Google發佈最新AI成果:強力回擊GPT-4o,蘋果生態或將被碾壓_風聞
知危-知危官方账号-26分钟前
全場共提到 “ AI ” 121 次,平均一分半提一次。
今天凌晨 1 點( 太平洋時間 5 月 14 日上午 10 點 ),Google I/O 2024 大會的開幕主題演講,在美國山景城正式舉行。大會演講在網絡上公開直播的同時,也有部分媒體和觀眾來到了大會現場。
知危編輯部的前線同事,也到達了美國山景城參加了本次大會,全程觀看了本次開幕主題演講。

這位同事曾在 Google 前幾年的鼎盛時期參加過一次 I/O 大會,用他的話來講,那時候的 Google I/O 可以用四個字形容:萬國來朝。
而如今,Google 的光環全都被 OpenAI 搶了去,本屆 I/O 大會雖然依舊有很多人蔘加,但相較早年難免顯得有些 “ 人丁不旺 ”。( 以前還賣票的,這次沒賣 )
不過,在這場 I/O 大會上,Google 依然秀出了一些肌肉,對昨天的 GPT-4o 做出了強力回擊。
谷歌 CEO 劈柴哥在演講的一開始就坦然直言:目前正是整個行業正處於 AI 發展的早期,谷歌有信心和實力打這場持久戰。
話裏話外,一副 “ 你 OpenAI 別高興得太早 ” 的味道。
縱觀整場演講,知危編輯部認為,如果去年穀歌的 I/O ,我們看到的是谷歌在 AI 領域的孤注一擲,那麼今年,我們則發現谷歌這麼一隻巨無霸,正在 AI 的賽場上全方位一路狂奔,逐漸找回自己的狀態。
本次主題演講的內容,主打的是一個大而全,內容包含但不限於新基礎模型、AI Agent、文生圖模型、文生視頻模型、TPU芯片、AI app、Android 與 AI 、新開源大模型等等等等。
知危編輯部也準備挑選其中幾個比較亮眼產品,進行詳細的介紹。
首先,知危編輯部覺得 OpenAI 昨日的春季發佈會,有意狙擊谷歌的的可能性非常之高。
因為谷歌本次重點推出的多模態 AI 助手 Project Astra ( 基於 Gemini ),功能與昨日橫掃科技圈媒體頭版的基於 GPT-4o 的 AI 助手極其類似。
同樣擁有低延時的絲滑語音對話體驗,同樣也能用攝像頭,讓 AI 處理視覺信息。
在谷歌的演示視頻中,Project Astra 能迅速認出音響的發聲部位、彩筆,還能對屏幕上的代碼進行一定程度上的解釋。
它甚至還能根據箭頭,提出在服務器和數據庫之間添加緩存,能提高速度的建議,還能看懂畫板上 “ 薛定諤的貓 ” 的梗圖。
若不是昨日 GPT-4o 已經搶先亮相了一波,Project Astra 一定會被各路媒體打上 “ 炸裂 ”、“ 史詩 ”、“ 顛覆 ”、“ 改寫歷史 ” 等標籤。
可惜,僅僅是晚了一天,現在大家對 Project Astra 的形容只有一個標籤:“ 跟 GPT-4o 好像 ”。
不過,如果仔細觀察演示視頻,你會發現Project Astra 的視頻對話交互功能展現了一個 GPT-4o 並沒有展示的功能:視頻對話的過程是帶有記憶的,即便是一個你可能從未向它提及的點。
這樣形容起來有些抽象,看一下視頻你就能明白了。
( 這裏很抱歉的跟大家説一聲,我們翻譯了 Google 官方演示視頻並進行了上傳,但我們發現一個叫 “ AI喵能力 ” 的賬號上傳了 Google 官方視頻並莫名申請了 “ 視頻原創 ”,導致我們的視頻會被微信平台判定為 “ 侵權 ”,視頻會被強制改為轉載 AI喵能力上傳的視頻,他並未對視頻進行翻譯,影響了大家的體驗。大家有空也可以點擊視頻上方跳轉到該公眾號對其進行 “ 濫用原創能力 ”的投訴,該賬號的做法是非常違背新聞道德的,淨化網絡媒體環境從你我做起 )
在視頻中,Project Astra 注意到並記住了鏡頭經過的桌子上的眼鏡,在與測試者進行多輪對話後還能指出眼鏡在桌子上,並且還指出了 “ 旁邊有一個蘋果 ” 這樣的細節,可以説是過目不忘,比人類強了不少。
而在文生視頻領域,谷歌也對 Sora 發起追趕,在本次的主題演講中,谷歌正式發佈了視頻生成大模型 Veo。
根據介紹,Veo 能以各種電影和視覺風格生成高質量的 1080p 分辨率視頻,時長可以超過一分鐘。Veo 能憑藉對自然語言和視覺語義的深入理解,生成緊密代表用户創意願景的視頻。

此前我們曾介紹過,OpenAI 的 Sora 是基於 Diffusion Transformer,也就是 DIT 架構而成的。
但根據谷歌官方的介紹,Veo 採取的卻是 GQN、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet 和 Lumiere 等 “ 老模型 ” 所組合而成的結合架構。
非常值得一提的是,谷歌在 Veo 的生成視頻之下,標註了一行小字 “ All videos were generated by Veo and have not been modified. ”( 所有視頻均由 Veo生成,未經修改)。
這個舉動,應該是意在陰陽 OpenAI,OpenAI 的 Sora 正因被爆出演示視頻經過了大量的人為後期修改而遭受廣泛的質疑。****

另外,對標 Midjourney 等文生圖片大模型的 Imagen 3、對標 Suno 等音樂生成大模型的 Lyria、對標 GPT-4 Turbo 等輕量性能大模型的 Gemini 1.5 flash、對標 llama 3 等開源大模型的 Gemma 2,還有 Google 自家的新 TPU 等都在谷歌的本次開幕主題演講上一一亮相。
看起來,谷歌似乎不願放棄 AI 領域的任何一個賽道,想把自己打造成一個 AI 界的六邊形全能戰士。
而更可怕的是,在各個領域裏,Google 相比友商雖然都不一定是最好的,但也並不落後多少。
同時,谷歌的上限和野心,肯定不限於此。本次的開幕式主題演講中,**谷歌還拿出來些不少其他 AI 廠家單打獨鬥絕對拿不出來的東西。**知危編輯部認為,正是這些東西,有機會能讓谷歌從 AI 領域的追趕者,躋身為領跑者。
因為谷歌,擁有其他 AI 巨頭所沒有的成熟系統與應用生態。
在演講中,谷歌就展示了一波 Gemini 和 Google 相冊的結合。
記不清自個兒車的車牌號,在 Google 相冊裏搜索 “ 查找車牌號 ”,擁有多模態能力的 Gemini 會從你的圖片庫中,找到你車的照片,並告訴你車牌號。
在谷歌 Gmail 郵箱裏,你也能通過 AI 迅速提取郵箱裏航班信息,同時 Google 地圖以獲取您酒店附近的餐廳和旅遊景點,再給計劃相應的日程。谷歌的老本行搜索,也在和 AI 相結合,你可以直接用文字進行搜索,也可以給圖片畫個圈兒,讓搜索引擎自動搜索你圈出的部分。
甚至,你還可以上傳視頻對搜索引擎進行提問。比如在演示中,谷歌的員工就拍視頻問問了 Gemini,相機上的那個杆卡住了咋辦。

Gemini 馬上就給出了基於搜索引擎的答案,看上去體驗很好,可惜就是回答有些翻車,回答中的一個建議是 “ 把膠捲取出來看看 ”,而這樣只會讓整卷膠捲直接報廢。。。
不過,我們只能説貴在真實吧,大模型亂講話這事兒確實一直存在,自然展現比造假強一些。
總之,按照谷歌的説法,Gemini 大模型正在全面整合谷歌的那一大家產品中,包括在未來,他們將把 AI 直構建到 Android 操作系統的底層之中,準備改寫用户和手機之間的交互方式。
他們舉了一些例子,比如在用手機看書的時候,你可以直接給書裏內容畫圈兒,問 AI 圈兒裏的提名怎麼解;刷視頻的時候, 也有可以直接問 AI ,視頻裏這運動員的動作是不是犯規;打電話的時候,AI 也能從你們的對話裏,判斷出對方是不是有可能是個騙子。

這樣一來,在全面集成 Google 原生 AI 並且與原生 Google 應用打通的 Android 陣營面前,蘋果如果不和 OpenAI 深度合作的話,我們只能説 Android 將在 AI 時代,對 iOS 進行一場降維碾壓式打擊。( 不過,6 月的 WWDC 上我們相信蘋果肯定會搬出自己的 AI 方案來抵禦這場進攻 )
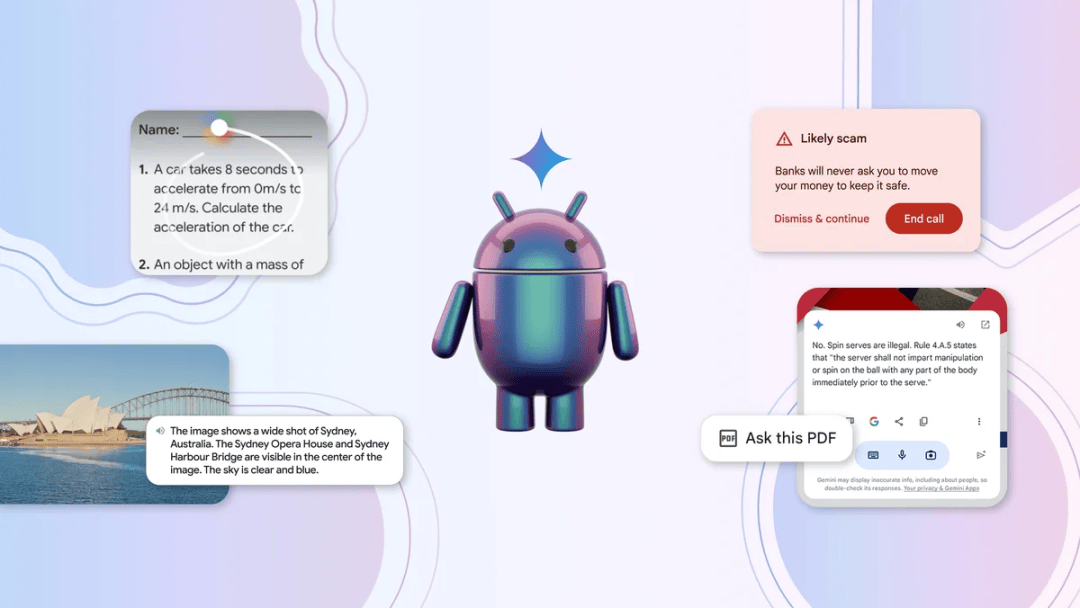
總得來講,這次谷歌的 I/O 大會啥產品都有,但要説出類拔萃,還談不上。不過,在 AI 應用集成這一個最直面消費者的維度上看,谷歌還真是目前 AI 領域的集大成者之一。
這一波,去年還被稱作是 AI 圈 “ 仲永” 的谷歌,算是漸入佳境了。