蘋果發佈第一個手機端UI多模態大模型——Ferret-UI_風聞
kasim188-52分钟前
蘋果公司最近發佈關於手機端多模態大模型的論文《Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs》(《Ferret-UI:理解移動用户界面的多模態大語言模型》)。論文介紹一個名為Ferret-UI的多模態大型語言模型(MLLM),該模型專為提升移動用户界面(UI)屏幕的理解而設計。Ferret-UI具備指代(Referring)、定位(Grounding)和推理能力,能夠與UI屏幕進行有效的互動。
Ferret-UI基於Ferret模型構建,該模型在自然圖像中表現出強大的參照和定位能力。為了適應UI屏幕的不同寬高比,Ferret-UI集成了“任意分辨率”(any resolution,anyres)技術,將整個圖像分成子圖像,以便同時適應豎屏和橫屏,能夠靈活地適應各種屏幕長寬比,並且利用增強的視覺特徵放大細節。
此外,研究者們從廣泛的基本UI任務中精心收集訓練樣本,如圖標識別、文本查找和控件列表,併為高級任務編制了數據集,包括詳細描述、感知/交互對話和功能推斷。這些樣本被格式化為帶有區域註釋的指令遵循格式,以促進精確的參照和定位。
這篇論文的關鍵點總結如下:
針對UI屏幕的定製化MLLM:Ferret-UI是首個專為UI屏幕設計的MLLM,能夠有效執行指定、定位和推理任務。任意分辨率技術的集成:通過將整個屏幕分成為子圖像,每個屏幕根據原始縱橫比分為2個子圖像(即縱向屏幕的水平分割和橫屏的垂直分割),以便同時適應豎屏和橫屏,這樣能夠靈活地適應各種屏幕長寬比,並且利用增強的視覺特徵放大細節,因此Ferret-UI能夠更好地處理UI屏幕的細節。廣泛的訓練樣本收集:研究者們為基本UI任務和高級任務生成了大量數據,這些數據涵蓋了從簡單的語義和空間任務到複雜的推理任務。綜合測試基準:研究者們開發了一個包含14種不同移動UI任務的全面測試基準,用於評估模型的性能。卓越的性能:在評估中,Ferret-UI不僅超越了大多數開源的UI MLLMs,還在所有基本UI任務上超過了GPT-4V(複雜任務還是不如GPT-4V,估計還得在複雜任務的訓練集上做文章)。
總的來説,Ferret-UI的提出為移動UI的自動化理解和交互提供了一種先進的解決方案,其在多個方面的創新和卓越性能使其成為一個引人注目的研究成果。
摘要
多模態大語言模型 (MLLM) 的最新進展值得注意,然而,這些通用域 MLLM 在理解用户界面 (UI) 屏幕並與之有效交互的能力方面往往不足。在本文中,作者引入了 Ferret-UI,這是一種新的MLLM,旨在增強對移動 UI 屏幕的理解,參考、定位和推理功能。鑑於 UI 屏幕通常表現出比自然圖像更細長的縱橫比,並且包含更小的感興趣對象(例如圖標、文本),我們在 Ferret 之上加入了“任何分辨率”來放大細節並利用增強的視覺功能。具體來説,每個屏幕根據原始縱橫比分為 2 個子圖像(即縱向屏幕的水平分割和橫屏的垂直分割)。兩個子圖像在發送到 LLM 之前都是單獨編碼的。作者從廣泛的基本 UI 任務中精心收集訓練樣本,例如圖標識別、查找文本和小部件列表。這些示例的格式主要為了指令遵循,帶有區域註釋,以方便精確參考和定位。為了增強模型的推理能力,作者進一步編譯了一個用於高級任務的數據集,包括詳細描述、感知/交互對話和功能推理。在對精選數據集進行訓練後,Ferret-UI 表現出對 UI 屏幕的出色理解和執行開放式指令的能力。對於模型評估,建立了一個包含上述所有任務的綜合基準。Ferret-UI 不僅超越了大多數開源 UI MLLM,而且在所有基本 UI 任務上都超過了 GPT-4V。
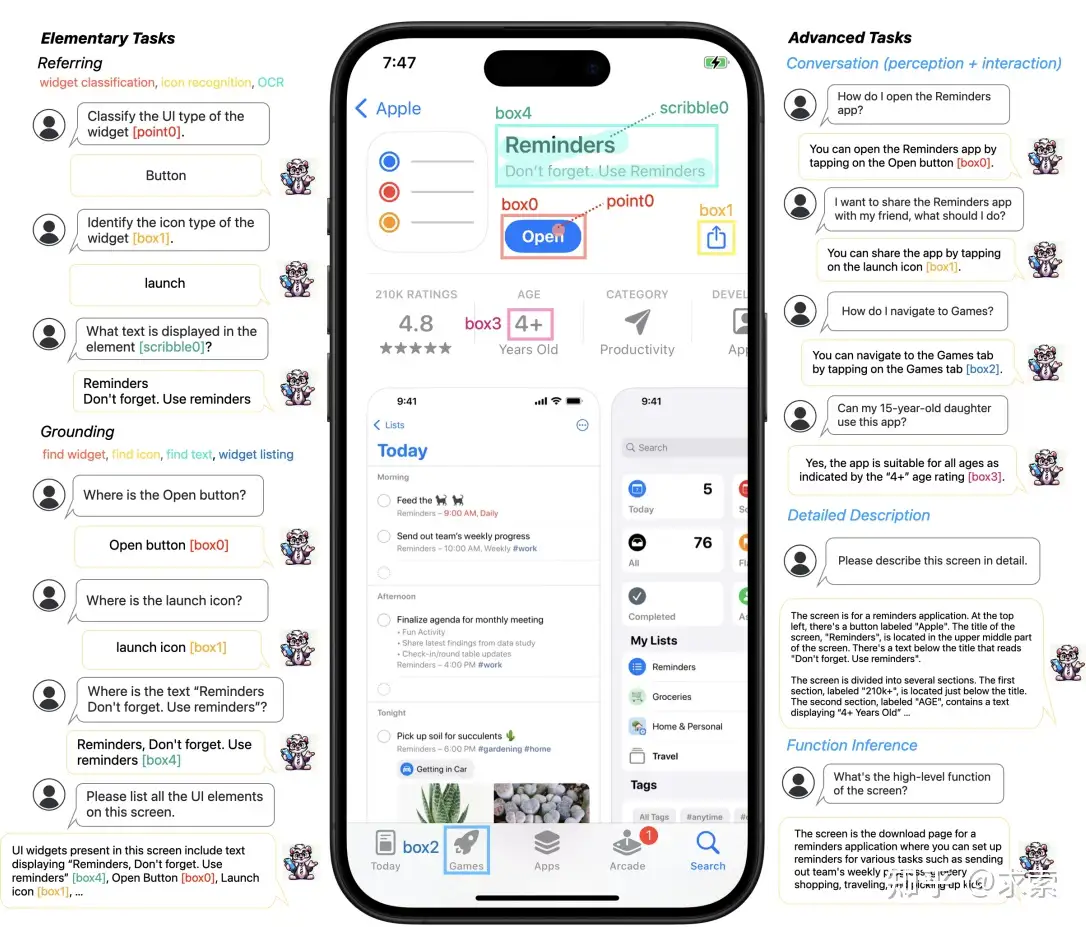
Ferret-UI能做什麼?
Ferret-UI可以執行11種任務,從基本任務到複雜任務。它能夠在移動UI屏幕上使用靈活的輸入格式(點、框、塗鴉)執行任務(例如,小部件分類、圖標識別、OCR)和定位任務(例如,查找小部件、查找圖標、查找文本、小部件列表)。這些基本任務為模型提供了豐富的視覺和空間知識,使其能夠在粗略和精細級別(例如各種圖標或文本元素之間)區分 UI 類型。這些基礎知識對於執行更高級的任務至關重要。具體來説,Ferret-UI不僅能夠在詳細描述和感知對話中討論視覺元素,還可以在交互對話中提出面向目標的動作,並通過功能推理推斷出屏幕的整體功能。
方法
Ferret-UI建立在Ferret的基礎上,Ferret是一個MLLM,在不同形狀和細節水平的自然圖像中實現空間參考和基礎。無論是點、框還是任何自由形式的形狀,它都可以解釋相應的區域或對象並與之交互。Ferret包含一個預訓練的視覺編碼器(例如,CLIP-ViT-L/14)和一個Decoder Only的語言模型(例如,Vicuna)。此外,Ferret還採用了一種獨特的混合表示技術,該技術將指定區域轉換為適合 LLM 處理的格式。從本質上講,空間感知視覺採樣器旨在熟練地管理不同稀疏度級別的區域形狀的連續特徵。
為了將 UI 專業知識灌輸到 Ferret 中,作者進行了兩個擴展來開發 Ferret-UI:
(i) UI指代和定位任務的定義和構建;
(ii)模型架構調整,以更好地處理屏幕數據。
具體來説,Ferret-UI包括廣泛的、用於模型訓練的UI指代任務(例如,OCR,圖標識別,小部件分類)和定位任務(例如,查找文本/圖標/小部件,小部件列表),這為高級UI交互建立強大的UI理解基礎。與以前需要外部檢測模塊或屏幕視圖文件的MLLM不同,Ferret-UI是自給自足的,將原始屏幕像素作為模型輸入。這種方法不僅促進了高級單屏交互,還為新的應用鋪平了道路,例如提高可訪問性。對數據集的初步探索得出了兩個建模見解:
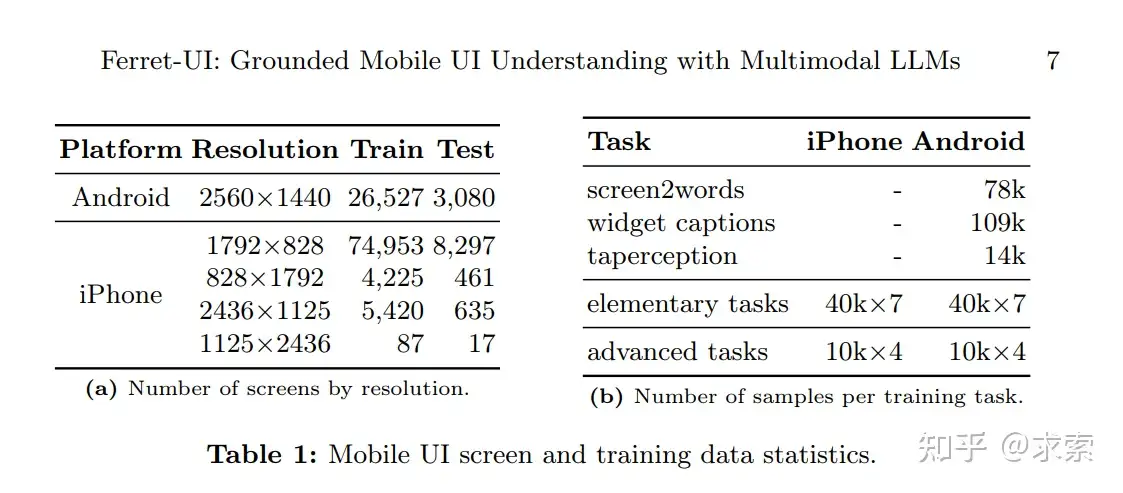
(i)UI屏幕的主要特徵是與自然圖像中的縱橫比相比,縱橫比更寬,如Table 1a所示
(ii) 這些任務涉及許多感興趣的對象(即圖標和文本等 UI 小部件),這些對象明顯小於自然圖像中通常觀察到的對象。例如,許多問題都集中在佔據整個屏幕不到 0.1% 的圖標上。因此,僅依靠單個直接調整大小的低分辨率全局圖像可能會導致視覺細節的重大損失。
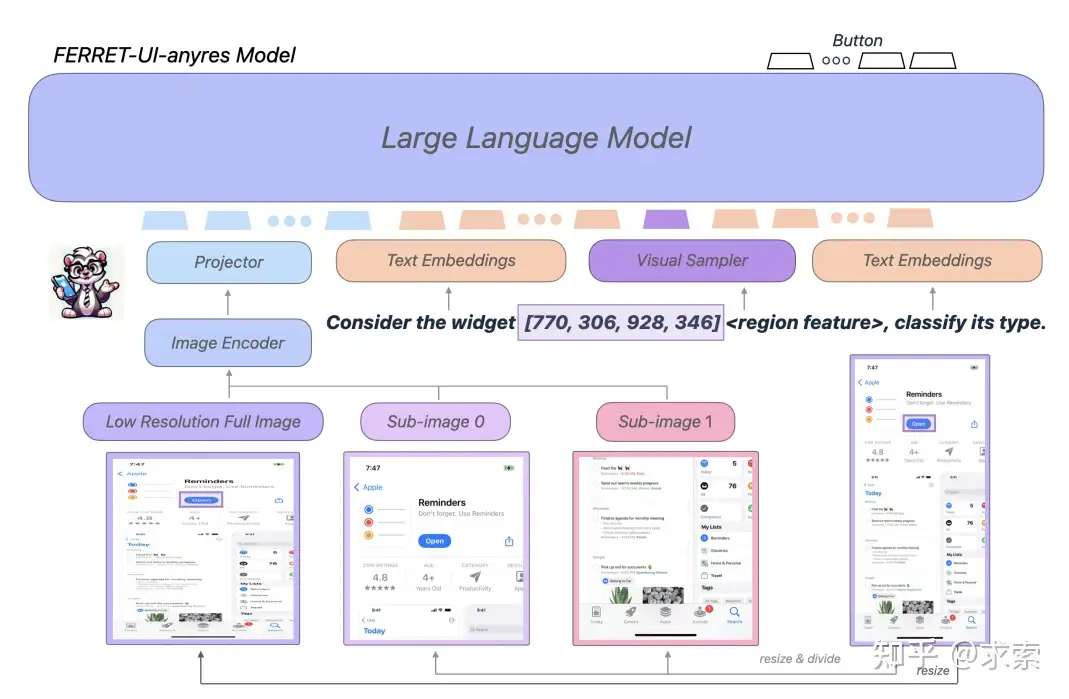
為了解決這個問題,將 SPHINX、LLaVA-NeXT和 Monkey中提倡的“任何分辨率”(anyres)的概念應用於 FerretUI。具體來説,選擇了兩種網格配置,1x2 和 2x1,它們是根據Table 1a 中描述的原始屏幕的縱橫比選擇的。給定一個屏幕,選擇最接近其原始縱橫比的網格配置。隨後,屏幕大小調整以適合選定的網格配置,然後被劃分為子圖像。直觀地説,縱向屏幕是水平劃分的,而橫向屏幕是垂直劃分的。所有子圖像都使用相同的圖像編碼器單獨編碼,並且 LLM 使用所有不同粒度的視覺特徵以及完整的圖像上下文和增強的細節。
Ferret-UI-anyres(“任意分辨率”)架構
雖然 Ferret-UI-base是基於Ferret 的架構,但 Ferret-UI-anyres 包含額外的細粒度圖像功能。特別是,預訓練的圖像編碼器和投影層為整個屏幕生成圖像特徵。對於基於原始圖像長寬比獲得的每個子圖像,都會生成額外的圖像特徵。對於具有區域參考的文本,視覺採樣器會生成相應的區域連續要素。LLM 使用全圖像表示、子圖像表示、區域特徵和文本嵌入來生成響應。
數據集
UI 屏幕集
為了構建一個能夠感知移動屏幕並與之交互的模型,收集各種此類屏幕的集合至關重要。這項研究檢查了 iPhone 和 Android 設備的屏幕。對於 Android 屏幕,使用 RICO 數據集的子集 。具體來説,考慮了 Spotlight中的任務,其數據是公開的,包括 screen2words、widgetcaptions 和 taperception。總共有 26,527 張訓練圖像和 3,080 張測試圖像。
對於iPhone屏幕,使用AMP數據集,該數據集涵蓋了廣泛的應用。隨機選擇一個子集,並將其劃分為訓練和測試拆分。iPhone 屏幕有各種尺寸,總共有 84,685 張訓練圖像和 9,410 張測試圖像。圖像尺寸的細分總結在Table 1a中。
對於iPhone屏幕,我們使用AMP數據集[58],該數據集涵蓋了廣泛的應用。隨機選擇一個子集,並將其劃分為訓練和測試拆分。iPhone 屏幕有各種尺寸,總共有 84,685 張訓練圖像和 9,410 張測試圖像。圖像尺寸的細分總結在表1a中。
UI 屏幕元素註釋
在收集了Android和iPhone的屏幕後,作者使用基於預訓練的基於像素的UI檢測模型進一步從屏幕中收集細粒度的元素註釋。對於每個檢測到的 UI 元素,輸出包括 UI 類型(按鈕、文本、圖標、圖片等)、相應的邊界框以及由 Apple Vision Framework 標識的文本(如果有)。進一步使用屏幕識別的啓發式方法將單個檢測分組為更大的單元,例如,將多行文本合併為一組,將圖像與其標題分組等。
任務制定
本節介紹如何將 UI 屏幕以及相關的檢測數據轉換為可用於訓練 MLLM 的格式。詳細闡述了為構建數據集而設計的三種不同方法。
重新格式化Spotlight
首先從現有的 Spotlight 任務 中獲取 screen2words、widgetcaptions 和 taperception,並將它們格式化為對話式 QA 對。具體來説,GPT-3.5 Turbo 用於根據我們為各自任務編寫的基本提示創建一組不同的提示:
– Screen2words:提供此屏幕截圖的摘要;
– widgetcaptions :對於交互式元素 [bbox],提供最能描述其功能的短語;
– Taperception:預測 UI 元素 [bbox] 是否可點擊。對於每個訓練示例,我們對相應任務的提示進行採樣,並將其與原始源圖像和真實答案配對。
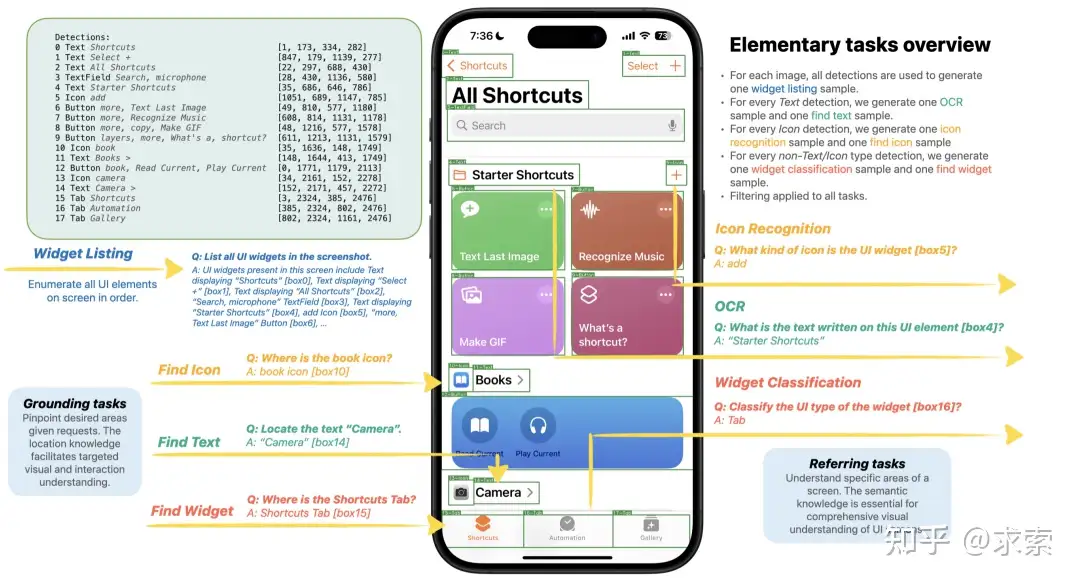
基本任務
UI 檢測器輸出所有檢測到的元素,以及每個元素的類型、文本和邊界框。這些檢測用於為基本任務創建訓練樣本。對於定位任務,使用所有元素檢測來創建一個用於小部件列表的樣本,而其餘任務一次專注於一個元素。將元素分為圖標、文本和非圖標/文本小部件。對於每種類型,創建一個指代樣本和一個定位樣本。
複雜任務
首先從檢測輸出中歸一化邊界框座標,然後將檢測、提示和可選的單次示例發送到 GPT-4。對於詳細的描述和函數推理,將生成的響應與預先選擇的提示配對,以訓練 Ferret-UI。對於對話任務,直接將 GPT-4 輸出轉換為多回合對話。
結果
在簡單任務完勝GPT-4V,如下圖所示:
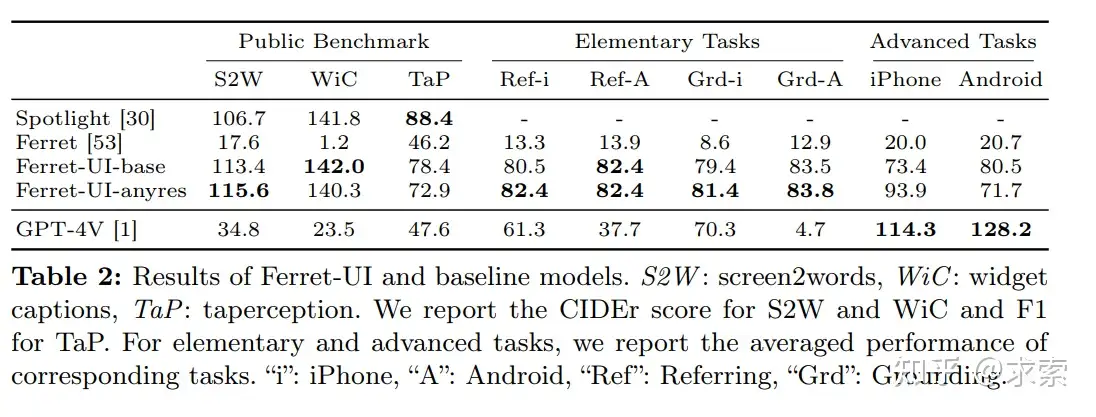
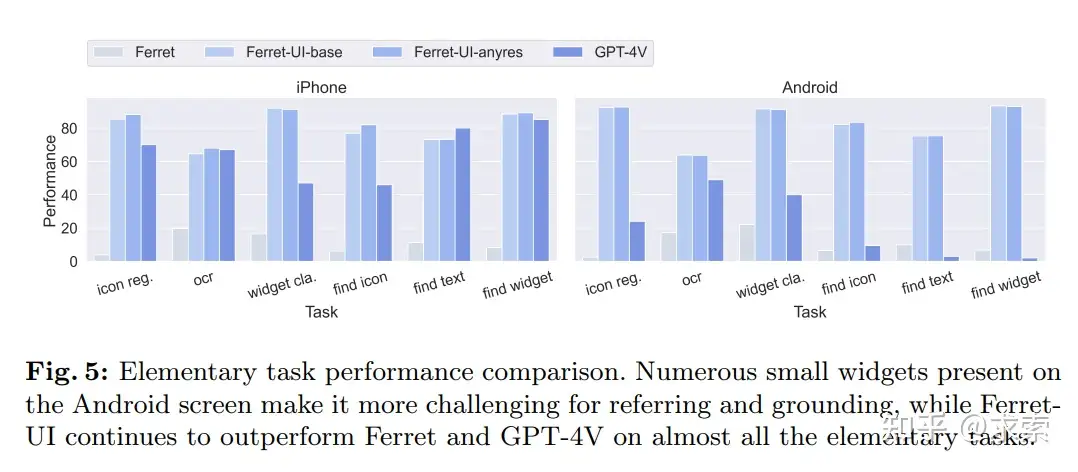
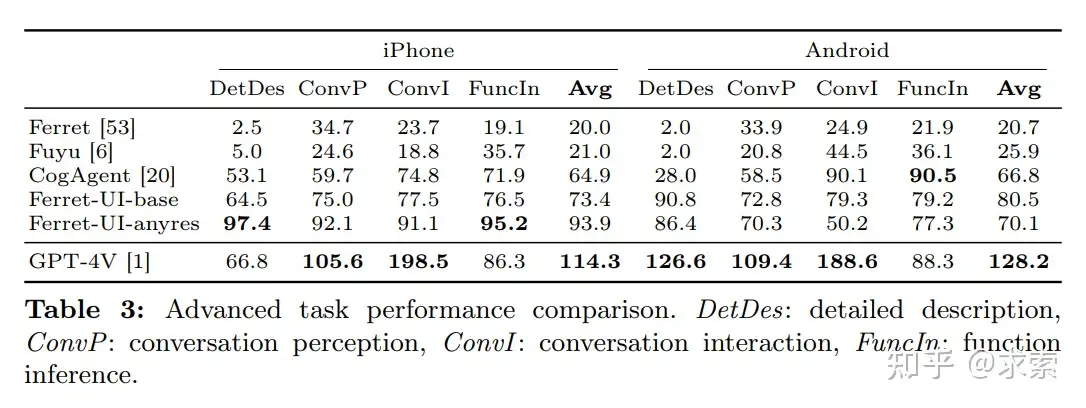
複雜任務上還是不如GPT-4V,如下圖所示:
 結論
結論
在本論文中,作者介紹了 Ferret-UI,這是一種專門的 MLLM,旨在增強對移動 UI 屏幕的理解和交互。通過精心設計“任意分辨率”以適應各種屏幕縱橫比,並策劃包含各種基本和高級 UI 任務的訓練樣本,FerretUI 在指代、定位和推理方面表現出非凡的熟練程度。這些增強功能的出現有望為眾多下游 UI 應用程序帶來實質性的進步,從而擴大 Ferret-UI 在該領域提供的潛在優勢。
來源:求索