蘋果找“搭子”,地主家也搞不定AI了?_風聞
酷玩实验室-酷玩实验室官方账号-1小时前
最近,蘋果遇到的事兒挺多的,不過都不是什麼好事。
首先是在3月底,美國司法部揮舞着反壟斷的大棒,給蘋果來了一記重擊,指控它搞封閉生態系統,限制競爭對手。
這事兒一出,蘋果股價那是“嗖”的一聲,**市值縮水了934億美元,摺合人民幣約6724億,**簡直比A股的過山車還刺激!
緊接着,外界又有傳聞稱,蘋果竟然還悄咪咪地跟谷歌和百度勾搭上了,打算在今年發佈的iPhone16、Mac系統和ios18中,使用谷歌的雙子座作為英文AI,使用百度的文心一言作為中文AI,把兩家的AI技術整合到Siri裏。
當然這只是一條傳聞啦。
不過,這兩樁看似不相關的事,其實背後都繞不開同一個主題——那就是AI。

在2024年,哪個科技巨頭敢説自己離得了AI?蘋果也不例外,但讓庫克有些發愁的是,面對洶湧而來的AI大勢,蘋果自身在AI方面的進展,卻不怎麼明朗,甚至到現在連自家大模型都沒真正弄出來。
於是才有了蘋果破天荒地打算讓別家的AI,進入自家的封閉系統的傳聞。
儘管這事兒目前還真假未定,但蘋果在AI方面滯後的情況,卻讓庫克不得不深思,倘若這次的生成式AI,真的會帶來一場手機領域的顛覆性變革,那蘋果的處境就危險了。

到了那時,即使沒有司法部的制裁,蘋果自家的封閉生態,也遲早會在其他AI的圍攻下逐漸崩解。——因為用户不會接受一個沒有好AI的手機。
那麼,手機與AI的結合,到底有沒有人們想象中的那麼重要呢?
噱頭or變革?
講真,關於手機AI這件事,其實很多大廠都已經開始了佈局。
例如三星發佈Galaxy S24系列產品引入“Galaxy AI”;小米的澎湃OS融入AI大模型能力,OPPO發佈“首款端側應用70億參數AI大模型手機”——OPPO Find X7 Ultra;榮耀在Magic6系列新機上置入自研70億參數AI大模型——“魔法大模型”。
然而,這一系列火熱表象的背後,卻是手機AI雷聲大雨點小的情況,現階段,似乎很少有用户將手機AI當成換機的動力。
究其原因,還是目前手機AI能幹的事兒,實在太少了——而且幹得往往還不如雲端AI好。
現在的各種手機AI,新增的功能無非就是圖像生成,照片消除,以及文檔摘要,語音通話總結,語音翻譯等等。

但這些功能,實際上不用內置的大模型,第三方App聯網的雲端AI也能完成……
而那些內置於手機的AI,由於端側硬件的限制,往往參數很小,發揮不了與雲端AI等效的性能。
就比如語音翻譯功能,手機端側的AI可能可以快那麼兩秒鐘,但翻譯出來的話狗屁不通,那還不如等一下聯網翻譯呢。
所以,一個直擊靈魂的問題來了:手機AI存在的意義,究竟是什麼?

關於這個問題,最近蘋果披露的一篇技術論文,似乎提供了某種可能的答案。
在這篇名為《ReALM: Reference Resolution As Language Modeling》的論文中,蘋果不但發佈了自家的最新模型ReALM,而且還提出了一種新穎的思路:讓AI將屏幕上的東西都轉化成文字,然後讓語言模型去理解。

具體來説,ReALM在運作過程中,會先通過視覺技術識別屏幕上的各種元素,例如按鈕、圖標、文本框等。之後,再對這些實體進行編碼,記錄每個元素的確切位置和它們的關係。
最後,AI會將這些實體和位置信息,轉換成詳細的文本描述,並輸入語言模型,讓其學會解析用户的指令。
例如,你現在在手機上用微信聊天,AI就能把聊天框裏所有的記錄、文件,和它們在屏幕上的位置都記下來,轉化成一段話,比如“聊天框中部有個連接,是一篇關於自動駕駛的文章”。
換句話説,有了這個技術,你無論在屏幕上幹什麼,甚至在想什麼,都逃不過AI的法眼。
並且,因為AI有了和你“同時觀看”屏幕的能力,所以在交互的時候,即使有些指令説得模糊,或者不太清晰,AI也能理解你在指的是什麼。
比如你跟AI説,“剛才視頻的那個東西是什麼?”,AI就能知道“那個”是指的是蘋果還是香蕉,這就是所謂的**“實體參考解析”**。
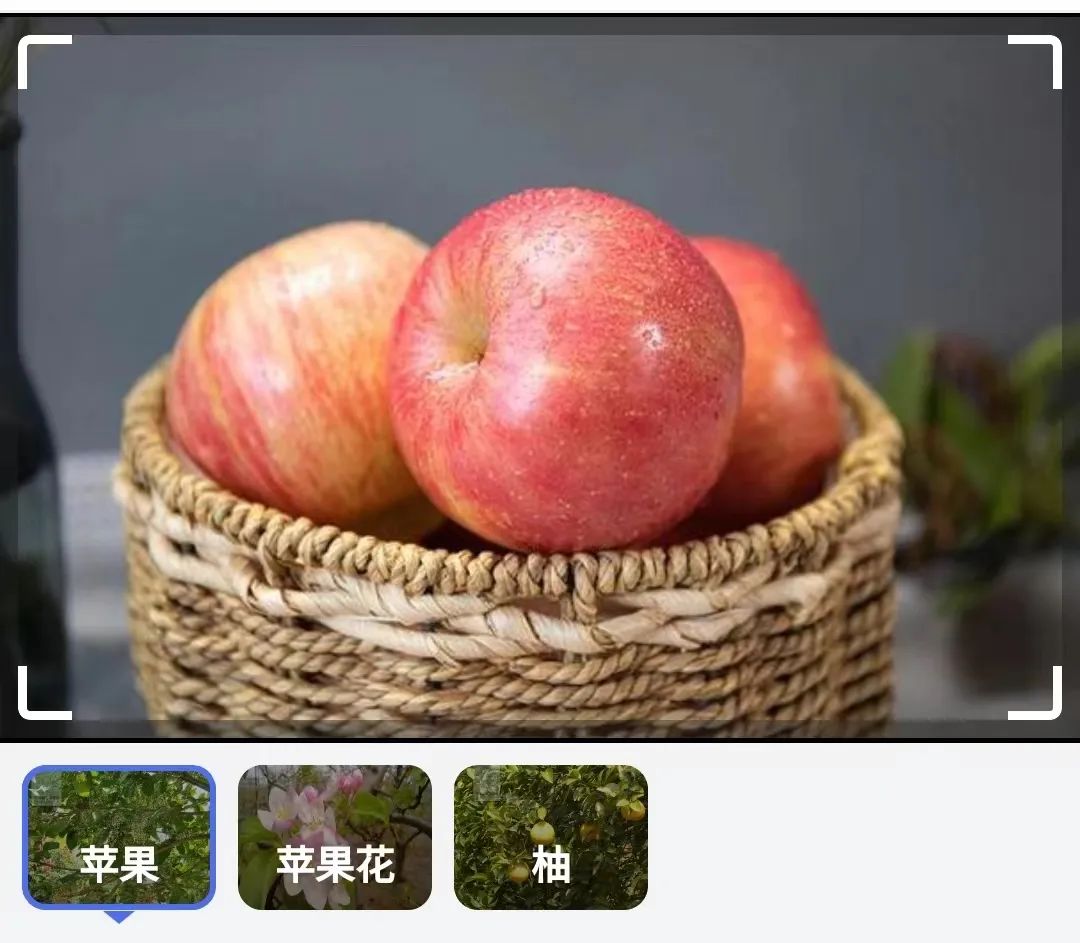
根據論文,研究者將來還打算探索更精細的空間編碼技術,比如用一種更高級的方法來“畫”屏幕,就像用網格一樣標出每個東西在哪兒。
在此基礎上,研究者還想讓模型擁有記憶,“記住”和用户在一段時間內的交互歷史,並結合這些“記憶”來解析當前的查詢。
那諸如此類的功能,將來應用在手機上,究竟能發揮怎樣的功效呢?
一種可能的答案,就是用來針對某些信息密集型APP在使用過程中的複雜查詢。
手機AI的三個階段
什麼是信息密集型APP?簡單來説,就是那種用起來會生成、處理或者顯示一大堆信息的應用程序。
例如某些社交媒體APP,像微博、微信那樣的,每天得有幾百萬人在上面髮狀態,有數不清的文章、動態要看,回不完的消息在顯示。

再就是某些電商APP,比如淘寶、京東,上面有成千上萬的商品信息,每個商品都有自己的圖片、價格、評價、銷量等等。
針對這些APP,簡單的摘要、總結,或是圖片識別等功能,顯然是不夠用了,因為在使用這些APP進行信息篩選的過程中,人們常常會遇到那些不是一兩句話就能説清楚的問題,或者是那種需要繞幾個彎才能搞明白的請求。

舉例來説,假設你在視頻APP上看了一部科幻電影,覺得特效特別棒,於是就問:“這部電影的特效用的是什麼技術?”
又或者,有時你想起在微信上看過的一篇公眾號文章,覺得其中有一句話很有意思,但想不起文章名了,只能大概地説:“我想找一篇關於問界汽車的文章,裏面好像提到了自動駕駛”。
這樣的需求,就叫做“複雜查詢”。
如果説,現階段各類手機AI所具有的總結、摘要,以及AI照片消除等功能,是AI在手機上較為初級的第一階段,那麼這種針對密集信息進行復雜查詢的AI,則代表了將來AI在手機上進階的第二階段。
而這第二個階段,也在某種程度上解釋了,為什麼AI大模型非得內置在手機系統裏,因為**只有一個內置在系統中的AI,才能進行跨應用,跨平台的功能調用,**從而讓AI的觸手伸向每一個APP。
但如果只是做到了這點,其實還不足以完全顛覆各大互聯網巨頭打造的APP孤島,因為各個APP,實際上也可以通過在應用內置AI的方式,在一定程度上實現這樣的複雜查詢(實際上,某些APP,例如B站,已經開始嘗試那麼做了)。
真正對當前手機生態造成顛覆性影響的,或許是手機AI的第三個階段,也就是AI在手機上通過AI智能體(Agent)技術實現各種自動化操作,並初步建立起一種輕量級人****機融合的階段。
舉兩個簡單的例子,比如我們賣飛機票訂酒店,很多時候攜程、飛豬等等平台裏面的價格都是不一樣的,能不能讓手機上的AI智能體跨平台總結三個合適的選項讓我做最終決定?
或者説,我一覺醒來,微信裏面諸位大佬發了好幾百條朋友圈,我沒時間一一去看,能不能讓我的手機自己去幫我看,如果朋友分享的是好事,就鼓勵互動一番?
做到這些的前提就是手機要足夠了解我。
也這就需要通過前面提到的類似ReALM的技術,讓手機AI可以在伴隨用户的過程中,通過觀察屏幕上的各種操作,分析和總結出一個人使用手機時既定的行為模式,之後再結合機器學習算法,建立起每個用户的個人大腦/思維模型。

之後,再將這樣的模型,與Agent技術結合,從而在手機上實現一種更為自動化、個性化的操作。
這也是當前的大模型,走向手機、PC,以及所有個人化終端最大的意義之一。
人機融合
與馬斯克的腦機接口有點類似,手機AI與個人思維、習慣的結合,本質上也是**讓手機作為人體一種延伸出來的“器官”或“義體”,**去實現人類現有的思維和肉體難以實現的操作。
例如同時寫好幾份報告、文章,還能同時刷視頻,逛淘寶啥的。
那具體怎麼才能實現這點?前面提到的Agent技術就成了關鍵。
今年2月,由北京交通大學和阿里的研究人員共同發佈的一項研究成果,就揭示了將來在手機上實現這種全自動操作的可能。

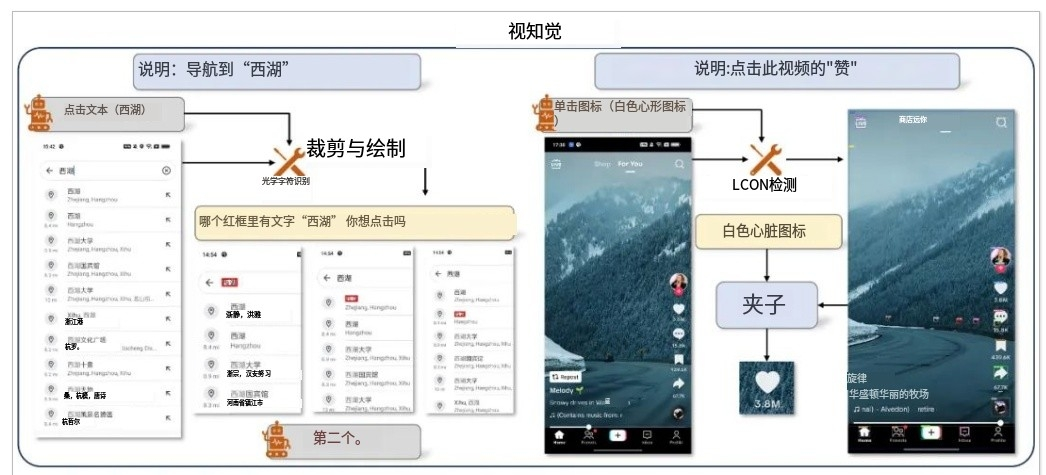
簡單來説,在這個研究裏,這個叫做Mobile-Agent的智能體助手,用了一種特別的“視力檢查”技術,能認出屏幕上的字啊、圖標啊這些東西,有點類似於前面蘋果的ReALM技術。
但比蘋果的技術更進一步的是,這個智能體在識別屏幕的基礎上,還具備了自主規劃的能力。
在測試中,用户想讓它在Youtube上找金州勇士隊當家球星,小球時代的開創者,兩屆MVP得主斯蒂芬·庫裏的視頻,並在下面發表個評論,它還真的就在全程無人為控制的情況下完成了這些操作,而且沒有任何錯誤。
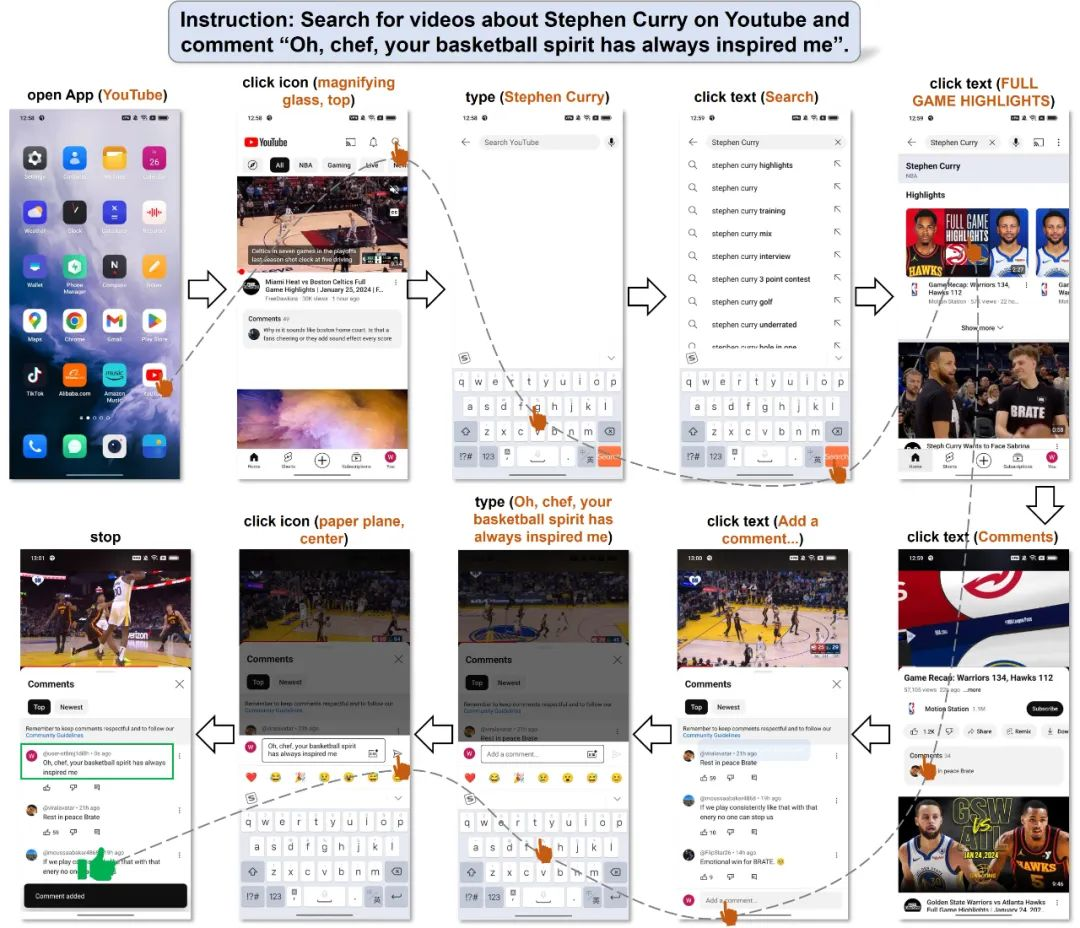
同樣地,即使是面對某些操作多App 的要求,它也能得心應手。
例如用户讓它查詢今天的比賽結果,然後根據結果寫一個新聞。Mobile-Agent接到任務後,先在瀏覽器App裏找到了比賽的比分,接着,它退出了瀏覽器,打開了記事本App。最後,它把比分寫了下來,還按照新聞的樣子給整理了一下。
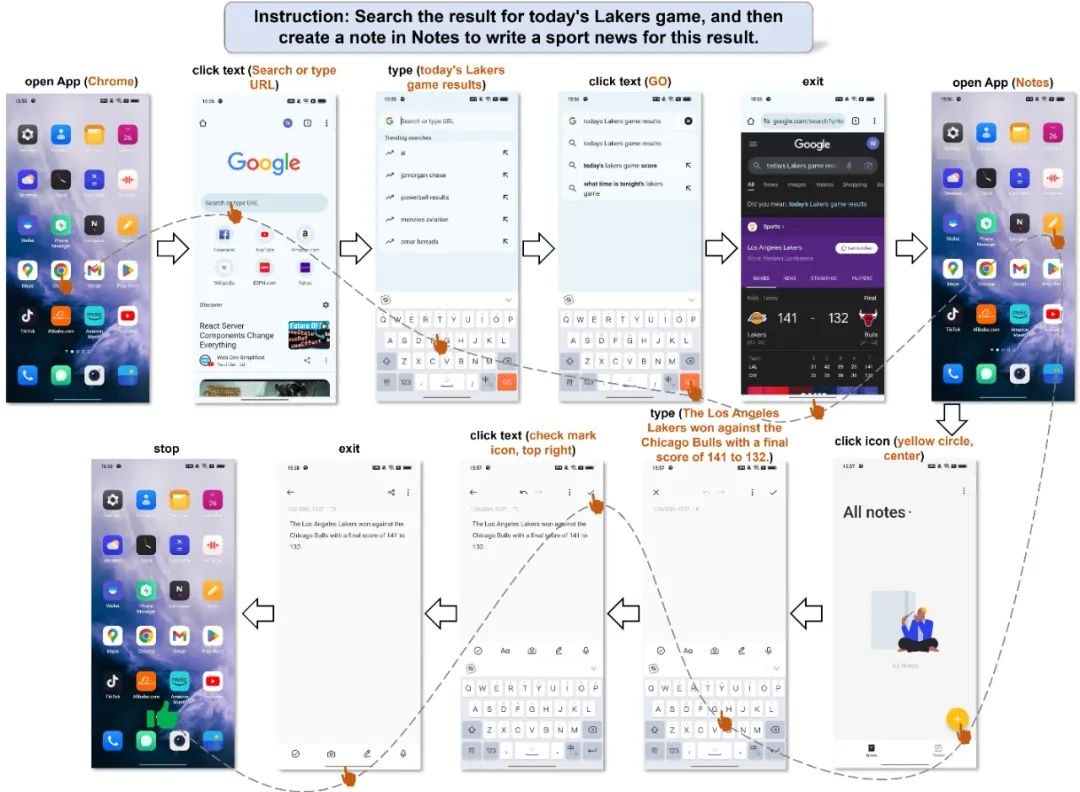
而Mobile-Agent之所以能實現這種多APP、多任務的操作,靠的正是自我規劃與自我反思的能力。
在Mobile-Agent做事的過程中,在做完第一步後,它就會看一下當前手機屏幕的截圖,看顯示的是不是所需的APP界面,如果是的話,它就知道上一步做對了,然後繼續規劃並執行下一步操作。
如果不是,它就會“反思”一下,重新修正操作,根據不斷變化的截圖,調整下一步的操作,直至最終完成任務。
這種自動化的流程,倘若與前面蘋果的ReALM技術相結合,那麼AI在觀看並學習了用户操作習慣、行為後,就能基於個人習慣,更熟練地進行各種多APP、多任務的複雜操作。
例如對於某個經常需要寫稿的編輯來説,AI在觀看了他對手機的使用習慣後,便可以知道,他經常上的是哪些網站,看的是哪些公眾號、視頻。
進一步地,AI會根據這樣的軌跡和習慣,建立起一個大致的思維/習慣模型,在他需要寫稿時,從不同的APP蒐集文章、視頻,與他進行交流。最後再將交流的成果凝練,輸入進其常用的文檔工具。
當這樣輕量級人機融合進一步演化,並延伸到其他領域時,人類智能的提升和優化,以及對生產力的影響,也將進入一個新的階段。
例如在複雜工業環境中,手機上的多模態感知,能讓AI實時規劃和指導作業流程;
在醫療領域,集成生物傳感器、醫療影像分析等AI能力,手機等終端能夠全面感知和分析人體健康狀況;
甚至在軍事領域,這種人機融合的能力,在戰場上還能加深各種智能化裝備與士兵的契合度,出現一種類似“賈維斯”的存在。
意義與影響
如果要論手機AI帶來的最直接的影響,那恐怕就是將現在愈發萎靡的手機市場給盤活了。
去年,在華為Mate60系列的引領下,全球智能手機市場似乎有了復甦的跡象。但國際數據公司IDC卻揭示了這種復甦背後的“危機”。
IDC數據顯示,2023年全球智能機出貨量同比下降3.2%至11.7億部,為十年來最低,當年中國智能機出貨量約2.71億台,同比下降5%,也創下近10年以來最低出貨量。而蘋果雖在去年以20%的市場份額穩居第一,但新機激活量同比出現—10.6%的下滑。
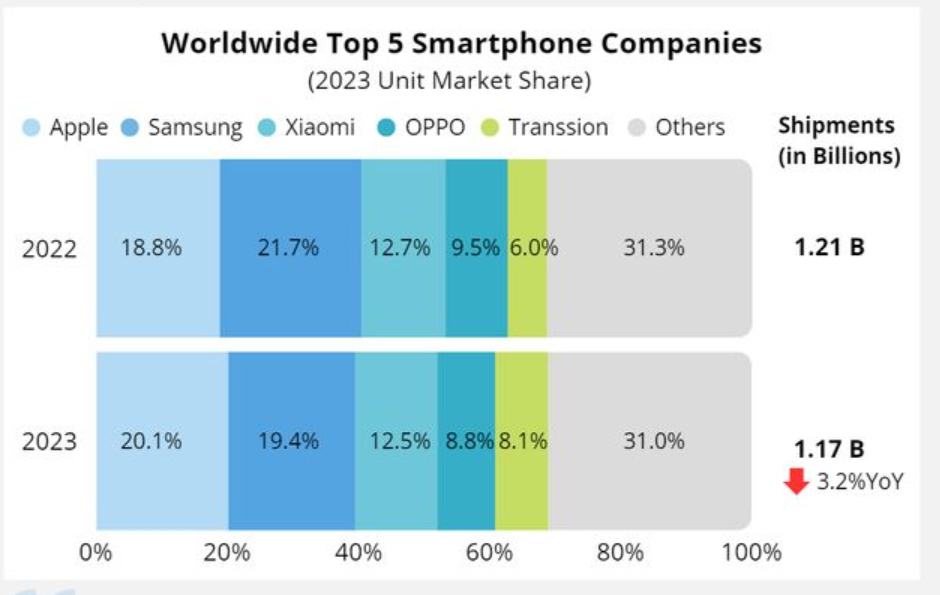
由於同質化和性能過剩問題,很多人覺得沒有必要頻繁更換新機。因此,消費者平均四年零三個月才會考慮換新機。
事實上如果沒了銷量,也就沒必要研發先進製程的芯片了,到時候沒人買,也沒有海外市場可以佔領,研發也沒啥意義了。
而如果手機AI真的給人帶來了顛覆性的體驗,到時勢必會刺激新一輪的換機潮,而相應的芯片需求也將水漲船高,因此手機AI便和端側芯片形成了一種相互促進的關係。
而第二點較為重要的影響,就是通過手機AI,相應的廠商能夠擴大AI數據積累。
具體來説,通過聯邦計算的方式,AI會先利用手機本地的用户交互數據,對模型在設備端進行訓練,這時只有模型的參數在更新,原始數據不會離開手機(這也解決了隱私問題)。
而分別在大量手機上訓練出許多模型後,服務器會收集並聚合它們的參數,得到一個全局模型。全局模型再下發給各設備,重複上述訓練聚合流程,形成迭代優化。
在此情況下,誰率先佔領了手機AI的市場,誰就能讓**數以億計的手機用户成為自己海量的“數據源”,**從而為訓練更強大的AI模型提供寶貴的資源。

雖然雲端大模型(閉源),也能實現這樣的“數據飛輪”,但效果卻不會像本地化了的手機AI這樣直接,原因就在於本地化部署使得數據採集更加直接,中間環節更少。
最後一點頗為重要的影響是,通過這一個個海量分佈的手機AI,端側小模型將有可能對雲端大模型形成一種“農村包圍城市”的態勢。
具體來説,手機上有大量不同的應用場景,如拍照、打車、購物、辦公等等,每個場景都有特定的AI需求。這些細分場景,難以用通用的雲端大模型高效覆蓋,因為需要針對性地訓練和優化。
而端側的小模型,則可以專門為每個應用場景量身定製,隨着越來越多的應用場景"嵌入"端側專用AI模型,就逐漸形成了一個覆蓋手機各領域的完整AI生態系統。
用户在使用手機時,基本上所有AI需求都可在端側得到滿足,無需調用雲端服務。
這樣一來,雲端大模型在手機場景的發展空間就會被逐步蠶食和壓縮。
在這樣的態勢下,端側小模型,最終將很可能將佔據那些無處不在、滲透性較高的生活場景(相當於“農村”)。
而云端大模型,則將佔據那些更加集中、通用,且對算力要求更高的場景(相當於“城市”),例如對長文檔,長視頻的總結、分析等任務。
各方進展
從技術上來説,決定手機AI將來發展的,主要有三大關鍵技術,分別是:端側芯片、小模型技術、Agent技術。
就目前來看,在端側芯片方面,表現較為突出的主要有高通、聯發科和蘋果,雖然從製程技術、CPU架構這兩個關鍵指標來看,三者看上去都不分伯仲(都是4nm),然而具體在端側大模型的部署方面,勝出的還是聯發科的天璣9300。
其不僅支持在手機端運行最大**330億參數的大模型,**而且能夠在1秒內生成圖像,以及以每秒20 Tokens的速度生成文本。
在此之前,大部分的手機廠商,都很難做到在手機端部署超過100億參數的大模型。

而天璣9300其之所以能做到這點,最重要的,就是採用了硬件生成式AI引擎和全大核CPU架構這兩個關鍵技術。
用大白話解釋,前者是一種將AI引擎直接集成在芯片中的技術,而後者則是將所有的**CPU核心都設計成高性能的大核心,**這樣CPU就都能夠處理複雜的任務,而且處理速度很快。
但是,僅僅在硬件方面下功夫,還不足以在手機AI方面獨佔鰲頭,畢竟端側芯片的性能上限,再怎麼也不可能和PC端的高性能GPU相提並論。這就決定了塞進手機裏的大模型,參數終歸不可能超越PC。
所以,想要在手機AI上取得突破,另一個需要發力的方向,就是小模型技術。
而這門技術的關鍵,就在於將模型變小,塞進手機(或其他終端)的同時,還能讓模型保持不錯的性能。
而在這方面,目前實力較為靠前的企業,當屬微軟和國內的面壁智能。
早在今年2月,微軟就宣佈收購了在小模型方面頗有建樹的歐洲公司Mistral,而後者的過人之處,正是“四兩撥千斤”,通過參數更小的模型,取得比大參數模型更好的效果。
其主要的代表作,就是參數只有70億的Mixtral 8x7B。在許多基準測試中,Mistral 8x7B的性能已經達到甚至超越了規模是其25倍的Llama2 70B。
而微軟自己推出的Phi-2,雖然規模更小**(僅27億參數)**,但得益於“教科書質量”數據的訓練,目前已在基準測試中超過了更大的模型,如70億參數的Mistral和130億參數的Llama2。
這性能,這大小,看起來已經“壓縮”得很極致了,可國內的面壁智能,在今年2月直接來了個王炸,**用20億參數的MiniCPM,**就實現了參數是自己數倍,甚至數十倍模型相媲美的性能,例如Llama2-13B(130億)、Falcon-40B(400億)等。
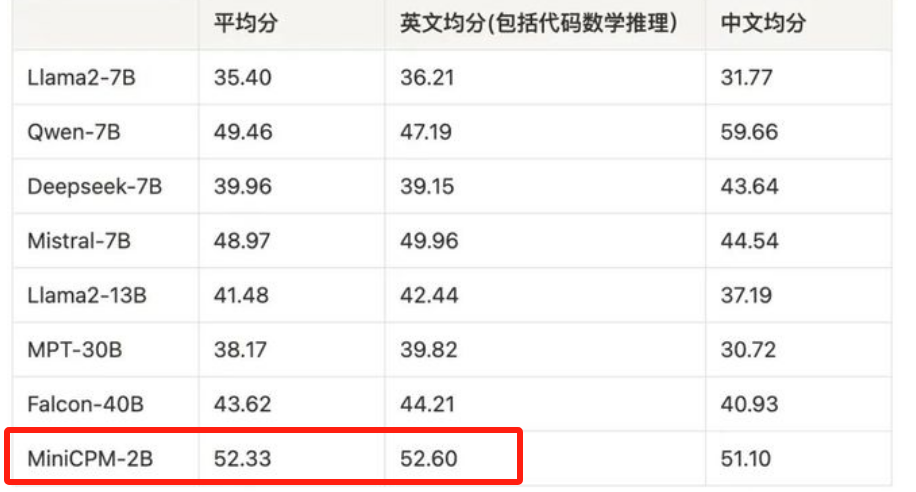
最厲害的是,MiniCPM不僅能在手機上流暢運行,推理成本還低到令人髮指——170萬tokens僅1塊錢!
如此一來,在小模型方面,國內已經做到了與國際巨頭並駕齊驅,甚至略微反超的水平。
而將模型變小,除了能更好地將它“塞進”手機之外,更重要的一點,就是小模型比大模型更容易被靈活調度和部署,而這也是在手機上實現Agent技術的關鍵。
因為所謂的Agent技術,實際上就是讓多個AI分工協作,實現自動化流程的一種技術,而大模型雖性能更強,但卻結構複雜,像個不易馴服的大象,而小模型雖小,但勝在結構簡單,輸出和行為更易於控制。

這就好像訓練十幾只分別精通不同任務的猴子,要比訓練一個什麼活都會幹的大象要容易多了。
之前提到,AI Agent在手機上的應用,是實現各種自動化操作,帶來顛覆性體驗的關鍵。而在這方面,上面提到的面壁智能,可以説取得了獨佔鰲頭的優勢。
其憑藉自身Agent技術打造的項目**ChatDev,**甚至得到了斯坦福大學教授、AI科學家吳恩達的盛讚。

吳恩達講解ChatDev
ChatDev就是讓一羣AI智能體扮演不同角色,合夥開發一個軟件項目。
人類開個頭,説做啥軟件。設計師AI就給出創意界面設計;程序員AI寫代碼;測試員AI檢查Bug。他們會像真人團隊似的,反反覆覆討論優化,最後呈現一個能運行的軟件。
要是這種技術用在手機AI上,是能實現各種複雜操作的關鍵。

因為越是複雜操作,需要分工的環節就越多。比如你去開個會,用手機拍了視頻,想剪輯加字幕、校對、配圖片標題什麼的,再發到某APP上。這麼多環節,每一步都得有專門的“崗位”和“角色”在幹活。
現在的一些Agent應用,比如AutoGPT,雖然“自動”、“高效”了,但處理不了這麼多不同“角色”之間如何合作的問題。
面壁智能的ChatDev之所以牛逼,不僅僅在於它讓多個AI智能體分工合作,而是在於它如何讓這些智能體高效、協調地工作。
結語
倘若手機AI的“ChatGPT”時刻真的來了,那麼有兩種後果,是很可能會出現的。
其一就是軟件和服務的主導權將改變。
與當前由谷歌、蘋果等主導軟件和服務不同,未來AI手機,很可能由AI公司或專門的AI應用公司主導生態系統。相較於“半路出家”的手機廠商來説,起步更早,投入也更專一的AI企業,例如OpenAI、面壁智能等,無疑能提供更好的端側大模型。
到了那時,手機市場,乃至其他移動硬件市場的主導權,很可能就會變天了。蘋果這種起步較晚,且處於**“兩線作戰”**(既要顧AI,又要顧硬件)的企業,能不能守住自身的封閉生態,會是個很大的未知數。
其二,則是“算力枷鎖”的打破。
前面提到,隨着手機AI的成熟,端側小模型將有可能對雲端大模型形成一種**“農村包圍城市”**的態勢。而在更大的國際尺度上,這種態勢會呈現出更復雜的形態。
因為相較於對算力要求頗大的雲端AI而言,手機上的端側AI,對芯片、硬件的需求,實在是小巫見大巫了。
基於這一前提,加上華為在芯片領域撕開的缺口,以及中國龐大的移動用户體量,倘若手機AI將來真的盤活了,那相當於中國部分地規避掉了美國在AI算力方面的封鎖。
更進一步地,這樣對算力依賴較低的特點,還會讓端側小模型在發展中國家和新興市場進一步普及。
如果説,端側大模型,讓人們看到了AI有多強大,而手機AI這樣的端側模型,則將讓人看到,AI究竟可以惠及多少普通人。