對話MiniMax閆俊傑:現在的AI應用不會成為Super App,但這不重要_風聞
极客公园-极客公园官方账号-37分钟前

以語音助手切入的多模態,是提高用户滲透率的一種嘗試。
對話 | 張鵬
文 | 黎詩韻****編輯| 靖宇****
和多數人一樣,在看到 OpenAI 最新發布的「AI 智能助手」GPT-4o 時,MiniMax 創始人兼 CEO 閆俊傑的第一感覺是「驚豔」。他也為那些演示效果着迷,如絲滑的語音交互、實時的視覺理解、語言捕捉甚至包括了「呼吸聲」。
作為中國第一梯隊的大模型創業者、OpenAI 的最重要追趕者之一,他迅速看穿了這場「魔術」背後的手法。在發佈會結束兩天後,這位以神秘、低調著稱的從業者,罕見地做客極客公園直播間,和極客公園創始人、總裁張鵬進行了近 2 小時的實時訪談。
從這場發佈會切入,他聊到了技術和成本、行業賽點、開源與閉源之爭、投流和 PMF、超級產品等關鍵問題。
在他看來,這次 OpenAI 展現的技術難度並不高(比如語音模型處理速率更低、容易對齊到語言模型,實現絲滑語音交互)。使他感慨的是,這位對手在行業最重要的使命上邁出了重要一步——那就是讓AI為更多普通人所用。
他説,GPT-4o 本質是多模態(文本、語音、視覺)的進步。而他很早就意識到,大模型在多模態的每一次進步,都會帶來用户體驗的提升、獲得更高的用户滲透率。比如,當 GPT-4o 擁有更絲滑的語音交互(延時縮短、增加情感等)後,它就會走向更多人。
這也是他於 2021 年底創立 MiniMax 的初衷。彼時。ChatGPT 還沒有出現、業內也沒有人相信大模型。促使他一定要創業的動力是,「把人工智能做成通用、服務大眾這件事是很重要的。」
在這個目標驅使下,MiniMax 是行業少有的同時做模型、產品的公司。目前,MiniMax 是國內 AI 產品做得最出色的公司之一。其產品主要分為兩類:一是「星野」代表的娛樂類,對標 Character.AI,目前處於國內領先位置;一是「海螺 AI」代表的效率類,對標ChatGPT,尚在起步階段、但是他目前最看重的產品。
GPT-4o 的發佈,讓他更明確了「海螺 AI」接下來的研發方向。他説,下半年的目標是,要把過去彼此獨立的多模態大模型融合在一起。並且他認為,這會是未來行業的「必答題」,效率類產品必須跟上。不過他認為,從長遠看效率類產品的本質方向,仍然是要提升底座語言大模型的上限。因為其最重要的指標是用户對回答的滿意度,而現在連 ChatGPT 的回答滿意度都只有 60%。
儘管 AI 在過去一年多引起了全球廣泛關注,但它距離為普通人所用的未來還很遙遠。**閆俊傑做了一個演算,目前國內最好的效率類產品DAU只有 400 萬、國外是 1000 萬,這意味着 AI 在移動端的滲透率可能不到 1%。**從業者們要做的努力還有很多。
用户滿意度和滲透率、以及背後需要的技術進步,似乎一直是他思考的「第一性原理」。而當我們談到成本、商業化、行業競爭等等關鍵問題,他的答案都圍繞這點展開。比如他説,「投流是因為技術沒有拉開足夠差距」、「搞不懂 PMF,其實有了用户時長就會有商業價值」、「如果創業者沒有做出足夠創新,這件事就該大廠幹」……在這場對話裏,我們能看到這位技術向 CEO 難得的「簡單」、少見的「坦誠」。
那麼,最終我們何時能迎來大模型時代的 Super App、真正讓 AI 普及大眾?他説,也許目前的產品都看不到這個可能,但這並不是一個重要的問題。原因在於,AGI 的路很長,很多事情無法現在就看清,沒有必要給自己這麼大的壓力。還是那個回答,做好技術和產品,有能力跟上一代代的創新,最終才有機會看到那一天的到來。
以下是這次直播對話的實錄,經極客公園整理後發佈:
01
談語音助理:效果驚豔、能提升用户滲透率,且在技術上並不難實現
張鵬:你應該也是非常詳細關注了 GPT-4o 和谷歌I/O的這兩個發佈會,它們的風格其實挺迥異的,你個人對哪個印象更深?更喜歡哪個?可以分享一下原因和理由。
**閆俊傑:**一方面,我自己其實是一個用户,會每天使用這些 AI 產品。另一方面,我自己又是從業者,所以有很奇怪的兩種不同感受。
看 GPT-4o 的發佈會的時候,作為用户來説,我覺得非常驚豔。特別是那兩個演示,一個是(AI 聽懂了)呼吸聲,一個是拍照做一些事。我當時覺得為什麼人工智能可以變得這麼流暢,大家都覺得實時的語音交互是第一次有人實現。這個事確實很成功的,非常顯然 GPT 發佈會的風口和傳播量是大於谷歌的。用户肯定覺得 OpenAI 的發佈會更震撼。
不過發佈會那天晚上,我就開始想這個東西到底怎麼實現的。**大概想了半個小時之後,就覺得實際上是很直接的事。**為什麼?原因是,説話是比打字要慢很多的。比如説現在正常的語言模型,基本上每秒可以處理的 token 是十幾個到二十幾個量級。但是説話其實每秒只能説 3-5 個字,大概只有 4-5 個 token。所以語音的速度是遠遠慢於現在標準的語言模型的處理速度的。
這個意思就是説,只要把語音的模態——就像之前做圖片跟文本一樣,只要把它對齊到語言模型上,把它改造成一個成純流式的交互,這件事改造起來非常自然。
所以我覺得這件事體現出來兩個事:第一,OpenAI 還是能夠從非常底層思考這個事。第二,這個事的技術難度其實遠小於 Sora 或者一開始 GPT-4 的技術難度,這就是我看 OpenAI 發佈會的感受。
張鵬:那看了谷歌的發佈會你有什麼感覺?
**閆俊傑:**谷歌的發佈會不是看的直播,而是第二天看了完整的兩個小時視頻。它最前面是 DeepMind 負責人講了很多技術的部分,這部分就很像是一箇中年男人拖家帶口來搞科研,一定既要滿足股東、又要滿足用户、又要滿足市場對谷歌的期待。
張鵬:還得不能讓社會質疑你有 ethic(倫理)的問題。
**閆俊傑:**對,相當於畫了很多目標,幾千人的研發團隊大概做了一年,做出來了很多東西。每一點應該都不是最好的,但是能同時做這麼多東西,從芯片到產品都做,可能也只有谷歌有這麼多的研發力量能做。
但是我比較震撼的是它的 AI 搜索。AI 搜索在過去幾個月很火,海外有 Perplexity,包括 ChatGPT 在內,以及國內很多助手,大家都會做搜索,甚至聲稱替代了傳統的搜索。坦白説,我覺得目前這些產品的搜索和谷歌展示的那一套 AI 搜索,還是有非常大的差距。
因為我覺得裏面非常核心的東西,可能只有谷歌才有。比如很多實時的本地的信息,這些信息對一些高價值的場景其實有非常大的價值。如果我是用户的話,我其實非常願意用這樣的搜索,這種體驗絕對不會是在 ChatGPT 裏外接第三方的搜索引擎就可以實現的。坦白説,我覺得這是谷歌真正的壁壘。
其次,目前大家用的其他的 AI 搜索產品裏面,只有單步的推理,谷歌展示了多步推理,這對搜索體驗的提升還是非常大的。這個事谷歌也是第一個做的。它本身不難,原來的語言模型能夠支持就好了,但是説明谷歌已經想得非常深刻了。
最後,可能是谷歌獨有的優勢。實際上包括 OpenAI 在內,幾乎所有公司的視頻理解都做得比較一般。甚至 GPT-4o 裏面展示的東西,它的 Camera 其實處理的也不是 video,而是靜止的圖像。**真正能夠做到非常流暢的視頻理解,效果比較好的,好像只有谷歌。**Gemini1.5 做的相當不錯了。
我在想為什麼這件事這麼重要呢?為什麼谷歌非得做這件事呢?其實也可以理解,原因是谷歌有大量 YouTube 的視頻,但是這些視頻無法被展示出來。因為之前的搜索只能有一個標題,或者非常簡單的標籤。現在這個技術,就可以把這些視頻加到搜索的結果裏面去了,這是非常獨特的一件事。
總體來説,我比較受震撼的是有了 AI 之後,真的可以把搜索這件事有質的提升,並且這件事谷歌已經走得非常靠前了。
張鵬:感覺我們大部分都是觀眾,看完發佈會的「魔術」都「哇」一下,但你是「魔術師工會」的,你看完了會琢磨一下這個「魔術」怎麼實現的。比如語音這件事看起來很厲害,但沒有想象中那麼難實現。所以有人評價説,OpenAI這次主要是工程上的進展,它選擇了一個明確的目標、甚至可能針對發佈會的場景做了很好的想象,然後它的工程能力配合技術能力、完美的把這個點打爆了。而不像上次 Sora 那樣是技術的本質變化。這麼理解對嗎?
**閆俊傑:**可能不同的人對系統、算法、工程的理解都非常不一樣,我説一下技術上的理解。
雖然我也不知道 OpenAI 具體是怎麼做的,但我猜 OpenAI 的語音技術可以分成兩步:第一,用大模型做語音的合成。第二,把大模型的語音合成和語言模型合在一起。第一步其實去年有了非常多進展,但問題是在做交互的時候,要先把聲音變成文字、再用語言模型生成回覆、再用這個模型來跑一遍。
張鵬:當時不是端到端的實現,而是要分幾步**。**
**閆俊傑:**對,這個會造成延時和信息丟失。這次 OpenAI 就更進一步,直接把語音模型和語言模型合在一起了。
這在技術上是比較容易做的,因為聲音和語言模型都是 Transformer 的模型,本質上就是把聲音模型的 incoder(編碼器),對齊到一個語言模型上去。這個事在圖片裏面已經發生了,現在只是把圖片換成了聲音。而且因為聲音的處理速度遠低於文字處理的速度,所以改造成流式是非常自然的。
這帶來的結果是,原來 ChatGPT 的語音交互、包括海螺 AI 的語音交互,大概延時會有兩秒。現在純流式了,延時只有 300 毫秒,就是説一個字的時間。
張鵬:所以這種語音技術路線其實並不難、而且很早就被證明是可行和明確的,這是否意味着它不會是OpenAI的獨門技術,而是可以迅速擴散到更多的公司?
**閆俊傑:**我覺得如果一個公司或者組織,它之前能獨立做好語言模型、並且能獨立地做好利用這種 LLM 方式做聲音的模型,如果這兩個都具備了,把它合在一起是相對比較輕鬆的。不過這背後還涉及到很多工程鏈路上的優化。
但比較核心的還是你的目標是什麼。比如 OpenAI 為什麼要把語音延時降到 300 毫秒,**本質上是因為在移動端,每當你降低延時、對用户體驗就會帶來特別大的提升。**為什麼線上會議沒法替代線下見面,核心就是它有幾秒的延遲。而延時優化的極限就是一個字的時間,300 毫秒,你在這個目標下最後就會推出來最合理的技術路線。
張鵬:延時的問題我很有感觸,之前有聲音賽道的創業者跟我説,如果延時超過一秒,用户就會發現對方跟自己不在一個地方聊。所以語音助理沒有延時之後,你感覺它從雲端,走到了你房間裏,這個感覺給人的衝擊感是非常強的。它對用户體驗的提升有多強?語音是否會成為主流的交互方式?
**閆俊傑:**過去一年非常明顯的變化是在車裏面,你可以看到新能源車裏的語音滲透率是顯著變高的,這説明在一個場景裏,如果你能夠把語言的交互做得非常好用、且有實際價值,它的用户滲透率就會變高,至少在智能車艙裏面已經實現了。這個事在現實生活中也會是一樣,這也是為什麼 AI 公司會越來越重視聲音交互的原因。
過去一年大模型雖然是非常熱的詞,但現在全球每天使用 AI 產品的人只有四千多萬,而這四千多萬裏有三千多萬在用 ChatGPT,而這三千多萬有兩千萬是用 Web、一千多萬是用手機。而現在全球每天使用手機的人可能有 4 億人,**所以 AI 在移動端的滲透率可能不到 1%,這是非常低的數字。**真正主流的產品,比如説短視頻、或者長視頻、或者社交,它的滲透率應該都是 50% 以上。
我覺得未來有志於做 AI 產品的公司,一定要思考一個邏輯,那就是怎麼讓用户滲透率變高。其實唯一的方式就是讓更多的場景可用、讓更多的人可用。我覺得聲音應該是符合這個趨勢的,它可以讓一些不方便打字的人進來、並拉來更多場景。這是 AI 公司提高滲透率的一種努力。

在 OpenAI 發佈會上,研發人員與 GPT-4o 對話 | 圖片來源:OpenAI
張鵬:你覺得它是會增加存量用户的黏性、還是獲取更多增量用户?
**閆俊傑:**這兩個事都可能會發生。我們發現很多場景確實只有語音才會發生,舉個例子,比如説在海螺 AI 裏面,很多家長會讓它給小孩講睡前故事。這顯然擴充了使用人羣。
再比如,我們發現有很多用户會用它來學英語口語。從這個維度上來説,它應該是提升了用户的活躍。還有我自己親身的例子,我今天春節回到老家看我外公,他已經 80 歲了。他在很破的安卓手機上裝了海螺 AI,會跟它打很久電話、討論歷史人物。之前你很難想象一個 80 歲的老人會這樣用 AI。
而他們在用這個產品的時候會真的把 AI 當成一個人,比如他會説你(AI)聲音能不能大一點,其實潛意識裏把它當成人了。
這也是我們為什麼那麼相信通用智能的原因,它就是服務普遍人的東西。問題是整個行業的滲透率確實沒那麼高,更簡單的交互是很重要的一方面。
張鵬:你説過自己很早就堅信多模態,是因為產品每擴展一次模態、都能擴展一批新的用户。你預測ChatGPT改善語音技術之後,它的DAU、用户時長這些數據會有什麼變化?
**閆俊傑:**實際上現在沒法猜,因為它還沒有上線。我覺得使用時長會變長,但是用户滲透率會不會有顯著的變化,我其實比較懷疑。
張鵬:語音交互確實對人有門檻的,很多上一代做語音交互的朋友們覆盤過,大家打開一個語音助理之後會突然不知道説什麼,然後就停了,這件事跟技術其實沒有關係。它其實需要用户有比較強烈的目標和意願去用。
**閆俊傑:**對,我覺得對年輕或者比較年長的用户會更友好,對中間的用户反而不會。原因是因為,願意使用 AI 的人、或者聽過 AI 的人,大概率至少試用過一些東西了。
02
談行業賽點:多模態融合是大模型行業「必答題」,決定效率類產品的成敗
張鵬:你自己也在大模型領域創業,各項技術能力都在主動跟OpenAI、谷歌做對標。看完這兩場發佈會之後,你感到的更多是一種興奮,還是一種挑戰?
**閆俊傑:**我覺得有人跑在你前面是好事,這説明這個行業上限遠遠沒有到。
我個人是非常期待 OpenAI 會出 GPT-5 或者其他的東西,即使作為一個業內人士,我也是希望 OpenAI 進步速度能保持這麼快。反正也沒有競爭,實際上沒有任何的競爭。但是這不是因為不想跟他們競爭,是他們太強了,構不成競爭。
至少目前,真正把算法匯成產品,真正開拓 AI 行業邊界的,主要還是 OpenAI,如果他們能夠非常快地開拓 AI 的邊界,至少説明 AI 的用户滲透率是有底層動力的,而且這個動力可持續的。
OpenAI 可能比中國公司多 10 倍的研發資源,如果他們都做不出來創新,這才是這個行業比較可怕的一件事。
張鵬:你有方法、有路徑,有計劃,未來可以在你們的產品裏見到跟OpenAI今天類似的用户體驗嗎?大概多長時間可見?
**閆俊傑:**首先我覺得這個事肯定可見的,雖然他們怎麼做的我不知道,但是我覺得我剛才的分析應該是對的,至少那種方法可以實現,至少它是有一條比較明確的路徑。
**其實對我來説,主要的挑戰不是語音模型,主要還是把語言模型做得儘可能好。**真正的原因是因為,現在的多模態實際上還是以語言模型作為核心的。今年我們在做上一版 ABAB6.5 的時候,我們其實把萬億量級的 MoE 這件事做通了,這還是個語言模型。
另外,我們在去年的時候,每個模態都是獨立的,雖然它們有同樣一套框架、裏面都是 Transformer,代碼也是差不多的,但是它的數據和模型是獨立的。現在我在設計下一版的模型,我們下半年的核心考慮是如何能夠能有一個上限更高的語言模型,以及把這些不同的模態合在一起。
我們還沒有完全設計完,還有很多的實驗需要做。但是它基本上已經是可見的東西了。接下來這個模型會分成兩個階段:第一,設計階段,有很多假設,你要做很多實驗驗證你的假設。第二,假定,你認為你的假設驗證得差不多了,把這些東西合在一起,最後訓練這個模型。
這裏面的 trade off(權衡)是説,你的這些假設,或者你設計的這些預測實驗,到底要做到多好?這是我們正在經歷的一個事。
MiniMax 旗下的效率類產品「海螺 AI」|圖片來源:MiniMax
張鵬:最近聽到谷歌提的比較多的是One network Moti-modelity,多模態是在一個神經網絡裏實現的。現在MoE 在訓練萬億大參數的模型上是非常有效的方法,但下一步如果做多模態融合,方法上會跟以前有什麼不一樣嗎?
**閆俊傑:**這個是兩個維度,第一個是中間這步都是一堆巨大的 transformer,為了提升效率,不管訓練效率還是推理效率,大家主流的選擇都是一套 MoE,比如 GPT-4。據傳 Gemini-1.5 也是長這個樣子。如果你做一個大概幾千億參數的模型,基本上這就是必然的選擇。
第二個,你有不同的模態,怎麼樣能夠合到這個大的以 MoE 為基礎的主幹模型上,這就是多模態。現在已知的東西是,怎麼把視覺的理解跟主幹模型合在一起,比如説像 GPT-4v,你先有一個巨大的 MoE,再把視覺的東西對齊,就可以有比較好的視覺的理解。
未知的東西有這麼兩個:
第一,GPT-4o 裏面展示的,把聲音也對齊到裏面去,這是 GPT-4o 乾的其中一件事。
第二,生成的這部分,比如説圖片的生成、視頻的生成能不能合進來。至少現在,視頻是沒有實現的,比如説 Sora 是獨立的模型。為什麼會這樣?原因是視頻的 tokenizer(標記)是有損的壓縮,基本上要通過 diffusion(擴散)才能恢復到一個比較正常的狀態,現在還沒法整。當然會有很多人做,可能明年才會整合一起。但是視頻的生成目前還不知道怎麼整合的。
圖片的生成我不知道,比如説在上一代 DALL-E 3 的時候,其實也沒有整合在一起的,也是獨立的模型。但是這次看 GPT-4o 的話,我感覺它們似乎整合在一起了,但是我不是特別確定。我覺得基本上底層的技術就是這樣了。
張鵬:那麼緊接着多模態統一融合的能力,會不會成為下一個階段大模型領域、尤其是中國的創業公司們要去提升的目標?這是不是所有人都必須要跟上、必須要解決的問題?
**閆俊傑:**我更覺得是必須要做的事。其實這分兩個產品,**目前AI產品有兩種,一種是滿足娛樂需求的,一種是滿足效率的。**娛樂的不説了,是運營的屬性、產品的屬性,更加偏綜合產品能力的事。
偏效率的一定是需要做(多模態)的,因為從歷史上來看,所有效率的產品基本上最終大家只會用最好的。比如説有兩個產品,一個可以做很多東西,一個只能搜文字,那大家一定會用那個啥都能做的那個產品。當然這個前提是説,這個(多模態)賽道是存在的。關於這個賽道是不是存在,其實也是需要很多努力的。
張鵬:可不可以理解為 Sora 是「選答題」、可以不選,但是多模態的統一融合是「必答題」、如果答不好就會出局?
**閆俊傑:**我覺得你這個概述還是挺好的,之前沒想到這樣,確實更像是一個必答題。
Sora 這個東西其實有不同的用法,比如説有 PGC 的用法、作為工具屬性的用法,也有 UGC 的用法、會涉及很多產品、內容的東西,不是 AI 都要做的東西。
但是在工具類、效率類、助手類的產品上,只要有公司做出來(多模態),其他公司必須跟上。因為基本上就這麼點技術。
03
**談生態:****「智能語音助理」爭奪戰,**巨頭和創業公司是複雜的競合關係
張鵬:這次我們看到語音助理這個事,蘋果想用到 Siri 裏、谷歌想非常深層地用到安卓體系裏,似乎它會是個很重要的入口級的東西,這個事最終會是巨頭的 Game 嗎?創業者還能幹嗎?
**閆俊傑:**首先,這個產品的所有用户體驗幾乎都來自於模型的能力。它不太取決於產品是巨頭的產品、還是創業公司的產品,只是取決於背後是什麼樣的技術水平。它考驗的是你能不能做出一個體驗最好的模型。這裏面涉及到你的技術模型怎麼做、怎麼做很好的對齊、怎麼優化你的延時,怎麼提高工程的效率、怎麼降低計算成本等等。
其次,在商業層面,這個產品背後肯定要消耗成本。**因為現在的AI產品跟早期移動互聯網產品的本質區別是,以前我們不需要考慮每天維護用户的成本,現在我們都要考慮。**所以這一代產品怎麼變現是比較直接的。而手機上產品的商業價值有多大,幾乎取決於它有多長的用户時間,因為用户時長總是有標準化的變現手段。
這樣的產品,假設它能做到大部分的需求都在裏面解決,比如説當我想要搜索的時候,我不需打開百度了。或者我需要看一個視頻的時候,不需要在抖音裏看了。只要它佔有用户足夠長的時間,那它的商業化效率就是足夠高的,它的商業化跟時長是成正比的。
這個事最終會變成,產品的競爭力取決於技術能力,商業競爭力取決於你佔有多少用户市場。
張鵬:我再具象一點,蘋果屬於完整的從硬件到軟件的掌控者、安卓在操作系統上有天然的優勢、OpenAI是新型的基於大模型能力的創業公司,如果未來這三家公司都在搶佔語音助手這個最關鍵的入口,誰更有可能是贏家?創業公司能贏得這個位置嗎?
**閆俊傑:**我覺得這裏面有各種各樣的博弈、競合關係,在搜索裏已經發生了。我們能看到蘋果裏集成了谷歌的搜索,谷歌每年給蘋果很多錢,為什麼谷歌願意付錢?顯然因為谷歌在蘋果裏做搜索的商業價值,要大於谷歌自己付的錢了。
但是我覺得不管怎麼樣,如果看第一性原理的話,那在這裏面如果誰能把東西做出來、並且把體驗做得顯著地好,那至少在裏面你應該會有一席之地。
這件事我覺得更利好於擁有設備的公司,為什麼?比如説我買一個小米的手機,只要給小米付一次錢,之後這個小米手機創造多大的價值,其實都跟小米沒有關係了。唯一有關係的是,小米商店裏面的分發裏面會有分成,其他的基本上沒有關係了。
張鵬:也有一些負一屏的內容廣告,都是比較薄了。
**閆俊傑:**負一屏的內容水平顯然是沒有抖音或者小紅書高。其實手機提供了很多用户時間,比如説我在小米上裝了一個抖音,一個用户在抖音上花了很多時間,但所有的錢跟小米一點關係沒有,都被抖音轉走了。
我覺得一個比較強的 AI 助手的好處是説,它確實能夠讓手機的操作系統這層佔領很多用户的時間,因為可以滿足很多多樣化的需求。這個事相當於是説它其實是把很多價值從 APP 里拉到手機上。
張鵬:最近我們也看到傳聞,蘋果跟OpenAI有可能在智能助手這個層面產生合作。所以按照你的推理,一家在大模型裏做的非常優秀的公司,和一個對生態硬件、軟件有掌控力的手機巨頭,最終大家合在一起、在未來的生態裏產生新的價值分配,這是符合邏輯的?
**閆俊傑:**對,實際上就是用户時間的分配,而這又考驗背後的技術和產品能力。
張鵬:反過來説,如果 OpenAI 沒有跟蘋果合作,而是成為最強的 Super APP,作為獨立的力量去挑戰現有的生態、甚至對原有價值鏈進行重構,你認為存在這種可能性嗎?
**閆俊傑:**這主要看它的規模。現在 1000 萬 DAU 的 APP 顯然不夠格。到 Mata 這種 10 億 DAU 量級的,估計會有本質的變化。但即使是OpenAI,距離這個也有 100 倍的距離。
張鵬:現在想着做所謂大一統的 Super App、超級入口還是很難實現的,今天更現實的是怎麼把DAU從一千萬漲到 1 億,這也是 OpenAI 很頭疼的事。
**閆俊傑:**我猜這也是它們為什麼這麼在意語音的原因,因為這個東西確實有可能會提高滲透率。
04
談技術路線:投入通用基礎大模型、打造通用產品,能看到真正的未來
張鵬:前段時間在整個創業者的圈子裏,大家圍繞基礎模型和開源模型爭論很大。本質上是説,你要麼自己做一個智能引擎,要麼就買一個自己改。其實模型、產品雙輪驅動,自己同時做基礎模型和產品,滾動着往前走是最好的。但很多創業者説這風險很大,模型的一次迭代跟不上、或者產品 PMF 的一次失敗,就不行了。你怎麼看這兩種路線?
**閆俊傑:**我覺得這本身是風險很大的事。先不説同時做模型和產品,只做模型、或者只做產品,本身就是風險很大的事。
張鵬:創業其實就是生死遊戲。
**閆俊傑:**對,確實是很殘酷的事。比如我們看美國的公司,OpenAI 是都做,Aanthropic 之前只做模型、昨天他們把 Instagram 的 CTO 也招過去了,我不知道是不是它們也有可能做產品。**我覺得至少對做模型的公司來説,自己做產品幾乎是必然的選擇。**我們算是比較堅決的,有些公司後面變成這樣了,這是必然的。
反過來,其實對做產品的公司也是一樣的。比如説我們國內的開放平台上,有很多做產品的公司和客户,其實規模還挺大的,大概有接近一千家。這裏面有大的公司,也有小的創業公司。其實坦白説,對所有這些公司來説,**如果它們的產品得很大,他們也希望自己掌控模型的。**這也是必然的一個路。
所以這裏面核心的考慮還是説,如果你覺得這件事是對的,本質上是説你現在有多少資源、最大化優化你們想優化的目標。對我們來説,我們的目標是要最大化地優化用户體驗,那我們覺得這兩個東西(模型、產品)都是重要的,只能兩個東西都做,才能最符合我想優化的目標。
不同的人定義的目標不一樣、路徑不一樣,就會出來很多不同的公司。
張鵬:所以產模一體歸根到底是我們追求的最終目標,只是很多人基於今天已有的資源,會發現燒錢太高、風險很大,但這只是階段的選擇問題。
**閆俊傑:**還有一個更底層的原因。舉個例子,假設有個需求要滿足,而這個東西需要通過模型來滿足——那如果是(模型和產品都在)一家公司,你的路徑是優化這個業務指標就可以了。但如果(模型和產品是在)兩家公司,你們乾的事是把這個指標轉成一個對模型的要求,讓給你提供模型的公司優化這個指標。
這中間本身損失了很多信息,並且讓週期變長。這個事一定不是最大化業務指標的方式。
當然這個事上,微軟例外。核心原因是,微軟的這些場景,Bing 的搜索、還有 office,其實都是一些能夠變得非常標準化的東西,基本上主要依賴於模型的通用能力。OpenAI 的通用模型是最好的,那就可以給這些產品用。在這種情況下(模型和產品分開)是合理的,但是大部分情況下不是最優的選擇。
張鵬:你提了一個非常好的問題,就是我們到底是要根據模型能力造產品,還是要根據產品目標去改模型?我打個比方,如果模型是一把槍,產品是靶子,我們今天到底是要造更通用的機關槍、在更多領域命中靶子,還是應該造一把高精度的狙擊槍、就打中某個具體的靶子?
**閆俊傑:**其實這個事背後有一層含義,咱們講這個時間點,AI 背後是有一些技術紅利的。這個紅利是説,全世界有這麼多聰明的人、這麼多資源、這麼多社區在做這件事。這件事的價值或者能力遠大於單個公司,也大於 OpenAI 的,顯然也大於任何一箇中國的創業公司。
所以一家公司的研發水平不是一家公司封閉做出來的,而是這家公司的自身能力加上整個行業整合出來的。只是不同公司利用的效率不一樣。包括 OpenAI 在內,它們很多的東西不是原創的,可能是谷歌做出來的,但是它們把它很好的整合在一起,擴大規模,就變成現在的狀態。
**其實把模型做通用這件事,是一個比較容易來吸收到整個社區進展的途徑。**這件事本身是有巨大的紅利的。
張鵬:今天你應該站在那個位置上,把更多的能力拿出來,讓更多的人跟你共創,也許是用户、也許是產業裏面的其他創業者兄弟們,OpenAI有這樣的感覺。但如果今天你只是做某一個產品、維繫你自己的「菜園子」,你可能失去了世界與你共創的機會。
**閆俊傑:**客觀的説不是世界與我們共創,是我們與世界共創。
張鵬:我看 SamAltman也不斷提醒,大家不要基於今天模型的一些具體問題去打補丁,這其實是浪費時間。因為技術在滾滾向前,你在這個時空剛把補丁打完,這件衣服可能都已經換了,會出現這樣的問題。
**閆俊傑:**客觀上説能夠做什麼產品,其實是由技術的週期決定的。
比如説目前這一代,我們見過的所有產品基本上是以文字的交互為主,產品的功能基本上是助理這個層面的。不管是娛樂還是效率,基本上都是 copilot(輔助助理)這個框架。只是不同的人基於不同的理解、不同的資源、不同的團隊,組成了不一樣的東西。
假設我們有更好的模型,能力比現在再顯著地提升,比如所有的測試都可以做得非常好,它可以獨立來工作了,就不是一個 copilot、可能是一個 auto-pilot(全能助理),這顯然會產生更多完全不一樣的產品形態。
但是這個東西不是產品設計出來的,而是當你把技術 Push 到某一個階段的時候,這個產品自然就清楚了。
05
談成本:技術成本兩年內可能降100 倍,這比****探索技術上限容易多了
張鵬:我想把話題延展到很具象的東西,前些天我跟投資人算了算賬,今天千萬級DAU的產品,恨不得一天花掉 200 萬的成本,很高的。比如今天 GPT-4o 如果容納了更多用户、獲得了更大的用户粘性,它每天的成本得有多高?你肯定掌握一些成本結構的判斷,能不能幫我們算一算?
**閆俊傑:**其實語音比文字便宜的,因為語音慢。比如文字一秒要生成 20 個 token,但語音一秒只有 4-5 個 token。而且人聽的時候也慢,我看一千個字只需要一分鐘,但是我聽一千個字應該是很長的時間。
所以假設使用相同的時間,語音其實更便宜的。
張鵬:這挺反常識的。
**閆俊傑:**你覺得聲音更貴,其實更便宜,這是第一點。
第二,優化或者降低成本一直是學術界非常經典的研究領域,很多年前我自己也在這個領域做了很多工作。但它實際上不是業界最高端的領域,最高端的領域一定是説如何拓展技術的邊界。
一旦你能夠拓展技術邊界之後,怎麼把成本降低 10 倍這件事,其實從最早的機器學習時期,比如我當年讀博士的時候,到 2012-2022 年這 10 年用 CNN 來做(卷積神經網絡)的時代,怎麼來量化、減值、增流是有一套非常標準的 pipeline。
在 Transformer 這一代裏面,其實也可以複用上一代的 pipeline。比如説做量化;比如説當你有一個非常長的 context window(聊天框)的時候,如何做緩存,效率更高、時間更低;比如説如何優化你的 attention(注意力)……有很多方法來做這件事,這其實是沒那麼難的東西,你只需要把每步做得足夠好,拼在一起就會帶來很大的變化。
張鵬:也就是説,相比於探索新大陸,現在掘地三尺把礦挖出來其實挺容易的?
**閆俊傑:**這個事我們想一下就知道了,比如説去年 3 月份剛有 GPT-4 的時候,那個時候又慢又貴,但是我們現在其實看 GPT-4o,包括之前的 GPT-4turbo,又便宜又快,效果又好,這只是過去一年發生的事。價格可能降了 10 倍,但實際上 OpenAI 比這個價格的降低還要更多。
我們大概算過,如果有兩年的時間,成本可以下降近 100 倍。其實我覺得,**技術的上限這件事相對來説沒那麼確定,需要更多的探索。但是成本下降這事,一定是有辦法的。**這個事在學術界已經發生了三次了。
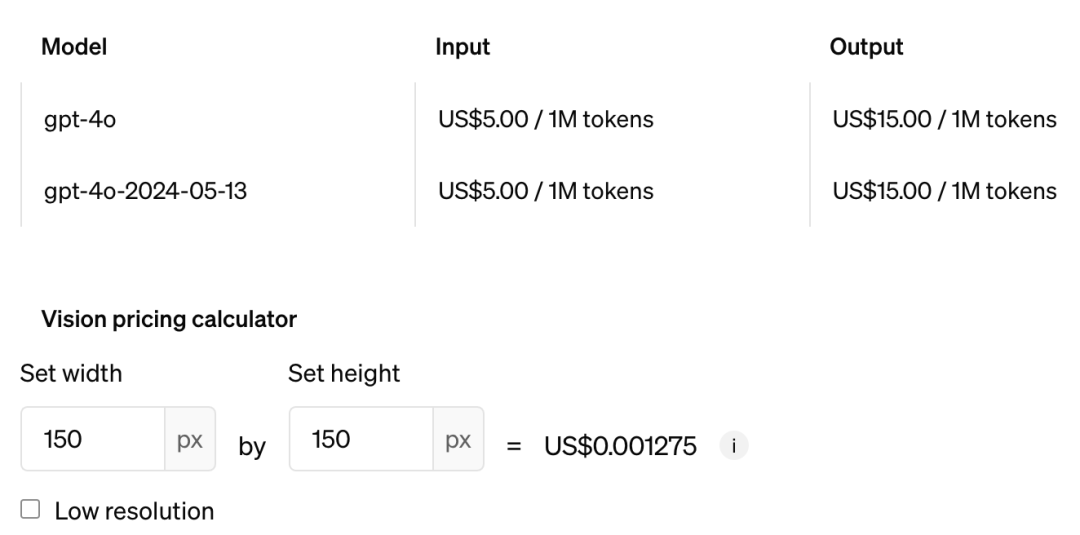
GPT-4o 成本|圖片來源:OpenAI
張鵬:今天有的人在拼命地優化技術成本,有的人在拼命提升模型能力、想做到最 top,在你看來後者是不是更重要?
**閆俊傑:**我覺得從結果上來是這樣的,但是從過程上兩個事是相互轉化的。這個其實是大模型裏面一個非常重要的規律是,效率跟效果其實可以相互轉化的。
假設訓練精度一樣,而你的算力是別人的 1/10,這意味着你能把效率做得很高,那你一定是能夠把模型的上限變得足夠高的。或者反過來説,如果你想要能力達到那個足夠高的上限,那你一定只有把效率變得非常高,這個事才有可能。
所有人的資源都是有限的,一定是你的效率足夠高、你的上限才能更高。實際上並不是我先衝到邊界後再來做優化,實際上兩邊是要一起做的。
這也是為什麼大部分研發越往上越難的原因,它要求你綜合考慮。
張鵬:所以 Sam 説「給我多少萬億、我就能把 AGI 迅速實現」這種話,是不是太不現實了?
**閆俊傑:**如果類比的話,比如台積電現在是 7 納米,那他接下來肯定是 5 納米、3 納米、2 納米一代代往下做。他不可能把 5 納米、3 納米都跳過了,突然間説自己能做到 2 納米。我覺得這個不太對,你很難把中間幾步跳過去。
張鵬:遠大的目標還是要一步步走,不能奢望直接通向目標,這也是創業的本質。
**閆俊傑:**當然可能它們太強了,我沒有理解它們的精髓之處。不過正常情況下應該是這樣的。
06
談投流和 PMF:國內 AI 產品不得不投流,還是技術沒有拉開足夠差距
張鵬:説到成本,前段時間我們看到,業界AI產品都開始投流了。我感覺以前移動互聯網時代,大家好歹是產品達成了 PMF 之後以後再投流放大,而現在產品需要花錢來測 PMF。一方面整個中國互聯網流量板結了,都在巨頭這。另一方面 AI 的能力有限,沒有辦法直接推到用户面前。這種投流導致的 PMF 成本上升,對這一代 AI 創業會不會是很大的挑戰?
**閆俊傑:**我們在這個事上吃過虧的。你發現這個事在中國,和在美國非常不一樣。比如美國的產品,ChatGPT 顯然沒有投流的,最早期的 Character.AI 也是沒有投流的。偏工具的東西,比如像 Midjourney,它顯然也是沒有投流,更多的是運營。但是反過來説在中國,基本上所有的產品都會投流,這其實是非常明顯的差別。
相當於説,美國公司更多的是靠技術能力和產品能力,大家都不會投流。但是這背後其實也是有代價的,代價就是美國的研發成本還是會非常高的。在中國反過來了,中國工程師的紅利和產品的紅利相對比較充裕的,但是中國的流量是頭部聚攏的。
但是投流更底層的原因還是因為,**目前為止在助手類的產品上,沒有哪家公司能拉開差距。**大家在同一個維度上,產品比較同質化,技術能力相對也是比較同質化的。為了獲取更多用户,只有靠投流,這是目前這類產品的困境。
這個東西大家都會有一些解釋,比如説有一種人認為獲取 query(用户詢問)是比較重要的事,如果把 query 本身的價值換算成錢的話,投流是值得的。就看你怎麼看這件事了。在技術不突出的時候,這個東西就是沒辦法。
張鵬:我覺得你選擇了某種「簡單」,就是把技術做到最好、絕對的領先,這個世界也會變得簡單。如果你不能在這件事上簡單地領先,世界就會對你變得複雜。你也不會省下多少成本,沒準成本更高,無非是押在這還是押在那。
**閆俊傑:**對,所以我們沒有認為要花錢買用户的 query。
我覺得 PMF 這件事是這樣的,一般創業的時候要寫 BP(商業計劃書)講你的 PMF 是啥,我們其實一開始沒有搞懂這件事,目前也沒有寫。其實我覺得可以做一些假設:核心就是類似這種產品,只要有用户時長就能變現。本質上,PMF 是以用户時長來量化的,這是比較標準的東西。目前這類產品是沒有變現邏輯的,但是如果這個東西能做的更大,或者能夠做到某個狀態,是能夠出來一些東西的。
張鵬:其實我覺得在不同的階段,大家需要面對不同的東西,並不是説有技術的純淨信仰,就一定要做 PLG(產品主導型增長)、就絕對不要投流。我也想到當年滴滴在很多的城市都沒有 PMF,都在燒錢,結果有一天它突然把用户習慣和產業邏輯燒出來了,PMF 出現了。你覺得AI行業會走跟當年網約車一樣的路嗎?
**閆俊傑:**我覺得不是,因為其實網約車是非常典型擁有網絡效應的業務,如果你有更多的司機、你就會有更多的用户,反過來也是一樣。
**大模型產品目前為止沒有網絡效應,**有可能有微弱規模效應。不過還是需要拆成不同的產品類型,比如效率類、娛樂類,單獨來看。
比如單純在效率類產品上,用户體驗的提升主要不是看用户是不是變多了,其實主要是看研發速率、模型迭代效率。相當於説,**你的技術能力提高跟你的用户數量增長,其實不完全成正比。**但在星野這種娛樂類產品上,如果你有越來越多的內容,規模效應還是挺明顯的。
張鵬:我覺得今天的創業確實比移動互聯網那一代更加不容易了。今天你去投流,所有的流量基本上在巨頭手裏,甚至你的 PMF 在它面前都是透明的,因為你不斷地投就説明你找到 PMF 了,它隨時可以跟。創業者一直在打明牌,巨頭錢多、人多,也有流量,你做產品測試還要給它們「交税」,這就是這個世界非常真實的真相,你作為創業者怎麼保持自己的希望?
**閆俊傑:**這確實是非常關鍵的問題,而且是一個很本質的問題。
我覺得偏信仰層面是這樣的。如果你沒有做很多的技術創新、產品創新,或者説沒有在合理的時間內找到足夠的非共識,這個事就不應該你幹,就是該被大廠幹。這不怪大廠壟斷。
我們要思考的是你作為一家獨立的公司,你真正能創新的東西在什麼地方?是研發效率、認知、產品體驗還是什麼?你如果沒有,創業就應該失敗,也不能怪別人。
張鵬:很務實的想法,大廠的競爭反而能驗證創業公司是不是真的有價值。
**閆俊傑:**是的。不過國內的流量被巨頭壟斷,但海外的流量其實相對比較開放,至少很多市場可以自由競爭。所以我覺得雖然很難,但是空間還是存在的。
07
談產品:
虛擬社交比智能助手受歡迎,但 super app 可能並不誕生其中
張鵬:説到產品,MiniMax 也是國內AI產品做得最早、最好的公司之一,能不能介紹一下你們「星野」、「海螺 AI」這兩款主打產品?它們的發展情況怎麼樣?
閆俊傑:「星野」基本是一個主打 fantasy(想象)的產品。你看它的時長、用户分佈、包括留存數據,其實它很像小説類的產品。
像「海螺 AI」這種,我們叫它智能助手,但其實它是沒有定義的。原因是目前這類產品最大的都只有 400 萬 DAU,不能算很大的產品,不太能定義這個行業。
我們的 fantasy 產品算是做的比較領先的,就用户量來説,它可能比助手類產品要高個 100 倍。我們的助手類產品才剛起步。
張鵬:fantasy 產品這麼好,它的交流輪次、使用時長怎麼樣?
**閆俊傑:**我覺得挺誇張的,是很長的時長。
張鵬:為什麼當年你會做「星野」這種 fantasy 的產品?當年的決策邏輯是什麼?
**閆俊傑:**兩年多前我們創業的時候,大模型還不是共識。我們當時認為把人工智能做成通用、服務大眾這件事是很重要的,而且恰好看到非常明顯的技術拐點,所以就開始創業了。當時,我們也不知道技術會變成什麼樣、產品會變成怎麼樣、商業化會變成怎麼樣。
「星野」的前身是「Glow」,我們當年做「Glow」的時候既沒有 ChatGPT、也沒有 Character.AI。當年我們不是做了很多分析、發現了機會,決定要來做它。我們的產品都是撞出來的。

MiniMax 旗下娛樂類產品「星野」|圖片來源:MiniMax
張鵬:所以是先有了對 AGI 的信仰,做出了模型的能力,再順着模型能力看能做啥就做啥,是這個邏輯嗎?
**閆俊傑:**真實的情況是這樣的。為什麼這個產品最後變成了「Glow」了、沒有變成 ChatGPT,是 2022 年 10 月份我們當時第一版的模型大概只有 30B(參數),它只能做娛樂的事,因為沒有那麼好。
張鵬:你得把 hallucination(幻覺)當作它的優勢,而不是缺點。
**閆俊傑:**實際情況是,最開始的時候我們只有一個 pre training,對齊還根本沒有跑通。所以這種東西是撞出來的,是非常隨機的一件事,就變成這樣了。
如果我們那時候更強一點,可能能做出來ChatGPT,但是很遺憾,那個時候能力就是沒有那麼強。
張鵬:創業歸根到底還得看實際狀況,當時你技術沒準備好,做不出來很正常,這反而説明了為什麼技術是AI產品最重要的部分。
**閆俊傑:**對,因為技術的發展就是有紅利的。
張鵬:現在你們有了「海螺AI」,是不是還改過名字?我記得去年你們還叫「海螺問問」?
**閆俊傑:**的確是,我們改名是想讓產品更加大眾化。首先,我們覺得「海螺問問」有 4 個字,減掉兩個字之後,「海螺 AI」的用户覆蓋率會更高。其次,我們發現用户更深層次的需求不完全來自於問答,所以叫了這個名字。
張鵬:更深層次的需求不只是問答,所以那時候你們已經開始往未來的「智能助理」方向做思考了嗎?
**閆俊傑:**是的。
張鵬:隨着 GPT-4o、Astra 的發佈,「智能助理」這個領域可能會有越來越多競爭者,你怎麼看這類產品的發展目標?
**閆俊傑:**這類產品核心的東西應該就是一個,提升用户解決問題的效率、或者説回覆的滿意度。
我們客觀來看,比如你問 ChatGPT 一個問題,**它有多大概率給你一個滿意的答案?我們自己的測試結果是,只有 60%。**這也是為什麼 AI 的用户滲透率只有 1% 的原因。可能只有對 AI 特別熱忱的用户,在它給了你無數次錯誤答案的時候,你還能選擇相信它、容忍它、甚至引導它來得到一些答案。
舉個例子,我們用更大用户量級的產品,比如百度搜索、小紅書搜索、甚至抖音搜索的時候,大概率能得到想看到的東西,滿意度顯然比 60% 高。只有這樣,產品才能走向更廣大的用户。
這也是作為從業者來説,我覺得 GPT-4o 沒有讓我覺得那麼好的原因。因為它其實並沒有提高這類產品真正重要的指標,也就是用户滿意度。**這個指標如果從 60% 提升到 90% 甚至更多,它就能變成可以信賴的產品。**這也是我們在「海螺 AI」這個產品上要努力的方向。
張鵬:我相信最終你們的目標還是想創造 Super App,或者用AInative 的方式解決主流用户的大問題。你覺得今天不管像「星野」、還是像「海螺 AI」,它們會是 Super App 的侯選嗎?還是説我們今天未必能看到 Super App 的最終形態,它會像你説的,隨着未來技術的發展隨機湧現出來?
**閆俊傑:**其實我們的基本假設是這樣的:第一,現有的產品都不是。第二,我們認為現在的單個產品都能夠長到足夠大的用户規模,能給用户帶來更大的價值,也能為我們帶來商業上足夠的成功和回報。這也是我們努力的目標。
至於説現在的產品到底是不是最終那個 Super App,我覺得其實是不重要的。為什麼?因為 AGI 是一件長週期的事,顯然不是 2024 年或者 2025 年就實現的,我們其實不需要給自己特別大的壓力。
我們真正需要做的事是,讓技術能夠足夠快地進步,同時基於當前技術能力做出的產品,能讓公司的運轉效率變得更高、能給用户創造一定的價值、能給公司創造商業回報。同時,我們還能有能力做更多的產品,一代一代往上滾,這就已經夠了。
美國公司不一定是這樣的路徑。但作為一家中國公司,這至少是有先例可尋的一條路徑。
*頭圖來源:MiniMax
本文為極客公園原創文章,轉載請聯繫極客君微信 geekparkGO