UCIe,將Chiplet帶向何方?_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。47分钟前
UCIe(Universal chiplet interconnect express)是芯片生態系統的開放式行業互連標準,在這個生態系統中,來自多個供應商的芯片可以封裝在一起。UCIe 1.0 規範定義了使用標準和先進封裝技術與平面互連的互操作性。隨着用於芯片三維集成的封裝技術的進步,凸點互連間距逐漸縮小,我們在此探討 UCIe 的發展。
我們報告了針對封裝凸點間距小至 1 µm 的連續性的die-to-die解決方案,並提供了電路架構細節和性能結果。我們的分析表明,與傳統信號接口的發展趨勢相反,隨着凸點間距的減小,頻率的降低可以實現這些架構最節能的性能。
當凸塊間距接近 1 微米時,我們的架構方法可提供接近或超過單片系統設計的功耗、性能和可靠性特性。
多芯片封裝集成已廣泛應用於商業產品中。例如英特爾的 Sapphire Rapids 和 AMD 的 EPYC 和 Ryzen 等中央處理單元,以及英特爾的 Ponte-Vecchio3和 Nvidia 的 Hopper等通用圖形處理單元。這種使用芯片的方法已經應用了幾十年 ,這種方法使用芯片--較小的芯片封裝在一起後實現了較大芯片的功能--可以滿足日益增長的計算需求,並克服先進工藝節點中的芯片微粒限制和良率挑戰。先進封裝技術的飛速發展使設計人員能夠在封裝上實現芯片間的互連,並使摩爾定律得以延續。
除了克服reticle limits和良率挑戰外,使用封裝內芯片還有其他各種令人信服的理由。其中包括降低整體組合成本,重複使用芯片有助於避免因採用先進工藝幾何尺寸而激增的知識產權移植成本,同時還能利用與採用更成熟工藝節點相關的低成本優勢。
此外,由於可在重複使用舊芯片的同時添加或替換新芯片,從而縮短了設計和驗證週期,因此還具有上市時間優勢。定製解決方案也是可行的,通過將具有新功能的芯片與現有芯片混合到一個封裝中,可以創建系統級封裝(SiP)變體。這提供了一種開放的即插即用基礎設施,類似於電路板級的 PCI Express和 Compute Express Link(CXL)產品。
UCIe是一種開放式行業標準互連,可在異構芯片組之間提供高帶寬、低延遲、高能效和高成本效益的封裝內連接(圖 1a)。未來三維(3D)封裝架構的凸點間距有望低於有機封裝的歷史最小值(約 90-110 微米)和增強型二維(2D)架構的歷史最小值(約 10-55 微米)。該領域的最新工作研究了各種封裝選項對一組參考片上系統器件的D2D (die-to-die) 實現的功耗、性能和麪積的影響。
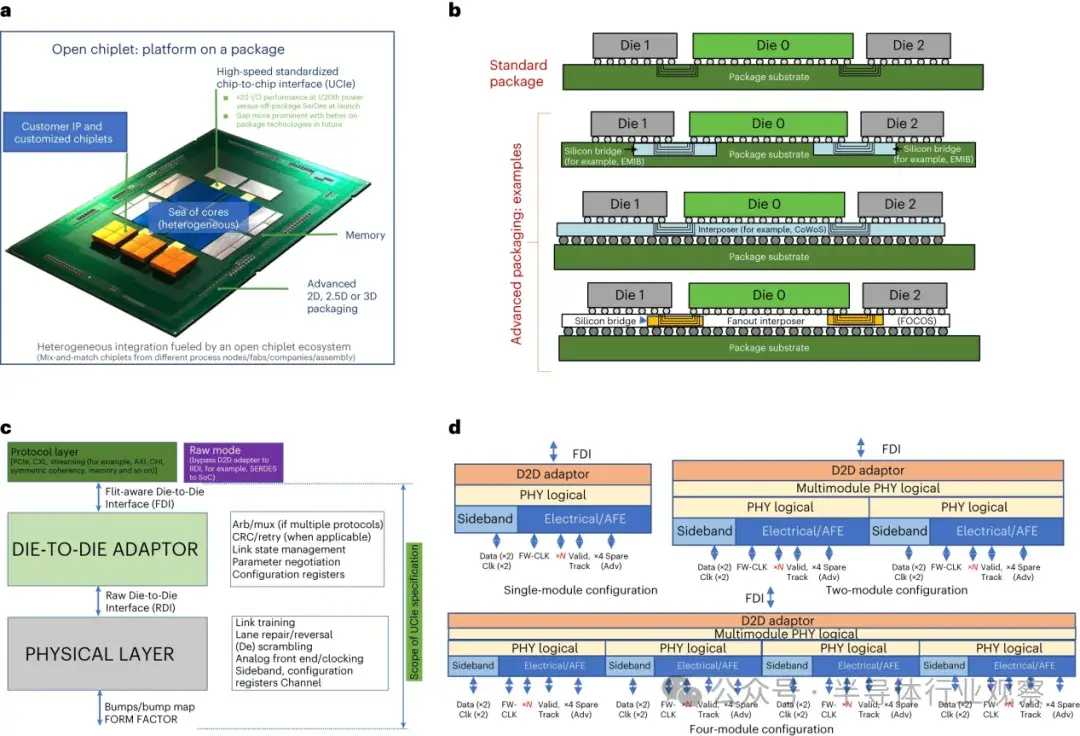
a.異構開放式芯片組封裝(就像現在的平台一樣)--開放式芯片組生態系統 UCIe 支持不同代工廠的不同功能芯片組在任何組裝組織中的混合和匹配。b.UCIe 1.0 支持兩種類型的封裝:帶有標準凸點的標準封裝,以及由不同代工廠和外包半導體組裝和測試供應商提供的帶有微凸點的各種高級封裝,如圖中所示的 2D 和 2.5D 選項示例。c.UCIe 1.0 規範的分層方法。d.應用 UCIe 的多模塊配置。PCIe,外圍元件互連快車;AXI,高級可擴展接口;CHI,相干集線器接口;RDI,原始芯片到芯片接口;SoC,片上系統;FDI,飛點感知芯片到芯片接口;Arb,仲裁;mux,多路複用器;EMIB,嵌入式多芯片互連橋;COWOS,基板上芯片;FOCOS,基板上扇出芯片;AFE,模擬前端;FW-CLK,前向時鍾。在本文中,我們考慮了 UCIe 應如何隨着新興先進封裝架構中凸塊間距的縮小而發展,並報告了一種適用於封裝凸塊間距小至 1 µm 的 D2D 解決方案。對於我們的方法,我們提供了相應的電路架構細節以及詳細的性能分析。我們還考慮了使用我們的方法構建未來 SiP 所需做的工作。
UCIe 1.0 規範概述
UCIe 1.0 定義了兩種封裝類型(圖 1b):標準封裝(UCIe-S)和高級封裝(UCIe-A)。標準封裝用於實現高性價比。高級封裝用於實現高能效性能。
UCIe 1.0 是一個分層協議(圖 1c)。物理層(PHY)負責電信號、時鐘、鏈路訓練、邊帶、電路結構等。UCIe 支持不同的數據速率、寬度、凹凸間距和信道範圍,以確保最廣泛可行的互操作性,詳見擴展數據表 1。基本單元是一個模塊,由 N 個單端、單向、全雙工數據通道(UCIe-S 為 N = 16,UCIe-A 為 N = 64)、一個用於驗證的單端通道、一個用於跟蹤的通道、主頻帶每個方向的差分轉發時鐘組成。邊帶由每個方向的兩條單端通道(一條數據通道和一條 800 MHz 轉發時鐘通道)組成。邊帶接口用於狀態交換,以促進鏈路訓練、寄存器訪問和診斷。多個模塊(1、2 或 4 個)可以聚合在一起,以提高每個鏈路的性能(圖 1d)。
D2D 適配器(adaptor)負責通過循環冗餘檢查和鏈路層重試機制可靠地傳輸數據。當支持多種協議時,適配器定義底層仲裁機制。當適配器負責可靠傳輸時,256 字節流量控制單元定義底層傳輸機制。PCI Express 和 CXL 協議是原生映射協議,因為這些協議已廣泛部署在所有計算領域的板卡上。光學 UCIe 芯片可在封裝外傳輸 CXL,以高帶寬、低延遲和低功耗的連接方式連接處理和內存元件,從而實現在機架和吊艙級緊密耦合可組合系統的願景,而這是 2 米銅纜無法實現的。此外,UCIe 還支持作為流協議的其他專有協議。UCIe 還支持用於連接高速串行解串器 (SERDES) 芯片或調制解調器等應用的原始模式。在這種情況下,通過連接原始 D2D 接口,繞過 D2D 適配器傳遞原始比特,因為主芯片側的外部互連有一個完整的協議棧。擴展數據 表 1 總結了 UCIe 1.0 的特性和目標性能指標。
UCIe-3D 方法
在當前的應用中,Chiplet 在封裝內以橫向(2D、2.xD)和縱向(3D)兩種方式相互連接。這裏的 2D 指的是標準有機封裝解決方案,而 2.xD 指的是具有更高密度連接的高級封裝解決方案。
本文前面提到的一些計算設備採用 2D 互連6 或 2.xD 橫向連接芯片(參考文獻 1)。內存設備製造商使用三維互連芯片已有十多年曆史。此外,還有 2.xD 和三維結合的例子,結合了橫向和縱向互連的優點。
最近的一個主要趨勢,特別是三維封裝技術,如混合鍵合(HB),是積極縮小芯片間的凸點間距,從而減少相應的互連距離及其相關的電寄生。隨着凸點間距的減小,凸點下的面積也隨之減小,給定面積下的導線數量隨凸點間距減小的平方而增加。隨着導線密度的增加和麪積的縮小,應採用與 UCIe 1.0 完全不同的架構方法。正如我們的方法所證明的那樣,如果架構正確,具有這種低凸塊間距的互連芯片將比大型單片芯片具有更好的延遲和功耗特性,並將提供摩爾定律在過去 50 多年中通過縮小晶體管尺寸所提供的相同優勢。
我們建議下一代 UCIe 將繼續採用單向設計,同時支持 2.xD 和 3D 連接,以芯片內部頻率甚至更低的頻率運行。我們將建議的下一代 UCIe 稱為 UCIe-3D。與現有的 UCIe 1.0 規範相比,我們的方法將在帶寬和能效方面帶來數量級的改進。較低的頻率和較短的距離使電路更加簡單;它們將適合凹凸區域並以較低的功率運行。由於距離短、頻率低,這種互聯方式的誤碼率(BER)更低,因此我們建議完全取消 D2D 適配器。
我們的設想是,兩個芯片使用多個獨立模塊連接,每個 UCIe-3D PHY 由片上網絡控制器(NoC)直接控制(圖 2a)。所有 PHY 的通用功能由芯片中的通用控制塊協調,以分攤開銷(圖 2b)。PHY 採用方形凸塊佈局,數據與非數據(地址、糾錯碼 (ECC)、備件等)採用專用子集羣。缺陷修復在 NoC 和芯片級進行管理(圖 2a-d)。
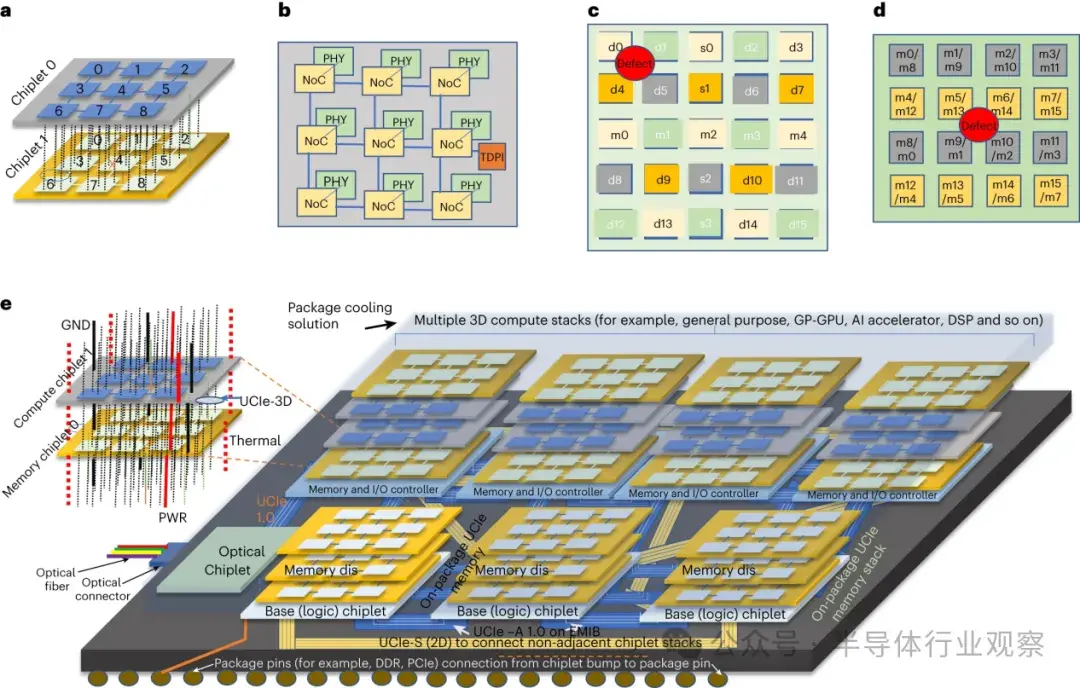
a.使用 UCIe-3D 鏈接連接的兩個芯片。NoC 在芯片內和芯片間路由流量。任何故障(NoC 或 UCIe-3D 鏈接)都可由其他 NoC 繞過。b.每個 NoC 直接連接到一個或多個 UCIe-3D 加硬物理層模塊。加固意味着晶體管的放置和佈線都是為了實現便攜性和最佳性能、功耗和麪積。每個芯片組都有一個連接到一個或多個 NoC 的通用測試、調試、模式生成和檢查基礎設施(TDPI)。該測試基礎設施負責利用 NoC 的路由網絡在 UCIe-3D 鏈路上協調培訓、測試和調試。因此,PHY 沒有任何配置或狀態寄存器。PHY 是方形的,與 NoC 的尺寸相匹配,以最大限度地減少導線的扇入或扇出,從而使導線長度接近 NoC 與 PHY 之間的最小距離,這將有助於最大限度地減少面積、功耗和延遲。c.每個 UCIe-3D 鏈路由 25 個子集羣組成,每個子集羣有 16 根導線,共 400 根導線;25 個子集羣分別為數據集羣(d0-d15)、雜項集羣(m0-m4)和備用集羣(s0-s3)。一個缺陷(製造、裝配或運行時)可能會影響多個相鄰的子簇。為了繞過故障,備件的連接方式如下(“mux “表示多對一多路複用器):S0:mux{d0, d3, m0, m2, m4, d13, d14},S1:mux{d4, d7, d9, d10},S2:mux{d5, d6, d8, d11},S3:mux{d1, d2, m1, m3, d12, d15}。這種安排確保了對於任何缺陷,附近多達四個子模塊都有唯一的備用模塊可以使用。使用備用模塊需要多路複用數據,這將導致額外的門計數。對於 c 所示的缺陷示例,s0 將攜帶 d0,s3 將攜帶 d1,s1 將攜帶 d4,s2 將攜帶 d5。d.16 個子集羣的另一種實現方式,每個子集羣有 20 多條導線,其中 16 條為數據線,其餘為雜線(地址、命令、ECC 等)。在這種安排中,NoC 可以選擇將鏈路降級為半寬(即 2:1 複用)。e.基於 UCIe-3D 架構的未來 SiP 系統示意圖。EMIB,嵌入式多芯片互連橋;GP-GPU,圖形處理單元上的通用計算;AI,人工智能;DSP,數字信號處理;PWR,電源;GND,接地。UCIe-S 和 UCIe-A 的物理層架構基於前向時鍾( forwarded-clock,源同步:source synchronous)、並行輸入輸出(IO)結構,大部分構件由高速互補金屬氧化物半導體電路構成。邏輯接口到 PHY 的典型速度為 2 GHz(參考文獻 15)。因此,在 32 GT s-1 工作速度下,邏輯接口與整個封裝互連的 PHY 發送器/接收器(TX/RX)工作之間存在 16:1 的串行化和 1:16 的反串行化(SERDES)因子。
當封裝互連實際上受到層數和 IO 凸塊間距的限制時,以足夠高的 SERDES 因子運行至關重要,因為每條封裝線都需要傳輸更多的數據。隨着凸點間距的減小,例如從 UCIe-S 的 110 微米減小到 UCIe-A 的 45 微米,D2D 帶寬和硅面積帶寬密度都實現了大幅提升。對於 UCIe-3D,這種帶寬趨勢進一步加快,以至於在不需要任何 SERDES 的情況下,以本地 NoC 頻率運行 IO 更為高效。
我們建議取消 D2D 適配器,只需讓 NoC 直接與 UCIe-3D 電路接口即可。NoC 設計人員將把電源電壓電平設置為適當的值,以滿足 NoC 邏輯時序的需要。最高效的 UCIe-3D 互連將是能夠在與 NoC 相同的電源下運行的 UCIe-3D,以避免任何特殊的電源要求。我們建議採用精簡的 D2D 數據路徑,該路徑僅由 UCIe-3D TX 凸塊上的重定時翻轉級組成,然後是一個適當大小的反相器驅動器,以滿足其自身高達 5 V 的帶電器件模型 (CDM) 靜電放電 (ESD) 要求(通過寄生二極管),以及通過 HB 連接進入 RX 反相器和其他芯片 ESD 的壓擺率要求。
我們預計,隨着凸點間距縮小到 3 µm,UCIe-3D PHY 將適應凸點區域,從而達到 0 V CDM 的要求。圖 3 和擴展數據表 2 顯示了 UCIe PHY 架構從 -S 和 -A 變體到 UCIe-3D 解決方案的演變過程。
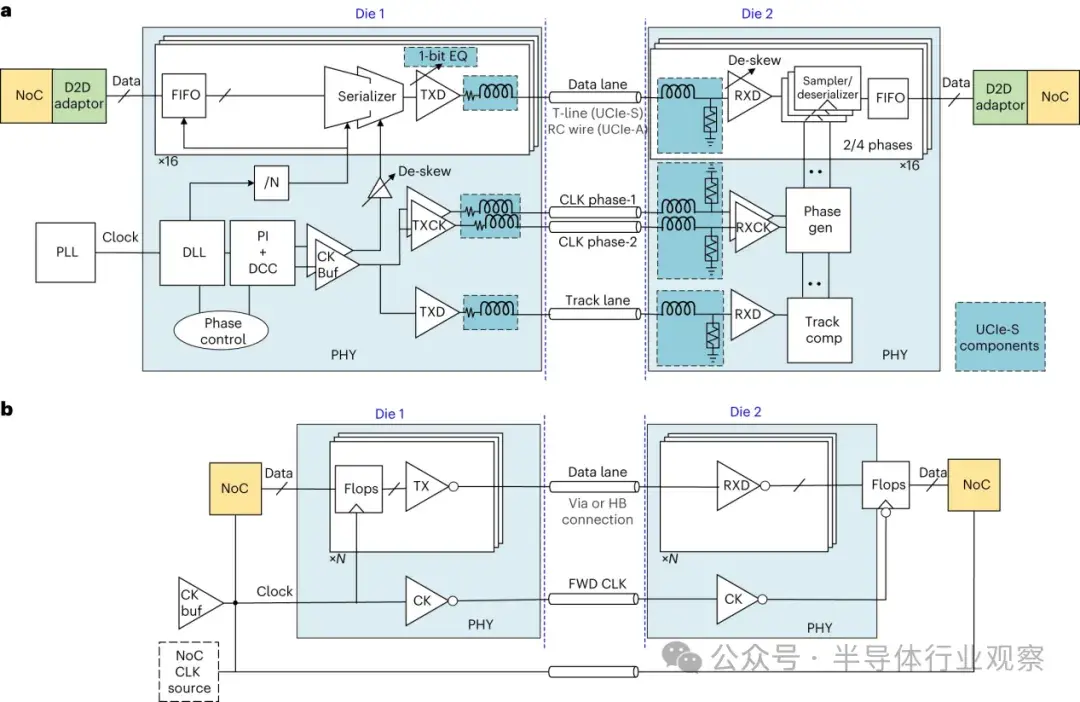
a.分別為 2D 和 2.xD 的 UCIe-S 和 UCIe-A 互聯架構。UCIe-A 的組件移除用虛線框表示。UCIe 1.0 PHY 基於 “匹配 “源同步時鐘架構,大部分元件由高速 “數字”(即互補金屬氧化物半導體開關)電路組成,包括延遲鎖定環路、相位內插器、佔空比連接器和 TX 驅動器。在低速情況下,RX 實現可以是一個簡單的反相器,而在高速情況下則需要一個更靈敏的架構。在高速運行時,UCIe-S 和 UCIe-A PHY 都需要具備常見的高速 PHY 功能,如時鐘到數據居中、車道到車道糾偏、TX 驅動器阻抗等。此外,由於 2D 互連通道的傳輸線性質,UCIe-S 還需要進行 TX 和 RX 均衡,並在 TX 和 RX 焊盤上安裝電感線圈,以在更高速度下降低焊盤電容,從而管理符號間干擾。UCIe-A 消除了面積密集型電感器、電阻器和均衡,這對於壓縮面積以支持更小的凸點間距範圍至關重要。因此,與 UCIe-S 相比,KPI 有了顯著提高,包括線性帶寬密度提高了 6 倍,面積帶寬密度提高了 11 倍,功率提高了 2 倍。b.基於我們的實施方案,UCIe-3D 的物理層架構針對小於 10 微米的凸點間距支持目標範圍進行了大幅簡化。建議的最大數據傳輸速率為 4 GT s-1,這應涵蓋目前和可預見的未來使用的大多數片上邏輯速度。我們建議在整個物理層採用源同步時鐘,並在凸塊處採用簡單的設置和保持規範,以實現靜態定時驗證。在 TX 之前,對 NoC 輸出數據信號進行重定時的邊界翻轉可最大限度地減少接收器輸出的車道間偏移。數據速率、到 NoC 的距離、工藝和時序將決定接收器輸出和 NoC 輸入之間是否需要重定時觸發器,因此圖中所示的重定時觸發器跨越了 PHY 邊界,並針對具體實現。NoC 時鐘源可以位於任一芯片上。我們提出了 0.01 pJ b-1 的目標,以實現等同或優於全單片實現的功能。FIFO,先進先出;CK,時鐘;DLL,延遲鎖定環;PI,相位插值器;DCC,佔空比校正器;Buf,緩衝器;TXCL,發送器時鐘;TXD,發送器數據;/N,除以 N;PLL,鎖相環;EQ,均衡;T-line,傳輸線;RC,電阻電容;CLK,時鐘;RXCK,接收器時鐘;Gen,發生器;Comp,補償。UCIe-3D 方法適用於綜合和自動佈局佈線工具,並能適應各種平面圖。我們建議在 HB 凸點邊界指定時序,並繼續採用 UCIe-S 和 UCIe-A 的前向時鍾架構,在凸點引腳上建立一套時鐘到數據規範。
由於 3D 連接的兩側使用相同的架構,因此只需在連接的兩側排列不同數量的 IO 模塊,即可滿足非對稱帶寬需求。TX、RX 和時鐘電路是簡單的反相器,可創建匹配的數據和時鐘路徑,在時鐘上升沿發送數據,並在相應的時鐘下降沿捕獲數據。轉發時鐘源與 NoC 時鐘源相同,在兩個芯片上共享,以避免與時鐘域交叉相關的功耗和延遲問題。
在凸塊間距接近 3 微米及以下時,我們預計分數 NoC 頻率 (FNF) D2D 交叉可能有利於功率優化。例如,在 1 µm 凸塊間距下以 4 GHz 的原生 NoC 頻率運行的 D2D 交叉可能比以 2 GHz 的頻率運行兩倍數量的導線消耗更多的功率。需要將標準環回方案(如近端(芯片內)或遠端(D2D 交叉點處))納入整體數據路徑,以便在封裝內組裝多個芯片之前進行分類測試時檢測缺陷。
UCIe-3D 分析
接下來,我們將分析 UCIe-3D 方法的效率,並展示我們在英特爾工藝節點上的實施結果(詳情請參見方法)。
隨着凸點間距的增大,理論帶寬密度可以通過這些公式計算出來:
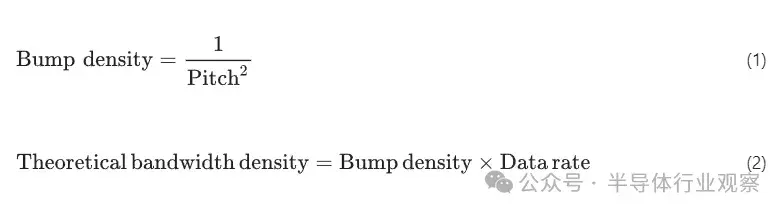


相比之下,目前 2.xD 的修復開銷約為 3%。即使在凸塊間距較小的情況下,公式(5)中的電源接地開銷也保持一致。凸點間距越大,最大數據傳輸率越高,因此需要額外的接地凸點來實現隔離和足夠的信號完整性。在間距較小的情況下,每個凸點的電流會因拉伸尺寸而受到限制,因此需要額外的電源和接地凸點來實現穩健的電源傳輸。
眾所周知,隨着互連技術的不斷發展,對額外電源凸塊的需求會逐漸減少,並有助於提高可實現的帶寬密度。圖 4 中繪製了理論帶寬密度、可實現帶寬密度和 FNF 帶寬密度,其中包含這些開銷假設以及 128 µm 至 1 µm 的凸塊間距。這些圖表顯示,9 微米間距時的理論帶寬密度與 3 微米間距時的可實現帶寬密度或 2 微米時的 FNF 帶寬密度相同,這説明了各種開銷的影響以及不斷改進互連技術以實現更窄凸點間距的必要性。根據上述公式對各點進行曲線擬合,可得出以下公式,用於預測任何凸點間距和實際開銷的實際帶寬密度:
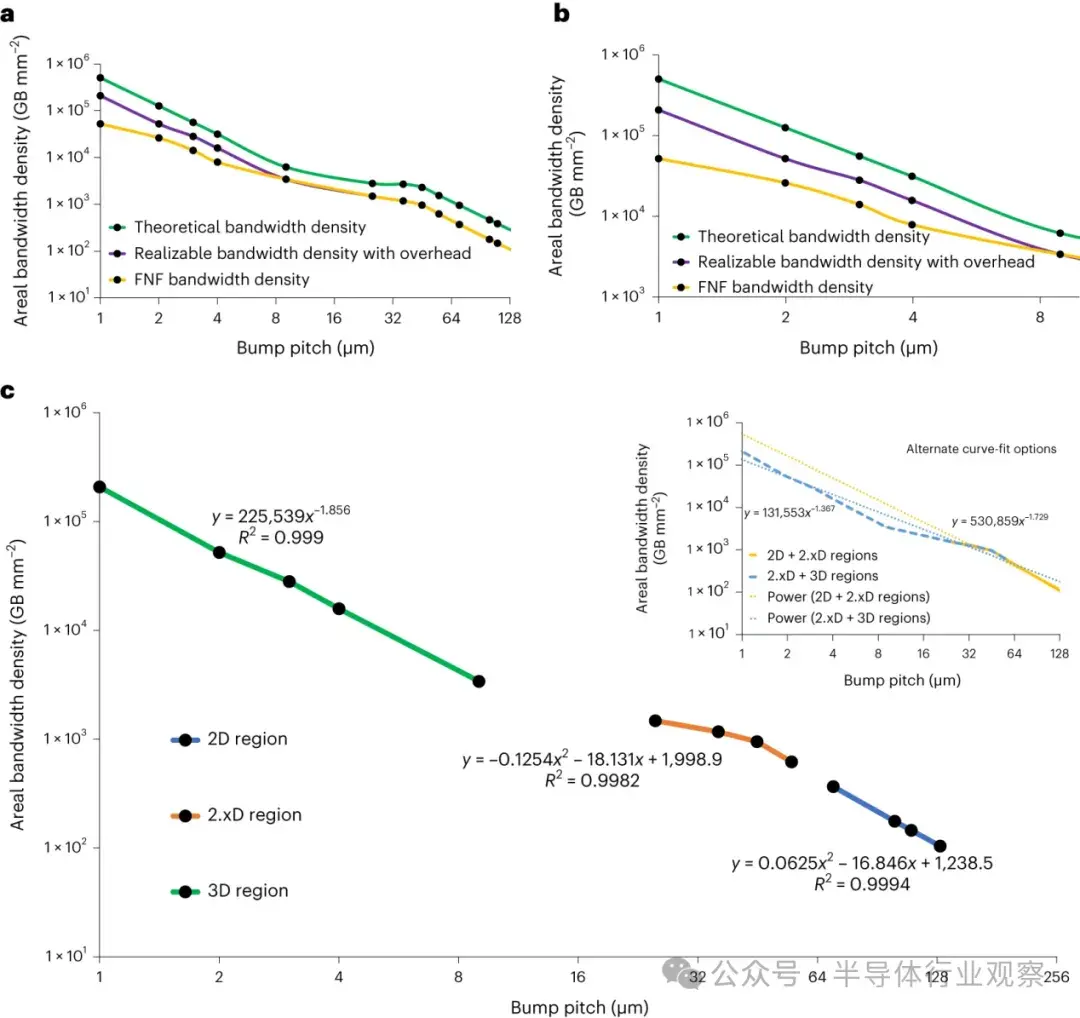

a,b,全範圍凸點間距(a)和凸點間距 <9 µm(b)的理論、可實現和 FNF 帶寬密度與凸點間距的關係。理論帶寬密度值採用公式 (2),無開銷,並假設每個引腳的最高頻率,如 UCIe 規範所述。可實現和 FNF 密度值通過公式 (3) 計算得出。在 a 中,UCIe 規範一直沿用到 25 微米間距(45 微米以下為 32 GT s-1,36 微米為 24 GT s-1,25 微米為 12 GT s-1)。在 b 中,對於 9 微米及以下的凸點間距,所使用的參數如上所述。正如 “方法 “部分所解釋的,如果我們將所有凸點間距曲線擬合為一個或兩個方程,推論誤差可能高達 ×10(一個數量級),如 c 的插圖所示。2D 區域幾乎是線性的,二次區域的權重很小;2.xD 區域主要是二次區域;而 3D 區域則以冪級數為主。這種方法將各種凸點間距的預測誤差限制在 8%以下。
FNF 使我們能夠在不超過 SiP 熱極限的情況下進一步分解片上系統器件,並有助於關鍵性能指標 (KPI),包括產品的功耗-性能-面積。在 9 µm 時,最大頻率為 4 GT s-1(根據 UCIe-3D 方法),如圖 4a、b 所示。然而,通過 FNF,我們將小於 9 µm 至 2 µm 的最大速度限制為 2 GT s-1,1 µm 時為 1 GT s-1。這樣,當間距從 9 微米變為 1 微米時,帶寬密度仍能增加 ×2,同時還能節省相當大一部分功率,這將在下文的功率部分解釋。
等式 (6) 與我們設計的實際實現具有良好的相關性和擬合性,有助於將帶寬密度推斷到 UCIe-S、UCIe-A 和 UCIe-3D 可以使用的各種間距。在曲線擬合考慮的範圍內,已經給出了足夠的重疊,以保持 2D、2.xD 和 3D 互聯區域之間邊界的靈活性。
由於分解沿多條軸線跨越多個切口,D2D 功率的微小變化在系統層面會迅速累加。D2D 鏈路會使兩個芯片之間的時序複雜化,從而增加 IO 和測試的複雜性(如前面章節所述)。如果兩個芯片採用完全不同的工藝或材料,甚至採用相同的工藝但在不同的電壓下運行,並對性能進行了優化,那麼數據路徑中的元件總數就會增加。額外的複雜性--包括獨立的芯片測試和使用線路修復的缺陷恢復--也會增加數據路徑上的元件數量。
除此之外,ESD 還在 D2D 交叉路口上增加了一個顯著的元件--電容器。圖 5 顯示了 D2D 功率與凸點間距(2D、2.xD 和 3D 區域)的函數關係,以及 9 µm 和 3 µm 凸點間距下 UCIe-3D 鏈路的功率分佈。
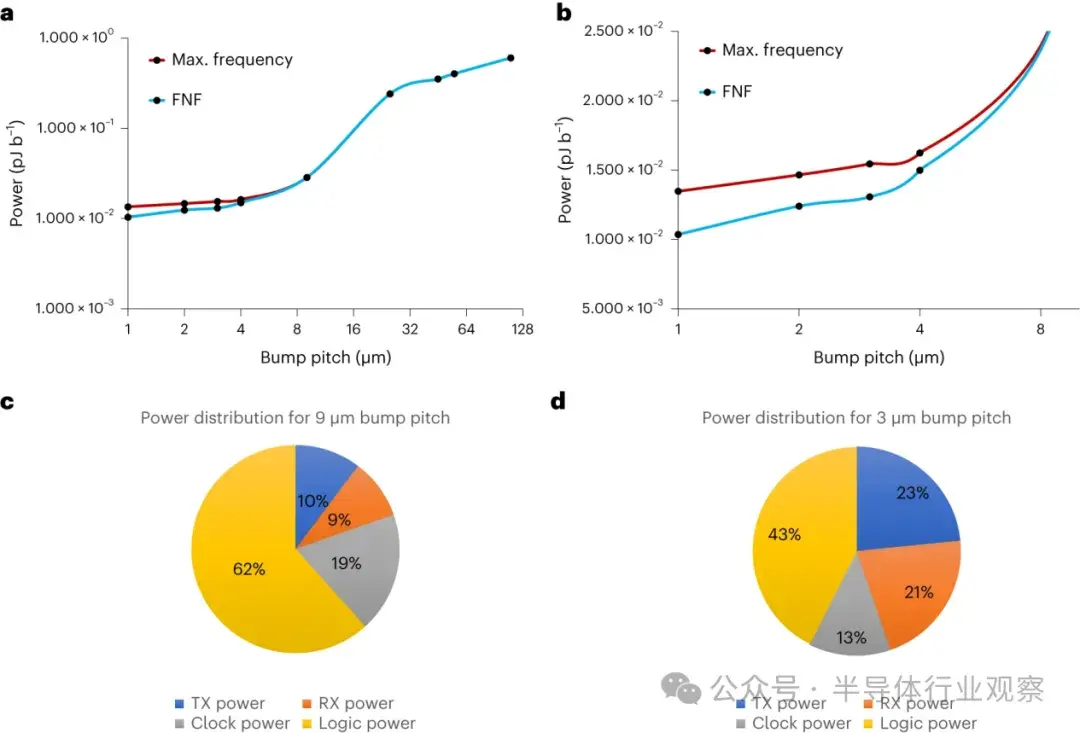
a,最大運行頻率下 D2D 功率與凸塊間距的關係曲線;b,9 微米以下間距下 FNF 鏈路的優勢。a 和 b 中的曲線假定 UCIe 規範中規定的最大頻率直至某個凸點間距(32 GT s-1 至 45 微米,24 GT s-1 至 36 微米,12 GT s-1 至 25 微米)。在 9 微米處,簡化架構在 4 GT s-1 時產生的 D2D 鏈路總功率為 0.03 pJ b-1。在 1 微米處,4 GT s-1 時的總功率降至 0.015 pJ b-1。在 1 GT s-1 時,使用 FNF 可額外節省 50%的功率;例如,在 1 µm 時,總功率為 0.01 pJ b-1。假設每 512 個全雙工數據通道有一個 TDPI,則 UCIe-3D 鏈路在較小的凸塊間距下主要由 TDPI 中的泄漏所主導。通過進一步分解和基於 NoC 的數據路徑控制,有機會進一步降低功耗。
c、d,分別為 9 微米(c)和 3 微米(d)UCIe-3D 鏈路的功率分佈示例。發射功率分量由電容主導,幾乎保持不變,因為隨着凸點間距的縮小,三維凸點寄生電容的縮放可以忽略不計。5 V ESD 增加了總功率的 15-24%,具體取決於間距。對於 30 V CDM,ESD 對 D2D 功率的貢獻會更高。未來的 ESD 趨勢(預計 CDM 水平將降低30)將有助於減輕這種影響。時鐘功率還包括髮送到其他芯片所需的轉發時鐘功率。邏輯功耗是面積的函數,隨着間距的縮小,反相器和邏輯的總數也會減少,從而將其功耗份額從 62% 降至 43%。如上所述,由於 TDPI 在間距縮小時幾乎保持不變,因此 3 微米處的功率和 9 微米處的部分功率仍以漏電為主。Max.
採用 UCIe-3D(即準單片)架構,延遲加法器可以是芯片兩側的幾個觸發器,從而使兩個芯片在兩個不同的工藝或電壓下具有最大的靈活性。通過適當的工具開發,還可以使兩個芯片的時序趨同,並進一步降低延遲,使其看起來像單片 IO。隨着凸點間距的縮小,從控制器到凸點的距離也會縮短,這樣我們就能去除級翻轉,使 3D 交叉看起來像單片機。
除了降低電路和邏輯延遲外,三維芯片堆疊還具有架構性能優勢。與平面佈局(單片、2D 或 2.xD 互連)相比,整體跳轉延遲降低,帶寬提高。圖 6 總結了以理想單片芯片(無產量或網紋限制)實現的計算元件與使用 UCIe-3D 連接的芯片的性能對比,兩者都使用網狀拓撲結構,每跳帶寬相同。我們使用理想的單片芯片進行 KPI 性能比較,因為它優於基於 UCIe 1.0 的芯片設計。其他應用(如內存或計算元件與內存的組合)也會出現類似的趨勢。
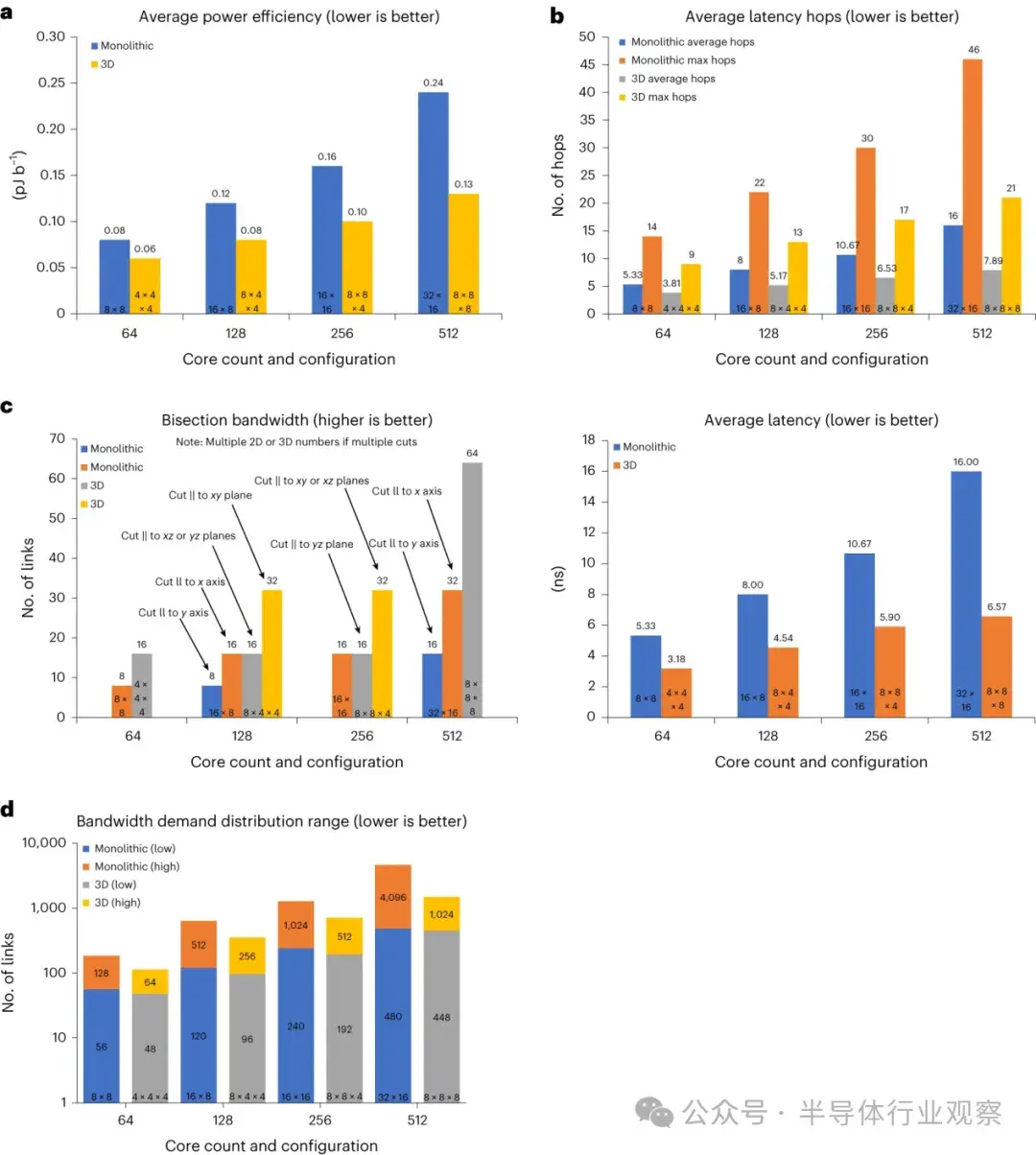
a.與單片解決方案相比,UCIe-3D 減少了跳數,縮短了傳輸距離,從而降低了平均功率。如圖 x 軸所示,比較的是四種內核數方案(64、128、256 和 512 內核);條形圖中嵌入了物理配置(例如,“8 × 8 “是指平面單片芯片上的 8 × 8 內核陣列,“8 × 8 × 8 “是指使用 UCIe-3D 堆疊的 8 個芯片,每個芯片 8 × 8)。功率值是根據公式(9)、3 毫米距離和公式(10)(0.02 pJ b-1)確定的。如果單片芯片中跳數之間的延遲數或功率數不同,趨勢也會相似。b.與單片解決方案相比,UCIe-3D 減少的平均延遲、平均跳數和最大跳數,適用於與 a 中相同的場景。c.左圖,與單片解決方案相比,UCIe-3D 增加了額外的垂直鏈路,從而提高了分段帶寬;右圖,在 a 和 b 的方案中,減少了平均延遲。d.在 a、b 和 c 方案中,與單片解決方案相比,使用 UCIe-3D 的任何鏈路的帶寬需求分佈和最大帶寬需求均有所減少。正如預期的那樣,我們看到帶寬需求分佈向中間行、列和垂直鏈路增加,因為大部分通信都通過這些鏈路。數字越小,説明分佈越合理,從而減少了擁塞。最後,在可靠性方面,我們使用時間故障(FIT),即 109 小時內的故障次數。理想情況下,芯片組所有 UCIe 鏈路的 FIT 值都應為 1,這樣鏈路的貢獻就只佔芯片組典型 FIT 值(100)的極小部分。雖然我們預計芯片組的錯誤檢測和糾正在 UCIe 鏈路中不會發生變化,但我們忽略了任何形式的 ECC,也忽略了所有鏈路中的所有通道同時處於活動狀態,以獲得對 FIT 的悲觀估計。我們建議指定誤碼率為 10-30;這將導致 100 Tb s-1 帶寬下的 FIT 為 3.6 × 10-4(方法)。由於每個芯片都有內置的錯誤檢測和糾正邏輯,即使誤碼率的目標是 10-27 ,這個數字也會低幾個數量級,隨後的例子就證明了這一點。
結論
我們報告了 UCIe-3D,這是一種利用新興的先進 3D 封裝技術構建 SiP 架構的高效能、低成本方法,其凸點間距不斷縮小。與平面實現的 2D 和 2.xD 互連或大型單片機相比,UCIe-3D 具有更低的延遲、更高的分段帶寬和更低的帶寬需求等卓越性能。
我們的方法可用於創建功能強大的芯片。特別是,UCIe-3D 方法可用於創建多個三維異構計算堆棧--每個堆棧都有自己的本地內存芯片、多個封裝上內存堆棧以及外部 I/O 和內存芯片--所有這些都通過現有的 UCIe 1.0 互連進行內部連接。在這種架構中,每個芯片組可以面對面、面對面、背對背或背對背配置與上層或下層芯片組連接。在非面對面連接的情況下,信號需要通過硅孔傳輸。我們需要進一步探索硅通孔製造和裝配技術的發展,這些技術可以根據凸點間距範圍進行擴展,並引入可忽略不計的電氣寄生,同時將 KPI 保持在當前水平。
在冷卻、功率傳輸和可靠性方面也可能面臨更多挑戰。新出現的 2.5D 和 3D 封裝架構的熱需求已經得到強調,與平均值相比,熱點峯值功率密度會增加。更多的三維堆疊芯片只會加劇這一問題,並需要更先進的冷卻能力。這種架構的功率傳輸預計也會帶來新的問題,可能會更多地依賴背面功率傳輸等技術。在可靠性方面,需要制定維修策略,同時降低對組裝工藝的靜電放電保護要求。
最後,電子設計自動化的進步也是必要的。此前已強調過對此類設計自動化能力的需求27,要創建真正的混合與匹配架構,還需要進一步的創新。