新算法讓智能駕駛“看”得更清楚_風聞
中科院之声-中国科学院官方账号-54分钟前
近日,中國科學院上海微系統與信息技術研究所的研究人員在智能駕駛感知領域取得進展,針對智能駕駛感知的兩個關鍵問題——柵格佔據預測和全景分割取得突破。該成果被機器人領域國際學術會議2024 IEEE ICRA錄用。
01
感知能力 自動駕駛的基礎
作為定義汽車智能網聯進程的核心維度,自動駕駛技術已然成為衡量智能與否的關鍵指標。汽車的自動駕駛核心系統包括感知系統、決策系統與執行系統。感知系統好像人類駕駛員的眼睛與耳朵,通過各種傳感器對路況信息進行捕獲,是自動駕駛的重要基礎與先決條件。
目前,自動駕駛感知技術大致存在兩種模式:一種是以攝像頭為主要傳感器,搭配毫米波雷達等低成本傳感器,以圖像識別模式為核心流程的模式;另一種模式則是以高成本的激光雷達為核心元件,利用激光雷達獲取更遠探測距離、更優角度分辨率,且受環境光影響更小。前者雖然成本較低,但對算法和芯片的依賴程度較高,目前的算法和模型讓其相較於後者,在可靠性和精確性上處於劣勢。
對此,科研人員針對低成本模式的攝像頭為主傳感器後台算法,進行了升級創新,在算法涉及的柵格佔據預測和全景分割這兩個關鍵問題上取得突破,提高環境感知力,優化駕駛場景精度,提升安全保障。

▲圖片來自網絡
02
克服障礙物視角遮擋
柵格佔據率預測算法,通常被用來了解和分析車輛周圍環境信息。它會將車體周邊環境分割成許多小的方格,即柵格,並解讀每個柵格中的信息供自動駕駛後台參考。但是由於對某些場景的還原不夠細緻,對於各類車輛和障礙物幾何信息的理解也不夠透徹,當開放場景中對象的形狀或外觀不明確時,往往會出現錯誤估計障礙物的情況。因此,科研人員提出一種以自車為中心的環視視角的佔據預測表徵方法——CVFormer。
CVFormer採用“環視視圖交叉注意力模塊”技術,利用汽車周圍的環視多視圖來建立多個二維視角的表徵,從而有效地描述周圍的三維場景。它採用的“時序多重注意力模塊”可以加強幀間關係的利用,提高預測的精度和效率。而且,科研人員還在CVFormer中引入二維與三維類別一致性約束,讓預測結果更加符合實際場景。
通過以上技術,CVFormer能夠克服車輛周圍障礙物可能引起的視角遮擋問題,為自動駕駛車輛提供了更加精準和可靠的環境感知能力。
▲CVFormer在自動駕駛常用數據集nuScenes上三維佔據率預測任務可視化效果圖
03
提升全景分割精度
由於以攝像頭為主要傳感器的自動駕駛方案不涉及3D激光點雲數據處理,因此全景分割便成為一項至關重要的核心技術,主要用於行車路線和街道的識別與理解。
全景分割是融合語義分割與實例分割的綜合方法。語義分割關注將圖像中的區域分割為不同的類別;實例分割則側重對每個實例對象進行獨立的分割。全景分割將兩者融合,但在實際操作中,二者預測結果會出現矛盾,導致後台誤判。
為解決這一問題,科研人員設計了基於門控編碼和邊緣約束的端到端全景分割模型BEE-Net。模型通過語義—實例—全景三重邊緣優化算法,對邊緣分割質量進行針對性優化,保持高效的同時,顯著提升了場景分割性能。
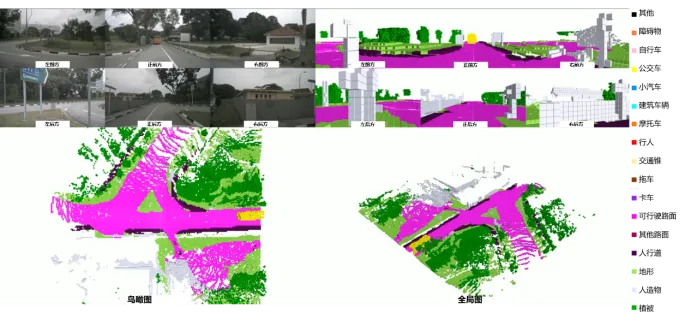
BEE-Net在駕駛場景分割權威數據集CityScapes上進行了驗證,獲得了65.0%的PQ精度指標。在精度方面,它超越了目前基於CNN的全景分割模型的最高精度63.3%。同時,在效率上,它優於所有基於Transformer的全景分割模型,兼顧了分割精度與效率的性能需求,在某下一代量產車型智能駕駛感知系統上完成了測試驗證。

▲BEE-Net在CityScapes數據集上的分割結果
總的來説,BEE-Net不僅有助於緩解語義-實例預測混淆問題,還能提升分割質量,特別是在邊緣處。這不僅提高了全景分割的準確性,也進一步增強了自動駕駛算法對環境的感知能力,使其更加精準可靠。