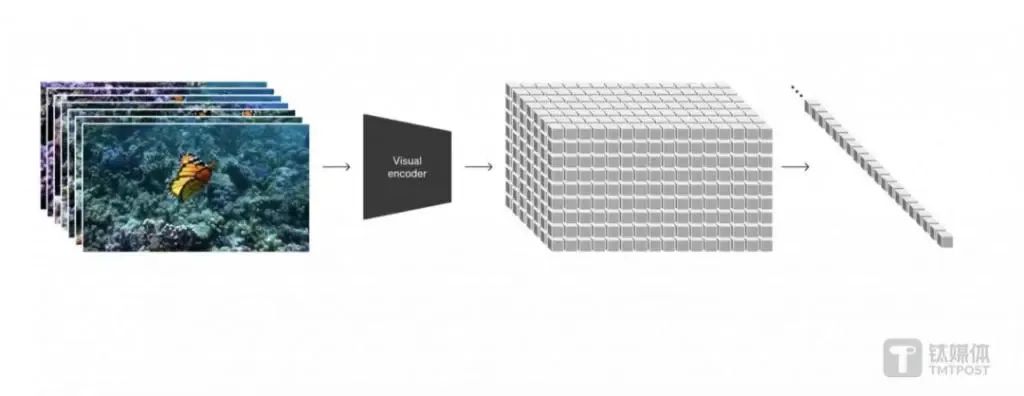
它建立在過去對DALL · E和GPT模型的綜合研究之上,提出了一種新的模型可能。
不僅可以理解用户在提示中提出的要求,還能理解它們在物理世界中的存在方式。
更重要的是:
Sora作為一種擴散模型(diffusion models)。
除了能夠根據文本指令生成視頻之外。
還能夠獲取現有的靜態圖像並從中生成視頻,準確地動畫圖像的內容並關注小細節,獲取現有視頻並對其進行擴展或填充缺失的畫面。
但Sora也不是沒有缺陷。
雖然其產出的視頻運鏡自然,物體運動符合規律,鏡頭間邏輯一致性好。
但其視頻邏輯性較差。
如一分鐘的東京街頭女郎漫步,女郎走路過程中存在腿部變形、腿部交叉換位時錯亂、右腿連續兩次在前方邁步等錯誤;
一段提示詞為 " 一個人跑步的場景 " 中,主角在跑步機上反向奔跑;
提示詞為 " 考古學家在沙漠發現塑料椅子 " 的視頻中,椅子呈現懸浮狀態。
提示詞為“五隻灰狼幼崽在一條偏僻的碎石路上互相嬉戲、追逐”的視頻中,狼的數量會變化,一些憑空出現或消失。
對此。
OpenAI表示:
Sora可能難以準確模擬複雜場景的物理原理,可能無法理解因果關係,可能混淆提示的空間細節,可能難以精確描述隨着時間推移發生的事件,如遵循特定的相機軌跡等。
但是相比於同類產品Gen-2和Pika 1.0。
Sora已經走出很成功的一步。
而且。
考慮到GPT深度學習模型是OpenAI AI技術的“大腦”。
Whisper作為“耳朵”;
ChatGPT作為“嘴巴”;
Sora作為“眼睛”。
OpenAI的每一次技術迭代。
都有可能帶來系統性的革新。
Sora將有可能成為虛擬與現實之間交互的主流算法。
當AI能夠真正的“理解”文字、圖像和視頻之後。
就已經越來越接近通用人工智能AGI了。
③Sora隱患難除?▽
與此同時。
近日。
博主@AI 瘋人院 在網絡上發佈了一部利用 AI 技術生成的《西遊記》動畫短片。
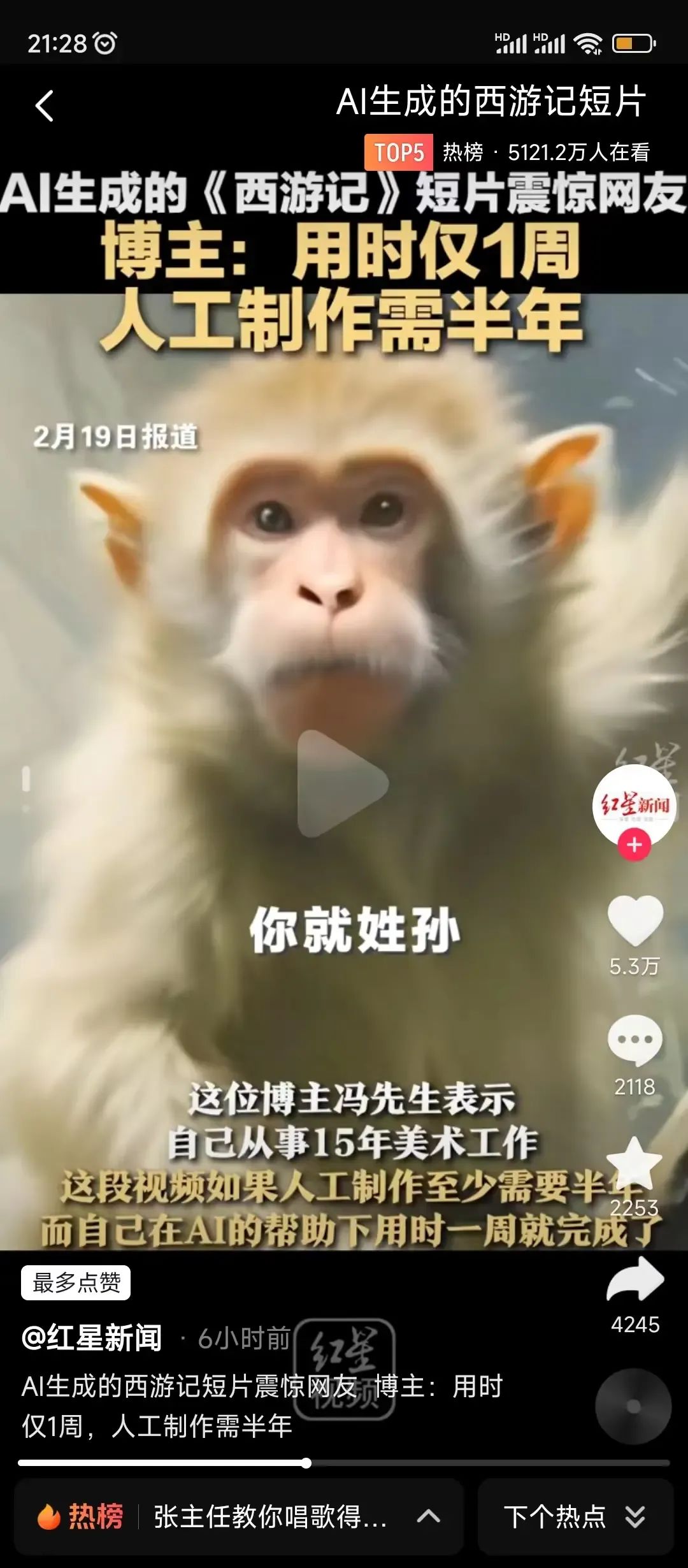
這段3分56秒的動畫短片以《西遊記》原著第一集為藍本,通過 AI 技術將石猴降生到拜師學藝的故事生動地呈現在觀眾面前。
除了《西遊記》外。
@AI 瘋人院 還用 AI 生成了絲綢之路、龍生九子、克魯蘇神話等視頻動畫,目前他在抖音上有超過十萬粉絲,收穫了超過百萬點贊。
而其步驟:
1、構思;
2、用文字生成靜態圖片;
3、讓圖片動起來;
4、整理剪輯。
由此可見。
用AI技術生成視頻幾乎沒有門檻。
尤其是Sora類產品的出現。
個人以及小規模團隊生成AI視頻將會大規模“湧現”。
但在AI生成視頻湧現創意變現之前。
AI濫用帶來的倫理問題必將是最大的障礙。
1月27日。
#泰勒斯威夫特AI不雅照瘋傳#

《紐約時報》稱。
該圖片在禁封之前被瀏覽了4700萬次。
而這。
還不是黴黴第一次被AI造假。
此前。
由人工智能生成的假泰勒·斯威夫特(Taylor Swift)帶貨廣告在社交媒體Facebook上傳播。
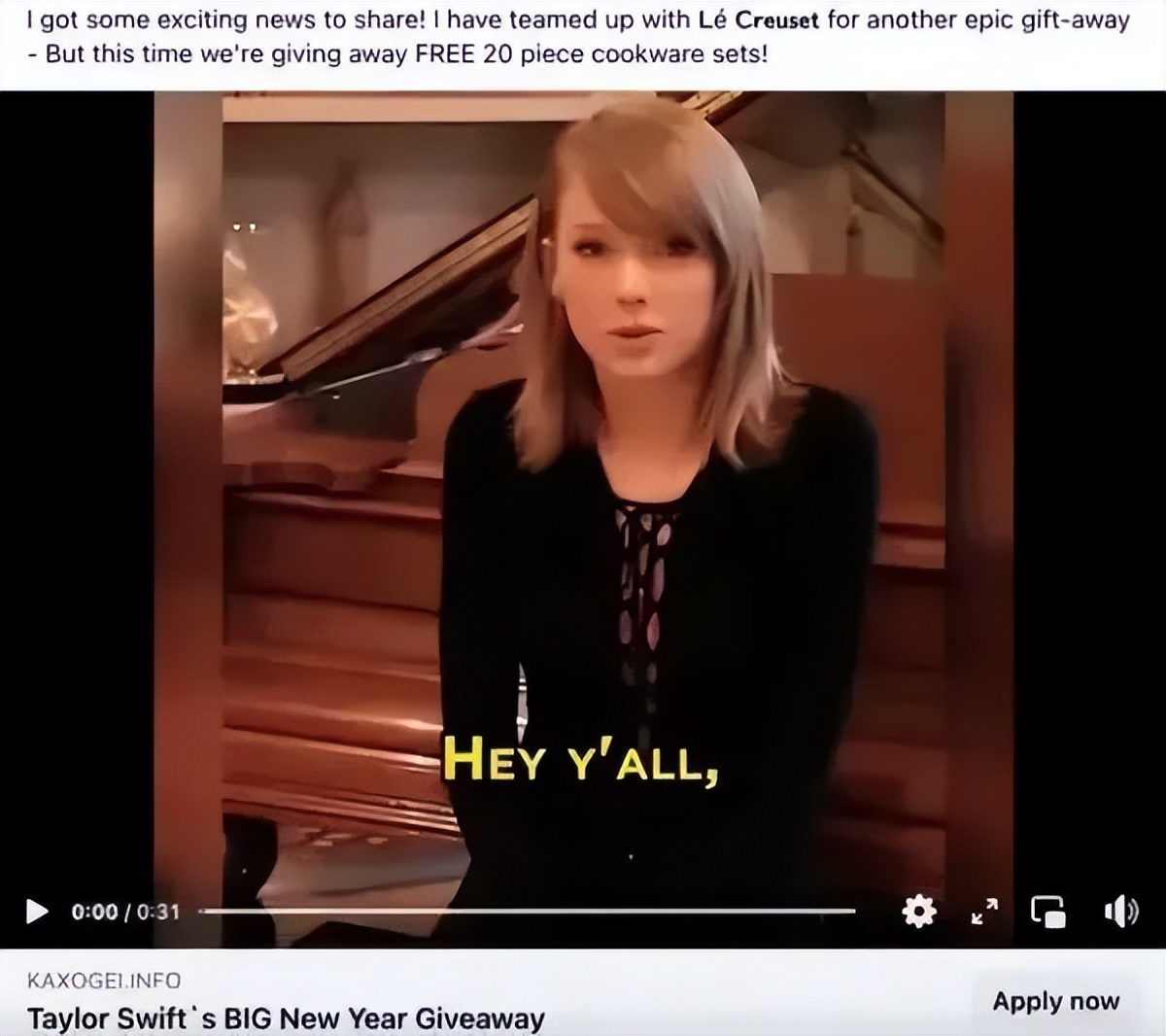
廣告詞主要為:
“嘿你們好,我是泰勒·斯威夫特。由於包裝出錯,有3000套Le Creuset炊具套裝無法正常線下銷售,轉向線上出售。有一個好消息分享給你們,我與Le Creuset聯手進行促銷——有20位忠實粉絲將免費獲得贈送的炊具套裝。”
事情發生後。
涉事公司對此迅速做出回應稱。
Taylor Swift沒有參與任何消費者贈品活動,所有關於產品促銷的活動均來自官方社交活動。AI“深度造假”技術合成了她的聲音,並將聲音與她的形象和Le Creuset廣告片段拼湊在一起。
更早之前。
2018年。
加蓬總統Ali Bongo因中風在公共視野中消失了數月。
政府為了安撫民心。
在新年時公開了一段總統錄製的新年致辭。
這段新年致辭使用了Deepfake技術進行生成,但這個視頻非但沒有起到安撫民心的作用,反而讓軍方的資深大佬發現異常,最終導致了兵變。
在這個事件中。
“AI換臉”技術成為干擾政治選舉,降低政府公信力的一大推手。

早在2017年年底。
Deepfake第一次亮相就引起了轟動。
這是一個社區裏面一位名叫Deepfakes的用户,將《神奇女俠》蓋爾·加朵的臉,嫁接到了一部成人電影女主角身上,還將視頻上傳至該網站。
可以預見。
Sora類產品上市後。
由於門檻更低;
還有技術加持;
一些似是而非的東西將會更加難以辨別。

這還僅僅只是民用市場。
放在國際關係中。
某國用來栽贓就不用“洗衣粉”那麼低級了。

最後。
我們再聊幾句。
雖然Sora真的很有想象力。
但至少當前還依舊稚嫩。